
我在8月底的时候,发过一篇基于 LlamaIndex+LangChain 框架,开发的简历筛选助手的应用。后续有星球成员提出希望能增加多个岗位的管理功能,正好接下来的校招活动可以用的上。
这篇在原项目的基础上,核心实现了多岗位并行管理(独立 JD、候选人池、向量索引隔离)和 HR 工作流(标签系统、分组展示、快速操作),同时进行了架构重构(分层设计、数据分库、模块化),并增强了大模型分析输出(四级推荐等级、结构化优劣势)和智能问答(按岗位过滤检索、流式输出)。
这篇试图说清楚:
系统的实际效果演示、四层系统架构拆解、五点核心技术实现、三个二次开发场景指南,以及对端侧模型应用的一些感想。
1、视频效果展示
在开始讲具体实现之前,老规矩先来看看整个系统的架构设计。下面这张图展示了从用户界面到数据存储的完整数据流。
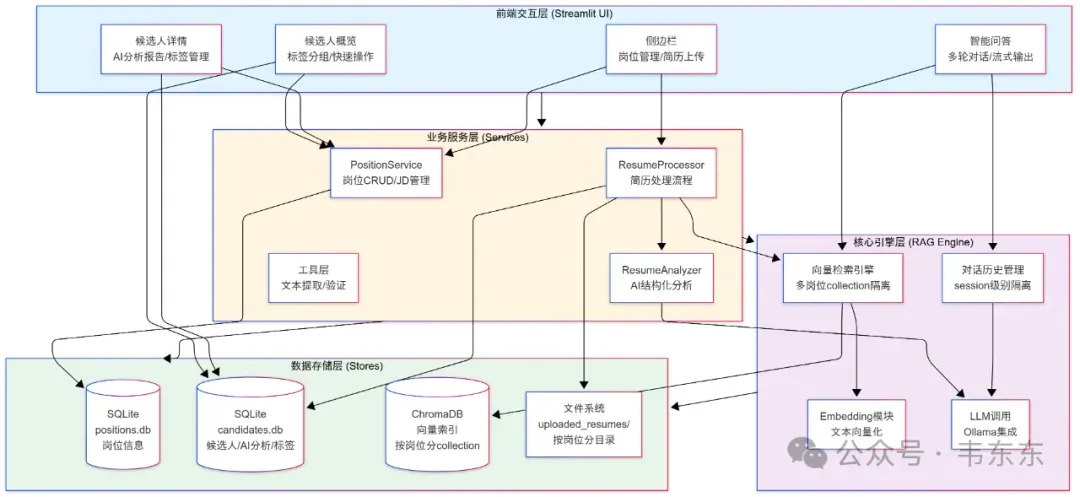
2.1为啥要分四层
在上一版单岗位系统里,UI 代码、业务逻辑、AI 调用全都混在一起的,一开始写起来确实快,但这次升级到多岗位管理的时候,改动起来难免顾此失彼,所以这次也算是做了下系统重构。
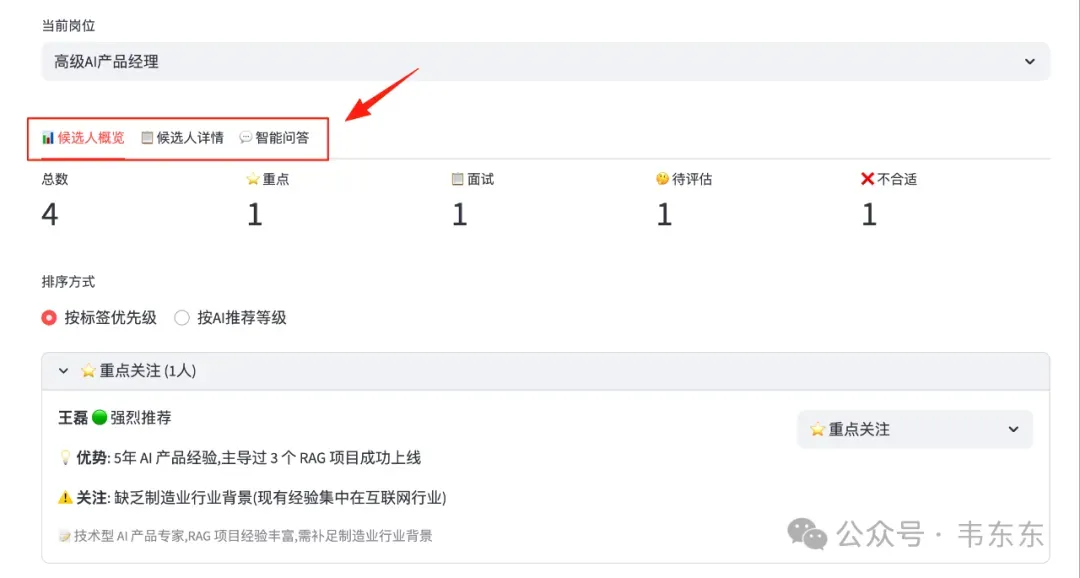
前端交互层这部分依然采用了轻量化的 Streamlit,搭建了三个 Tab 页面:候选人概览、候选人详情和智能问答。这一层只管显示数据和响应用户操作,不关心数据从哪来以及怎么处理。
业务服务层这部分是整个系统的核心处理逻辑所在。一份简历从上传到展示,需要经过:先提取文本,再调用大模型分析,然后存入数据库,最后建立向量索引。这些流程编排都在ResumeProcessor这个类里完成。还有一个PositionService,专门管理岗位的增删改查。这一层的好处是,如果以后想改业务流程,比如在大模型分析前加一个简历去重检查,只需要在这一层加几行代码,不用动其他地方。
核心引擎层这部分封装了所有大模型相关的能力。这一层最重要的是RAGEngine,包括了简历文本向量化、存入 ChromaDB,以及在用户提问时检索相关内容等功能。
数据存储层这部分用了三种存储方式:SQLite 存储岗位信息和候选人结构化数据,ChromaDB 存储向量索引,文件系统存储原始简历文件。所有复杂的 SQL 逻辑都封装在各个 Store 类里,这样以后如果要把 SQLite 换成 MySQL,只需要改 Store 类的实现,上层代码完全不用动。
2.2多岗位数据隔离
为了保证不同岗位的数据不会串台,我在三个层面做了隔离设计。
文件系统按岗位分目录
最简单直接的办法,就是把不同岗位的简历文件分开存。我在uploaded_resumes/目录下,给每个岗位创建一个子目录,目录名就是岗位 ID。比如"AI 产品经理"的岗位 ID 是position_001,这样做的好处是删除岗位的时候可以直接把整个目录删掉。
关系数据库用外键关联
在 SQLite 里,我给candidates表、ai_analysis表、hr_tags表都加上了position_id字段,并且设置了外键约束。每次查询候选人数据,SQL 语句里必须带上WHERE position_id = ?,从源头上避免跨岗位查询。
向量数据库按岗位分 collection
这是整个隔离机制里最关键的一环,ChromaDB 支持创建多个 collection(可以理解为不同的向量数据库),我给每个岗位创建一个独立的 collection。比如position_001对应的 collection 叫resumes_position_001,position_002对应的叫resumes_position_002。
可能会有人问为啥不用 metadata 过滤呢?比如所有简历存在一个 collection 里,然后在 metadata 里标记position_id,检索的时候再过滤。这个方案看起来更简单,但有个致命问题是,实际使用的时候性能会随着候选人总数线性下降。假设系统里有 10 个岗位,每个岗位 100 个候选人,那全局就有 1000 个候选人的向量。每次检索都要在 1000 个向量里搜索,然后再用 metadata 过滤,这无疑会很慢。
而用 collection 隔离,每个岗位的检索只在自己那 100 个向量里进行,性能只跟该岗位的候选人数相关,跟其他岗位完全无关。这就是物理隔离优于逻辑过滤的典型场景。这点非常像我在做 ibm rag 冠军赛项目拆解中提到的“疑一文一库”的做法。
2.3RAG 引擎与业务逻辑的解耦
在上一版系统里,我把 RAG 的代码直接写在业务逻辑里,结果就是代码复用性很差。这次重构我专门抽出了一个通用的RAGEngine类,只提供三个核心能力:建索引、检索、问答。
业务层想用的时候,把数据准备好,调用对应的方法就行。比如ResumeProcessor在处理简历的时候,会调用RAGEngine.build_index()把简历文本向量化;在智能问答的时候,会调用RAGEngine.query_with_rag()执行 RAG 流程。
这种解耦带来的好处是,如果各位想换一个向量数据库,比如从 ChromaDB 换成 Milvus,只需要改RAGEngine的内部实现,业务层的代码一行都不用动。或者如果想把这套 RAG 引擎用到其他项目,比如做一个标准的企业知识库问答系统,直接复制core/rag_engine_v2.py这个文件过去,写一个新的 Processor 类就能跑起来。
3、核心技术实现拆解
前面讲完了架构设计,这部分从代码层面讲几个关键的技术实现,这部分会聚焦在私以为有一定工程借鉴价值的地方。
3.1简历完整向量化的考量
一个好用的 RAG 系统设计,一个绕不开问题是如何精准的切分文档。上一版系统里,因为目的是要演示完整的系统流程,所以演示的简历部分也是针对性的进行了设计,分块部分按照"核心技能"、"工作经历"等章节标题进行处理。但这显然不符合实际五花八门的简历格式情况。 这次重构,我做了一个看似偷懒实则更务实的做法,就是把每份简历作为一个完整的 node,不做分块处理。
复制首先有个共识是,简历通常很短,一般 2-4 页,毛估 2000-4000 字左右,完全在主流嵌入模型的处理范围内。这次演示用的bge-m3模型支持 8192 tokens,处理一份完整简历应该说毫无压力。
其次,完整向量化也避免了信息碎片化。当 HR 问“张三有没有 RAG 项目经验”的时候,如果简历被切成 10 个 chunk,可能需要检索多个 chunk 才能拼凑出完整答案。而整份简历作为一个 node,一次检索就能拿到所有相关信息,LLM 可以看到完整上下文进行推理。
再者,实现逻辑简单也减少了 bug 风险。代码的核心逻辑就是把多页 PDF 合并成一个字符串,然后塞进一个 node,没有复杂的正则匹配、没有边界判断,代码清晰好维护。在实际使用中实测效果很好,检索准确率明显提升,而且及时是 8b 尺寸的量化模型推理过程也很稳定。
3.2Pydantic 驱动的结构化分析
如何让 LLM 稳定地输出结构化数据,这也是个绕不开的挑战。好的工程实践,无非也是一套围绕模型动态边界构建的解决方案。这次我用了在历史企业项目中常用的 Pydantic 模型 + 详细 Prompt 的组合,实现了相对可靠的结构化输出。先定义数据模型:
复制Pydantic 的好处是,它不仅定义了数据结构,还内置了校验逻辑。比如recommendation_level必须是四个等级之一,key_strengths至少有 1 条最多 5 条,这些规则会自动执行。然后在 Prompt 中明确输出格式:
复制Prompt 里不仅给出了 JSON 格式,还详细说明了每个字段的要求,以及提供了好例子和坏例子的对比。这种高指令性的 Prompt 实测可以明显提升 LLM 输出的质量和稳定性。最后在解析时做好容错处理:
复制这套机制总结来说有三层容错:先尝试直接解析,不行就用正则提取 JSON 块,再不行就清理格式后解析,最后还有一个降级策略返回默认值。实际使用中,绝大部分情况第一次就能成功解析,少数格式异常的也能被后续逻辑兜住,系统健壮性非常高。
3.3简历处理的五步流水线
一份简历从上传到最终可用,需要经历多个步骤。原版系统这些逻辑散落在各处,这次我用ResumeProcessor类把整个流程标准化成五步流水线:
复制这个设计有几个好处:
首先,每一步都有明确的输入输出和成功标志。result['steps']字典记录了每一步的执行状态,方便调试和监控。如果处理失败,可以立刻看到是在哪一步出的问题。
其次,失败快速返回,避免无效计算。如果文本提取就失败了,后面的大模型分析、向量索引都不用做了,直接返回错误信息。这种 fail-fast 策略节省资源,也让错误信息更清晰。
最后,result字典不仅包含每一步的状态,还包含候选人 ID、分析结果、文件路径等信息,上层 UI 可以根据这些信息给用户精准的反馈。
这种流水线模式在企业级应用中非常常见,它把复杂流程拆解成清晰的步骤,每步职责单一,容易测试和维护。
3.4多岗位检索的元数据过滤机制
前面架构部分提到,我用 metadata 过滤实现多岗位隔离。这里展示一下具体的检索代码:
复制LlamaIndex 的MetadataFilters功能非常强,支持多种操作符(EQ、GT、LT、IN等),可以组合多个条件。这里我只用了最简单的等值匹配,但如果以后需要更复杂的查询,比如"工作年限大于 5 年且有制造业背景",只需要添加更多的MetadataFilter就行。在向量化这一步,我把position_id、candidate_name等信息存入 node 的 metadata:
复制检索的时候,ChromaDB 会先在全局向量空间找到语义最相似的 top-K 个结果,然后用 metadata 过滤器筛选出符合条件的 node。语义匹配 + 精确过滤的组合,既保证了检索质量,又实现了数据隔离。
需要注意的是,我在架构设计部分提到过 collection 隔离性能更好。但实际开发时我发现 LlamaIndex 对多 collection 管理不太友好,需要为每个岗位创建独立的 index 对象,代码会变得很复杂。所以我在单 collection + metadata 过滤和多 collection 隔离之间做了权衡,选择了前者。
这也是说明了理论最优方案不一定是工程最优方案。要考虑框架限制、开发成本、可维护性等多方面因素。目前这个方案在候选人数量不超过 200 的情况下性能完全够用,如果以后数据量真的上去了,再重构成多 collection 也不迟。
3.5基于 Session 的多轮对话记忆
智能问答如果只能单轮回答,用户体验无疑会很差。我用 Streamlit 的session_state实现了按岗位隔离的对话记忆。
复制首先是按岗位 ID 隔离对话历史。不同岗位的问答互不干扰,HR 在"AI 产品经理"岗位的对话,不会影响到"算法工程师"岗位。其次,只显示最近 N 条消息。对话历史完整保存在session_state里,但页面上只显示最近 15 条,避免页面过长影响体验。
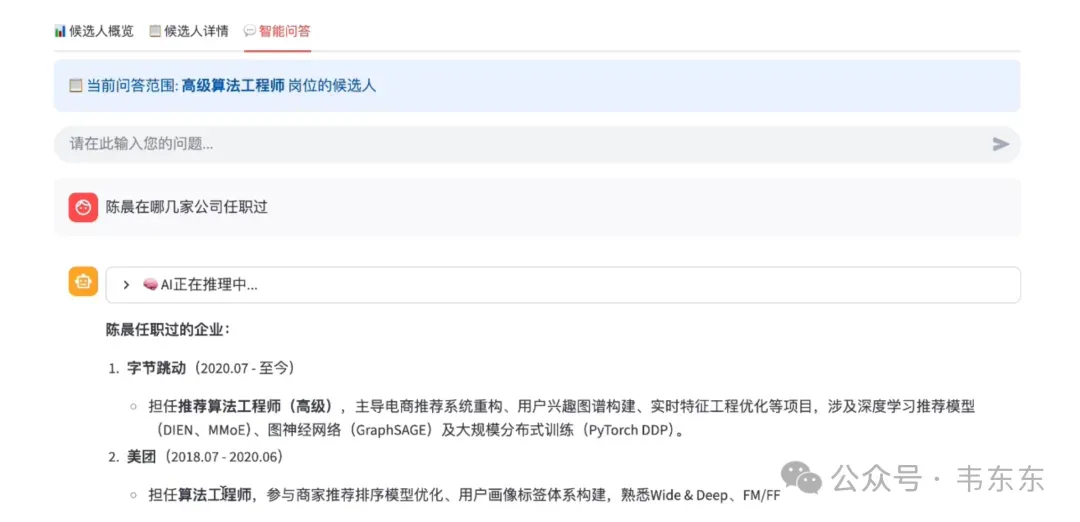
最后,保存推理过程。除了最终答案,我还把 LLM 的 thinking 过程保存下来。这样用户可以在st.expander里查看 AI 的推理链路,提升可解释性。这个实现虽然简单,但在实际使用中效果很好。多轮对话让 HR 可以不断追问,获得更深入的候选人情况了解。
4、二次开发指南
在实际使用中,不同企业或者用户会有不同的定制需求。这部分我根据和一些从业者的沟通,介绍三个高频需求场景,作为二次开发的参考。
4.1批量导入简历
从招聘网站批量下载的简历通常打包在 zip 文件里,每次都要手动解压再上传,非常低效。如果能直接上传 zip 包,系统自动解压并批量处理,能节省掉不必要的手动操作。
复制核心实现思路是在上传组件支持 zip 格式,解压后递归扫描所有简历文件,然后调用现有的批量处理逻辑即可。
4.2薪资期望范围提取与预算匹配
薪资是招聘决策中的关键因素,但人工查看每份简历判断是否在预算内,无疑会浪费大量时间在预算不匹配的候选人上。如果系统能自动提取薪资期望并与岗位预算对比,就可以在筛选阶段就过滤掉不合适的候选人。
复制核心实现思路,是在大模型分析的 Pydantic 模型中增加薪资字段,在 Prompt 中增加提取指令,大模型会自动识别各种薪资表述("20-25K"、"年薪 30 万"等)并归一化为统一格式。
4.3AI 生成面试问题清单
筛选出候选人后需要准备面试问题,要仔细读简历找出可以深挖的点。如果系统能根据简历和岗位要求自动生成针对性的面试问题,可以大幅提升面试准备效率。
复制核心实现思路是设计一个专门的 Prompt,让 LLM 基于简历内容和分析结果,生成分类的面试问题(能力验证、项目深挖、短板确认等)。
5、写在最后
现在,当大家谈论大模型企业应用落地的时候,默认的潜台词都是企业主导、集中部署。而现实情况是,企业去落地一个面向于不同部门的大模型应用,是一个道阻且长的过程。但实际上像 HR、律师、会计这类专业工作者,每天也在做大量重复劳动。如果能把这套系统打包成一个开箱即用的桌面应用,内置嵌入模型、向量数据库、开源 LLM,完全本地运行,不依赖云服务,可以更加短平快的的给很多岗位带来提效或者解放双手。
这个项目中演示时使用的 qwen3:8b(Q4 量化版)5.2GB大小,在我的 24GB 内存 MacBook 上,首字响应时间大概 5 秒,后续 token 生成速度相对比较流畅。但这个性能对大部分 HR 的工作电脑来说是个不小的挑战。DeepSeek 年初开源的蒸馏后的小尺寸模型,在智力水平和电脑性能要求上都不够实用,但现在似乎重新来到了端侧模型应用重新爆发的临界点。一方面,1.5B-3B 的小模型配合垂直领域微调,完全可以胜任简历筛选这类专业场景。其次,更优秀的小尺寸开源模型更新的速度我想也会超出大家的预期。
从创业视角来看,这不仅是 2B 市场的机会,更是面向专业个人用户(像 Cursor 面向开发者那样)的增量市场。让专业工作者都能拥有自己的大模型应用助手,而不是一味的等待企业采购,这或许是接下来非常值得保持关注的长尾需求。


