全球最快的开源大模型来了——速度达到了每秒2000个tokens!
虽然只有320亿参数(32B),吞吐量却是超过典型GPU部署的10倍以上的那种。

它就是由阿联酋的穆罕默德·本·扎耶德人工智能大学(MBZUAI)和初创公司G42 AI合作推出的K2 Think。
名字是不是有点熟悉?
没错,它和月之暗面前不久推出的Kimi K2在命名上是有点小撞车,不过阿联酋这个多了个“Think”。
但非常有意思的一点是,在K2 Think的背后,确实有“made in China”的味道。
因为从HuggingFace中的Model tree来看,K2 Think是基于Qwen 2.5-32B打造的:
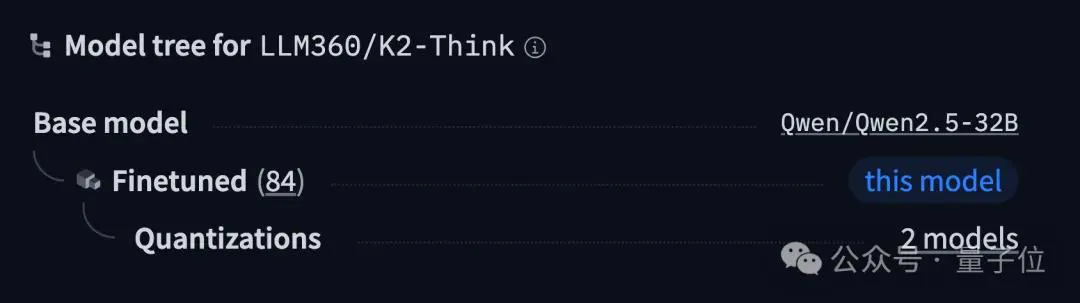
而且“全球最快开源AI模型”之外,MBZUAI官方还称自家的K2 Think是“有史以来最先进的开源 AI 推理系统”。
那么它的实力到底几何?我们继续往下看。
目前,K2 Think已经给出了可以体验的地址(见文末)。
我们先小试牛刀测试一把IMO的试题:
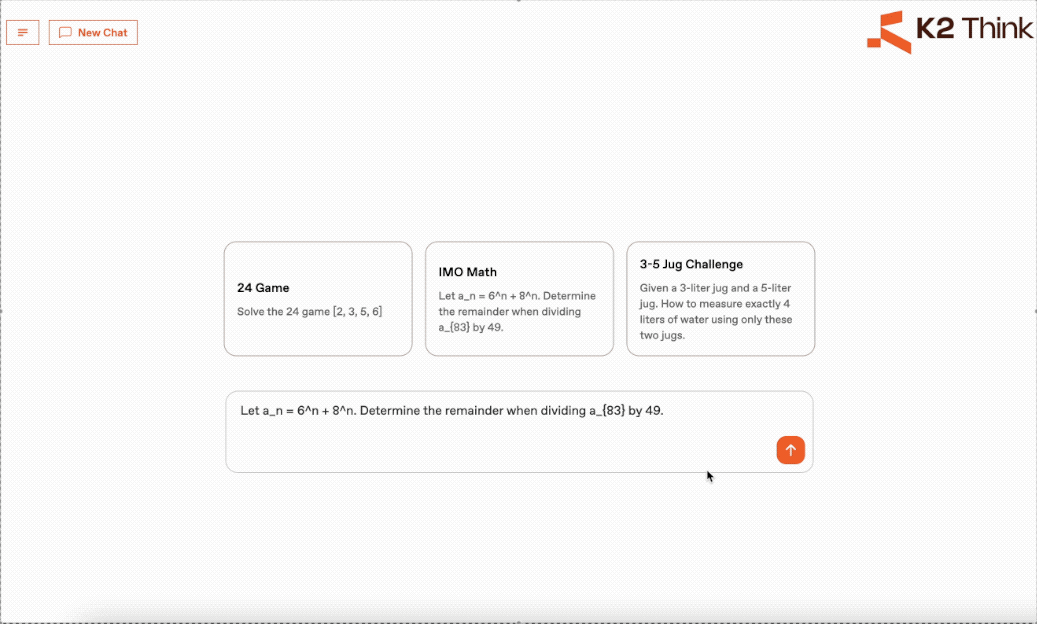
可以肉眼看到,在没有任何加速的情况下,K2 Think在思考过后输出答案的速度,真的就是“啪的一下”。
从底部给出的速度来看,已经达到了2730.4 tokens/秒。

接下来,我们用中文来测试一个经典问题:
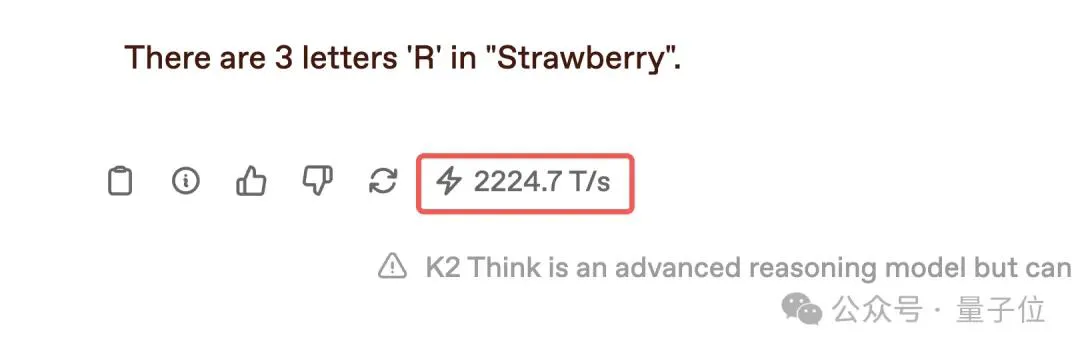
速度依旧保持在了2224.7 tokens/秒,并且给出了正确答案:3个R。
我们再来实测几道AIME 2025的数学题:


可以看到,K2 Think最大特点就是所有问题均能保持在超过2000 tokens/秒的速度,并且就目前实测结果来看,生成的答案均是正确。
但从功能角度来看,目前K2 Think还不支持文档传输,以及多模态等能力。
不过MBZUAI的高级研究员Taylor W. Killian在X上也给出了解释:
从体量上来看,K2 Think仅有32B,但官方却表示,它已经可以与OpenAI和DeepSeek旗舰推理模型的性能相当。
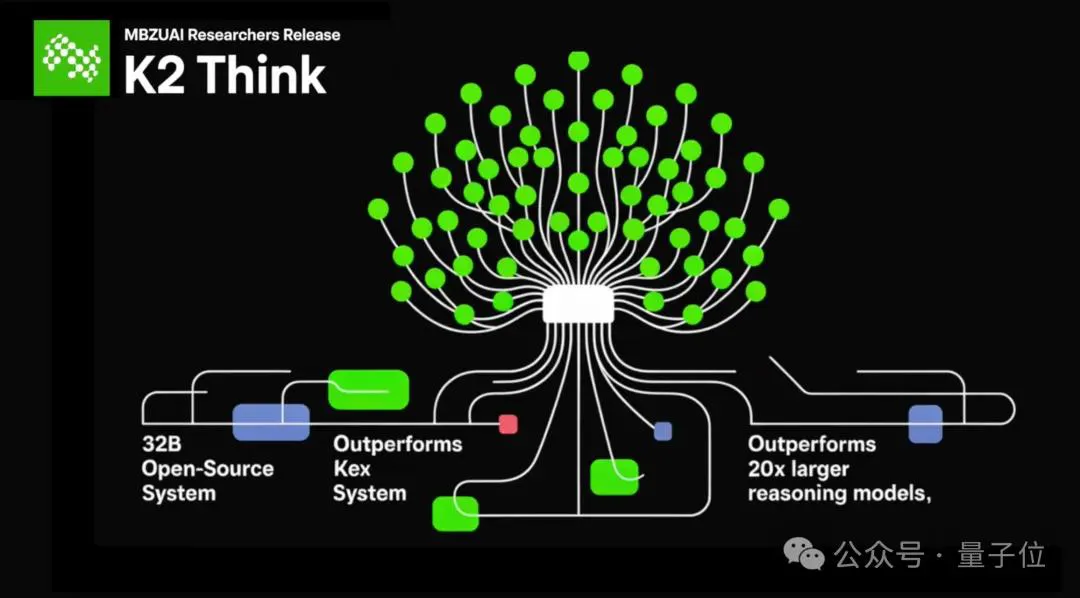
从测试结果来看,K2 Think在多项数学基准测试中,拿下了较为理想的分数,例如AIME’24 90.83分、AIME’25 81.24分、HMMT25 73.75分,以及Omni-MATH-HARD上取得60.73分的成绩。
并且K2 Think团队已经发布技术报告:

从整体来看,K2 Think团队主要从六个方面做到了技术创新:

- 长链路思维的监督微调(SFT):通过精心设计的链式推理数据,训练模型逐步思考,而不是直接给答案,使其在复杂问题上更有条理。
- 可验证奖励的强化学习(RLVR):模型不是依赖人类偏好打分,而是直接以答案对错为奖励信号,显著提升数学、逻辑等领域的表现。
- 推理前的智能规划(Plan-Before-You-Think):先让一个规划代理提炼问题要点,制定解题大纲,再交给模型展开详细推理,就像人类先列提纲再解题一样。
- 推理时扩展(Best-of-N采样):对同一问题生成多个答案,再挑选最佳结果,从而提高正确率。
- 推测解码(Speculative Decoding):在推理时并行生成和验证答案,减少冗余计算,加速输出。
- 硬件加速(Cerebras WSE晶圆级引擎):依托全球最大的单芯片计算平台,实现单请求每秒超2000 tokens的生成速度,使长链路推理也能保持流畅的交互体验。
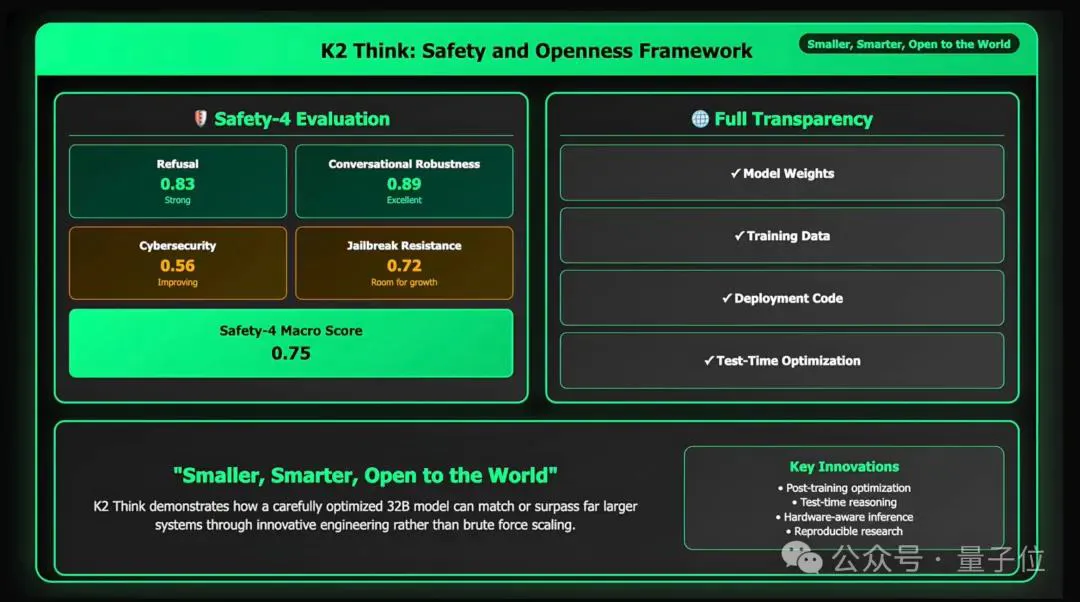
与此同时,研究团队还对K2 Think进行了系统的安全测试,包括拒绝有害请求、多轮对话鲁棒性、防止信息泄露和越狱攻击等,整体达到了较高水平。
那么你也想尝鲜一下目前世界最快开源AI模型的速度吗?链接放下面喽,感兴趣的小伙伴快去体验吧~
体验地址: https://www.k2think.ai/
技术报告: https://k2think-about.pages.dev/assets/tech-report/K2-Think_Tech-Report.pdf
参考链接: [1]https://www.k2think.ai/k2think [2]https://x.com/mbzuai/status/1965386234559086943 [3]https://huggingface.co/LLM360/K2-Think [4]https://venturebeat.com/ai/k2-think-arrives-from-uae-as-worlds-fastest-open-source-ai-model [5]https://www.youtube.com/watch?v=8C6_B1QeyBo


