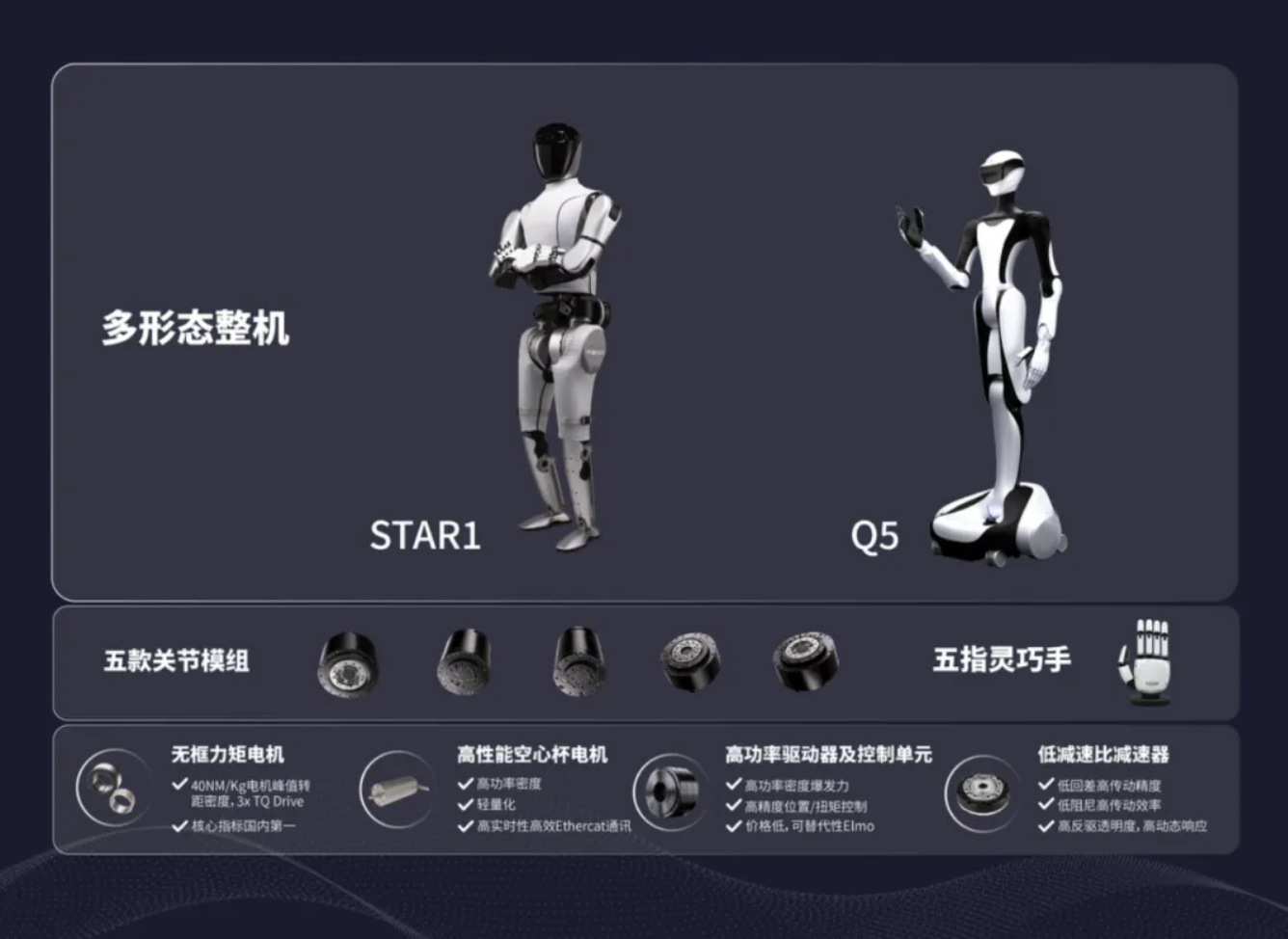
据了解,生成式机器人大模型 VPP 由清华大学叉院的 ISRLab 和星动纪元合作开发,将视频扩散模型的泛化能力转移到了通用机器人操作策略中,解决了 diffusion 推理速度的问题,让机器人实时进行未来预测和动作执行,大大提升机器人策略泛化性,并且现已全部开源,相关成果入选 ICML 2025 Spotlight。

星动纪元介绍称,VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望大大加速人形机器人的商业化落地。

目前 AI 大模型领域有两种主流方法,基于自回归的理解模型和基于扩散的生成模型,各自代表作分别为自回归的 GPT 和生成式的 Sora:
GPT 的思路演化到具身智能领域,就是以 PI( Physical Intelligence )为代表的 VLA 技术,是从视觉语言理解模型(VLM)微调而来,擅长抽象推理和语义理解。
生成式的技术与机器人的碰撞,就诞生了 VPP 这样的生成式机器人大模型。
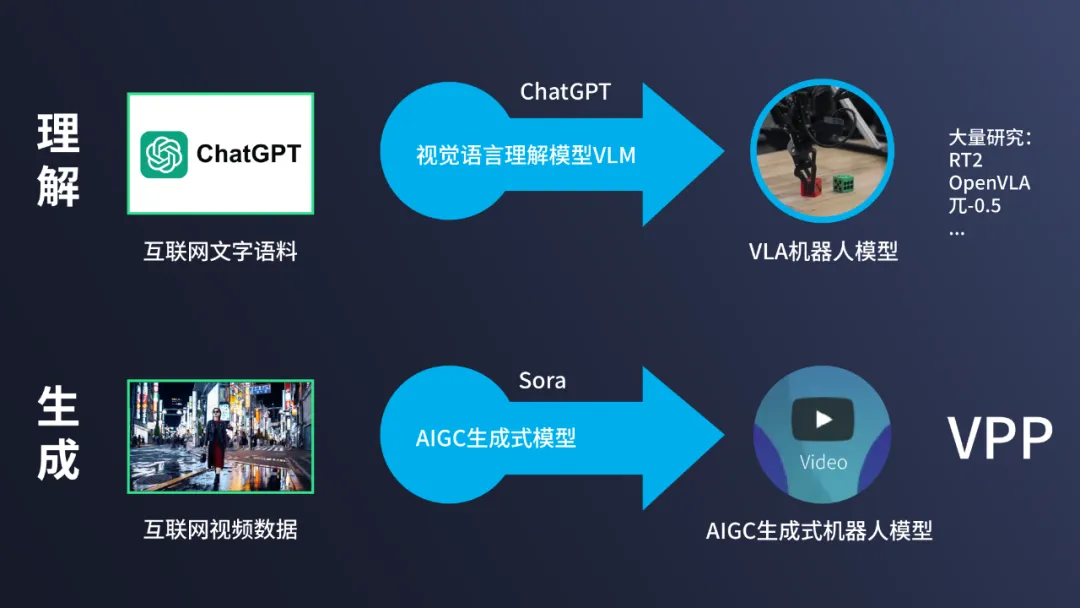
然而,人工智能领域存在着著名的莫拉维克悖论(Moravec's paradox):高级推理功能反而容易(例如围棋、数学题),下层的感知和执行反而困难(例如各种家务)。VLM 更擅长高层级的推理,而 AIGC 生成式模型更擅长细节处理。VPP 基于 AIGC 视频扩散模型而来,在底层的感知和控制有独特的优势。
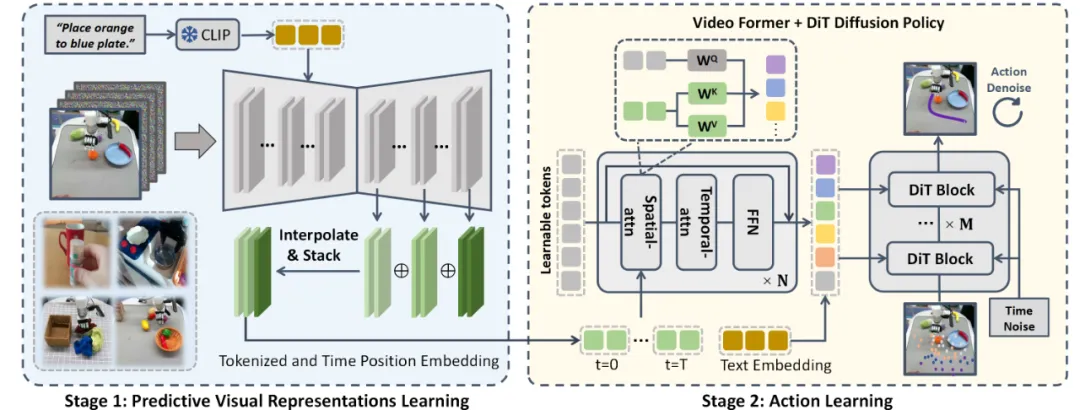
如图所示,VPP 分成两阶段的学习框架,最终实现基于文本指令的视频动作生成。第一阶段利用视频扩散模型学习预测性视觉表征;第二阶段通过 Video Former 和 DiT 扩散策略进行动作学习。
1、提前预知未来:VPP 让机器人行动前做到“心里有数”
以往机器人策略(例如:VLA 模型)往往只能根据当前观测进行动作学习,机器人策略需要先理解指令和场景,再执行。VPP 能够提前预知未来的场景,让机器人“看着答案”行动,大大增强泛化能力。

VPP 视频预测结果与机器人实际物理执行结果几乎一致。能被视频生成的,就能被机器人执行。
2、高频预测和执行:VPP 让机器人执行速度“更快一步”
AIGC 视频扩散模型虽能生成逼真的视频,但往往花费大量推理时间。星动纪元研究团队发现,不需要精确地预测未来的每个像素,通过有效提取视频模型中间层的表征,单步去噪的预测就可以蕴含大量未来信息。这让模型预测时间小于 150ms,模型的预测频率约 6-10hz,通过 action chunk size = 10,模型的控制频率能超过 50Hz。
如图所示,单步视频扩散模型预测已经蕴含大量未来信息,足够实现高频预测(规划)和执行。

3、跨本体学习:VPP 让机器人先验知识流通“畅通无阻”
如何利用不同本体的机器人数据是一个巨大的难题。VLA 模型只能学习不同维度的低维度 action 信息,而 VPP 可以直接学习各种形态机器人的视频数据,不存在维度不同的问题。如果将人类本体也当作一种机器本体,VPP 也可以直接学习人类操作数据,降低数据获取成本。同时视频数据也包含比低维度动作更加丰富的信息,提高模型泛化能力。

VPP 能学习跨本体的丰富视频数据,相比之下,VLA 只能学习维度不一致的低维动作信号。
4、基准测试领先:VPP 让机器人性能“一骑绝尘”
在 Calvin ABC-D 基准测试中,实现了 4.33 的任务完成平均长度,已经接近任务的满分 5.0。相较于先前技术,VPP 实现了 41.5% 的提升。
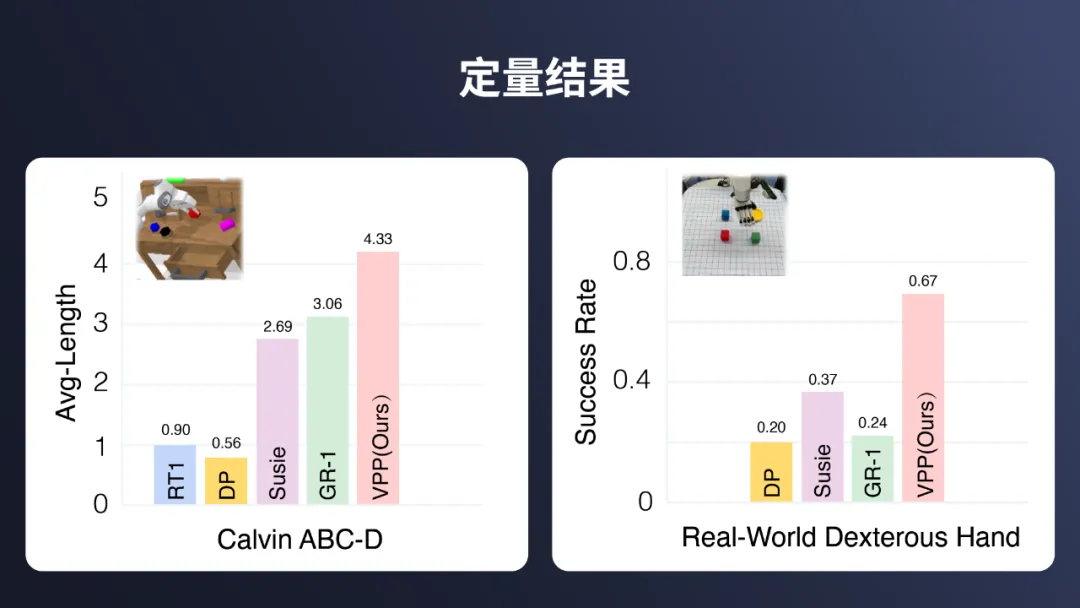
左图为 Calvin ABC-D 任务的平均长度对比,右图为 Real-World Dexterous Hand 任务的成功率对比。可以看出,VPP 方法在这两项指标中均取得了最佳表现,在仿真环境任务完成平均长度达到 4.33,真机测试成功率为 67%,显著优于其他方法。
5、真实世界灵巧操作:VPP 让机器人灵巧操作“举一反三”
在真实世界的测试中,VPP 模型展现出了良好的多任务学习能力和泛化能力。在星动纪元单臂 + 仿人五指灵巧手灵巧手 XHAND 平台,VPP 能使用一个网络完成 100+ 种复杂灵巧操作任务,例如抓取、放置、堆叠、倒水、工具使用等,在双臂人形机器人平台能完成 50+ 种复杂灵巧操作任务。

6、可解释性与调试优化:VPP 让机器人“透明可控”
VPP 的预测视觉表示在一定程度上是可解释的,开发者在不通过 real-world 测试情况下,通过预测的视频来提前发现失败的场景和任务,进行针对性的调试和优化。
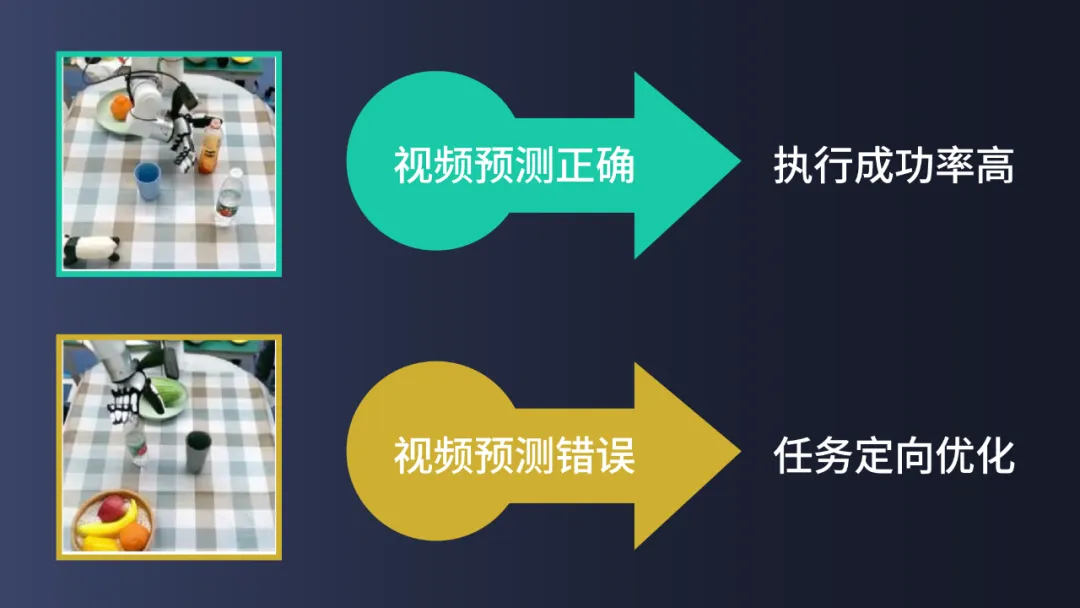
而 VLA 模型是完全端到端的模型,开发者在调试优化中需要大量真实世界的测试来找到模型漏洞,需要花费大量的时间。
AI在线附开源链接如下:
论文地址:https://arxiv.org/pdf/2412.14803
项目地址:https://video-prediction-policy.github.io
开源代码:https://github.com/roboterax/video-prediction-policy