
为破解长期以来学界与业界难以对数据进行价值量化的困局,上海人工智能实验室(上海 AI 实验室)OpenDataLab 团队在今年 8 月正式开源了首个全面、公正的后训练数据价值评测平台 ——OpenDataArena (ODA) 。该项目致力于将数据选择从「盲目试错」的炼丹术,转变为一门可复现、可分析、可累积的严谨科学。
在初版系统发布后的数月间,项目通过团队内部及小范围社区用户的深度使用,完成了高强度的技术验证与功能打磨。伴随着评测规模、工具链和分析能力的持续扩展,近期,我们终于迎来了 ODA 的全面升级 —— 一个结论更系统、功能更完整、视角更多元的正式版本,该项目正式面向全体开发者开放。

项目主页: https://opendataarena.github.io/
开源工具: https://github.com/OpenDataArena/OpenDataArena-Tool
数据集: https://huggingface.co/OpenDataArena/datasets
报告链接:https://arxiv.org/pdf/2512.14051
ODA 的核心理念非常明确:数据价值必须通过真实的训练来检验,而非主观的臆测。为此,我们立足于全新发布的正式版本,对平台进行了体系化的深度重构,由四个相互支撑的核心模块组成了这套完整的数据评测基础设施。这标志着 ODA 已经从最初的功能验证阶段,发展成为可以对数据价值进行系统化评测的重要平台。
一、数据价值排行榜
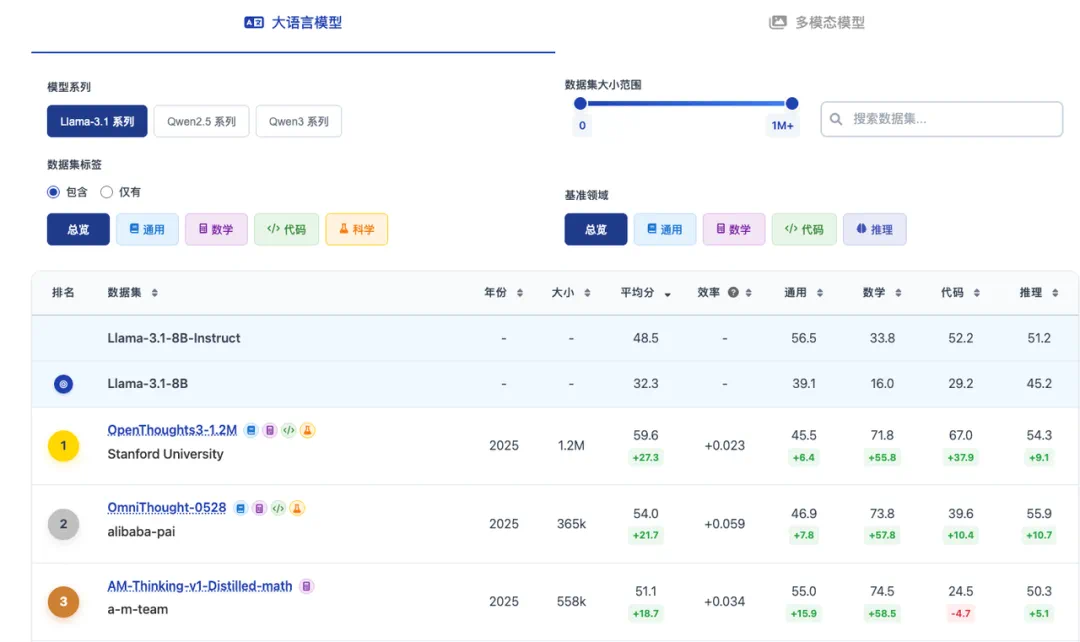
首先,ODA 项目打造了数据价值排行榜。通过构建一套统一的训练与评测流程,让数据在固定的模型规模(如 Llama3、Qwen2/3 7-8B)和训练配置下,对来自不同领域的文本及多模态数据进行横向评测。
评测覆盖通用、数学、代码、科学与长链推理等能力维度,这使得数据价值能直接通过下游任务(如数学、代码、推理等)的实际表现来量化,而非主观判断。目前,ODA 平台已经从初版仅仅只有文本数据的评测,扩展到了多模态数据集的质量评测,并以最先进的 Qwen3-VL 作为真实训练的基准模型。
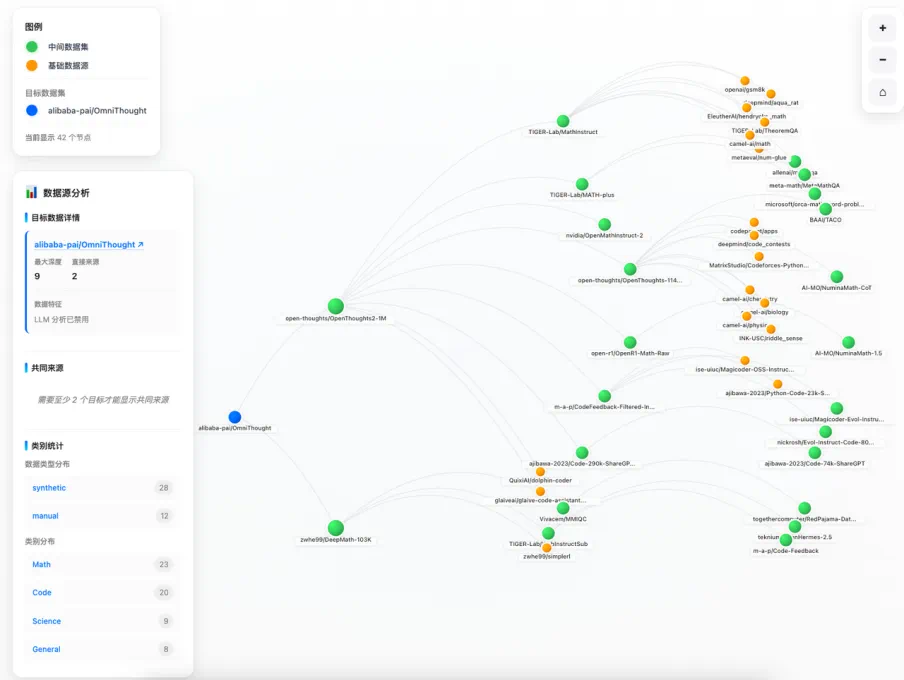
二、数据血缘探索器
其次,针对数据界常见的「近亲繁殖」问题,ODA 全新发布「数据血缘探索器」。它像绘制族谱一样,清晰地刻画出数据集之间的继承、混合与蒸馏关系。通过结构化建模与可视化展示,研究者可以直观地看到不同数据集之间的高度重叠与依赖关系,看到社区中被反复复用的核心数据源,以及更清晰的发现潜在的训练–测试污染与「近亲繁殖」问题。这一能力让「为什么某些数据集长期霸榜」不再是经验结论,而是可以被结构性解释的现象。
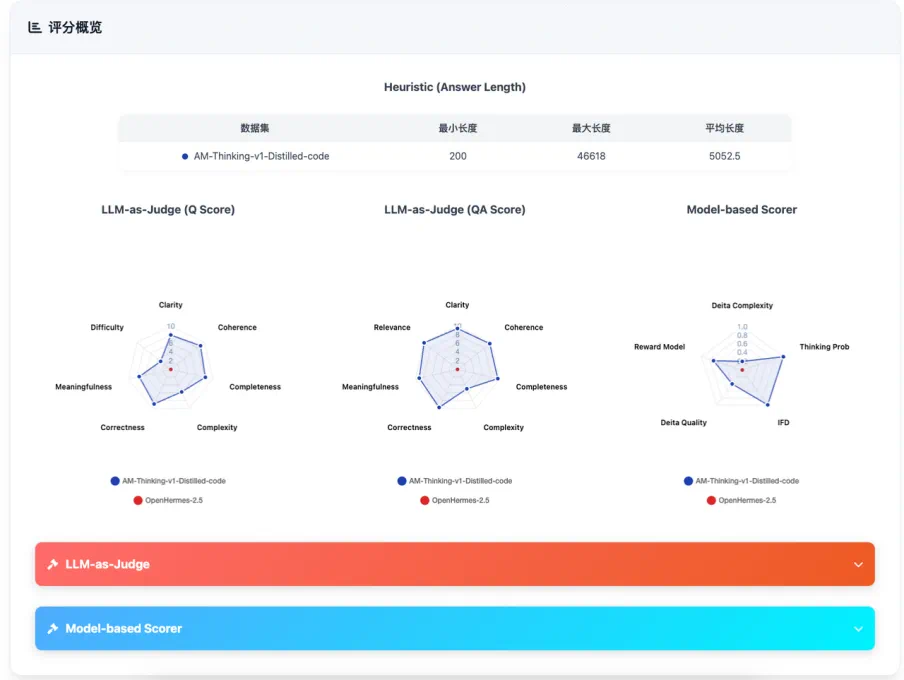
三、多维数据评分器
除了看模型结果,ODA 还从数据本体出发,对数据质量进行细粒度刻画。ODA 提供了一个细粒度的评分框架,基于模型评估、LLM-as-a-Judge 与启发式指标等多种方法,从指令复杂度、响应质量、多样性等维度对数据进行深度剖析,生成每份数据的专属「体检报告」,并已对千万级样本的评分结果进行开源。 这使得研究者不仅能判断「哪份数据更有效」,还能进一步分析它为什么有效。值得一提的是,在初版的基础上,ODA 多维数据评分器目前已经扩展支持 80+ 种多维度的评分器,支持用户一键方便的对所需要的数据维度进行打分。
四、全开源评测工具箱
此外,为了促进社区共建,ODA 完全开源了其训练、评分和可视化工具,覆盖从模型微调到结果复现的完整流程,以及上述精细化的数据评价打分器。ODA 工具支持用户一键复现结果,或对自己私有数据进行标准化评测,实现真正意义上的横向对比。
五、硬核发现:那些被忽视的数据真相
在对 120 多个主流数据集进行超过 600 次训练和 4000 万条数据的深度分析后,OpenDataLab 团队得出了一系列具有指导意义的「硬核」结论,足以重塑业界对高质量数据的认知 :
1. 解答质量比问题复杂度更关键: 实验发现,单纯增加问题的复杂度并不能有效预测数据价值。相反,解答的长度(推理过程的充分性)与最终质量呈强正相关,这在数学和科学类任务中尤为突出。
2. 代码数据的「异类」属性: 搞代码模型不能照搬数学的逻辑。代码讲究简洁精准,长篇大论反而会损害效果。这意味着通用的评分标准在代码领域经常失效,必须建立针对性的评估体系。
3. 开源数据「近亲繁殖」严重: ODA 的数据血缘分析显示,社区反复依赖的核心数据源比较有限(例如 GSM8K 被多次复用),由此造成了严重的数据同质化。借助数据血缘分析,更极端的发现是,数据污染越来越严重:大量训练样本直接与测试集发生重叠。
4.「少即是多」的局限性: 尽管 LIMA 等研究曾宣称少量精选数据即可成功,但 ODA 的实验证明这极度依赖模型底座的先天能力。如果底座一般,过少的数据量会导致性能崩塌。真正稳健的路径是追求「高质量且具规模(High-Density Volume)」 的数据配方。
5. 为什么有些数据集能霸榜? 以 AM-Thinking-distilled 为代表的超大规模聚集型数据集,能够同时在数学与代码任务上取得明显的优势,关键原因在于其跨领域融合能力。它通过递归方式整合了 435 个数据节点,显著提升了数据分布的多样性与互补性。
6. 数据可以弥补底座差距: 这是一个令人振奋的发现。即使 Llama 3.1 和 Qwen 2.5 之间存在显著的底座分差,只要用上如 OpenThoughts3-1.2M 这样的高质量微调数据,这个差距几乎可以被抹平。可以说,好的数据配方真的能让模型「逆天改命」。
未来展望
OpenDataArena 的远景,绝不不满足于仅仅建立一个排行榜,更致力于将数据研发从「玄学」推向可复现、可分析的「科学」。未来,ODA 将持续进化,探索智能体数据,金融、医疗等垂直领域的深层价值。
在这个数据决定 AI 上限的时代,唯有手握科学的标尺,才能精准丈量每一份数据的真实「重量」。


