编辑 | 白菜叶
根据近期推出的基准测试平台,o3 是由 ChatGPT 的创建者开发的人工智能 (AI) 模型,被评为回答多个领域科学问题的最佳 AI 工具。
由华盛顿州西雅图艾伦人工智能研究所 (Ai2) 开发的 SciArena,根据 23 个大型语言模型 (LLM) 对科学问题的回答进行了排名。102 位研究人员对答案的质量进行了投票。
由 OpenAI 开发的 o3,在回答自然科学、医疗保健、工程以及人文和社会科学问题方面被评为最佳。
SciArena:https://allenai.org/blog/sciarena
由 DeepSeek 公司研发的 DeepSeek-R1 在自然科学问题上排名第二,在工程学问题上排名第四。谷歌的 Gemini-2.5-Pro 在自然科学问题上排名第三,在工程学和医疗保健问题上排名第五。
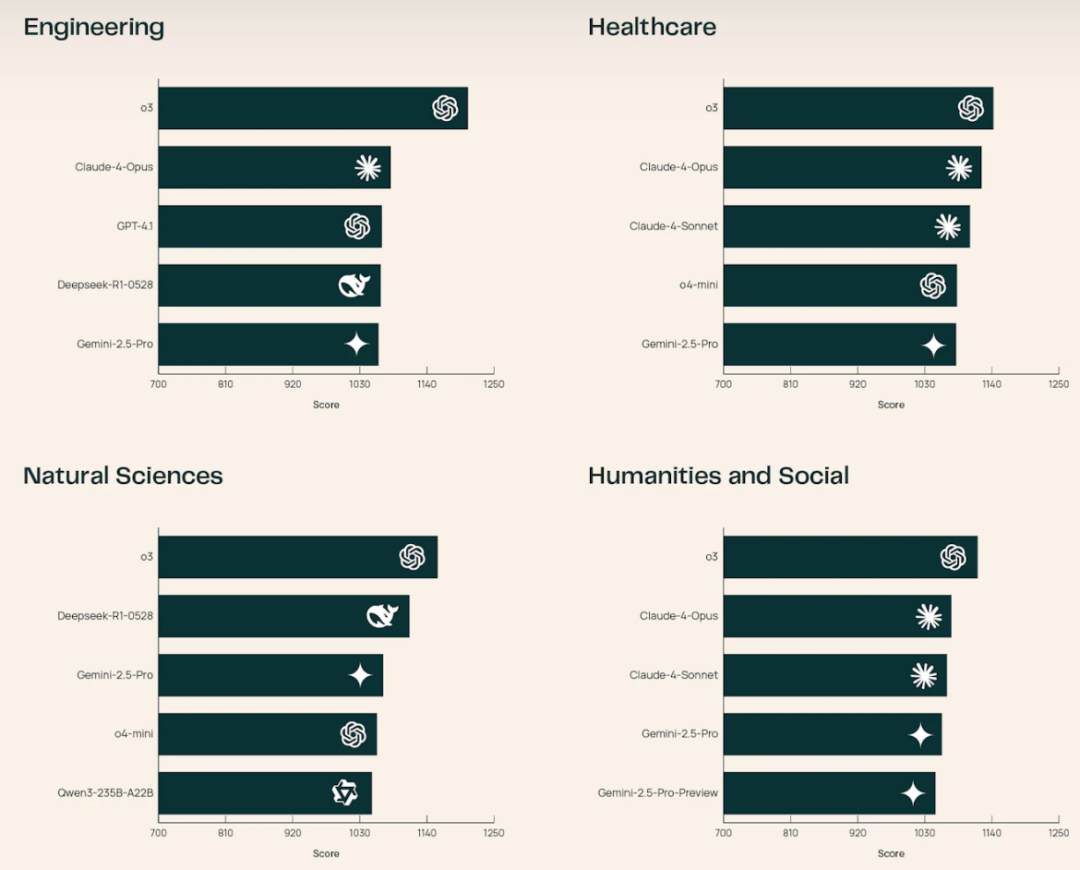
图示:部分排名展示。(来源:SciArena 官网)
Ai2 的研究科学家 Arman Cohan 表示,用户对 o3 的偏好可能源于该模型倾向于提供大量引用文献的细节,并给出技术上细致入微的响应。但解释模型性能差异的原因颇具挑战性,因为大多数模型都是专有的。他表示,训练数据和模型优化目标等差异可能部分解释了这一点。
SciArena 是最新开发的平台,旨在评估 AI 模型在某些任务上的表现,也是首批利用众包反馈对科学任务的表现进行排名的平台之一。澳大利亚国立大学机器人与人工智能研究员 Rahul Shome 表示:「SciArena 是一项积极的尝试,它促使人们认真评估 LLM 辅助的文献任务。」
随机选择
为了对这 23 个 LLM 项目进行排名,SciArena 邀请研究人员提交一些科学问题。研究人员从两个随机选择的模型中获得了答案,这些模型引用了 Semantic Scholar(一款同样由 Ai2 开发的人工智能研究工具)的参考文献,以支持他们的回答。之后,用户投票选出其中一个模型提供了最佳答案,两个模型之间没有太大区别,或者两个模型都表现不佳。
该平台现已向公众开放,用户可免费提出研究问题。所有用户均可获得两个模型的答案,并可对其表现进行投票,但只有经过验证并同意相关条款的用户的投票才会被纳入排行榜。该公司表示,排行榜将定期更新。
澳大利亚悉尼大学人工智能研究员 Jonathan Kummerfeld 表示,能够就科学话题向 LLM 提问,并对答案充满信心,将有助于研究人员掌握其领域的最新文献。「这将帮助研究人员找到他们可能错过的研究成果。」
Kummerfeld 表示,该平台还可以推动人工智能模型的创新,因为排行榜提供了一种透明的进度衡量方式。他补充说,该平台似乎经过精心设计,可以避免用户操纵分数等问题——其他基准测试平台也存在类似的问题。
Kummerfeld 表示,一个潜在问题是该平台对用户参与的依赖。「这些用户付出时间换取使用该工具的权利。」他说道。
「只要他们认为交易划算,它就能成功;但如果他们觉得自己没有获得价值,平台可能难以获得足够的参与。」 Cohan 表示,该平台通过免费提供并包含最新模型来激励用户。此外,Semantic Scholar 提供的参考文献表明,这些回复对研究人员「有用」。
Shome 表示,科学家应该牢记,LLM 撰写的文本可能与被引用的论文存在冲突,可能误解术语,并且可能无法准确回答问题。他补充道,阅读 LLM 撰写的研究论文摘要并不能代替阅读论文。
关于 SciArena
SciArena 是一个开放式评估平台,研究人员可以在此比较和投票评估不同基础模型在科学文献相关任务中的表现。它采用社区投票的方式构建,类似于 Chatbot Arena,但专门针对科学探究的复杂性和开放性进行了定制。
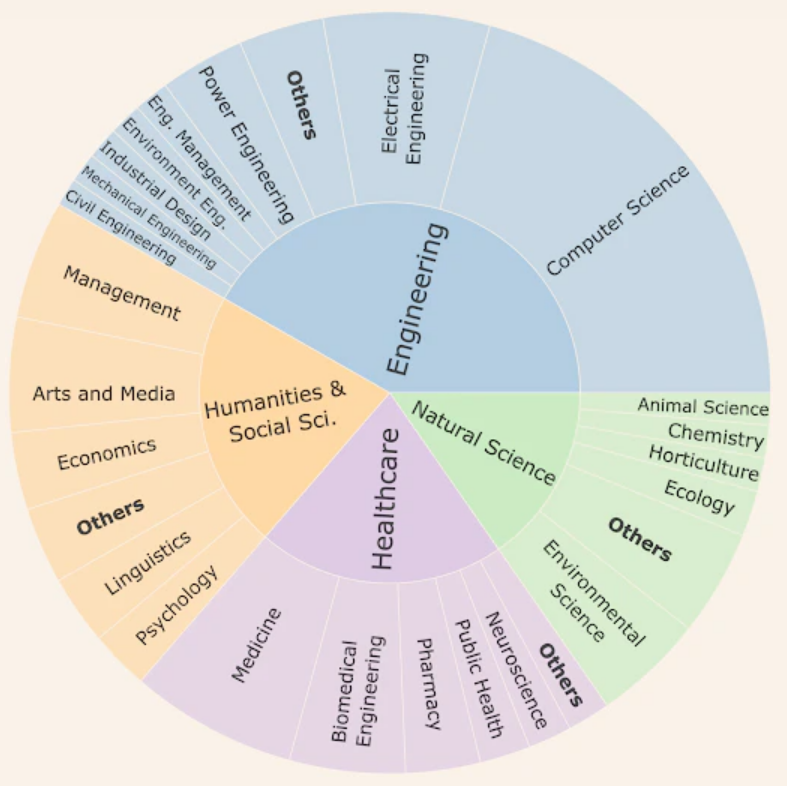
图示:截至 2025 年 6 月 30 日,SciArena 平台收集的人类偏好数据在各个科学学科的分布情况。(来源:SciArena 官网)
该平台由三个主要部分组成:
SciArena 平台:人类研究人员在此提交问题,并排查看来自不同基础模型的答案,并为首选结果投票。
排行榜:基于社区投票,Elo 评分系统对模型进行排名,提供动态且最新的性能评估。
SciArena-Eval:这是一个基于收集的人类偏好数据的元评估基准,旨在评估基于模型的评估系统的准确性。
相关报道:https://www.nature.com/articles/d41586-025-02177-7