传统的大模型开发需要大量的 GPU 资源,以参数量最小的 Llama 2 7B 为例,也需要 14G 显存,而且每一种大模型都有自己的开发接口,这导致普通人很难在自己的本地环境构建大模型、体验大模型。
所以,Ollama 构建了一个开源大模型的仓库,统一了各个大模型的开发接口,让普通开发者可以非常方便地下载,安装和使用各种大模型。
本质上,Ollama 是一套构建和运行大模型的开发框架,它采用的模型量化技术进一步降低了大模型对显存的需求。
模型量化
模型量化 (Model Quantization) 是一种用于减小深度学习模型大小并加快推理速度的技术。简单来说,就是把模型中原本用高精度浮点数(如32位浮点数,FP32)表示的参数(权重和激活值),转换成低精度的定点数(如8位整数,INT8)。
举个简单的例子,一个普通的浮点数就像是用很长的十进制数来表示一个数字,比如 3.1415926535...。而一个整数就像是用一个简单的、没有小数点的数字来表示,比如 3。
在深度学习模型中,大部分参数和计算都需要非常高的精度。但研究发现,在推理阶段,模型并不总是需要这么高的精度。很多时候,我们可以用更小的、更简单的数字来近似表示这些参数,而模型性能(如准确率)的损失却非常小,甚至可以忽略不计。
命令行运行
从 Ollama 官网可以看到,Ollama 已经实现了多平台支持,包括 MacOS,Linux 和 Windows。
 图片
图片
环境是一台 24G 显存的 4090 服务器,你也可以看下自己的配置,显存越高运行越顺畅。
 图片
图片
Linux 环境下安装 Ollama 只需要一个简单的命令行,非常方便。
复制下面是 Ollama 的模型仓库截图,你可以随时切换模型,用 pull 命令就能下载模型。
 图片
图片
接着,你可以使用 ollama run 命令进入对话模式,从命令行运行效果看,我们已经可以将其看做命令行版本的 “GPT 大模型”了。
复制接口 API
我们用 Ollama 的 Python 接口来定制自己的大模型。
这里面有一个 Modelfile,它是 Ollama 大模型的配置文件,你可以修改各种配置,然后运行接口程序。比如我就自己配置了一个基于 Llama2 的大模型,设置了温度,token 数量和系统提示词。
复制然后,创建一个 Modelfile 文件,在 Linux 中运行自定义的大模型。
复制你还可以用 Python 代码调用大模型的接口。
复制好了,有了大模型接口支持,你就可以在 Ollama 框架下编写自己的 AI 应用了。
模型微调
Ollama 也支持大模型微调。假设我们的目标是要实现一个二进制跳动专有小助理的大模型,就可以在 Llama2 的模型基础上做数据微调,最终得到的专用模型还可以在 Ollama 架构下运行。
模型微调的核心是整理小助理相关的问题数据集,比如下面这个数据集的例子。
复制你还可以使用 Hugging Face 的 transformers 库结合上述数据进行微调, 这样就可以让微调后的大模型学习到小助理日常的对话方式和常见的知识问答,下面是示例代码。
复制我把微调完成后生成新的模型命名为 fine_tuned_llama。在此基础上修改 Python 代码里的模型名称,就可以实现小助理专用模型的调用了。
复制什么是多模态大模型?
好了,到目前为止,我们的例子都是文本大模型。但是,我们的目标是实现一个真正的语音小助手,那就还需要进一步了解多模态大模型。
OpenAI 的 GPT-4 已经实现了大模型的多模态,包括图片大模型 DALL-E 3,TTS 语音模型和视频大模型。简单地说,除了文本,还支持其他输入输出格式的就叫多模态大模型。很多人会认为图片,语音,视频大模型的实现和语言大模型完全不一样,其实不然。
多模态的原理
关于多模态大模型的原理,我曾经接受过有一个博主的点醒,他说:多模态模型和语言模型一样本质就是一个序列化模型。因此多模态只是语言大模型的扩展。
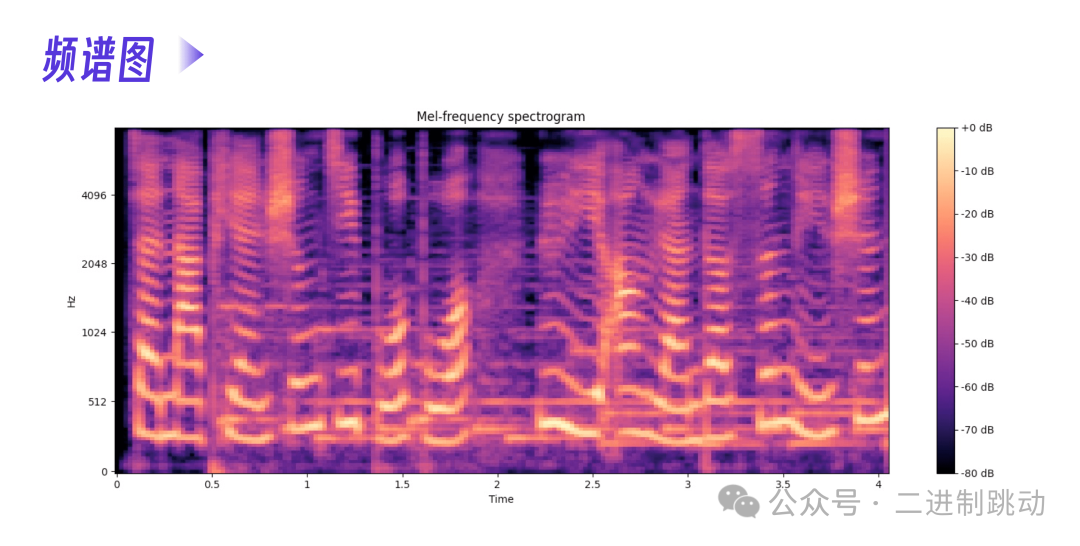
以相对简单的语音模型为例,先看下面的语音频谱图。下面的频谱图展示了音频信号里三个维度的信息。
 图片
图片
- 时间(Time):这是横轴,表示音频随时间的变化而变化。每个时间点对应音频信号的一帧。
- 频率(Frequency):这是纵轴,表示音频信号的频率成分。
- 分贝(dB):这是颜色表示的信息,表示每个时间 - 频率点上的能量强度。这张图右侧的颜色条(colorbar)显示的就是不同颜色对应的分贝值。
我们假设这个音频对应的文本是 极客时间是一个……。从频谱图上,能非常明显地看到时间线的一个颜色条对应一个中文字,不管音频的三个维度怎么表示,我们都可以把这个语音看做和文本一样的序列。
 图片
图片
多模态语音模型也确实可以用 Transformer 架构来训练。只要经过足够的文本 - 语音序列数据训练,大模型就可以准确识别出底层的文本 - 语音数据模式,从而实现文本 - 语音的翻译。
那么图片多模态模型又是怎么实现的呢?其实原理也是相通的。
首先,图像需要被处理成适合 Transformer 输入的格式。通常来说,图像会被分割成小块(patches),每个小块会被展平成一个向量,然后输入到 Transformer 中。以 32 x 32 像素的图像为例,假设我们将图像分割成 4 x 4 的小块(即每个小块包含 8 x 8 个像素),那么整个图像就会被分割成 16 个小块。
 图片
图片
按这种划分方法,一个图像也可以转成一个序列化的串。每一张图加上文本描述,就成为了文字 - 图片的序列串。虽然这样的图片序列化对人来说看不出任何的语义对应关系,但是经过 Transformer 训练之后,大模型就可以学习到文本 - 图片之间的语义关系。
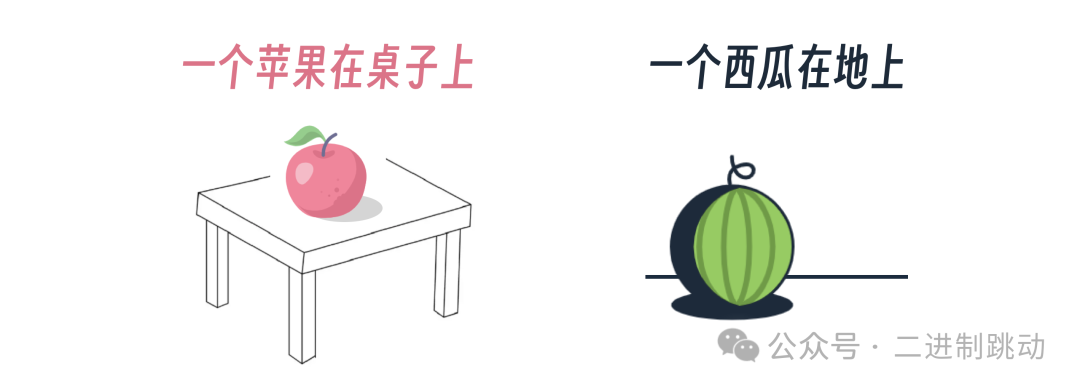
更形象地说,就是让大模型学习大量的对应关系。比如一个苹果在桌子上,一个西瓜在地上。
 图片
图片
最终大模型可以在用户输入 一个苹果在地上 的时候,就能准确地输出这个关系的图像。
 图片
图片
这里的西瓜、苹果、桌子、地面以及上下关系,就是大模型从文本 - 图片序列串中学习到的。
体验 TTS 大模型
要实现一个语音小助手,最核心的能力当然是语音能力,那语音能力如何跟 Ollama 大模型文本能力对接呢?这里就要用到 TTS 技术。
TTS 是 Text-to-Speech 的缩写,指的是文本转语音技术。通过 TTS,用户可以输入文字,让计算机生成自然语音,从而实现语音提示、有声书、语音助手之类的功能。
GPT-SoVITS 就是一个可以实现语音克隆的 TTS 大模型,最大的特点是只需要 5s 左右的语音输入样本,就可以实现语音克隆,之后还可以用我们训练好的模型实现 TTS 文本转语音操作,音色、音调的还原度也很高。
GPT-SoVITS 里的 GPT
GPT-SoVITS 的架构其实就是结合了 GPT (Generative Pre-trained Transformer,生成式预训练变形器)模型和 SoVITS(Speech-to-Video Voice Transformation System)变声器技术。
 图片
图片
的基础还是 Transformer 模型,通过大量的文字 + 语音波形序列化数据训练,得到一个可以完成文字到语音翻译的模型,从而实现 TTS。其实本质还是一个序列化的模型训练。
而音色音调的克隆怎么办呢?答案是,通过 SoVITS 技术实现。GPT-SoVITS 的更进一步技术细节我也还没有来得及分析,不过这个项目给我们最大的启发就是可以在更多的多模态场景下尝试应用 GPT 模型原理,可能会有不少意料之外的效果。
低成本云端环境
GPT-SoVITS 的官方已经提供了一个非常优秀的教程,我按这个教程顺利地搭建了模型并克隆了自己的声音。
我选用的是 AutoDL 云计算环境。注意选用一个 GPT-SoVITS 的镜像创建主机,下面是我具体的主机配置。
 图片
图片
下面是我选用的具体镜像信息。
 图片
图片
AutoDL 云计算的成本大约在 2 元 / 小时左右,整个训练过程我花了不到 10 元,还是非常经济的,购买了主机之后,可以进入 GPT-SoVITS 的界面,所有的后续训练操作都在这个界面上完成。
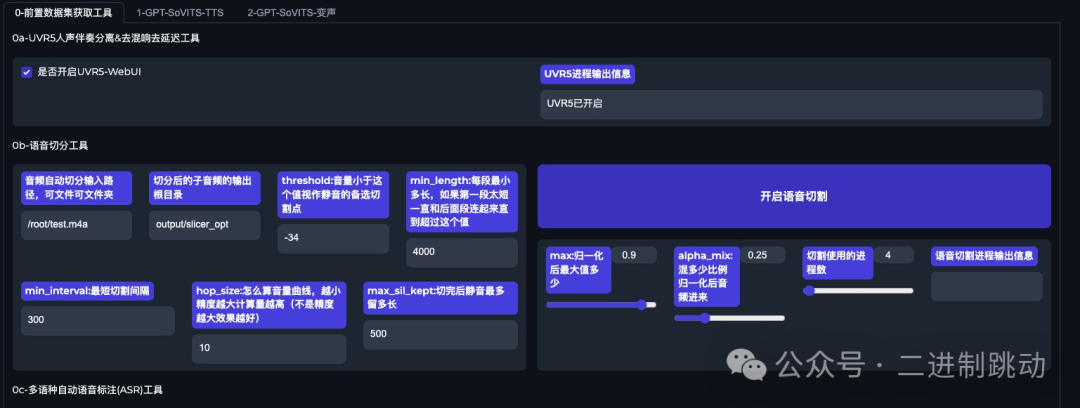 图片
图片
正式开始训练前需要录制一小段自己的语音,用于克隆训练。
低成本语音克隆
整个过程分为语音分割,模型训练,语音合成这三个步骤。
刚才说了,先准备自己的录音文件,我的语音文本如下。
复制第一步,将这个录制语音提取出纯人声的音频,再进行分割,按一定秒数分割成语音文件,最后对语音做文本识别。这个过程的目的就是生成文本 - 语音的序列数据,为下一步的微调做数据准备。
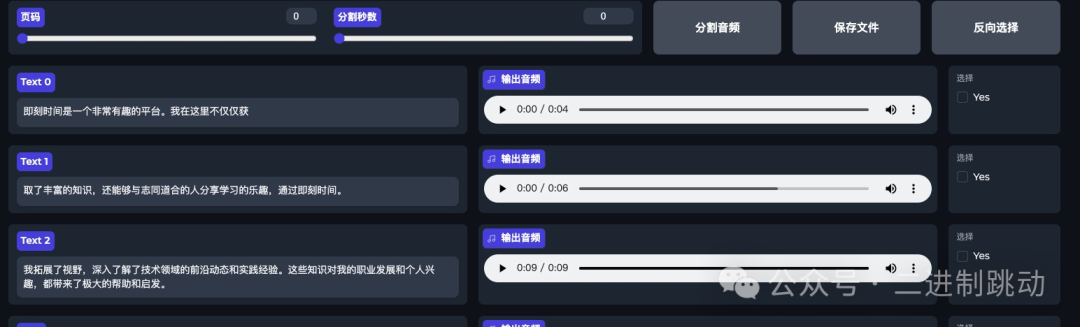 图片
图片
第二步,在刚才准备的文本和语音数据基础上,微调 GPT-SoVITS 训练自己的 TTS 模型。这里你可以自由发挥,直接在界面上操作,过程比我想象得要快很多,大概不到 10 分钟。
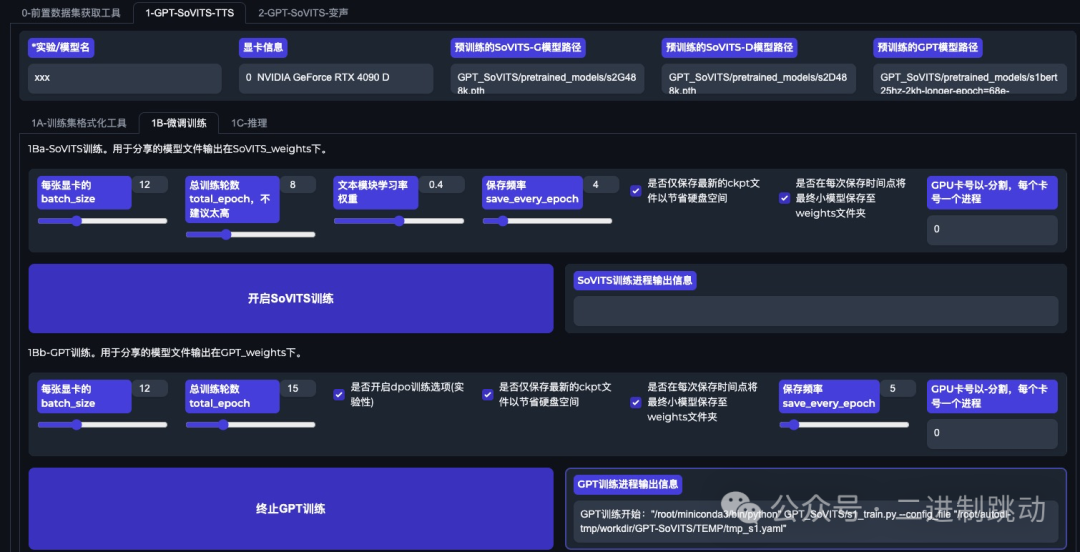 图片
图片
OK,现在已经生成了经过微调的 TTS 模型,可以做 TTS 文本合成语音了,而且你也可以直接将这个模型分享给别人。
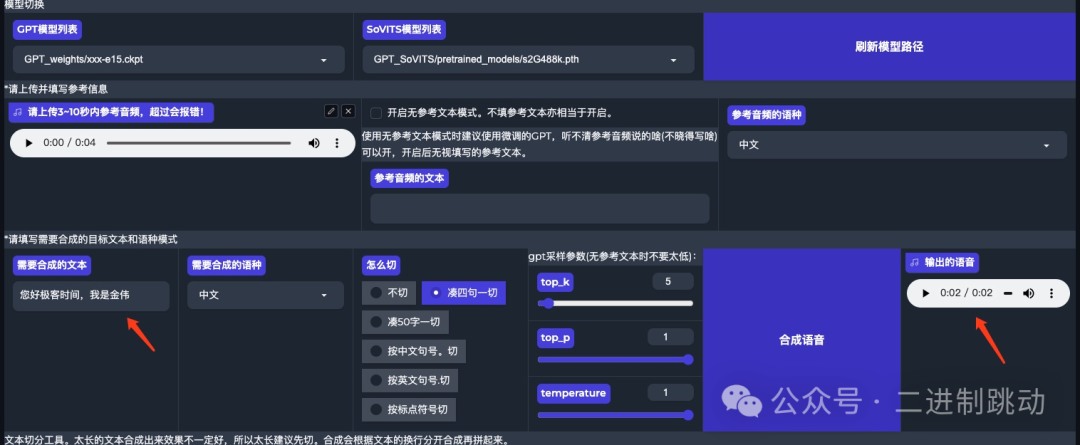 图片
图片
现在,用这个文本生成的语音已经完全克隆了我的声音,复刻了音色、音调和语速。你也可以用自己的真实声音训练出一个用于实现语音助手的专有 TTS 语音大模型。


