资讯列表

“AI 教父”等发布联名公开信: OpenAI 重组背离初衷,呼吁监管介入
前 OpenAI 员工、研究人员及非营利组织联名发表公开信,强烈呼吁监管机构阻止 OpenAI 提出的公司重组计划。

Anthropic 示警:Claude 等 AI 被滥用,引导舆论威胁公众认知
Anthropic 昨日(4 月 23 日)发布博文,报告称 Claude 等前沿 AI 模型正被恶意行为者滥用,涉及“舆论引导服务”(influence-as-a-service)操作、凭证填充、招聘诈骗及恶意软件开发等活动。

智谱宣布旗下多款大模型产品降价 其中GLM-4-Plus降价90%
4月24日,智谱BigModel开放平台宣布进入“亿时代”,对旗下多款大模型产品进行价格调整,大幅降低使用门槛,让更多的企业能够以极低成本拥抱大模型技术。 智谱BigModel开放平台此次价格调整涉及多个模型产品。 其中,GLM-4-FlashX模型每亿tokens的价格仅为10元,该模型基于强大的预训练基座,具有超快的推理速度,功能调用能力与GPT-4相当,在数据抽取、生成、翻译等方面表现出色。

全球首个集成大模型开发框架的区块链虚拟机正式开源
4 月 24 日,一款名为 DTVM(DeTerministic Virtual Machine)的区块链虚拟机宣布开源,在开发者社区引发热议。 据其公开的技术论文显示,DTVM通过创新JIT引擎与全链路优化,IT引擎加速较传统解释执行实现约30倍的性能提升,刷新了目前行业最高水平,同时完全兼容以太坊生态,成为技术新标杆。 区块链虚拟机是运行在区块链网络上的一个特殊计算环境,用于处理大量的计算和交易指令,是智能合约和区块链应用(DApp)的“操作系统”。

首届具身智能机器人运动会启动,宇树机器人携舞蹈与竞速项目参赛
首届具身智能机器人运动会将在无锡市盛大举行。 作为重要参赛队伍之一,宇树科技将与来自全国各地的机器人企业同台竞技,参与激烈的竞速跑比赛以及精彩的舞蹈表演环节。 截至目前,已有100多家相关企业报名参赛,来自北京、上海、深圳、西安、重庆等地的顶尖机器人公司将参与竞速跑项目,宇树机器人将在这一项目中与国家地方共建具身智能机器人创新中心(北京)、人形机器人创新中心(上海)等知名机构展开激烈竞争。
JSON Visuals for ChatGPT发布,解锁无限图像风格创作
JSON Visuals for ChatGPT正式发布,为ChatGPT的图像生成能力注入全新创意维度。 据AIbase了解,这一工具提供超过50种独特的美学代码,结合属性随机化器,可生成无限风格组合,用户只需输入图像与JSON风格代码即可创作个性化视觉内容。 发布消息在社交平台引发热烈反响,社区尤其推崇其荒诞科技风格。

挑战第一方 Siri:Perplexity 在苹果 iOS 平台推出 AI 语音助手
这一 AI 助手可通过网页浏览和多应用操作来执行用户语音中想要的操作,包括自动的地图搜索、餐厅预订、电子邮件草拟、提醒设置和媒体播放。

大模型向量去重的N种解决方案!
简单来说,“向量”Vector 是大模型(LLM)在搜索时使用的一种“技术手段”,通过向量比对,大模型能找出问题的相关答案,并且进行智能回答。 向量简介Vector 是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。 “定义:向量是用于表示具有大小和方向的量。
Google AI推出Mobility AI计划,赋能智能交通管理新未来
Google AI宣布推出Mobility AI计划,旨在为全球交通运输机构提供数据驱动的决策支持、交通管理和城市交通系统持续监控工具。 据AIbase了解,该计划利用人工智能在测量、模拟和优化领域的最新进展,助力城市实现更安全、高效和可持续的交通网络。 计划详情已通过Google AI官方渠道公布,引发了智能交通领域的高度关注。

Meta Ray-Ban智能眼镜全面推送实时翻译功能,支持离线使用
Meta公司近日宣布,其Ray-Ban Meta智能眼镜的实时翻译功能已正式向全球用户开放。 此前,这一功能仅限于部分市场的早期测试用户。 此次全面推出意味着用户可以在多种场景下,享受到更加便捷的语言转换体验,尤其是能够在无网络的环境下,突破语言障碍。
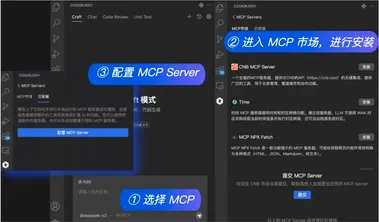
腾讯云代码助手CodeBuddy推出Craft软件开发智能体 支持MCP协议
4月24日,腾讯云宣布其代码助手CodeBuddy全新升级,推出Craft软件开发智能体,这一创新工具将AI编程从“补全代码”进化为“交付项目”,极大地提升了软件开发效率。 据腾讯云介绍,使用Craft智能体的开发者平均编码时间缩短了超过40%,AI生成代码的占比超过40%,研发效率提升超过16%。 在过去,开发一个完整的应用程序需要多个团队协作,包括前端、后端、测试和运维等,流程复杂且耗时。
Firefox实验室推出新功能:按住Shift+Alt即可预览链接内容
Mozilla近期在Firefox实验室推出了一项新功能——“链接预览”。 这一功能的引入,旨在通过简单的鼠标操作,让用户在不打开新页面的情况下,快速了解链接的内容,从而提升浏览体验。 当用户启用该功能后,只需按住Shift和Alt键并将鼠标悬停在任意链接上,系统便会弹出一个预览卡片。
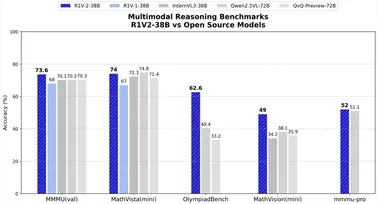
昆仑万维开源Skywork-R1V 2.0版本 视觉与文本推理能力提升
4月24日,昆仑万维宣布正式开源其多模态推理模型Skywork-R1V2.0(以下简称R1V2.0)。 这一升级版本在视觉与文本推理能力上均实现了显著提升,特别是在高考理科难题的深度推理和通用任务场景中表现出色,堪称当前最均衡兼顾视觉与文本推理能力的开源多模态模型。 R1V2.0的开源,不仅是昆仑万维在多模态领域技术实力的体现,也为全球开发者和研究者提供了强大的工具,推动多模态生态建设。

纳米AI发布MCP万能工具箱,简化AI工具集成与调用
纳米AI正式发布MCP万能工具箱(MCP Universal Toolbox),一款旨在解决Model Context Protocol(MCP)配置复杂性的一站式解决方案。 据AIbase了解,该工具箱预配置了100多个MCP服务,内置18个常用API密钥,支持高德地图、MiniMax图像生成、音频生成和视频生成等功能,用户可通过简单调用实现复杂任务自动化。 这一创新工具的发布引发了AI开发者社区的广泛关注,相关细节已通过纳米AI官网与社交平台公开。

刚刚,OpenAI最强图像生成API上线,一张图1毛5!
昨夜,OpenAI发布全新图像生成模型gpt-image-1,API向所有开发者开放。 这一次,他们直接把每张图的成本打到几美分。 图片对于低、中、高质量的方形图像,生成大约花费0.02美元、0.07美元、0.19美元。

LLM 推理引擎之争:Ollama or vLLM ?
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活的计算架构的模型推理框架。 在人工智能领域,模型的推理能力是衡量其性能的核心指标之一,直接影响其在复杂任务中的表现。 随着自然语言处理(NLP)和大规模语言模型(LLM)技术的迅猛发展,众多创新模型不断涌现,为开发者提供了多样化的选择。

颠覆传统!海螺集团联手华为发布水泥建材业首个AI大模型,赋能产业智能化升级
近日,一场引领水泥建材行业变革的技术发布会吸引了业界的广泛关注。 国内领先的水泥制造商海螺集团携手科技巨头华为,共同揭开了行业内首个人工智能大模型的神秘面纱。 这不仅仅是一次简单的技术应用,更是对传统生产模式的一次深度革新。

香港与英国研究团队提出创新图像标记化方法 分层结构提升重建质量
一组来自香港和英国的研究人员近日提出了一种新型图像标记化方法,旨在以更紧凑、更精确的方式将图像转换为数字表示(即令牌)。 与传统方法将信息均匀分布于所有标记中不同,该方法采用分层结构,逐层捕捉视觉信息,从而提升了图像重建的质量和效率。 传统的图像标记化技术通常会将图像的每个部分均等地划分为多个标记,而新方法则采取了分层结构。