资讯列表
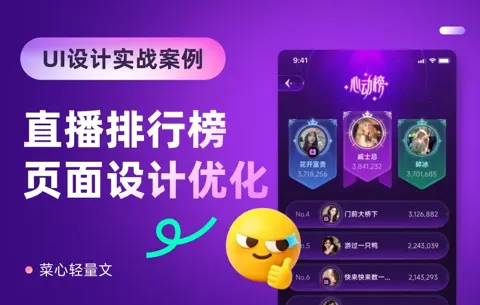
这么普通的界面,我居然做出了设计感!
往期干货:这次的案例是直播排行榜页面,客户的要求是要更具设计感,来看看优化前:再来看看优化后:接下来,我们一一拆解优化方向。 一、拉开等级. 在这个案例中,我们可以根据整体的“梦幻”主题找一些视觉元素,比如魔法阵、皇冠、金镶边,和旗帜等:第 1 步:增加前三名的设计感.

从视频一键提取某个声音:Meta 发布 SAM Audio,多模态音频分离新突破
AI在线 12 月 17 日消息,Meta 今日发布了首个统一的多模态音频分离模型 —— SAM Audio。 Meta 表示 SAM Audio 是一个“最先进的统一模型”,通过使用自然的、多模态的提示,使音频处理变得简单,能够轻松地从复杂的音频混合中分离出任何声音 —— 无论是通过文本、视觉提示还是时间段标记。 这种直观的方法模拟了人们自然与声音互动的方式,使音频分离更加易于使用和实用。

全球首个:具身智能机器人在宁德时代电池产线“上岗打工”,实现规模化落地
AI在线 12 月 17 日消息,宁德时代今日官宣,全球首条实现人形具身智能机器人规模化落地的新能源动力电池 PACK 生产线,在宁德时代中州基地正式投入运行。 人形机器人“小墨”已能精准完成电池接插件插接等复杂作业,标志着具身智能在智能制造领域的应用取得突破。 AI在线从宁德时代公告获悉,“小墨”所替代的 EOL 与 DCR 工序,是电池包下线前的最终功能测试。

网易有道宣布战略升级,从“教育科技公司”迈向 “学习与广告 AI 应用服务提供商”
AI在线 12 月 17 日消息,网易有道 2025 年度股东大会于 12 月 16 日举行,宣布公司战略升级:从“教育科技公司”迈向“学习与广告 AI 应用服务提供商”。 网易有道 CEO 周枫表示,今年前三季度,有道累计净收入 43.4 亿元,同比增长 1.4%。 在业务增长的基础上,包括销售费用、管理费用在内的运营费用同比下降,带动了经营利润提升至 1.6 亿元,同比增长 149.2%。

美的医疗发布国产医学影像大模型:胸部DR病种“一键诊断”,双量级架构兼顾端云部署
美的集团加速AI医疗布局。 旗下美的医疗近日正式推出具备完全自主知识产权的“医学影像多模态智能诊断大模型”,标志着其在智慧医疗核心赛道实现关键突破。 该模型目前已实现对肺结核、肺炎、气胸、骨折等常见胸部疾病的一次性自动检测,并能自动生成结构化诊断报告,大幅提升基层医疗机构的阅片效率与诊断一致性。

DeepMind CEO 哈萨比斯警示:初创公司高估值助长 AI 泡沫
谷歌 DeepMind 联合创始人兼 CEO 德米斯・哈萨比斯近日在《Google DeepMind:The Podcast》节目中发出警告,指出当前 AI 创业环境中正在形成泡沫现象。 他强调,许多早期初创公司在尚未真正展开业务的情况下,竟以数百亿美元的天价估值进行融资,这种现象并不具备可持续性。 哈萨比斯提到,与大型科技公司的融资模式应有所区别。

腾讯大模型架构重磅升级:成立 AI Infra 与 Data 部门,构建大模型训练推理全链路竞争力
腾讯近日宣布对其大模型研发架构进行战略性调整,通过成立 AI Infra部、AI Data部及数据计算平台部,全面强化大模型的核心研发体系。 据 AIbase 报道,此次升级旨在构建从底层算力基础设施到高质量数据处理的全链路竞争力,为大模型的高效迭代与业务落地提供强力支撑。 在核心人事任命上,Vincesyao 正式出任“CEO/总裁办公室”首席 AI 科学家,直接向腾讯总裁刘炽平汇报;同时,他还兼任 AI Infra 部及大语言模型部负责人,向技术工程事业群总裁卢山汇报。

OpenAI拟融资100亿美元牵手亚马逊,Trainium3芯片或成英伟达之外关键算力选项
OpenAI正与亚马逊展开一项可能重塑AI算力格局的深度合作。 据《The Information》报道,OpenAI正在谈判从亚马逊获得至少 100 亿美元融资,并考虑在其训练基础设施中引入亚马逊自研AI芯片 Trainium,以实现算力供应链的多元化。 若交易落地,这将是亚马逊Trainium芯片迄今获得的最具分量的外部客户。

50万AI应用上线、撬动50亿价值!“秒哒”掀起全民开发潮,石油工程师、琴行老板变身AI创业者
一场由AI驱动的全民开发革命正在悄然爆发。 最新数据显示,超50万个AI生成的商业应用已成功上线,覆盖教育、文旅、能源、文娱等200多个细分领域,累计服务用户突破1000万,创造经济与效率价值超50亿元。 而这股浪潮的核心推手,是一款名为“秒哒”的低门槛AI开发平台——它让“零代码、零成本、零部署”的应用创作成为现实。

亚马逊洽谈投资超100亿美元入股 OpenAI
近日,亚马逊正在与人工智能初创公司 OpenAI 进行谈判,计划投资超过100亿美元。 这项交易可能会将 OpenAI 的估值推高至5000亿美元以上,同时,OpenAI 也将可能利用亚马逊的云计算服务及其芯片技术。 OpenAI 近年来在人工智能领域取得了显著的成就,其开发的语言模型和图像生成技术引起了广泛关注。

消息称亚马逊讨论对 OpenAI 投资逾百亿美元,后者也有意 AWS 芯片
AI在线 12 月 17 日消息,参考外媒《The Information》报道,亚马逊与 OpenAI 正就一系列合作事宜展开谈判交涉。 亚马逊有意以超过 5000 亿美元的估值向 OpenAI 投资不少于 100 亿美元(AI在线注:现汇率约合 704.87 亿元人民币);OpenAI 有意在其算力组合中添加亚马逊 AWS 的 Tranium 系列 AI 芯片;双方还在讨论其它商业合作机会。 相关阅读:《OpenAI 与亚马逊签署 380 亿美元算力采购协议,进一步减少对微软依赖》

摩尔线程算法一鸣惊人,图形学顶会夺银!已开源
允中 发自 凹非寺. 量子位 | 公众号 QbitAI12月17日,在香港举办的全球图形学领域备受瞩目的顶级学术盛会SIGGRAPH Asia 2025上,摩尔线程在3D Gaussian Splatting Reconstruction Challenge(3DGS重建挑战赛)中凭借自研技术LiteGS出色的算法实力和软硬件协同优化能力,斩获大赛银奖。 这再次证明了,摩尔线程在新一代图形渲染技术上的深度积累与学术界的高度认可。

官宣!姚顺雨出任腾讯首席AI科学家,带队大语言模型、AI Infra
不久之前,OpenAI 著名研究者、清华校友、著名博客《AI 下半场》的作者姚顺雨加入腾讯的消息传得沸沸扬扬,点燃了 AI 社区。 (参见:姚顺雨离职 OpenAI,「亿元入职腾讯」传闻引爆 AI 圈,鹅厂辟谣了)今日,靴子落地。 刚刚,机器之心获悉 ,腾讯升级大模型研发架构,新成立 AI Infra 部、AI Data 部、数据计算平台部,全面强化其大模型的研发体系与核心能力。

分割一切、3D重建一切还不够,Meta开源SAM Audio分割一切声音
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。 深夜,Meta 放出音频分割模型 SAM Audio,其通过多模态提示(无论是文本、视觉,还是标注时间片段),让人们能够轻松地从复杂的音频混合中分离出任意声音,从而彻底改变音频处理方式。 SAM Audio 的核心是 Perception Encoder Audiovisual(PE-AV),这是推动其实现业界领先性能的技术引擎。

消息称腾讯大模型团队架构调整:前 OpenAI 研究员姚顺雨任要职,校招最高 2 倍薪资挖 AI 人才
AI在线 12 月 17 日消息,据 36 氪今日报道,腾讯近期完成了一次组织调整,正式新成立 AI Infra 部、AI Data 部、数据计算平台部。 12 月 17 日下午发布的内部公告中,腾讯表示,Vinces Yao 将出任“CEO / 总裁办公室”首席 AI 科学家,向腾讯总裁刘炽平汇报;他同时兼任 AI Infra 部、大语言模型部负责人,向技术工程事业群总裁卢山汇报。 报道称,Vinces Yao 即为数月前入职腾讯的姚顺雨,他毕业于清华和普林斯顿大学,曾任 OpenAI 研究员,是 OpenAI 首批智能体产品 Operator 与 Deep Research 的核心贡献者。

Meta 授权员工使用竞争对手 AI 工具,提升工作效率
近日,Meta 宣布将扩大员工对谷歌和 OpenAI 等竞争对手人工智能工具的使用权限,力求在公司的工作流程中更加广泛地融入人工智能技术。 根据 Business Insider 的报道,Meta 已鼓励员工使用多种先进的 AI 工具,如 ChatGPT-5和 Gemini3Pro,以提升工作效率和创造更大价值。 Meta 首席信息官阿蒂什・班纳吉在一份内部备忘录中指出,公司的首要任务之一就是将人工智能融入日常工作中。

AI 科学研究新基准:FrontierScience 评估模型推理能力
在科学研究中,推理能力至关重要。 科学家们不仅仅是回忆事实,还需提出假设、测试并修正这些假设,并在不同领域之间综合思想。 随着 AI 模型能力的提升,如何评估它们在科学研究中深度推理的能力成为了一个重要问题。

Meta全面拥抱竞品AI:员工可自由调用ChatGPT-5、Gemini 3 Pro,甚至用Midjourney画图
在“AI优先”战略的驱动下,Meta正彻底打破技术阵营壁垒——这家曾以Llama开源模型为傲的社交巨头,如今不仅允许员工广泛使用谷歌、OpenAI、Anthropic等竞争对手的AI工具,更将之深度融入日常办公全流程,从编码、写作到设计、决策,无一例外。 据Business Insider披露的内部文件,Meta员工目前已可合法调用包括OpenAI的ChatGPT-5、谷歌的Gemini 3 Pro、Anthropic的Claude(通过内部编程工具Devmate)等顶级外部模型。 6 月,首席信息官阿蒂什·班纳吉在全员备忘录中明确表示:“让AI成为我们工作方式的核心”是公司首要任务之一,并强调“不拘泥于自研技术,而是聚焦实际成效”。