资讯列表

AI的数据饥渴如何重塑企业对存储的需求
AI工作负载正从根本上重塑企业技术基础设施,市场预测凸显了这一变化的显著程度。 麦肯锡指出,AI已成为“数据中心容量需求增长的关键驱动力”,预计到2030年,整体需求将“几乎增长两倍,其中约70%的需求来自AI工作负载”。 事实上,世界经济论坛预计,目前全球数据中心产业价值为2427亿美元,到2032年将增长一倍多,达到约5840亿美元。

AI 编程指南!4个章节详解Figma看板插件开发过程
嗨,我是范米花儿,好久不见。 最近在梳理作品集,整理到 Figma 看板生成插件开发相关的内容。 之前插件发布时,不少朋友问过有没有相关教程,而且自年初发了 Cursor 还原教程后,我就没再更新过内容,也常收到小伙伴的催更。

2025 AI Agent 元年:你还在用 AI 聊天,别人已靠“智能体”成为“超级个体”
最近,我和朋友聊 AI 时,找到了一个共识:虽然,现在大家生活在同一个世界。 但,却活在不同的时代。 图片现在,很多人还在用传统的方式(你不用或很少用 AI)来解决问题,AI 没有产生什么帮助。

重新定义AI编程协作:深入解析Claude Code多智能体系统架构
引言:站在AI编程的十字路口2025年的软件开发领域正经历着一场静悄悄的革命。 如果你还停留在"AI只能写写简单代码"的认知层面,那么你即将错过这个时代最激动人心的技术突破。 今天,我们要深入探讨的Claude Code Agents系统,不仅仅是一个代码生成工具——它是一个由84个专业智能体、15个工作流编排器和42个开发工具组成的完整生产级多智能体协作系统。

一文读懂AI应用上下文工程(Context Engineering)
或许你已是一名AI应用提示工程高手,但随着对话的推进,你的聊天机器人常常会忘记你最初且最重要的指令内容,你的代码助手会丢失项目架构的线索,而你的检索增强生成(RAG)工具无法在复杂文档与不同领域间建立信息关联。 随着AI应用场景日益复杂,编写精妙的提示词只是更大挑战中的一小部分——这个挑战就是上下文工程。 在本指南中,我将阐释什么是上下文工程、它如何运作、何时应替代常规提示工程使用它,以及能让AI系统更智能、更具上下文感知能力的实用技巧。

深层网络通过分层抽象能够学习到更复杂的特征表示,从而提升模型对复杂数据的建模能力
神经网络层数越多效果越好这一观点,在特定条件下成立,其核心逻辑在于深层网络通过分层抽象能够学习到更复杂的特征表示,从而提升模型对复杂数据的建模能力。 图片理论机制:分层抽象与特征表示能力增强特征抽象的层次化神经网络通过堆叠层数实现特征的逐层抽象。 以图像识别为例:底层:学习边缘、纹理等简单特征(如卷积核检测水平/垂直边缘);中层:组合底层特征形成形状、部件(如检测车轮、车窗);高层:整合中层特征构成完整对象(如识别整辆汽车)。

思考不是免费的,大型语言模型推理的收益与代价
对于人工智能智能体,谈判是一场最接近人类智慧的“角斗”,它不仅仅是语言的堆砌,更是策略的博弈、心理的揣摩和利益的权衡。 人类社会和经济活动中,谈判无处不在,从商场里的价格讨价还价,到国际政治的桌面博弈,都是智慧与策略的交锋。 对于AI代理来说,能否在谈判中表现出色,直接决定了它们能否真正走向自主决策的未来。

让AI说"人话":TypeChat.NET如何用强类型驯服大语言模型的"野性"
引言:当AI开始"听懂人话"时发生了什么? 想象一下这样的场景:你走进咖啡厅,对着智能点餐系统说:"来杯大杯拿铁,少糖,加燕麦奶,要热的。 "系统不仅准确理解了你的需求,还把订单转换成了结构化数据——饮品类型、尺寸、温度、配料,一个都没落下。

官宣定档11月13日!百度世界2025将于北京举办
10月13日,百度官方公众号宣布,百度世界2025将于11月13日在北京·国家会议中心二期举办,大会官网()现已开启售票通道。 作为百度一年一度最重要的技术和产品发布会,本届百度世界或将全面展示百度在AI应用、大模型、AI生态、出海等方面的最新进展。 据悉,百度世界2025以「效果涌现|AI in Action」为主题,设置1 6场顶尖论坛。

网约车元老入局自动驾驶:川大校友,前滴滴SVP
出行领域大牛,加盟车联网明星。 智能车参考获悉,前滴滴高级副总裁付强已出任蘑菇车联首任总裁,负责公司AI业务和商业化落地。 蘑菇车联专注于车路云一体化赛道,是在车路协同方向上探索Robotaxi的玩家之一,此前开发了路侧基站、云端智慧平台、Robobus等多项产品,打造了交通大模型MogoMind。

大模型赋能文化遗产数字化:古籍修复与知识挖掘的技术实践
在文化遗产数字化领域,大模型的核心应用难点在于如何处理古籍中大量的异体字、残缺文本与模糊语义,尤其是面对明清时期的手写残卷,传统的文字识别技术不仅准确率低下,更无法理解古籍中蕴含的历史语境与专业术语。 我在参与某博物馆古籍数字化项目时,首先遭遇的便是大模型对古籍文字的“识别盲区”—初期使用通用大模型识别一本明代医学残卷,发现其将“癥瘕”误判为“症痕”,把“炮制”错解为“泡制”,更无法关联“君臣佐使”等中医方剂配伍逻辑,导致提取的知识完全偏离原意。 为解决这一困境,我没有直接进行模型微调,而是先搭建“古籍文字与语境知识库”:通过整理《说文解字》《康熙字典》等权威字书,以及近现代古籍整理学术成果,构建包含5000 异体字、通假字的对照词典,每个文字标注字形演变、常见语境与释义差异;同时,针对医学、天文、历法等专业领域古籍,收集对应的行业术语库,标注术语的历史用法与现代对应概念(如“勾陈”对应天文领域的“小熊座”)。

推理速度10倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架dInfer
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。 在基准测试中,dInfer 将 dLLM 的推理速度相比于 Fast-dLLM 提升了 10 倍以上,并在关键的单批次(batch size=1)推理场景下,作为首个开源框架实现了大幅超越经过高度优化的自回归(AR)模型的性能里程碑,在 HumanEval 上达到 1011 tokens / 秒的吞吐量 。 dInfer 通过一系列算法与系统协同创新,攻克了 dLLM 的推理瓶颈,兑现了其内生并行生成带来的推理效率潜力。

蘑菇车联加速AI商业化 前滴滴高管付强加盟任总裁
近日,智能交通与AI基础设施公司蘑菇车联发布内部公开信,宣布重大人事任命:原滴滴高级副总裁付强正式加入公司,出任总裁一职。 他将全面负责蘑菇车联AI业务的战略落地与商业化布局。 付强在智能出行领域拥有超过十年的丰富经验。

OpenAI 与微软达成重磅交易:股权结构再变,投资者面临稀释风险
《金融时报》报道了 OpenAI 近期一系列重要交易,这些交易让公司的股权结构变得更加复杂,也令投资者对于未来的回报更加不确定。 根据这些交易,OpenAI 成为了全球最有价值的非上市公司,估值高达5000亿美元。 这一成果主要得益于与芯片制造商英伟达和 AMD 签订的数十亿美元合同,这些资金将助力 OpenAI 在未来几年实现部署1万亿美元算力的目标。

OpenAI联手阿根廷,投资250亿美元打造超级数据中心
近日,OpenAI 与阿根廷能源公司 Sur Energy 签署了一项意向书,计划在阿根廷投资高达250亿美元,建设一个规模庞大的数据中心。 这一项目不仅是阿根廷历史上最大的信息技术和能源基础设施项目之一,还将为该国的科技发展注入新的动力。 根据协议,这座数据中心将具备500兆瓦的计算能力,专门支持先进的人工智能计算。
Perplexity CEO 宣布告别 PPT,借助 AI 实现投资者路演新模式
在人工智能技术不断发展的今天,许多传统商业活动也在悄然发生变化。 近日,AI 搜索工具 Perplexity 的联合创始人兼 CEO 阿拉文德・斯里尼瓦斯在伯克利哈斯商学院的采访中表示,他已经放弃了传统的融资演示文稿(PPT),转而使用人工智能来完成投资者路演。 图源备注:图片由AI生成,图片授权服务商Midjourney斯里尼瓦斯提到,自己在 A 轮融资时仅制作了一次路演幻灯片,而之后的融资活动都依赖于 AI 的协助。

马来西亚迎来 AI 新纪元,ChatGPT Go 助力数字化转型
近日,OpenAI 在马来西亚推出了全新的 ChatGPT Go 订阅服务,月费仅为38.99马币(约9.25美元),大幅降低了 AI 高级功能的使用门槛。 此次推出的 ChatGPT Go 不仅包括了最新的 GPT-5模型,还提供了丰富的功能,如图片生成、文件上传及记忆功能,极大地提升了用户的体验。 这一举措正值马来西亚 AI 用户数量在过去一年中激增的背景下进行,OpenAI 希望通过更亲民的价格吸引中端用户和学生,进而扩展用户基础。
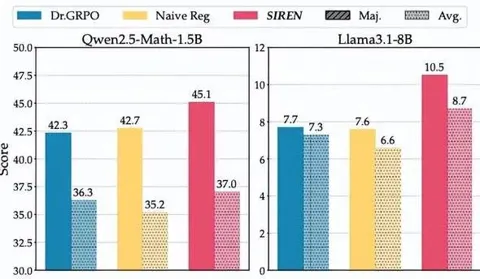
拒绝“熵崩塌”和“熵爆炸”!这项研究让大模型推理成绩飙升
大语言模型在RLVR训练中面临的“熵困境”,有解了! 2024年以来,以OpenAI o1、DeepSeek-R1、Kimi K1、Qwen3等为代表的大模型,在数学、代码和科学推理任务上取得了显著突破。 这些进展很大程度上得益于一种名为RLVR (基于可验证奖励的强化学习)的方法。