
近年来,以 OpenAI-o1、Qwen3、DeepSeek-R1 为代表的大型推理模型(LRMs)在复杂推理任务上取得了惊人进展,它们能够像人类一样进行长链条的思考、反思和探索。然而,这些模型在面对精确的数学计算时,仍然会「心有余而力不足」,常常出现效率低下甚至算错的问题。
一个直观的解决方案,是为模型配备代码解释器(Code Interpreter)等计算工具。但这引入了一个更深层次的挑战,也是当前领域面临的关键瓶颈:
认知冲突:模型内部基于概率的、模糊的「思考」,与外部工具返回的确定性的、精确的「知识」之间存在冲突,导致模型陷入无意义的反复验证和「纠结」。
行为低效:模型倾向于先用自然语言进行冗长的推演,再用代码验证,造成「延迟计算」;或者不信任代码返回的结果,进行不必要的「结果不信任」和手动核算,白白浪费了大量计算资源(tokens)。
数据稀缺:如何为这种新型的「模型 - 工具」协同推理模式,合成高质量的训练数据,本身就是一个开放性难题。
那么,如何让大模型学会「何时」以及「如何」高效地使用工具,将自身的抽象推理能力与工具的精确计算能力完美结合?
来自中国科学技术大学、香港中文大学(深圳)、通义千问的联合研究团队给出了他们的答案:CoRT (Code-Optimized Reasoning Training) —— 一个旨在教会大型语言模型高效利用代码工具进行推理的后训练(post-training)框架。该框架通过创新的数据合成策略和多阶段训练流程,显著提升了模型的数学推理能力和效率。
目前,该论文已被 NeurIPS 2025 接收,相关模型和代码均已开源。

论文链接:https://arxiv.org/abs/2510.20342
项目仓库:https://github.com/ChengpengLi1003/CoRT
方法核心:从「数据冷启动」到「智能体调优」的三步走
CoRT 框架的核心思想是,通过高质量的数据和精细化的训练,重塑模型与工具的交互模式,使其从低效的「验证」思维转向高效的「计算」思维。
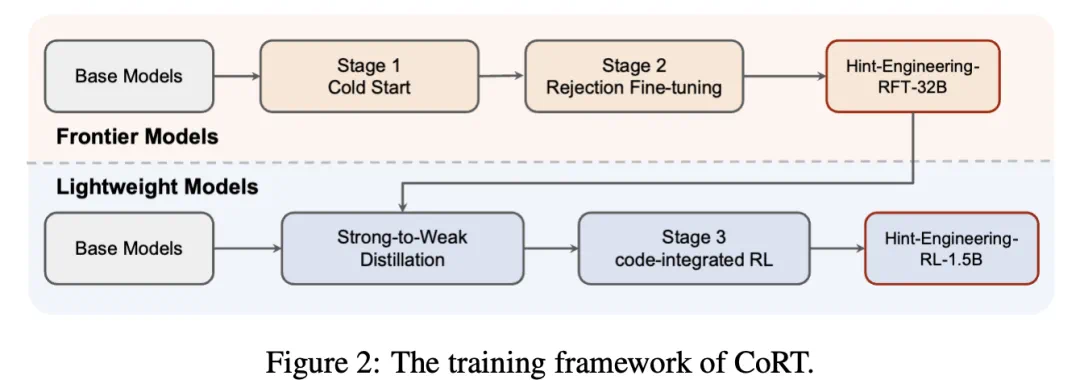
1.Hint-Engineering (提示工程):数据冷启动的艺术
挑战:高质量的「模型 - 工具」交互数据极度稀缺。简单地提示模型使用代码,会产生大量冗长、低效的推理轨迹。
核心思路:研究团队首次提出了一种名为「提示工程」(Hint-Engineering) 的全新数据合成策略。其核心是在推理路径的关键决策点,策略性地注入引导性提示,从而纠正模型的低效行为。
a.当模型试图手动进行复杂计算时,注入提示:「这看起来很繁琐,我们可以用 python 代码来简化推理」,引导其立即计算。
b.当模型得到代码结果后试图手动验证时,注入提示:「我们不需要怀疑 python 计算的准确性」,打消其结果不信任。
效果:遵循「数据质量远重于数量」的原则,团队仅手动标注了 30 个高质量样本,就为后续训练奠定了坚实基础。这种方法生成的推理轨迹不仅正确,而且极其简短高效。

2.多阶段训练流程:精细化能力塑造
在高质量数据的基础上,CoRT 设计了一套包含 SFT、RFT 和 RL 的完整训练管线:
监督微调 (SFT):使用 30 个「提示工程」样本进行初步微调,让模型快速学习到高效交互的基本模式。
拒绝采样微调 (RFT):让初步微调后的模型生成大量解答,并自动过滤掉错误的、或存在「延迟计算」「结果不信任」等不良行为的轨迹,只保留优质轨迹用于进一步训练,强化模型的「好品味」。
强化学习 (RL):将模型视为一个智能体 (Agent),将代码解释器视为环境 (Environment)。通过精心设计的奖励函数(同时奖励最终答案的准确性和代码执行的成功率),让模型在与环境的交互中,通过试错自主学习最优的工具使用策略。这一步极大地提升了模型的稳定性和上限,尤其对于小尺寸模型效果显著。
实验结果:性能与效率的双重飞跃
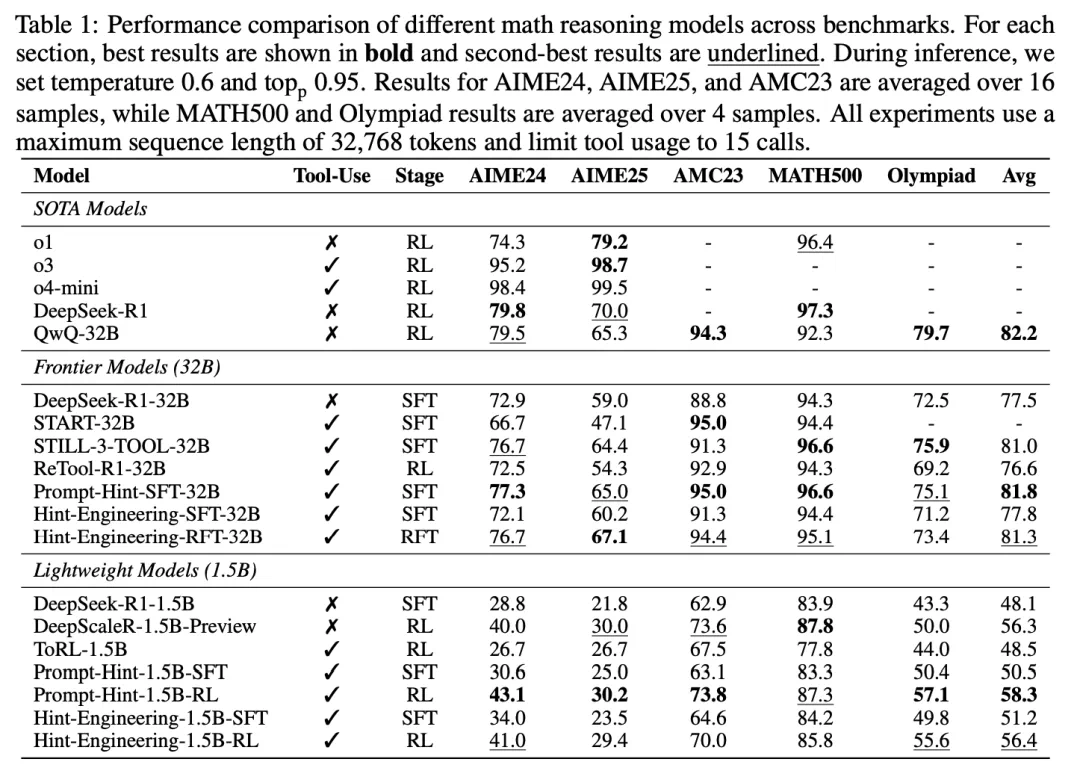
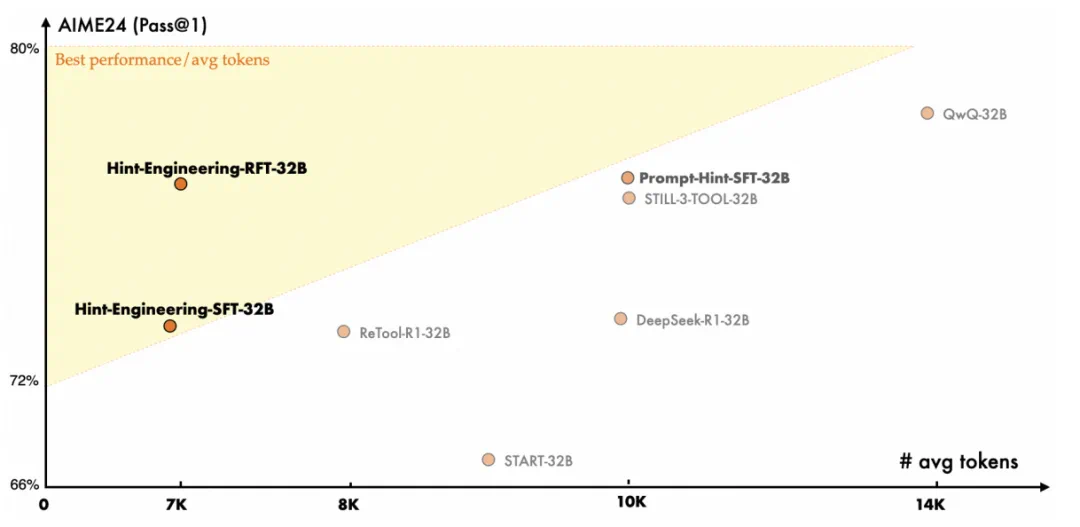
CoRT 框架在 5 个极具挑战性的数学推理基准上进行了全面评估,结果证明了其卓越的性能。
性能显著提升:在同等规模的开源模型基础上,CoRT 为 DeepSeek-R1-32B 带来了 4% 的绝对精度提升,为 1.5B 模型带来了高达 8% 的绝对提升,效果媲美乃至超越了许多依赖更多数据训练的模型。
效率革命性优化:与纯自然语言推理的基线模型相比,CoRT 将 32B 模型的 token 消耗降低了约 30%,1.5B 模型更是降低了惊人的 50%。这意味着用一半的计算成本,就能达到更高的准确率。
重塑代码使用行为:分析显示,传统方法促使模型将代码主要用于「验证」(占比 68.2%),而 CoRT 成功地将模型行为转变为以「计算」为核心(占比 51.1%),从根本上提升了推理效率。
强大的泛化能力:在完全没见过的化学问题(OOD)测试中,CoRT 训练的模型不仅性能更优,还能自发地发现并使用一个从未在训练中出现过的专业工具库(RDKit),使用率高达 81.3%,展现了真正的智能涌现。
意义与展望
CoRT 框架的提出,为解决大型语言模型在精确推理领域的短板提供了一条高样本效率、高计算效率的全新路径。
它证明了,通过精巧的数据设计和先进的智能体强化学习框架,我们不仅能教会模型「使用」工具,更能教会它们「高效、智能」地 与工具协作。
这项工作展示了构建更强大、更可靠、更经济的 AI 智能体系统的巨大潜力,为 AI 在科学发现、教育辅助、工程设计等需要精确推理的领域的落地应用,扫清了一大障碍。未来,将此框架扩展到更多样化的工具和更复杂的任务场景,将是该方向激动人心的研究路径。
作者介绍
核心作者:
唐正阳,香港中文大学(深圳)博士生,参与了 Qwen3 模型的开发,提出了 MathScale、ORLM 等代表性工作。
李成鹏,中国科学技术大学博士生,参与了 Qwen2.5、QwQ、Qwen3 等模型的开发,提出了 Mugglemath, START 等代表性工作。
李子牛,香港中文大学(深圳)博士生,提出了 ReMax、Knapsack RL 等代表性工作。


