今天的 2024 世界人工智能大会(WAIC 2024)期间,面壁智能联合创始人、首席科学家刘知远宣布,开源主打高效低能耗的新一代“面壁小钢炮”MiniCPM-S 模型,同时发布助力开发者一键打造大模型 SuperApp 的全栈工具集 MobileCPM。
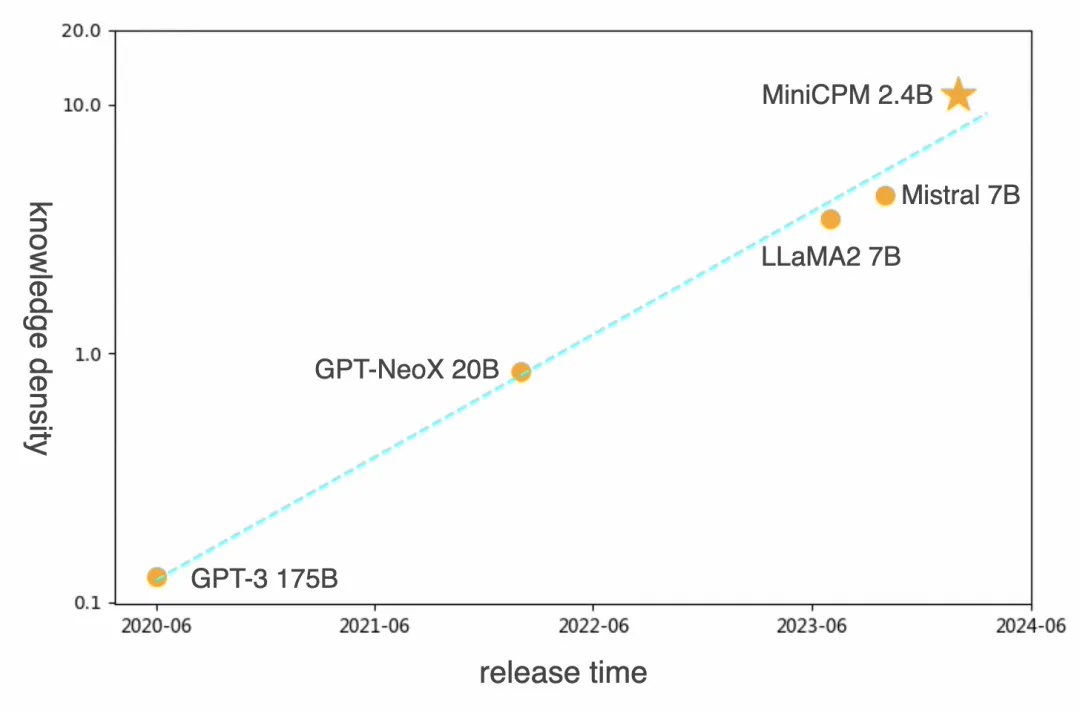
据介绍,面壁 2024 年发布了具备 GPT-3 同等性能但参数仅为 24 亿的 MiniCPM-2.4B,知识密度提高了约 86 倍。面壁方面更称,这“并不是极限”—— 其持续优化 Scaling Law 使模型知识密度不断提升,可不断训练出计算更加高效、表现更强(参数规模降低,数值位宽降低,结构更加高效)的基础大模型。
而此次开源的 MiniCPM-S 采用“稀疏激活”在同等参数下减少大模型的推理能耗,稀疏度越高,每个词元(token)激活的神经元越少,大模型的推理成本和能耗就越少。
MiniCPM-S 1.2B 采用了高度稀疏架构,通过将激活函数替换为 ReLU 及通过带渐进约束的稀疏感知训练,巧妙地解决了此前主流大模型在稀疏激活上面临的困境。

官方还表示,和同规模的稠密模型 MiniCPM 1.2B 相比,MiniCPM-S 1.2 具备如下特征:
Sparse-高稀疏低能耗:在 FFN 层实现了高达 87.89% 平均稀疏度,推理算力下降 84%;
Speed-神仙推理:更少计算,迅疾响应。纯 CPU 环境下,结合 Powerinfer 推理框架,推理解码速度提升约 2.8 倍;
Strong-无损强大性能:更少计算量,无损下游任务性能。

MiniCPM-S 1.2B 号称实现知识密度的“空前提升”—— 达到同规模稠密模型 MiniCPM 1.2B 的 2.57 倍,Mistral-7B 的 12.1 倍。
IT之家附开源链接:
论文地址:https://arxiv.org/pdf/2402.13516.pdf
模型地址:https://huggingface.co/openbmb/MiniCPM-S-1B-llama-format
PowerInfer可直接运行格式:https://huggingface.co/openbmb/MiniCPM-S-1B-sft-gguf
此外,面壁还开源了号称业内首个端侧大模型工具集 MobileCPM,开发者可以一键集成大模型到 App,且实现“开箱即用”。其包含开源端侧大模型、SDK 开发套件及翻译、摘要等丰富的 intent,可一站式灵活定制满足不同应用场景需求的大模型 App。其为开发者提供了基础模式、精装模式、全包配件模式,默认集成面壁新一代高效稀疏架构模型 MiniCPM-S 1.2B。
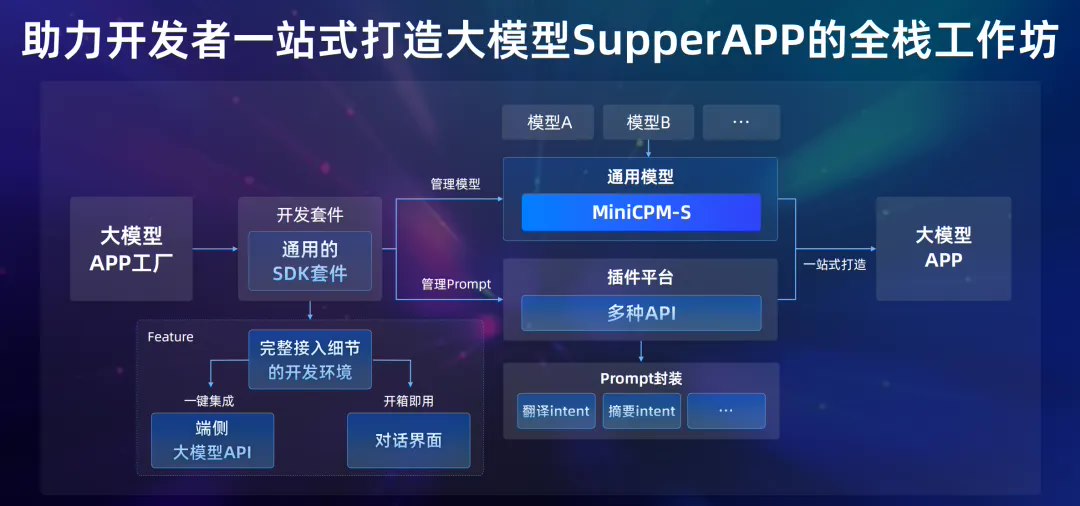


MobileCPM 已经支持 iOS 系统,安卓版本也即将上线。附:开源地址、TestFlight 外测地址。


