机器人轻轻伸出机械臂,捡起一块布料并折叠。
没有人给它“示范”过。
也没有人告诉它什么是“布”、什么是“拿起”、什么是“折叠”。
它只是在看过100万小时的视频之后,自己“理解”了这一切。
 图片
图片
这是一段实验视频,记录的是 Meta 最新发布的 V-JEPA 2 在机器人控制上的一次测试。它没有依赖大量手工标注的数据,也没有借助庞大的语言模型来“解释世界”。它靠的,是对这个世界运行规律的理解——一种被称为“世界模型”的理念。
是的,在世界模型这条冷门却持久的技术路径上,Meta 发布了 V-JEPA 2,一个 12 亿参数的视频模型,它能让机器人在没见过的环境中直接执行任务。
V-JEPA 2 是 Meta 在“世界模型”方向上的第二次出击。这个模型并不只是识别图像,而是尝试“理解物理世界”:它能从视频中学习因果关系、预测未来场景,并据此规划行为。Meta 声称,它已经具备“零样本”在机器人上的规划与控制能力。
 图片
图片
lecun亲自出境宣发世界模型
地址:https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
其实,在 Meta 的 AI 路线图中,LeCun 一直坚持“自监督学习”和“世界模型”是未来关键。他认为,今天的 AI 模型太依赖标签、数据和预设范式,缺乏真正的因果和空间理解能力。
相比 OpenAI、Google DeepMind 以大模型、对话能力为突破口,业内普遍认为 Meta 选择了相对稳健的 embodied AI 路线:他们的 AI 不必回答问题,而是更擅长在厨房、客厅、走廊等物理世界中“看懂并预测”。
这种 AI 的应用图景也随之改变:不是像 ChatGPT 那样聊天办公,而是做家务、配送物品、辅助护理。Meta 描述的终极目标是“real-world AI agents”——现实世界中的智能体,能做事,而不是说话。
比快更重要的是“少数据”
 来自meta,供交流学习使用,侵删
来自meta,供交流学习使用,侵删
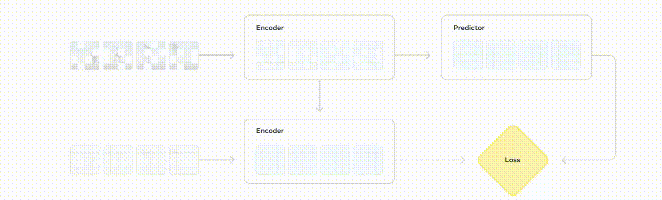
V-JEPA 2 具备 12 亿参数,采用的是 Meta 自研的 JEPA(Joint Embedding Predictive Architecture)架构。在一个无须人工标注、全程自监督的训练过程中,它观看了超过 100 万小时的视频,并在一个短期的“动作条件训练”阶段中,仅靠 62 小时的机器人数据,学会了用预测未来的方式来选择动作。用 Meta 的话说,它学会了“思考之后再行动”。
这一训练流程分为两个阶段:第一阶段是从人类的视频中学习世界是怎么运行的,比如物体如何移动、人与物如何互动;第二阶段是让模型结合机器人的控制信号,去理解“如果我采取某个动作,会发生什么”。
最终,Meta 展示了它在多种机器人实验中的能力:在实验室里,一台机器人面对陌生物体和新场景,依靠 V-JEPA 2 的模拟预测能力,可以完成“捡起物体并放到指定位置”的任务,成功率在 65%-80% 之间。
LeCun 的“孤勇”与 AMI 的下一步
 视频来自meta,供交流学习使用,侵删
视频来自meta,供交流学习使用,侵删
在 Meta 内部,V-JEPA 项目有一个特殊的领路人:Yann LeCun——深度学习三巨头之一。这一次,他亲自出镜解读模型细节。在许多人向 AGI、Sora 或语音助手下注时,他坚持走世界模型这条路。
LeCun 多次提到,“世界模型”是自己研究了近 20 年的方向。他不看好自回归预测未来视频帧的主流方式,而是倾向 JEPA 这种嵌入空间中的预测策略,避免 LLM-style 架构在物理世界模拟上的困境。他相信真正的“高级机器智能”(Advanced Machine Intelligence, AMI)必须先有物理直觉,就像婴儿扔网球知道它会掉下,而不是变成一个苹果。
这也是 V-JEPA 与其他多模态大模型的分野:前者关注“理解世界怎么运作”,后者则更强调语言和图像的泛化能力。世界模型,不只是描述,而是预测和规划。
而 Meta 最近的系列动作也显示,它没有放弃这条非主流路线:组建“超级智能”团队、重金挖角 Alexandr Wang、招聘 DeepMind 首席研究员 Jack Rae,以及发布全新基准测试,标志着它在 AMI 路线上全面加速。
三大新基准,补课物理常识
为验证模型是否真的具备“世界理解”能力,Meta 还同步发布了三个视频推理基准:IntPhys 2、MVPBench、CausalVQA——三者分别检验物理常识、最小干扰识别能力和因果推理水平。
- IntPhys 2:灵感来自认知科学中“违反预期范式”,即给模型两个视频,其中一个在最后一秒出现物理“bug”(比如物体穿墙),模型要指出哪个视频是“不可能的”。
- MVPBench:要求模型对两个几乎一致的视频回答同一个问题,答案却相反。这种“最小变化对”避免模型通过表面特征“猜题”,而真正考验推理能力。
- CausalVQA:聚焦“物理因果性”的问答任务,问题涵盖“反事实”、“预测未来”和“下一步计划”三类。这些问题比单纯理解“发生了什么”更难,V-JEPA 2 虽已优于以往模型,但离人类表现仍有不小差距。
Meta 在 Hugging Face 上还专门上线了 Leaderboard,希望整个研究社区都能围绕“世界理解”这一新维度展开竞赛和优化。
离通用智能,还有多远?
V-JEPA 2 是一把“万金油钥匙”的雏形:它不依赖具体机器人或场景,训练一次可以“即插即用”。这是区别于传统机器人模型的重大突破。后者往往需要为每一个新场景单独收集数据、训练模型,而 V-JEPA 2 强调通用性。
在执行短任务时,比如把物体从 A 点移动到 B 点,V-JEPA 2 接收两个图像(当前状态和目标状态),然后用预测器模拟各种可能的动作后果,选出最可能成功的那个。这种“模型预测控制”(model predictive control, MPC)让机器人每一步都像“想清楚再动”。
据悉,接下来,Meta 的重点是构建能处理“多时间尺度”的世界模型:不仅做一步规划,还能像人一样分解长任务;以及“多模态”的世界模型:不仅看,还能听、摸,最终形成更加完整的“世界理解系统”。
但真正的问题是:这种以“从视频中理解世界”为中心的路线,能否撑起 AGI 的未来?
就在这个通往高级机器智能的岔路口,V-JEPA 2 把 Meta 推向了一条冷门、但可能最接近“常识”的路径——但三年后,是不是所有人都还在等 LeCun 证明“世界模型”这一假说,仍是未知数。
作者长期关注 AI 产业落地与学术动态、以及具身智能、汽车科技等前沿领域,欢迎对这些方向感兴趣的朋友添加微信 Q1yezi,共同交流行业动态与技术趋势!


