上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。
本文第一作者辛毅为南京大学 & 上海创智学院博士生,现于上海人工智能实验室实习,研究方向为图像 / 视频生成、多模态生成与理解统一等。通讯作者为上海人工智能实验室青年科学家 — 高鹏。本文其他作者来自上海人工智能实验室、香港中文大学、上海交通大学、上海创智学院、浙江工业大学等。

论文标题:Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
论文链接:arxiv.org/pdf/2507.17801
GitHub 地址:Alpha-VLLM/Lumina-mGPT-2.0
关键词:图像生成、自回归模型、基座模型。
核心技术与突破
完全独立的训练架构
不同于依赖预训练权重的传统方案,Lumina-mGPT 2.0 采用纯解码器 Transformer 架构,从参数初始化开始完全独立训练。这带来三大优势:架构设计不受限制(提供了 20 亿和 70 亿参数两个版本)、规避授权限制(如 Chameleon 的版权问题)、减少预训练模型带来的固有偏差。
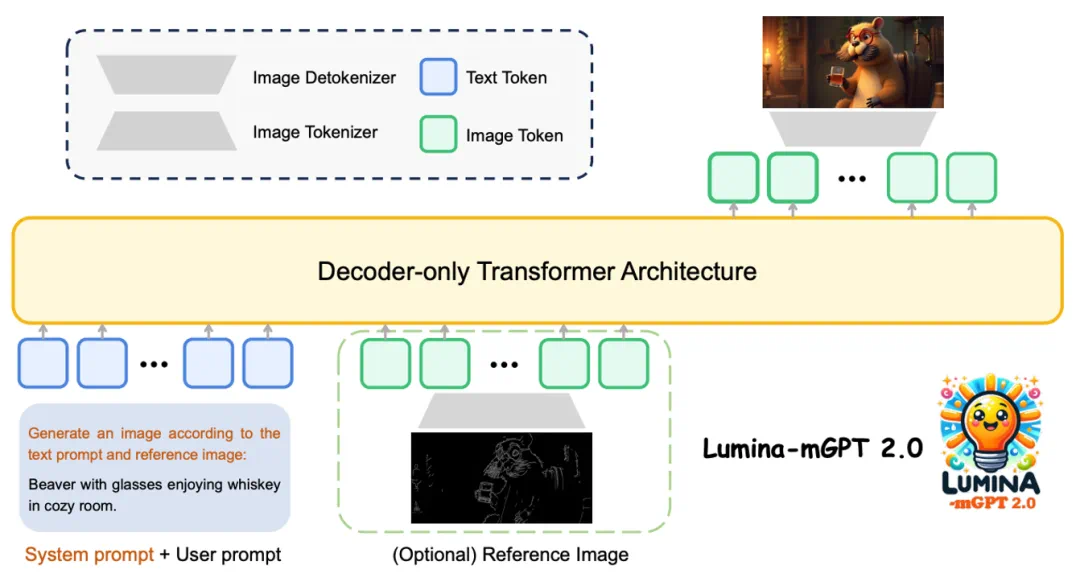
图像分词器方面,通过对比 VQGAN、ViT-VQGAN 等多种方案,最终选择在 MS-COCO 数据集上重建质量最优的 SBER-MoVQGAN,为高质量生成奠定基础。

统一多任务处理框架
创新地采用统一的图像分词方案,将图生图任务通过上下拼接视为一张图像,并通过提示描述进行控制,实现多任务训练与文生图训练的一致性。使得单一模型能够无缝支持以下任务:
文生图
主体驱动生成
图像编辑
可控生成(如基于轮廓 / 深度的生成)
密集预测
这种设计避免了传统模型需切换不同框架的繁琐,通过系统提示词即可灵活控制任务类型。

高效的推理策略
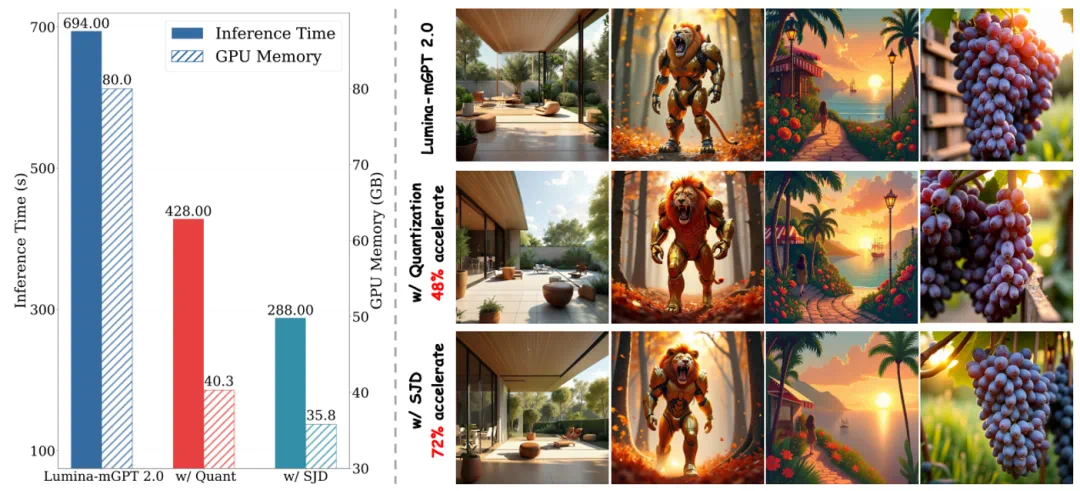
为了解决自回归模型生成速度慢的痛点,团队引入两种优化:
模型量化:将模型权重量化为 4 位整数,同时保持激活张量为 bfloat16,通过 PyTorch 2.0 中的原生编译工具和 torch.compile 的 reduce-overhead 模式实现无需改变模型架构的优化。
推测式 Jacobi 采样:通过静态 KV 缓存和静态因果注意掩码的方案,使 SJD 兼容于静态编译框架,从而实现加速采样,同时避免动态调整缓存。结合 4 位量化技术,减少 60% GPU 显存消耗,同时通过并行解码加速生成。
实验显示,优化后模型在保持质量的前提下,生成效率显著提升。
实验结果
文生图实验结果
在文本到图像生成领域,Lumina-mGPT 2.0 在多个基准测试中表现优异,与 SANA 和 Janus Pro 等扩散模型和自回归模型相当甚至超越,特别是在 “两个物体” 和 “颜色属性” 测试中表现卓越,以 0.80 的 GenEval 分数跻身顶级生成模型之列。
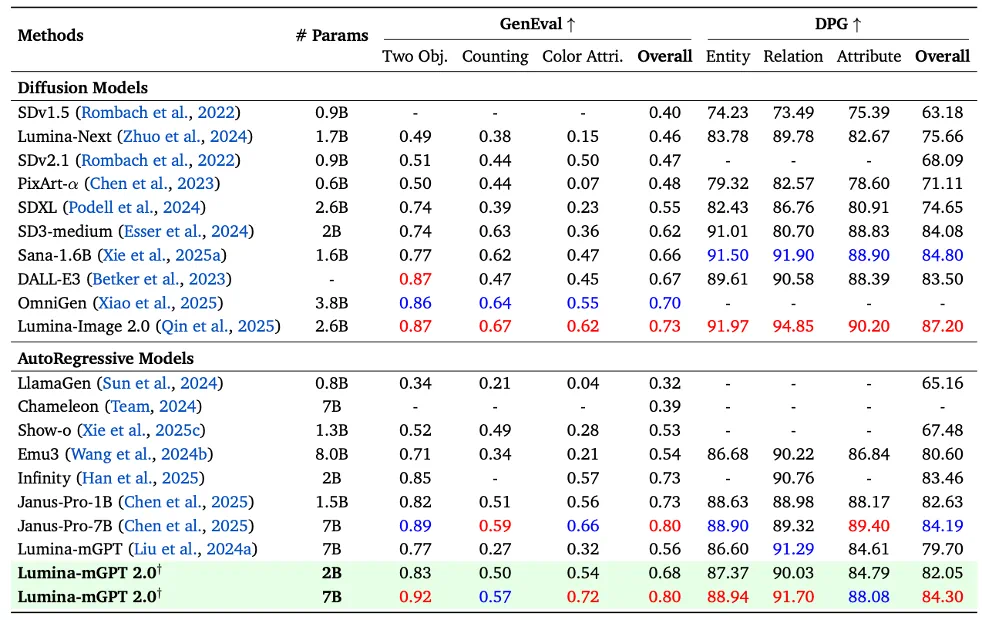
此外,在实际生成效果上,Lumina-mGPT 2.0 在真实感、细节和连贯性方面优于前代 Lumina-mGPT 和 Janus Pro,更具视觉吸引力和自然美感。

多任务实验结果
在 Graph200K 多任务基准中(可控生成、物体驱动生成),Lumina-mGPT 2.0 表现优异,证明了纯自回归模型在单一框架下完成多模态生成任务的可能性。
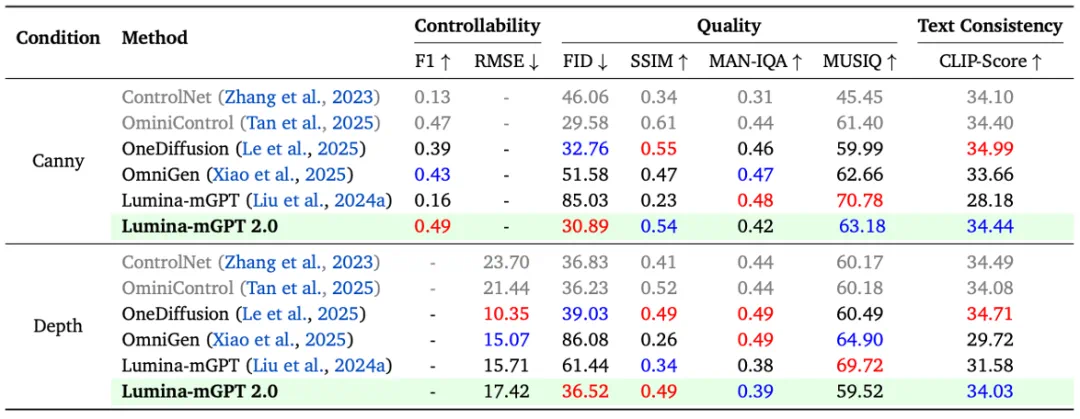
此外,团队与其他的多任务生成模型进行了实际比较,Lumina-mGPT 2.0 在可控生成和主题驱动生成任务中表现突出,与 Lumina-mGPT、OneDiffusion 和 OmniGen 等模型相比,展示了卓越的生成能力和灵活性。

未来方向
Lumina-mGPT 2.0 在优化推理后,仍面临采样时间长的问题,与其他基于自回归的生成模型相似,这影响了用户体验,后续将进一步优化。当前 Lumina-mGPT 2.0 的重点在多模态生成, 但计划更新扩展至多模态理解,以提高其整体功能和性能,这将使 Lumina-mGPT 2.0 在满足用户需求方面更加全面。