
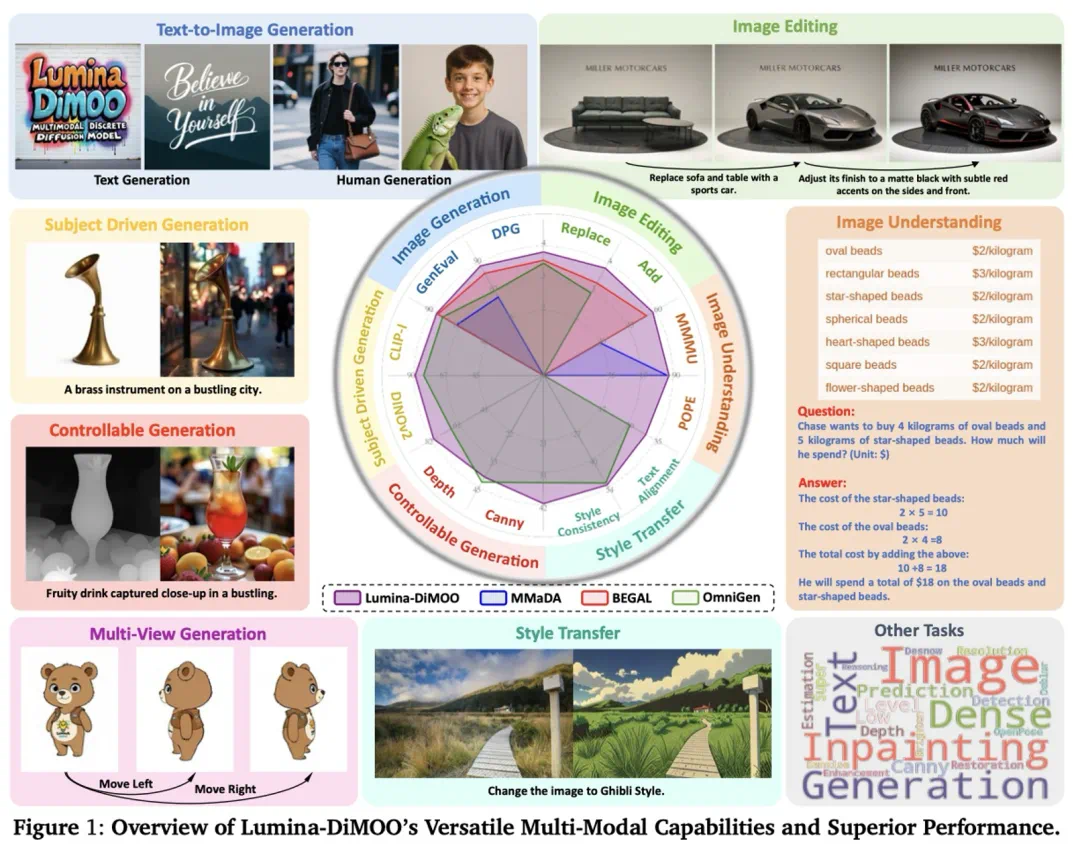
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。

论文标题:Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding
论文链接:arxiv.org/pdf/2510.06308
GitHub 地址:Alpha-VLLM/Lumina-DiMOO
关键词:多模态生成与理解统一、扩散语言模型
过去:自回归生成的瓶颈
从 Chameleon 到 Lumina-mGPT,再到 Janus-Pro—— 主流 “多模态统一模型”,几乎都基于 自回归(AR)架构。这些模型的架构存在显著缺陷:
生成太慢:逐 token 生成,导致图像生成通常需要几分钟;
生成质量受限:图像细节的表现力较弱,尤其是在高分辨率生成时,精细度无法保证;
任务间无法无缝衔接:多模态的生成和理解任务往往分开处理,导致模型的通用性和效率受到制约。
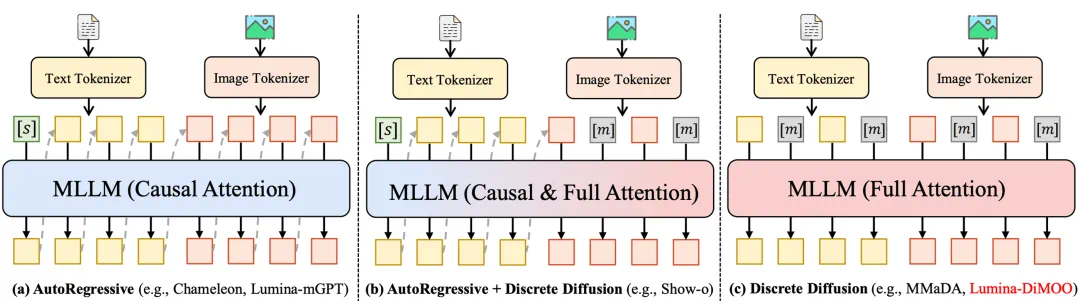
然而,Lumina-DiMOO 采用了纯离散扩散框架,彻底解决了上述问题。在这个全新的架构中,我们通过并行化的双向注意力机制和灵活的采样策略,实现了跨多任务的高效融合,不仅加速了生成过程,还提升了生成质量。
现在:扩散语言模型的崛起
Lumina-DiMOO,作为一款全新推出的多模态扩散语言模型,凭借其创新的离散扩散架构,不仅在图像生成和文本生成之间架起了无缝桥梁,还在理解和生成任务中实现了跨模态的一体化。与传统自回归(AR)模型相比,Lumina-DiMOO 大幅提升了生成速度和精度,成为多模态领域的技术突破。
1. 离散扩散架构:核心创新与优势
Lumina-DiMOO 使用了最新的离散扩散架构(Discrete Diffusion Model),通过并行生成和双向注意力机制,使得图像生成和理解任务不再互相独立,而是能够在同一个框架中高效运作。这一创新架构打破了传统的生成 - 理解边界,在一个框架中同时实现文本生成图像、图像编辑、风格迁移、图像理解等任务。
2. 高效生成:并行预测与加速
与大多数传统的自回归模型不同,Lumina-DiMOO 通过并行生成的方式大大加快了推理过程。通过一次性处理多个 token 的生成任务,Lumina-DiMOO 能够在每个时间步骤并行预测,并在图像生成任务中从完全 mask 的 token 开始,逐步解码生成图像或文本。这种方式不仅加速了生成过程,还有效提升了生成质量,确保了任务间的高效协同。
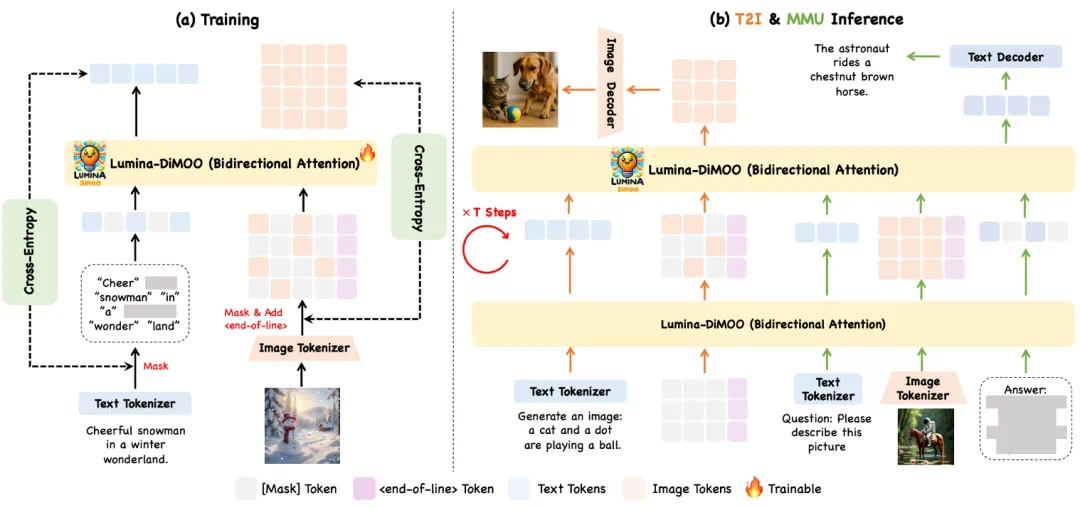
3. 双向注意力机制:深入理解与生成
双向注意力机制(Bidirectional Attention)是 Lumina-DiMOO 另一个关键的技术特点。该机制让模型不仅能够理解文本的上下文关系,还能捕捉图像之间的结构和细节。这种跨模态的注意力机制确保了文本和图像任务的高度一致性,同时提升了模型在理解和生成过程中处理多模态信息的能力。
4. 联合优化:全局性能提升
Lumina-DiMOO 还采用了全局优化策略,在训练过程中通过联合损失函数优化整体性能。通过这种方法,Lumina-DiMOO 不仅优化了文本生成图像、图像编辑、理解等任务的表现,还确保了模型的高效统一和多任务能力,使其能够在多个任务之间无缝切换。
加速采样:Max-Logit 缓存技术的革新应用
在 Lumina-DiMOO 的推理过程中,Max-Logit 缓存技术显著提升了生成效率和速度。该技术通过缓存那些 “稳定” 或 “不容易变化” 的 token,避免了不必要的重复计算,从而加速了推理过程。具体而言,在生成每个 token 时,模型评估其概率分布,并将高置信度的 token 进行缓存,只有当 token 变化较大时才重新计算。通过并行推理和高效的缓存机制,Max-Logit 技术不仅加快了推理速度,还保证了生成质量,尤其在高分辨率生成任务中,能够保留图像的细节与准确性。此外,该技术的引入大幅降低了计算成本,使得 Lumina-DiMOO 在保持高质量生成的同时,具备了更高的推理效率和更低的计算开销。
模型的 “自我演化”:Self-GRPO

更令人惊喜的是,团队提出了一个全新的自我强化框架 ——Self-GRPO。它把 “图像生成” 和 “多模态理解” 整合进一条强化学习轨迹,让模型在生成中学会理解,在理解中反哺生成。训练过程中,模型会自评答案正确率、计算奖励、再反向优化,从而完成 “生成 - 推理 - 校正” 的闭环。这意味着 Lumina-DiMOO 已不仅是一个多模态模型,更像一个具备 自主反思能力的智能体雏形。
成绩单:全面 SOTA
Lumina-DiMOO 在多项权威评测中夺魁:
UniGenBench(由腾讯混元维护):开源模型第一名
GenEval:综合得分 0.88,超越 GPT-4o、BAGEL、Janus-Pro 等顶尖模型
DPG、OneIG-EN、TIIF:在语义一致性、布局理解、属性绑定、推理等维度全面领先。
未来展望
Lumina-DiMOO 让我们再次接近 “原生多模态智能” 的理想。
它能读、能写、能画、能思考 —— 真正实现从感知到创造的统一闭环。
正如团队所言:
“我们希望模型不只是理解世界,更能创造世界。”
—— 来自 Alpha-VLLM 团队的又一次大胆尝试。


