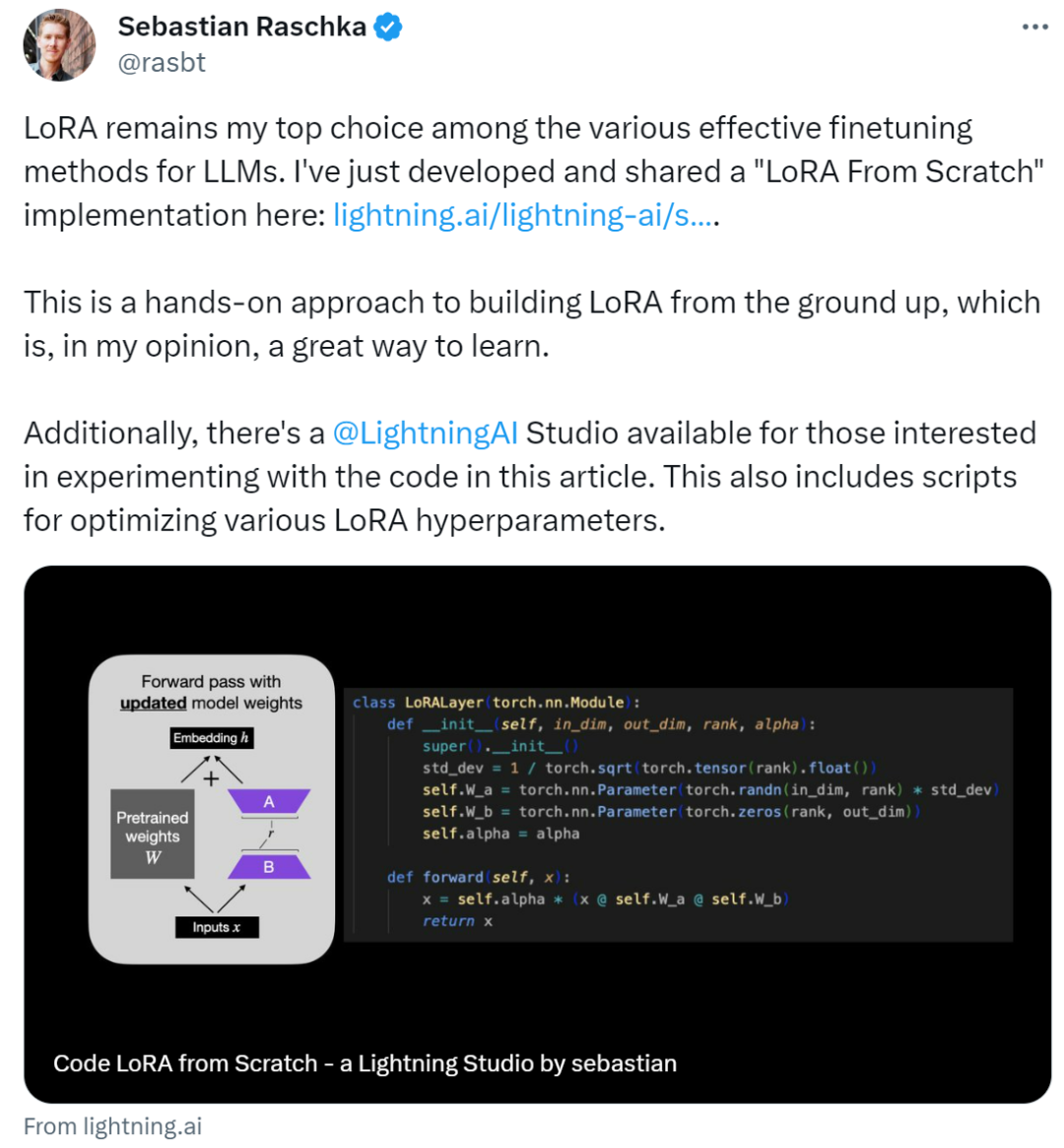
五月底写过一篇 Lora 微调的概念铺垫文章,这篇来结合阿里云的一个开源项目和免费试用 GPU 来做个完整的训练过程演示。
Lora微调实操教程(上):人话版概念详解(附案例)
注:本篇演示的脚本部分在参考 aliyun_acp_learning 开源项目基础上有部分删减和调整。后文相关配置和训练过程中的实际耗时也会进行标注说明。https://github.com/AlibabaCloudDocs/aliyun_acp_learning.git
这篇试图说清楚:
Lora 微调的环境配置、任务设计、基准测试、五次迭代训练以及微调后的对比测试效果。
以下,enjoy:
1、环境配置
虽然是 Lora 微调但对硬件性能要求也并不低,如果各位本地没有 GPU 环境或者显存不到 30GB,可以先按照下述步骤去蹭下阿里云的 DSW(交互式建模平台)3 个月250计算时的 A10 GPU 免费试用。
https://billing-cost.console.aliyun.com/home/myfreetier
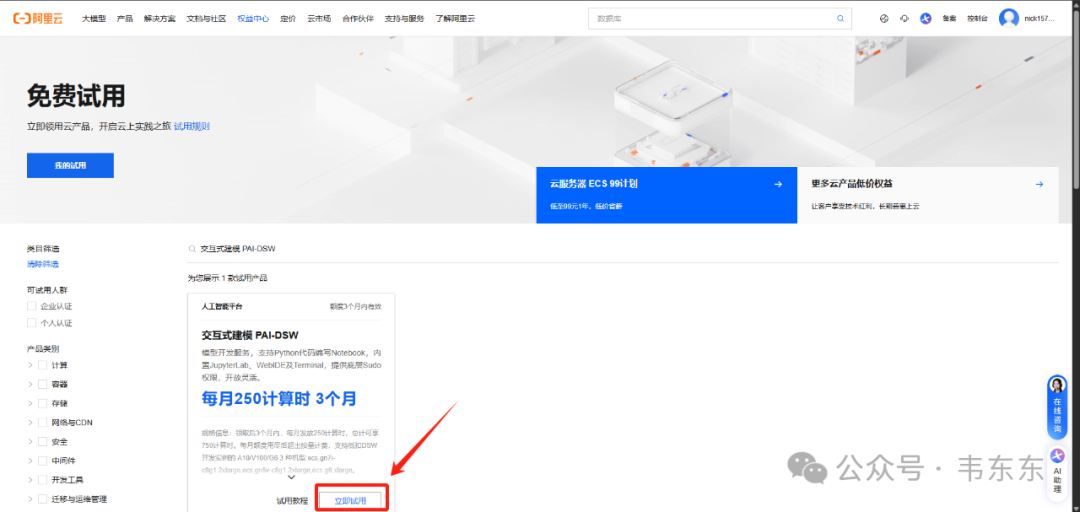
资源规格选择免费试用页签中的ecs.gn7i-c8g1.2xlarge(该规格有一个 A10 GPU,显存 30GB),镜像选择 modelscope:1.21.0-pytorch2.4.0-gpu-py310-cu124-ubuntu22.04(需要将“镜像配置”->”芯片类型“切换为 GPU)

注:实际安装依赖花了 48 分钟
2、明确训练状态
老规矩,正式开始介绍前,明确一些重要概念。最基础的损失函数、神经网络和各个超参数的概念本篇不再做赘述,不熟悉的盆友记得先去翻下上一篇。这部分明确下后续的训练和测试内容。
模型训练和人的学习考试过程非常像,前后需要经过三套题目的考验,来确定模型训练所处于的状态:
2.1训练集
课程练习册,带详细答案解析,模型会反复练习,并基于损失函数产生训练损失。训练损失越小,说明模型在你给定的练习册上表现更好。
训练损失不变,甚至变大说明训练失败。可以理解为模型在训练集(练习册)上没有学习到知识,说明模型的学习方法有问题。
2.2验证集
模拟考试题,模型每学习一段时间,就会测试一次,并基于损失函数产生验证损失。验证损失就是用于评估模型训练的效果。验证损失越小,说明模型在模拟考试中表现越好。
训练损失和验证损失都在下降说明模型欠拟合。可以想象成模型在训练集(练习册)上的学习有进步,验证集(模拟考试)的表现也变好了,但还有更多的进步空间。这时候应该让模型继续学习。
2.3测试集
相当于考试真题,模型在测试集上的准确率用于评估最终的模型表现。训练损失下降但验证损失上升说明模型过拟合。
可以理解为模型只是背下了训练集(练习册),在模型考试中遇到了没背过的题反而做不来了。这种场景需要通过一些方法去抑制模型的背题倾向,比如再给它 20 本练习册,让它记不住所有的题,而是逼它去学习题目里面的规律。
3、模型下载与基准测试
本篇微调的基座模型选择的是小参数的开源qwen2.5-1.5b-instruct,首先下载模型并把它加载到内存中。
3.1模型下载(42 分钟)
复制
3.2基准模型测试(2 分钟)
在开始模型微调前,先来看看基准模型在测试集上的表现如何。
复制
一共有十个测试问题,这里截取其中一个问答进行展示:
复制复制最终qwen2.5-1.5b-instruct模型在考试中得了60 分。
4、五次微调过程
这里使用 ms-swift(Modelscope Scalable lightWeight Infrastructure for Fine-Tuning)框架,它是阿里魔搭社区专门为模型训练开发的开源框架,在每次计算验证损失的时候,框架会自动保存当前训练阶段的模型参数,并在训练结束时自动保存训练过程中验证损失最小的参数。
在接下来的多次实验中,将重点调整学习率、LoRA 的秩、数据集学习次数三个参数,并替换数据集,展示如何进行 LoRA 微调,其它的参数的调整是为了方便实验效果呈现,如增加批大小从而缩短训练时间,可以不用过多关注。
4.1第一次实验(26 秒)
参数 | 参数值 |
学习率 | 0.1 |
LoRA 的秩 | 4 |
数据集学习次数 | 1 |
数据集位置 | 数据集位置: 当前目录/resources/2_4/train_100.jsonl |
可以调整所有的参数自由尝试,但根据展示效果和显存限制,有这些限制 | batch_size <= 16 (显存限制) max_length <= 512 (每条训练数据的最大长度,显存限制) lora_rank <= 64 (LoRA 的秩,显存限制)eval_step <= 20 (方便展示) |
注:ms-swift 框架的微调模块默认使用 LoRA 微调所以实验中不需要显式地声明微调方法。同时框架会在训练过程中智能地减少实际学习率,保证模型不会总是跳过最优解。
复制
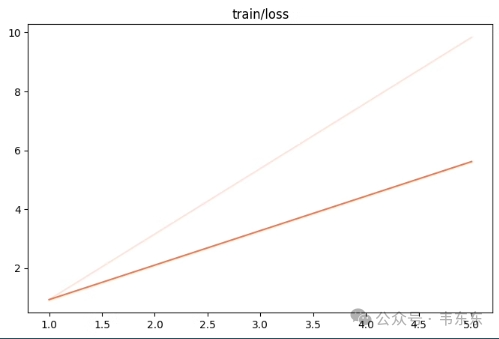
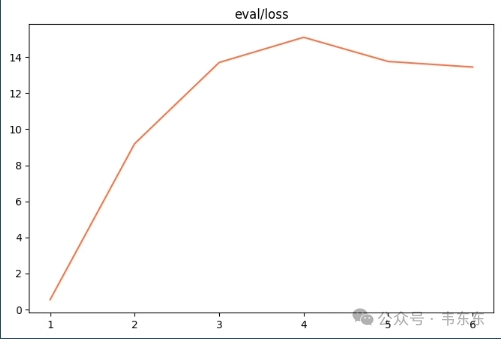
观察指标 | 训练损失增大、验证损失增大 |
训练状态 | 训练失败 |
原因分析 | 很有可能是学习率过高,导致模型参数在最优解附近反复横跳,无法找到最优解,训练失败。 |
调整逻辑 | 大幅降低学习率至 0.00005,让模型以更小步幅“谨慎学习”。 |
4.2第二次实验(22 秒)
参数 | 旧参数值 | 新参数值 |
学习率 (learning_rate) | 0.1 | 0.00005 |

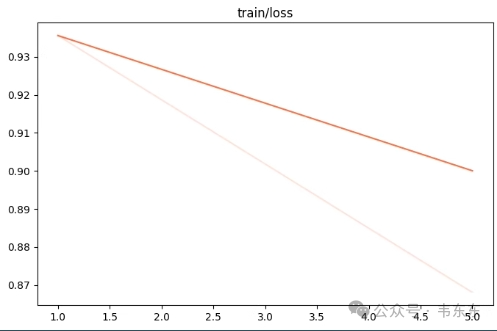
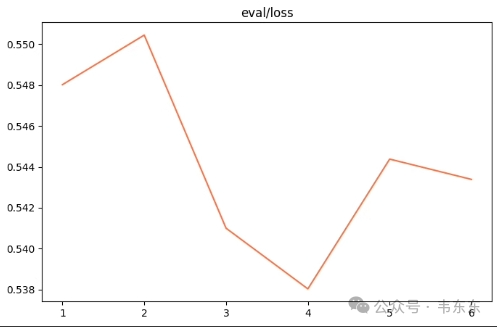
观察指标 | 训练损失减小、验证损失也减小 |
训练状态 | 欠拟合 |
原因分析 | 欠拟合是在训练中非常常见的现象。 说明在参数不变的情况下,只需要让模型再多训练,就可以训练成功了。 当然也可以修改参数来加速训练过程。 |
调整逻辑 | 1. 让模型多训练:数据集学习次数epoch增加至 50。2. 将batch_size调整到最大值 16,加速模型训练。 |
4.3第三次实验(7 分钟)
参数 | 旧参数值 | 新参数值 |
数据集学习次数 | 1 | 50 |
batch_size | 8 | 16 |
eval_step | 1 | 20 |

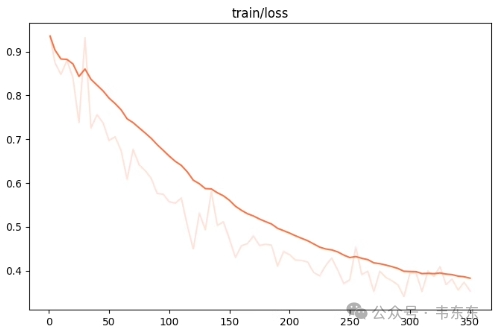
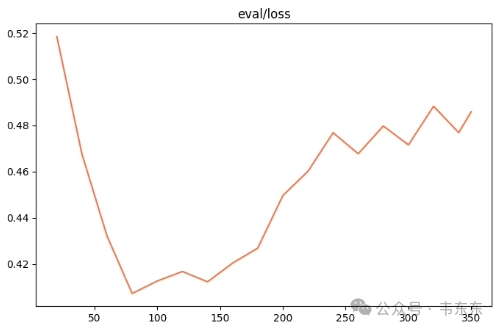
观察指 | 训练损失减小、验证损失先减小后增大 |
训练状态: | 过拟合 |
原因分析 | 过拟合也是在训练中非常常见的现象。 说明模型在“背题”,没有学习数据集中的知识。 我们可以通过降低数据集学习次数 (epoch) 、增大数据量来让模型“记不住题”。 |
调整逻辑 | 1. 数据集学习次数 (epoch) 降低至 5。2. 将由 DeepSeek-R1 生成的题解数量扩充至 1000 条。 数据集位置: 当前目录/resources/2_4/train_1k.jsonl3. 数据量增加后,根据之前的学习将 LoRA 的秩提升至 16 |
一般来说,微调至少需要1000+条优质的训练集数据。低于此数量级时,模型多学几遍就开始“背题”而非学习数据中的知识。
4.4第四次实验(5 分钟)
参数 | 旧参数值 | 新参数值 |
更换数据集 | 100 条数据 | 1000+ 条数据 |
数据集学习次数 | 50 | 3 |
LoRA 的秩 | 4 | 8 |
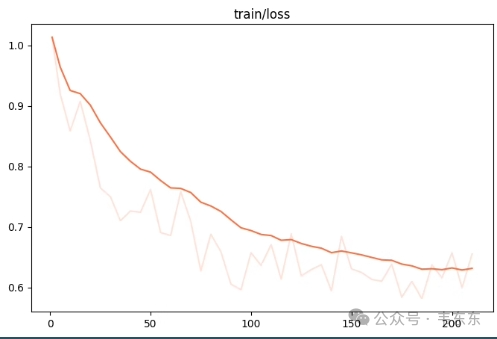
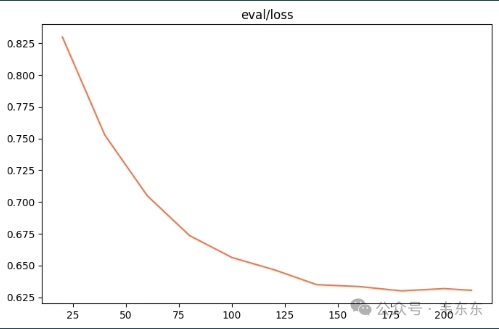

观察指标 | 训练损失减小、验证损失也减小 |
训练状态 | 欠拟合 |
原因分析 | 训练快成功了 |
调整逻辑 | 让模型多训练:数据集学习次数增加至 15。 |
4.5第五次实验(23 分钟)
参数 | 旧参数值 | 新参数值 |
数据集学习次数 | 3 | 15 |

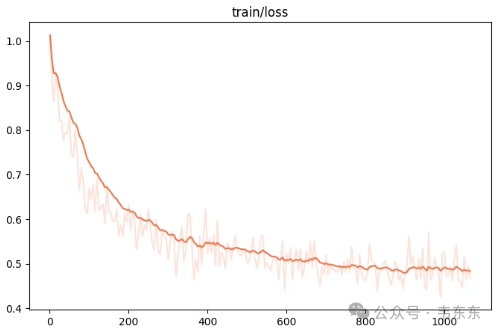
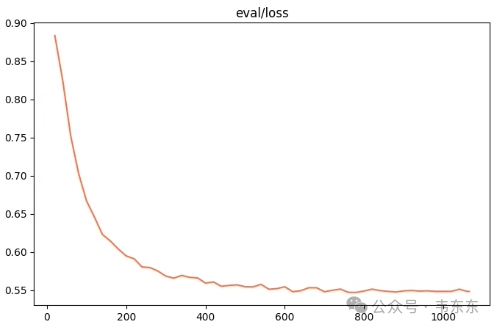
观察指标(训练损失、验证损失): | 训练损失基本不减小、验证损失也基本不减小甚至还略微升高 |
训练状态: | 训练成功 |
5、微调后测试
微调后一般会保存两个 checkpoint 文件,分别是 best_model_checkpoint(在验证集表现最佳的模型参数)与 last_model_checkpoint(微调任务完成时的模型参数)。这里选取 best_model_checkpoint 地址替换下面代码中的 ckpt_dir,就能调用微调后的模型。
先加载模型到内存中:
复制来看看微调后的模型在考试中的表现:
复制
6、写在最后
这篇只是个过程演示,在实际生产中,是否微调需综合考虑算力成本、数据规模和数据质量等因素。一般经验是,能靠提示词工程、RAG 、工作流编排能解决的先做工程优化为好。
最后留个彩蛋:一道多选题。(答案公众号聊天页面发送“微调”两个字看正确答案和解释)
复制