不再依赖人工设计,让模型真正学会管理记忆。
来自来自加州大学圣地亚哥分校、斯坦福大学的研究人员提出了一个创新的强化学习框架——
Mem-α,用于训练LLM智能体自主管理复杂的记忆系统。

在实际应用中,仅仅依靠prompts和instructions往往不足以覆盖所有场景:模型经常会遇到不知道如何更新记忆的情况,尤其是当记忆系统像MIRIX那样变得复杂时。
不同于MIRIX、MemGPT等依赖prompts和instructions的传统方案,Mem-α采用数据驱动的强化学习方法,让模型在交互中自主学习最优记忆管理策略。
如何做到的呢?
让模型真正学会如何管理记忆
上下文窗口限制&现有记忆系统的缺陷
大语言模型(LLM)智能体受限于有限的上下文窗口,这使得外部记忆系统对于长期信息理解变得至关重要。
即使像GPT-4.1这样支持100万tokens的模型,在长期交互中也会随着窗口增长而导致成本激增和延迟增加。
当前的记忆增强智能体通常依赖预定义的指令和工具来进行记忆更新。
然而,语言模型往往缺乏决定存储哪些信息、如何结构化组织以及何时更新的能力——尤其是当记忆系统变得更加复杂时。
这种局限性导致了次优的记忆构建和信息丢失,严重影响了智能体在长期交互中的表现。
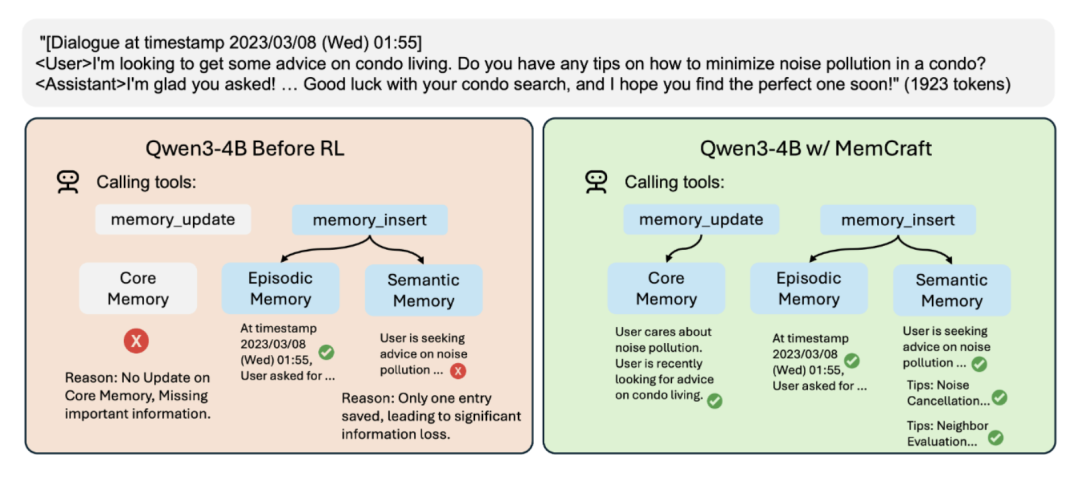
如上图所示,在没有强化学习的情况下,模型在管理记忆系统时会出现明显的错误:核心记忆没有更新导致重要信息丢失,语义记忆中只保存了单一条目造成信息损失。
而经过Mem-α训练后的模型能够正确地在核心记忆、情景记忆和语义记忆中存储相应信息,实现全面的记忆管理。
Mem-α 强化学习框架
Mem-α的核心贡献在于将记忆构建问题转化为一个可通过强化学习优化的序列决策问题。
与以往依赖监督学习或手工规则的方法不同,Mem-α让智能体在处理信息流的过程中自主探索最优的记忆管理策略,并通过下游任务表现直接获得反馈。这种端到端的优化方式使得模型能够学习到真正有效的记忆构建策略。
任务设定(Task Setup)
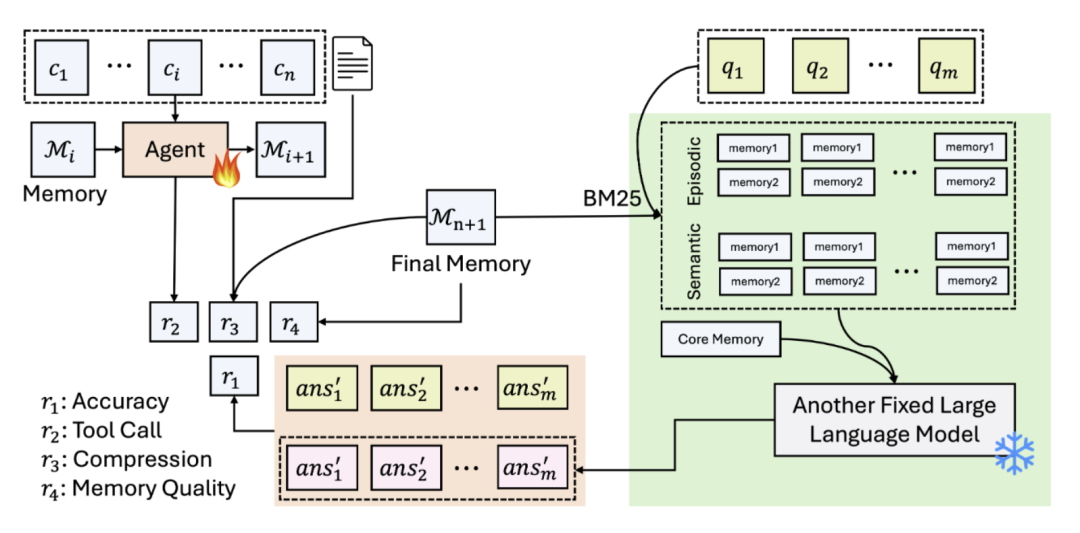
如上图所示,Mem-α将记忆构建建模为顺序决策过程。智能体依次处理信息块,决定执行哪些记忆操作,处理完成后利用构建的记忆系统回答问题。
训练过程中通过多个奖励信号(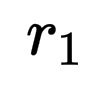 到
到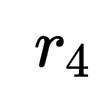 获得反馈。被训练的智能体(
获得反馈。被训练的智能体( )专注学习记忆管理策略,固定的大语言模型(
)专注学习记忆管理策略,固定的大语言模型( )负责根据记忆回答问题。
)负责根据记忆回答问题。
奖励函数设计
Mem-α 采用多维度奖励函数优化记忆构建:
- 问答准确率(
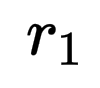 ):最核心的信号,直接衡量基于记忆回答问题的准确率
):最核心的信号,直接衡量基于记忆回答问题的准确率 - 工具调用格式(
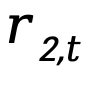 ):确保智能体正确使用记忆操作工具
):确保智能体正确使用记忆操作工具 - 记忆压缩(
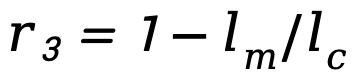 ):鼓励高效利用记忆空间
):鼓励高效利用记忆空间 - 内容有效性(
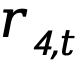 ):通过LLM评判器评估记忆质量
):通过LLM评判器评估记忆质量
最终奖励: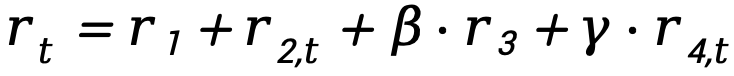 (实验发现
(实验发现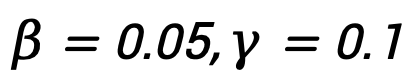 效果最佳)。
效果最佳)。
记忆系统架构
为了展示Mem-α框架的有效性,研究团队设计了一个包含三种记忆类型的复杂记忆系统,灵感来源于认知科学中的记忆分类理论:

- 核心记忆(Core Memory):存储用户的基本、持久信息(角色、偏好、目标),容量512tokens;
- 情景记忆(Episodic Memory):记录带时间戳的事件,如 “[9:15]在咖啡馆遇见Alice”;
- 语义记忆(Semantic Memory):存储结构化知识和事实,如专业知识、操作指南等。
每种记忆类型支持插入、更新、删除操作。智能体需要学习在适当时机选择合适的工具和记忆类型。
训练数据集构建
Mem-α的训练数据集的构建思路来源于MemoryAgentBench中的四个维度:
- 精确检索(Accurate Retrieval):从历史数据中提取正确信息以回答查询,涵盖单跳和多跳检索场景
- 测试时学习(Test-Time Learning):在部署期间获取新行为或能力
- 长期理解(Long-Range Understanding):整合分布在多个片段中的信息,回答需要全面序列分析的查询
- 冲突解决(Conflict Resolution):在遇到矛盾证据时修订、覆盖或删除先前存储的信息
本研究聚焦于前三个维度,排除了冲突解决维度。这是因为目前缺乏真实的评估基准——现有的冲突解决数据集主要是合成的,未能充分捕捉真实世界的复杂性。
研究团队收集并整理了来自不同源头的八个数据集,处理到统一的范式,最后构造了一个完善的数据集并保证与MemoryAgentBench的测试集没有交织,涵盖了以上的前三个维度进行训练。
实验结果
主实验:性能与泛化能力
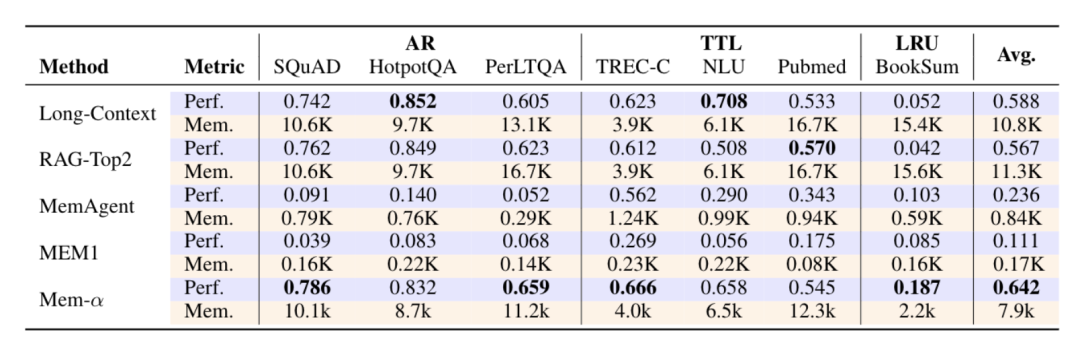
Mem-α在30k tokens上训练,在验证集(验证集也是<30k tokens的)上的效果如下:
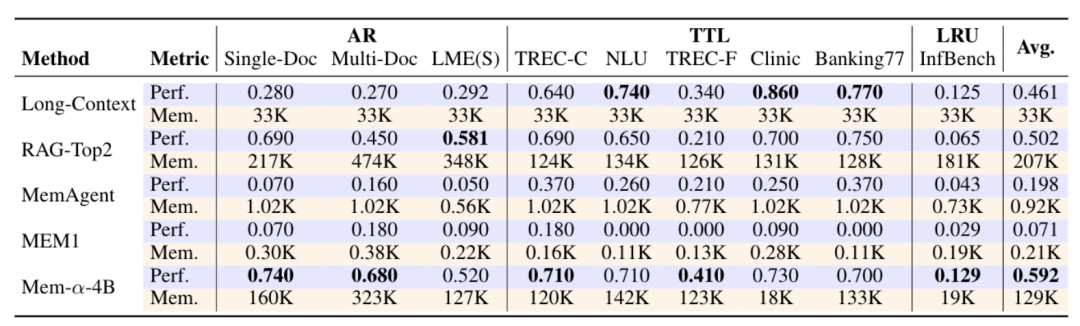
在测试集上的效果如下:
四个关键发现:
- 全面超越现有方法:在所有任务上显著优于基线。在MemoryAgentBench上,精确检索(AR)和长期理解(LRU)任务尤其突出,证明了对未见分布的强泛化能力。
- 高效记忆压缩:相比Long-Context和RAG-Top2,记忆占用减少约50%的同时保持更优性能。在BookSum和InfBench-Sum上压缩效果更佳,验证了语义压缩机制在性能和效率间的平衡。
- 结构化架构的必要性:扁平记忆基线(MEM1、MemAgent)使用单段落表示,性能明显受限,凸显了非结构化记忆在复杂信息处理中的不足。这验证了分层记忆设计和强化学习优化策略的有效性。
- 极强的长度泛化:训练时仅使用平均<30K tokens 的文档,成功泛化到超过400K tokens的文档(MemoryAgentBench 多文档数据集最长达474K),展现了训练框架对极端长度外推的鲁棒性。
消融实验:性能与泛化能力
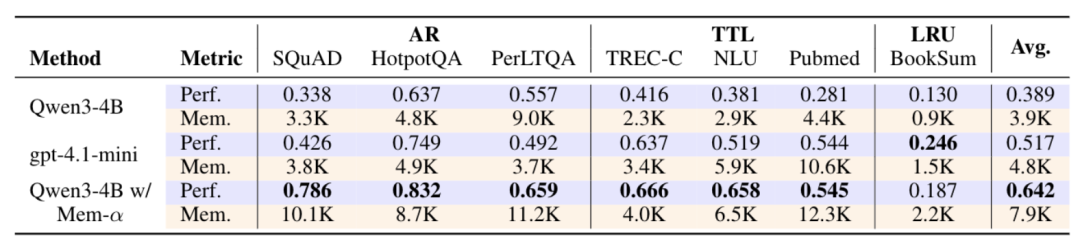
实验对比了Qwen3-4B在强化学习训练前后的表现。训练前,模型在使用复杂记忆系统时表现不佳,平均准确率仅为38.9%,且经常出现工具使用错误。
经过Mem-α训练后,同一模型的性能提升到64.2%,展现出正确的记忆管理行为。
Mem-α证明了当涉及LLM智能体的记忆管理时,学习胜过工程。
传统上被视为需要精心工程化的系统组件,实际上可以通过端到端的学习得到优化,未来,能够构建更智能、更自适应的AI系统。
论文链接:https://arxiv.org/abs/2509.25911代码仓库:https://github.com/wangyu-ustc/Mem-alpha开源模型:https://huggingface.co/YuWangX/Memalpha-4B训练数据集:https://huggingface.co/datasets/YuWangX/Memalpha测试数据集: https://huggingface.co/datasets/YuWangX/Memalpha-Memoryagentbench


