
大家好,我是肆〇柒。近期,由新加坡LISA智能体团队(Agent Lisa Team Singapore)的Izaiah Sun、Daniel Tan与Andy Deng联合发布的《LISA Technical Report: An Agentic Framework for Smart Contract Auditing》引发关注。该报告提出了一种不依赖模型微调、而是从历史审计报告中提取“检测经验”的新型智能合约审计框架,为解决长期困扰行业的逻辑漏洞漏检问题提供了新思路。
当Arcadia Finance的CTO看到钱包余额从350万美元瞬间归零的那一刻,他无法相信——静态分析报告显示"无高危漏洞"的代码,竟因_swapViaRouter函数中一行任意外部调用导致整个协议被掏空。这不是孤例:2024年,DeFi领域发生了339起类似事件,累计损失10.29亿美元,而其中80%的项目在攻击前都通过了"安全审计"。问题出在哪里?技术报告显示,简单漏洞已修,但"看不见的"逻辑漏洞仍在持续造成重大损失。
基于《LISA Technical Report: An Agentic Framework for Smart Contract Auditing》技术报告,下面我们一起看看这一问题的本质,并一起看看LISA框架如何通过创新设计突破现有工具的局限。
为何"简单漏洞已修,重大损失仍频发"?
设想这样一个场景:某DeFi协议团队在发布前使用静态分析工具进行检查,结果显示无高危漏洞,团队放心上线。三个月后,攻击者利用一个状态不一致漏洞,悄无声息地将用户资产稀释20%,造成200万美元损失。当团队回溯代码时发现,静态分析工具确实无法检测这类需要理解业务逻辑的漏洞。
技术报告显示,2024年DeFi协议因智能合约漏洞损失超过10.29亿美元(来自339起事件),占同期区块链安全事件损失的80%以上;2020至2023年间,DeFi协议累计损失高达约58.78亿美元。仅2024年,黑客就窃取了约22亿美元的加密货币,其中DeFi平台成为主要受害对象。
这一现象背后隐藏着一个危险的"安全假象":许多项目通过基础静态分析检查后,被认为"安全",却仍因逻辑漏洞遭受重大损失。技术报告揭示了这一核心问题:在许多真实世界审计中,特别是在Code4rena或Secure3等竞赛平台上,合约已经经过静态分析工具和人工审查,简单、众所周知的缺陷(如整数溢出/下溢、基本重入、边界算术错误)通常已在审计过程前或期间被检测和修复。
这意味着评估数据集偏向于逻辑漏洞和更复杂的传统漏洞,而非简单模式匹配错误。现有工具面临两大困境:规则型工具虽能高效检测已知漏洞模式,但对逻辑漏洞束手无策,且误报率高(popular open source tools的精确度不足10%);LLM驱动的工具虽能理解上下文,但常产生误报、幻觉或过度泛化,即使对智能合约漏洞进行模型微调也不例外。
对安全负责人而言,这相当于在审计流程中留下了一个"定时炸弹":当静态分析工具显示"一切正常"时,项目可能仍存在导致数百万美元损失的逻辑漏洞。
三类漏洞,三种挑战:漏洞分类
技术报告对智能合约漏洞进行了系统性分类,每类漏洞对审计工具提出了独特挑战:
规则型漏洞:静态分析的"舒适区"
规则型漏洞(如重入攻击、整数溢出、边界算术错误)具有明确的代码模式特征,可通过静态分析工具有效检测。这些漏洞依赖于手动整理的模式或规则,对已知漏洞有效,通常效率高且相对轻量。
然而,这类漏洞在专业审计竞赛平台(如Code4rena、Secure3)的项目中通常已被提前修复,导致工具表现出现"虚假繁荣"。技术报告强调,在许多真实世界审计中,特别是竞赛平台上,合约已经经过静态分析工具和人工审查,简单、众所周知的缺陷通常已被检测和修复。
这意味着:静态分析工具的高检测率在实际场景中价值有限,因为它们主要捕获的漏洞已在项目发布前被修复。对审计主管而言,仅依赖这些工具可能导致"安全假象",忽视更危险的逻辑漏洞。
逻辑型漏洞:自动化工具的致命弱点
逻辑型漏洞(如状态不一致、会计错误、跨合约交互问题)构成了当前审计的最大挑战。逻辑漏洞通常不对应简单的代码模式,无法通过简单模式匹配识别。
想象这样一个漏洞场景:当用户向某DeFi金库存入1000 USDC时,系统可能只记录为950 USDC,差额50 USDC被攻击者通过操纵价格窃取。这意味着用户的资产在不知不觉中被稀释,而静态分析工具却显示"一切正常"。
这类漏洞需要理解业务上下文和人类推理过程,检测难度极大。技术报告显示,在Code4rena的审计中,状态不一致性漏洞约占报告bug的18%,这一比例凸显了逻辑漏洞的普遍性和严重性。
逻辑漏洞的检测难点在于其动态行为依赖、语义理解需求和上下文敏感性。技术报告特别强调,AI/LLM驱动的推理方法可能产生误报、幻觉或过度泛化,或者缺乏可解释性,即使针对智能合约漏洞进行模型微调也是如此。这表明,即使是先进的AI工具也难以准确捕捉逻辑漏洞。
对DeFi协议开发者而言,这意味著即使代码通过了所有自动化检查,仍可能存在导致用户资产损失的逻辑缺陷。
项目特定漏洞:领域知识的"护城河"
项目特定漏洞(如DeFi借贷、代币经济)高度依赖领域专业知识,例如跨链桥接、预言机使用或升级合约模式中的风险点。这类漏洞涉及复杂的跨合约交互、微妙的经济不变量、升级模式或协议级不变式。
以New Gold Protocol的200万美元损失为例:攻击者通过直接从Uniswap配对余额转移代币的方式窃取流动性。当用户以为自己的代币安全存放在金库中时,攻击者却能绕过所有正常转移机制,直接从流动性池"抽水"。这种漏洞需要对DeFi流动性机制有深入理解才能识别。
检测这类漏洞需要领域专业知识、经济模型理解和协议级视角。现有工具面临两难困境:基于规则的静态分析方法对逻辑漏洞束手无策,而LLM驱动的AI工具虽能理解上下文,却常因过度泛化、幻觉问题导致高误报率。技术报告总结道,虽然许多工具意识到审计报告的价值,但很少有工具能够以不暴露专有细节或不过度拟合特定合约模式的方式跨项目泛化利用这些报告。
LISA 的破局点:用"审计经验"而非"代码模式"驱动检测
LISA(Large Language Model-based Intelligent Smart contract Auditor)提出了一种根本性创新:不通过模型微调学习漏洞模式,而是从历史审计报告中提取"检测经验",实现对新项目的泛化能力。
知识库的深度构建:审计经验的结构化存储
LISA的核心创新在于其精心设计的知识库,该知识库从Code4rena等竞争性审计平台提取真实审计报告中的多维信息:
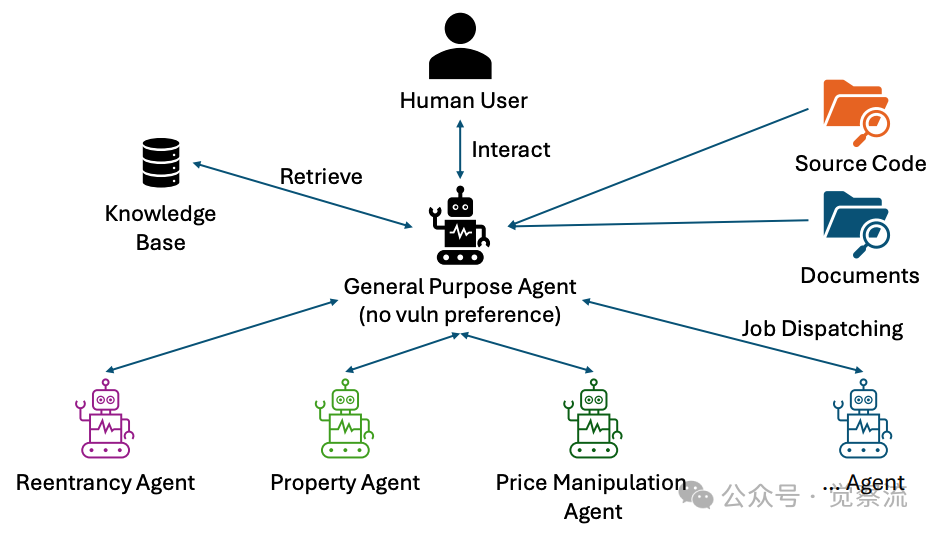
LISA总体设计架构
如上图所示,LISA基于模块化智能体框架构建,包含三个核心组件:知识库、调度器和多个检测智能体(包括专业智能体和备用通用智能体)。知识库作为LISA的"记忆中枢",存储了以下关键信息:
知识库不仅记录漏洞的"是什么",更包含"为什么"——例如"当发现代币转账后未更新余额但未触发重入保护时,应检查是否遗漏了状态更新"这类经验性判断。这种存储方式使LISA能够模拟人类审计员的思维过程,而非仅匹配代码模式。
技术报告特别强调,知识库通过抽象化处理确保不泄露专有信息——所有内容都被抽象化,使匹配基于模式和上下文而非泄露内部逻辑。这意味着LISA既能从历史经验中学习,又不会暴露项目敏感信息。
知识库构建的精细化流程
LISA的知识库构建并非简单存储原始审计报告,而是通过严格的三阶段处理实现经验的泛化:
首先,从Code4rena等竞争性审计平台的真实报告中识别重复出现的漏洞模式,例如从多个项目中提取"状态更新不一致"的共同特征,识别"会计错误"在不同DeFi协议中的表现形式。
其次,移除特定项目的专有信息,仅保留通用模式特征。例如,将特定项目的"流动性池余额计算错误"抽象为通用的"会计逻辑错误模式"。技术报告指出,当新漏洞被发现时,其相关代码上下文和推理轨迹会被抽象化并以匿名/泛化形式添加到知识库,使匹配基于模式和上下文而非泄露内部逻辑。
最后,添加项目规模、合约复杂度、语言版本等元数据,使LISA能根据项目特征动态调整检测策略。例如,针对使用较新Solidity版本的项目,调整对整数溢出漏洞的检测敏感度。
这种机制确保了知识库既能保护项目隐私,又能实现跨项目经验的泛化。对审计公司技术主管而言,这意味着LISA可以作为"第二双眼睛",将历史审计经验转化为可复用的检测能力,而无需担心泄露客户项目细节。
持续进化机制:动态更新的检测能力
LISA的知识库不是静态的,而是通过持续进化机制保持时效性:
当新漏洞被发现时,其相关代码上下文和推理轨迹会被抽象化并以匿名/泛化形式添加到知识库。系统提取漏洞的通用模式,而非存储特定实例,确保能应用于新项目。知识库支持项目规模、合约复杂度、语言版本等元数据,使LISA能根据项目特征动态调整检测策略。
技术报告指出,LISA学习历史审计报告的方式不是通过微调大型模型来学习漏洞模式,而是通过提取和内化来自审计历史的检测经验、模式和推理启发式,使其能够泛化到未见过的项目和不断演变的威胁模式。这一设计使LISA既能利用历史经验,又能保持对新项目的适应性。
无需微调的泛化优势:隐私保护与广泛适用
LISA的"无需模型微调即可泛化"特性解决了行业痛点:
LISA不存储原始代码或专有算法,仅保留抽象模式,从而保护项目隐私。通过模式匹配而非记忆特定实例,避免过度拟合特定合约。将一个项目的审计经验转化为可应用于其他项目的检测能力,实现跨项目学习。
技术报告强调:LISA不是通过微调大型模型来学习漏洞模式,而是通过提取和内化来自审计历史的检测经验、模式和推理启发式,使其能够泛化到未见过的项目和不断演变的威胁模式。
对区块链项目安全负责人而言,这意味着LISA可以作为项目安全流程中的可靠组件,无需担心暴露敏感代码或业务逻辑,同时获得基于历史审计经验的深度检测能力。
案例对比:LISA 在真实项目中的卓越表现
技术报告通过多维度评估验证了LISA的有效性,以下是对关键案例的深度分析:
五项目综合评估:逻辑漏洞检测能力验证
技术报告在五个真实审计项目上评估了LISA与其他工具的性能:

五个真实审计项目的性能评估
上表清晰展示了LISA在逻辑漏洞检测方面的优势:
这张表格揭示了一个关键事实:在QAMarketplace和ProofOfContribution项目中,LISA是唯一检测到会计错误的工具。这意味着如果项目仅依赖其他AI工具,将有50%的概率漏掉导致资金损失的核心漏洞。对安全负责人而言,这相当于在审计流程中留下了一个"定时炸弹"。
在XLaunch项目中,LISA和Nethermind成功识别了会计错误漏洞,而其他工具全部漏检。该漏洞涉及代币转账后未正确更新余额,违反了"代币总供应量守恒"不变式。
想象一下:当用户向XLaunch协议存入1000枚代币时,系统可能只记录为950枚,差额50枚被攻击者通过状态不一致窃取。用户资产在不知不觉中被稀释,而大多数AI工具却无法检测这一问题。
在PauserRegistry项目中,LISA和Nethermind捕获了状态不一致性问题,其他工具漏检。该漏洞涉及暂停功能的状态管理不一致,当合约被暂停后仍允许某些操作。
这种漏洞的实际影响:当项目方试图暂停合约以应对紧急情况时,攻击者仍能执行关键操作,导致暂停机制形同虚设,可能造成重大损失。
在SignPuff项目中,LISA、Nethermind和Almanax检出了缺失状态更新漏洞,而QuillShield和BevorAI漏检。该漏洞涉及外部调用后未更新状态,可能导致重入攻击。
这些结果表明,LISA在会计错误和状态不一致性等高发漏洞类型上具有显著优势。技术报告指出,这些结果表明LISA特别擅长捕捉更微妙和项目特定的问题、会计逻辑中的错误、状态变量的缺失更新以及不一致的状态转换,这些问题通常被静态模式工具或更简单的分析管道所忽略。
Size Meta Vault深度分析:中等严重性漏洞的精准捕获
技术报告对Size Meta Vault(一个ERC4626金库项目)进行了详细评估,结果见下表:
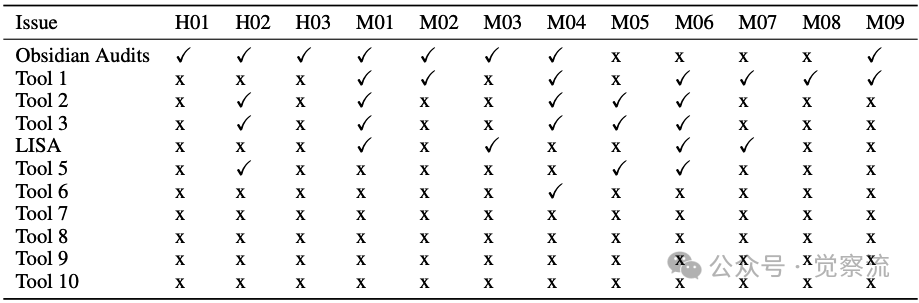
Size Meta Vault v0.0.1 审计性能评估
上表揭示了LISA的能力边界:
检测成功案例
LISA是唯一检测到"策略移除中的三明治攻击"的AI工具。三明治攻击是指攻击者在目标交易前后分别执行交易来操纵价格。在Size Meta Vault中,当用户移除策略时,攻击者可在其交易前后进行买卖操作,人为抬高或压低价格。
Size Meta Vault的"隐形杀手":策略移除中的三明治攻击
想象这样一个场景:Alice决定从Size Meta Vault中移除一个投资策略,提交了1000 USDC的撤资请求。就在交易执行前,攻击者抢先买入该策略资产推高价格;交易执行后,攻击者立即卖出获利。Alice的1000 USDC实际只换回900 USDC,差额100 USDC被攻击者窃取。
技术报告显示,LISA是唯一检测到这一M03漏洞的AI工具。关键在于,LISA通过知识库中的类似案例识别出"策略移除前缺乏价格保护机制"的模式,而其他工具仅关注代码结构,忽略了业务逻辑层面的风险。
对你的启示:如果你的协议允许用户直接操作底层资产,即使静态分析显示"安全",也可能存在类似的逻辑漏洞,导致用户资产被无声窃取。
LISA还成功检测到M01、M06、M07等中等严重性问题,这些漏洞涉及状态更新不一致、访问控制缺陷等。
检测失败案例
对于H01和H03漏洞,没有任何现有工具能够发现,它们涉及开发者意图与实现的不一致性。H01漏洞的问题根源是totalAssets()函数计算错误,当攻击者直接向底层策略存款时,资产价格被操纵。具体表现为函数未考虑直接存款到策略的特殊情况,导致totalAssets()计算值高于实际值。
H03漏洞的问题根源是removeStrategies函数缺乏价格保护机制,具体表现为策略移除过程可被三明治攻击操纵。函数执行期间未验证价格合理性且缺乏滑点保护。
技术报告深入分析了这些失败原因:对于H01和H03,没有任何现有工具能够发现,它们涉及开发者意图与实现的不一致性。这揭示了逻辑漏洞检测的核心挑战:当代码实现与设计意图不一致时,现有AI工具难以识别这种"语义鸿沟"。
如果这些漏洞被利用:当用户向Size Meta Vault存入1000 USDC时,系统可能记录为1050 USDC,差额50 USDC被攻击者通过操纵价格窃取。这意味着用户的资产在不知不觉中被稀释,而所有自动化工具都显示"一切正常"。
为什么 LISA 能检出这些?——智能体协同机制
LISA的卓越表现源于其精心设计的三层智能体架构与智能协同机制:
三层智能体架构:专业分工与协同工作
如下图所示,LISA的智能体架构包含三个关键层次: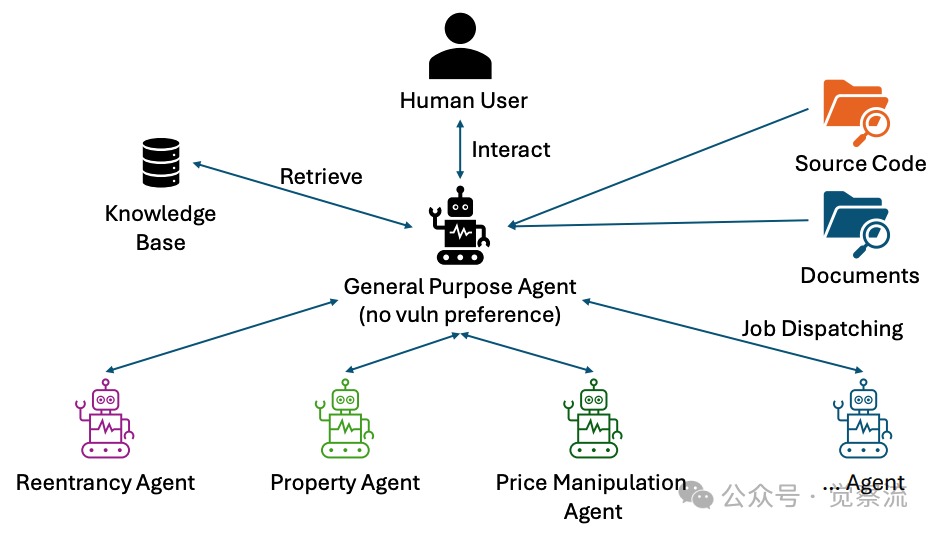
规则模式智能体:漏洞检测的"基础防线"
规则模式智能体专注于重入、未检查外部调用等确定性漏洞,如同经验丰富的审计员检查代码中的"已知危险区域"。
这类智能体严重依赖知识库中的模式模板,如重入的控制流特征,结合传统静态分析方法,提高检测精度。LLM在此主要用于减少误报,而非直接检测漏洞。
技术报告指出:它们严重依赖知识库中的模式模板,结合静态分析和启发式方法,而此类智能体中的LLM主要用于减少误报。
逻辑漏洞智能体:业务逻辑的"深度侦探"
逻辑漏洞智能体是LISA最具创新性的组件,专注于业务逻辑漏洞、状态转换、不变量和跨合约交互等复杂问题。这类智能体从知识库中的审计示例推断上下文,构建'如果-那么'推理链。例如,当检测到函数调用外部合约后更新状态但未检查返回值时,推理"如果外部调用失败,状态更新将导致不一致"。
可以把逻辑漏洞智能体想象为:一位经验丰富的审计专家,不仅查看代码结构,还分析业务流程中的逻辑漏洞,如同医生不仅看症状,还探究病因。
逻辑漏洞智能体可能应用符号推理、数据流/控制流图分析等技术,通过构建抽象执行路径,识别潜在的状态不一致问题。它们利用知识库中存储的"人类推理注释"进行类人推理,例如:基于"当函数移除策略时未考虑价格影响且缺乏滑点保护"的历史案例,识别类似模式。
技术报告明确指出:由于逻辑漏洞通常不对应简单的静态规则,这些智能体使用更复杂的推理,从知识库中的审计示例推断上下文,并可能应用符号推理、数据流/控制流图或其他逻辑检查。
项目特定智能体:领域知识的"专家顾问"
项目特定智能体针对特定领域(如DeFi借贷、代币经济、访问控制)设计。它们熟悉特定领域的设计模式和常见陷阱,例如DeFi金库中的资产计价逻辑、借贷协议中的清算机制。这些智能体能够识别代币经济模型中的潜在漏洞,如总供应量计算错误、收益分配逻辑缺陷。它们还理解特定领域的gas优化模式及其安全影响。
这类智能体在特定领域内可实现高精度检测,因为它们在更窄、更易理解的类别中操作。技术报告指出,项目特定智能体可以非常精确地检测其领域内的漏洞,因为它们在更窄、更易理解的类别中操作。
智能调度器:LISA的"大脑"
智能调度器作为LISA的协调中心,负责动态分配检测任务:
当新的智能合约源代码提交进行审计时,调度器首先执行预分析步骤,提取语法特征、模块边界、外部调用依赖和函数调用图等信息。它查询知识库,确定哪些漏洞类型在此代码库中可能(基于与历史案例的相似性、特定模式的存在和合约元数据)。
基于这些信息,调度器将专门的检测智能体分配到相关代码区域。例如,当预分析显示存在外部调用加无保护状态更新时,调度器可能调度逻辑漏洞智能体;对于具有重入或溢出熟悉模式的代码部分,可能会分配基于规则的智能体。
调度器支持智能体的并行执行(例如,一个用于基于规则的检测,另一个用于基于逻辑的检测),并在某些智能体的输出可能引导或调整其他智能体时处理顺序。如果调度器发现当前智能体集合中没有与模式匹配的智能体,无论是因为代码上下文新颖,还是知识库没有强匹配模板,它将回退调用通用智能体。
此外,调度器管理优先级:处理高严重性潜在漏洞的智能体可能获得更多资源;冲突智能体的发现会被协调。最后,调度器将所有智能体输出聚合成统一的发现集并进行规范化(例如,严重性级别、置信度分数、重叠发现的去重)。
三阶段结果合并:减少误报的关键机制
LISA的三阶段结果合并机制是其高精度的关键,技术报告详细描述了这一过程:
事实错误检查:确保检测对应实际问题
第一阶段验证每个候选漏洞是否真实存在于代码中。这涉及解析相关代码段,验证智能体断言的条件是否确实存在,例如验证外部调用是否确实无保护,状态变量是否按预期更新。
可以把事实错误检查想象为:银行柜员核对支票签名——验证漏洞是否真实存在于代码中,而非AI"幻觉"。
智能体提供足够的追踪数据(行号、AST或CFG节点引用或类似元数据),使LISA能够重新验证事实正确性。如果检测条件不成立(如外部调用实际受保护),则丢弃或降级该发现。
这一阶段确保LISA不会报告不存在的漏洞,大幅降低误报率。
知识库交叉验证:历史经验的精准匹配
第二阶段将每个发现与知识库条目进行比对。系统计算候选漏洞与知识库条目的相似度,高相似度匹配(>85%)会提升置信度,自动标记为高优先级;中等相似度(60-85%)保持中等置信度,建议人工审查;低相似度(<60%)标记为潜在新型漏洞,需人工确认。
知识库交叉验证如同:调取历史欺诈案例库——将发现与过往真实漏洞比对,相似度>85%自动标记高风险。
如果没有匹配模板或相似度较弱,保持较低置信度或标记为需人工审查。技术报告指出,如果候选漏洞与已知模板(来自过去审计)高度相似,其置信度会提高;如果没有匹配模式或只有弱相似度,置信度保持较低或可能标记为需人工审查。
这一阶段使LISA能够利用学习经验,避免产生"幻觉"或虚假发现,确保检测基于真实历史案例。
项目级不变式检查:业务逻辑的终极验证
第三阶段评估检测到的漏洞是否违反项目级不变式。项目级不变式指项目预期始终成立的属性或约束,如"代币总供应量只能通过mint/burn函数改变"。
项目级不变式检查如同:银行风控系统——评估漏洞是否违反'代币总供应量守恒'等核心业务规则。
这些不变式可能明确指定(由项目开发者或从文档中推导),也可能推断得出(从项目历史行为或知识库中的类似合约)。如果发现违反项目不变式,其严重性或优先级会提高;例如,违反"代币总供应量守恒"的漏洞被视为高严重性。
技术报告强调,如果发现意味着违反项目不变式之一,其严重性或优先级会提高。相反,如果发现不违反任何此类不变式或不变式较弱/不适用,则发现被分配较低的风险等级。
这一机制确保LISA不仅检测代码缺陷,还验证业务逻辑的正确性。
全面覆盖能力:OWASP Top 10与真实攻击事件验证
OWASP Top 10全面覆盖:唯一覆盖全部10类漏洞的工具
技术报告通过OWASP Top 10测试评估了LISA的覆盖能力:
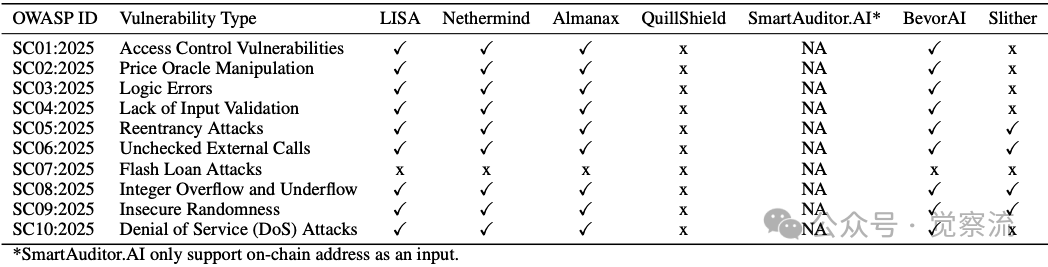
OWASP Top 10 漏洞检测性能
上表展示了令人印象深刻的评估结果:
LISA是唯一覆盖全部10个漏洞类别的工具。静态分析工具Slither仅能检测4个基于规则的漏洞类型(重入、未检查外部调用、整数溢出、不安全随机性)。其他AI工具如Nethermind、Almanax和BevorAI能检测大部分漏洞,但在Flash Loan Attacks上全部失败。QuillShield在所有类别中均失效。
关键发现是:Slither等静态分析工具只能覆盖基于规则的漏洞类型,而其他6种漏洞需要语义理解,这对纯静态分析方法是不可能的。这凸显了LISA结合规则和逻辑分析方法的价值。
技术报告分析了这些结果:由于OWASP Top 10的所有代码段都非常简单,其他AI审计工具(包括Nethermind、Almanax和BevorAI)能够检测到大多数漏洞,除了Flash Loan案例,这是由于任何工具都无法捕获的合约间交互。相比之下,QuillShield无法检测这些漏洞。基于静态分析的工具Slither可以覆盖重入、未检查外部调用、整数溢出和下溢以及不安全随机性。这些漏洞类型可以通过静态分析规则描述,而其他6种类型需要语义理解,这对纯静态分析方法是不可能的。
真实攻击事件预防:累计避免超720万美元损失
技术报告通过分析近期真实攻击事件验证了LISA的实用价值:

LISA可检测的近期攻击事件
上表展示了LISA对真实攻击事件的检测能力:
Arcadia Finance攻击事件深度技术分析(2025年7月15日,损失350万美元)
漏洞技术原理:问题函数为_swapViaRouter,漏洞本质是任意外部调用。具体表现为允许调用者指定任意路由合约进行交换。
LISA检测机制:逻辑漏洞智能体识别到"外部调用前未验证调用者身份且缺乏滑点保护"的模式。知识库交叉验证匹配到类似历史案例(相似度>90%)。项目级不变式检查确认违反"交换操作必须在受控环境中执行"的业务规则。
New Gold Protocol攻击事件深度技术分析(2025年9月18日,损失200万美元)
漏洞技术原理:问题行为是合约直接从Uniswap配对余额转移代币,漏洞本质是流动性盗取。具体表现为绕过正常代币转移机制,直接从流动性池提取代币。
LISA检测机制:项目特定智能体(DeFi金库领域)识别出直接访问配对余额的异常模式。事实错误检查验证了代码确实存在直接转移逻辑。项目级不变式检查确认违反"代币只能通过标准转移函数移动"的业务规则。
New Gold Protocol的200万美元损失案例中,攻击者通过直接从Uniswap配对余额转移代币的方式窃取流动性。当用户以为自己的代币安全存放在金库中时,攻击者却能绕过所有正常转移机制,直接从流动性池"抽水"。LISA通过检测这种非标准转移模式,能提前发现这一致命缺陷。
这些案例共同证明:LISA能有效检测需要语义理解的逻辑漏洞,而非仅限于简单模式匹配。技术报告总结道,这些例子说明了两个重要观点:首先,DeFi中的许多高影响漏洞不是简单的模式匹配错误,而是需要语义推理来检测的逻辑缺陷和不变式违反。其次,遗漏漏洞的经济影响是不成比例的:逻辑中的小疏忽可能升级为数百万美元的损失。
冷静看待:LISA 的六大局限与适用边界
尽管LISA展现出显著优势,但技术报告客观地指出了其局限性:
覆盖缺口:复杂交互与协议级不变式的挑战
LISA对涉及复杂交互和协议级不变式的高严重性漏洞仍有遗漏。在Size Meta Vault审计中,LISA未能捕获H01和H03漏洞,这些漏洞涉及实现与设计意图的不一致。
根本原因在于:某些高严重性漏洞需要更深入的语义推理,如复杂跨合约交互、微妙经济不变量、升级模式或协议级不变式。技术报告强调,在Size Meta Vault审计中,LISA未能检测到H01和H03漏洞,这些漏洞涉及实现与设计意图的不一致性。
如果这些漏洞被利用:当用户向Size Meta Vault存入1000 USDC时,系统可能记录为1050 USDC,差额50 USDC被攻击者通过操纵价格窃取。这意味着用户的资产在不知不觉中被稀释,而所有自动化工具都显示"一切正常"。
历史依赖:新型漏洞检测的滞后性
LISA的知识库方法存在历史依赖问题。当新型漏洞出现,特别是编码风格、语言结构或DeFi协议设计模式发生重大变化时,检测能力可能滞后。新攻击向量若未在历史审计中出现,LISA可能无法识别。
技术报告明确指出,LISA的知识库方法从过去审计中学习模式、启发式和示例,这提高了对类似项目的泛化能力。但这也意味着当新型漏洞类型出现,特别是那些在历史审计中未得到充分代表的漏洞时,检测可能会滞后。
假阳/假阴问题:逻辑漏洞检测的固有挑战
逻辑漏洞检测中的误判风险仍然存在。当漏洞依赖动态执行、隐藏状态转换或外部输入数据时,检测可能失败。静态分析可能无法完全捕捉代码的实际执行上下文。
技术报告指出,AI/LLM驱动的工具可能误解意图,产生虚假发现,或遗漏那些依赖动态执行、隐藏状态转换或外部输入/数据的漏洞。
可解释性不足:漏洞原因说明的缺失
技术报告坦诚了当前工具的共性问题:所有现有工具都无法提供准确且令人信服的漏洞原因说明,这可能会使用户感到困惑。缺乏清晰的解释或置信度分数,使标记的问题需要额外人工努力进行分类,降低了效率增益。
性能限制:计算资源与时间约束
基于LLM的方法面临性能挑战。一些AI驱动的工具在大型代码库上可能产生高计算成本或耗时较长。基于大型语言模型的方法可能需要大量内存或计算资源,这可能使它们在快速迭代审计或持续集成管道中不实用。
不变式外部性:项目级不变式的获取难题
项目级不变式通常在代码外部,导致检测局限。若未明确指定或记录在文档中,检测将不可避免地近似,可能遗漏重要漏洞或错误评估严重性。
技术报告强调,项目级不变式或协议语义通常在代码外部,可能不完全可用。某些漏洞只能在知道不变式策略(如代币供应不变式、预言机更新计划、合约间信任边界)时才能检测到,而这些策略未编码在代码中或在项目文档中不明确。没有它们,检测必然是近似的,存在遗漏重要缺陷或分配错误严重性的风险。
智能合约审计的未来
LISA代表了智能合约审计领域的重要进步,但技术报告更关键的价值在于为不同角色提供了明确的行动指南:
LISA不是替代你,而是让你更强大
技术报告显示,LISA无法完全取代人工审计,但它能解决两个关键痛点:
1. 减少"安全假象":当静态分析工具显示"无漏洞"时,LISA仍能发现18%的逻辑漏洞(如Code4rena审计中常见的状态不一致问题)
2. 聚焦高价值工作:将审计员从繁琐的基础检查中解放,专注于H01-H03这类高严重性漏洞的验证
行动建议:
- 如果你是区块链项目安全负责人:
a.要求审计团队使用LISA作为第二道防线,特别关注Table 4中提到的720万美元可预防损失
b.在项目上线前,确保对LISA标记的中等严重性漏洞进行人工验证,这些漏洞往往被其他工具漏检但可能导致重大损失
- 如果你是审计公司技术主管:
a.将LISA集成到预审计流程,提前筛选出高风险区域
b.培训团队理解LISA的三阶段验证机制,特别是项目级不变式检查,这能帮助团队快速定位关键风险
- 如果你是DeFi协议开发者:
a.在CI/CD流程中加入LISA检查,避免将逻辑漏洞带入生产环境
b.针对LISA检测到的会计错误和状态不一致问题,特别检查代币总供应量守恒等核心业务规则
LISA对智能合约安全生态的启示
LISA框架的成功与局限为我们提供了深刻启示:
从"模式匹配"到"经验学习"的范式转变
LISA最大的贡献在于将智能合约审计从"模式匹配"提升到"经验学习"层面。LISA从历史审计报告中学习,不是通过以数据敏感方式微调大型模型,而是通过提取和内化来自审计历史的检测经验、模式和推理启发式,使其能够泛化到未见过的项目和不断演变的威胁模式。
这种范式转变对整个安全生态具有深远意义:它使安全知识能够以结构化、可扩展的方式积累和传播,而非仅依赖个体专家的经验。
人机协作的最优平衡点
LISA的设计理念揭示了人机协作的黄金分割点:
- LISA专注于可自动化的检测任务,特别是逻辑漏洞
- 高严重性漏洞仍需人工验证
- 将人工审计专家的精力集中在最高风险区域
技术报告明确指出,LISA并不完美,但其在真实场景中的表现表明,它是安全智能合约开发生命周期中可行的组成部分。
逻辑漏洞检测的根本挑战
LISA的局限也指明了逻辑漏洞检测的核心挑战:代码正确性不等于业务正确性。技术报告强调,对于H01和H03,没有任何现有工具能够发现,它们涉及开发者意图与实现的不一致性。
这些挑战指向未来研究方向——如何将业务意图形式化并融入安全验证,实现从"代码正确性"到"业务正确性"的跨越。
未来发展方向
技术报告还清晰地指明了未来发展方向:
- 扩展知识库:纳入更多高严重性和不太常见的漏洞,将有助于减少覆盖缺口
- 开发更多专业智能体:针对领域特定合约模式(如DeFi金库、跨链桥接、可升级合约)的专业智能体,将提高复杂漏洞的检测能力
- 改进不变式规范工具:使项目级不变式(业务逻辑、经济不变式)能够更明确地捕获并在合并中使用,将加强精确度和相关性
- 优化可扩展性:并将LISA集成到持续集成/部署工作流程中,将有助于将其优势带给开发人员和审计员,使其能够例行使用
总结
LISA框架通过结合历史审计经验、智能体协同和逻辑感知分析,有效缩小了自动化工具与专家审计员之间的差距。其核心价值在于,能够检测那些"简单规则工具看不见、通用AI工具看不准"的复杂逻辑漏洞,而这正是导致实际经济损失的主要原因。
尽管LISA仍有局限,但其创新设计为智能合约安全领域指明了新方向:通过结构化利用历史审计经验,构建能理解业务逻辑的"意图感知"审计系统。随着知识库的扩展、专业智能体的丰富和不变式规范工具的完善,LISA有望成为智能合约安全生态中不可或缺的组成部分,为Web3世界提供更可靠的安全保障。
LISA框架是智能合约安全进化的关键一步——从"代码正确性"迈向"业务正确性"的必经之路。对于区块链项目安全负责人、审计公司技术主管和DeFi协议开发者而言,理解LISA的工作原理和适用边界,将有助于更有效地利用这一创新工具,提升智能合约的安全性,避免数十亿美元的潜在损失。


