
大家好,我是肆〇柒。大语言模型(LLM)在翻译、问答等任务中展现了卓越能力,但其在事实准确性与复杂推理上仍存在显著缺陷。为弥补这一短板,多智能体(Multi-Agent)范式被研究者提出:通过多个LLM协同工作(如辩论、验证、纠错),利用集体智慧超越单一模型的局限。这一思路已被证明有效,例如通过多模型辩论提升事实性。
然而,现有方法面临严峻挑战。首先,计算成本高昂。像ACC-Collab和SCoRe这类方法需要联合训练多个模型,其训练开销与模型数量呈线性甚至更高增长,难以扩展。其次,部署缺乏灵活性。大多数方案要求所有智能体在推理时必须在线,这不仅增加了延迟,也限制了在资源受限场景下的应用。最后,许多方法(如多智能体辩论)依赖于"涌现行为",即假设通用大模型天生具备协作能力,而未对其进行显式训练与优化,其协作效果不稳定且不可控。
这引出了一个根本性的矛盾:
- 一方面,显式训练多个模型(如ACC-Collab)能有效提升协作性能,但计算成本高昂,难以扩展;
- 另一方面,不训练模型(如MAD)虽然成本低,但协作效果依赖于涌现,性能上限有限且不可控。
因此,一个更根本的问题是:我们能否找到一种方法,既拥有显式训练带来的性能提升,又避免训练多个模型的高昂成本?
由字节跳动Seed提出的MLPO(Multi-agent guided Leader Policy Optimization)框架,正是对这一问题的有力回答。它提出了一种分层、高效且灵活的协作推理新范式,其核心在于训练一个"领导者"来协调一群"未训练的智能体"。
方法论:MLPO框架
整体架构:分层多智能体系统
MLPO的核心思想是构建一个分层的多智能体系统,其结构简洁而高效:一个领导者(Leader) + K个未训练的智能体(Agents)。
- 领导者(Leader):这是系统中唯一被训练的模型。它的核心职责是接收来自智能体团队的多样化响应,对其进行批判性评估、聚合与综合,最终生成一个高质量的结构化答案。
- 智能体团队(Agent Team):由K个现成的、未经训练的LLM(如论文中使用的Llama 3.1、Gemma2、Qwen2.5)组成。它们的角色是作为"思想贡献者",提供多样化的初步解决方案。
这一设计带来了两大核心优势。首先是训练效率的革命性提升。传统的多智能体训练方法需要同步优化多个大模型,计算成本极高。而MLPO仅需优化一个领导者模型,其余智能体保持冻结,这使得训练过程变得轻量且可扩展。其次是部署的极致灵活性。训练完成的领导者具备双重身份:它既可以作为一个强大的独立模型进行零样本(zero-shot)推理,无需任何智能体参与;也可以在需要更高精度时,与智能体团队协同工作,实现性能的进一步跃升。
推理流程:迭代式反馈与精炼
MLPO的推理过程是一个精心设计的T轮迭代循环(如下图所示),形成了一个领导者与智能体团队之间的闭环反馈系统。
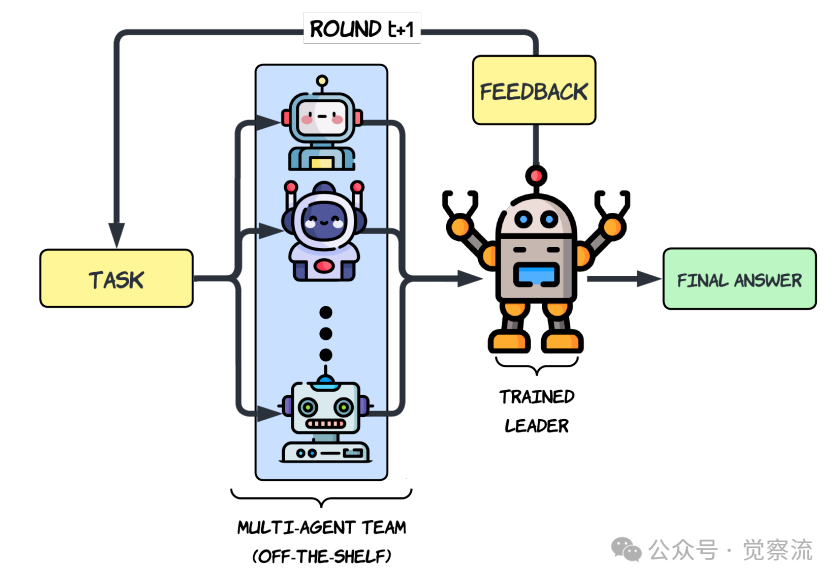
分层多智能体推理架构概览
- 初始生成(Round 0):对于给定任务 ,K个智能体模型并行地、独立地生成各自的初步解决方案 。
- 领导者聚合(Leader Aggregation):领导者模型 接收任务 和所有智能体的初步响应 ,生成一个结构化的输出 。该输出被强制分为两个部分:<think> 标签内的详细推理链,和 <answer> 标签内的最终答案。
- 智能体修订(Agent Revision):在后续轮次(),每个智能体会基于原始任务 、自身的上一轮答案 以及领导者的上一轮输出 ,来修订和改进自己的答案,即 。
- 循环精炼:领导者再次聚合更新后的智能体答案,生成新的 。这个过程循环往复,直到第 轮结束,最终答案从领导者最后一次输出中提取。
这一流程的关键设计在于其结构化输出和闭环反馈机制。结构化输出强制领导者分离思考与结论,便于监督学习和优势估计。闭环反馈则使领导者不仅是被动的"聚合器",更扮演了主动的"导师"角色,其输出为智能体提供了改进方向,从而引导整个团队向更优解收敛。
为实现上述结构化输出,领导者和智能体均采用精心设计的提示词(Prompt)。领导者被明确要求先进行详细的"思考"(<think>),再给出"答案"(<answer>),并以""格式结束。智能体在后续轮次中会接收领导者的反馈,并据此反思和修订。这种结构化的交互协议确保了信息的清晰传递和迭代优化的有效性。
训练流程:多智能体引导的领导者优化
MLPO的训练采用两阶段策略,是为了系统性地培养领导者的核心能力。
第一阶段 监督微调(SFT):- 目标:培养领导者的自我修正与回溯能力(backtracking),即在意识到错误后能自然地纠正。- 方法:首先,用一个未训练的领导者对每个训练任务生成16个答案。筛选出那些至少有一个正确和一个错误答案的任务。然后,构造一个提示(prompt),要求一个未训练的领导者基于一个正确的和一个错误的聚合响应,生成一段包含"从错误推理开始,然后自我纠正到正确答案"的自然推理链(例如,使用"等等,这似乎不对…"这样的短语)。- 论文发现:SFT阶段能提升性能,但并非不可或缺。实验表明,最大的性能增益主要来自于后续的GRPO阶段,SFT带来的提升相对有限(约1-2%)。
第二阶段 多智能体引导的GRPO(MLPO):比如可以想象,领导者在参加一场特殊的"考试"。
- 考试题目:一个复杂的任务(比如一道数学题)。
- 参考材料:考卷上已经附上了三份不同的"参考答案"(即来自智能体团队的解答)。
- 评分标准:最终得分只看领导者自己写出的最终答案是否正确。
在这个考试中,领导者需要做的是:1. 阅读和分析这三份参考答案,判断哪些是正确的,哪些是错误的,以及错误的原因。2. 综合这些信息,写出自己的最终答案。
训练过程就是让领导者反复参加这种"考试"。如果它最终答对了,它就"得分";答错了,就"不得分"。通过大量的练习,领导者会逐渐学会:如何从这些参考答案中提取有价值的信息,并避免被错误的答案误导,从而独立地找到正确答案。
这个过程的关键在于,领导者从未被告知哪份参考答案是对是错。它必须通过自己的分析和最终答案的对错来"反向学习"如何评估和利用这些信息。这正是MLPO的核心——让领导者在"多智能体引导"下,通过自我探索来优化其决策策略。
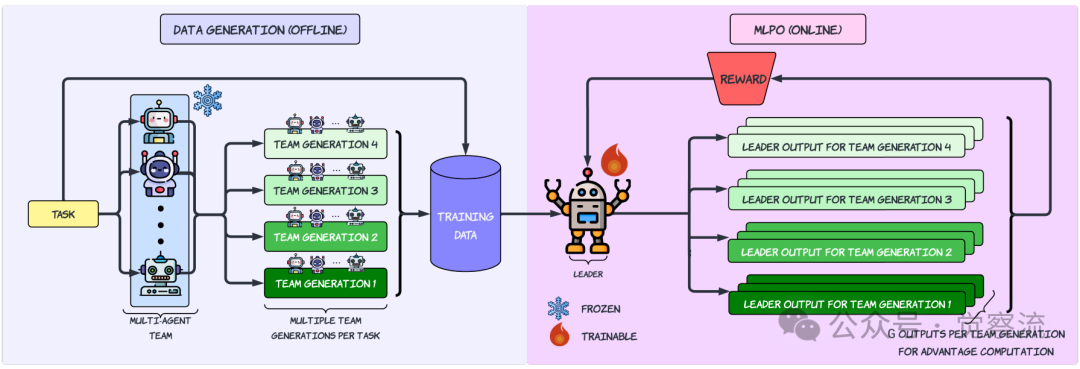
多智能体引导领导者策略优化(MLPO)管道概述
MLPO+:多轮训练的增强版本
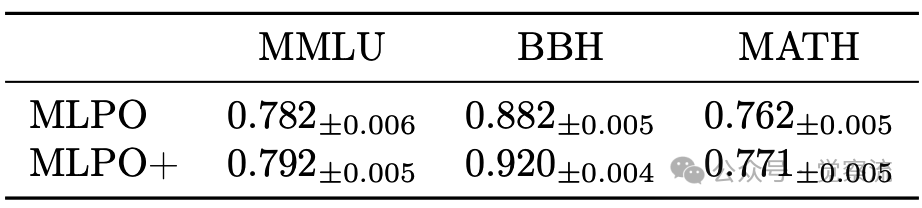
标准MLPO的一个潜在问题是,其训练数据仅使用了第0轮(即智能体未受领导者影响时)的响应,而推理时领导者面对的是已被其反馈"塑造"过的智能体响应。为弥补这一训练-推理之间的gap,作者提出了MLPO+。让领导者在更贴近真实部署环境的数据上进行训练。
- 流程:
- 1. 首先,使用标准MLPO流程训练出一个基础领导者。
- 2. 然后,将此领导者部署到智能体团队中,进行多轮(如2轮)交互。
- 3. 记录下第1轮和第2轮的智能体响应,这些响应包含了领导者的影响。
- 4. 使用这些"真实"的响应数据,对领导者进行二次MLPO训练。
- 优势:如下表所示,MLPO+在所有基准上均带来了性能的进一步提升(如MATH从0.762提升至0.771),且额外数据可离线生成,计算开销极小。
实验与结果:全面的实证验证
实验设置
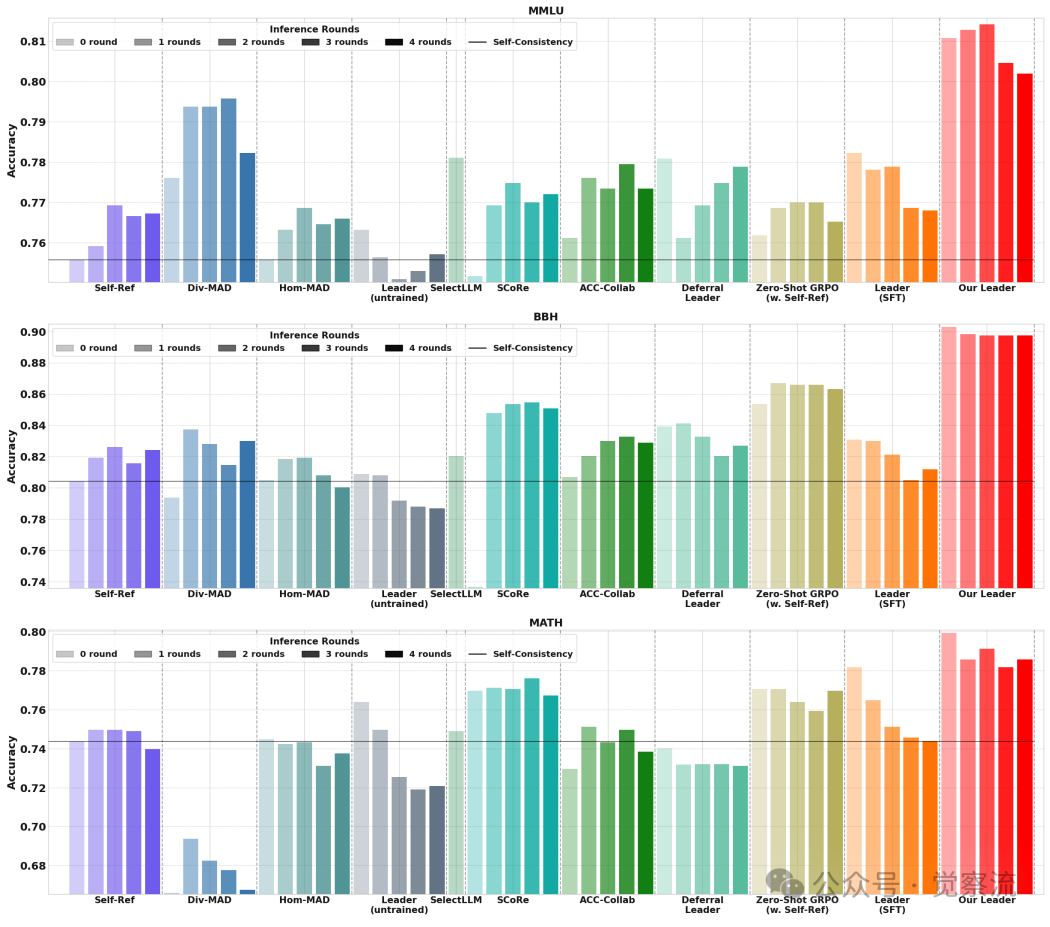
论文在三个高难度基准上评估了MLPO:MMLU(多任务知识理解)、BBH(Big-Bench Hard,复杂推理)和 MATH(数学推理)。领导者采用Qwen2.5 7B Instruct,智能体团队为异构组合(Llama-3.1 8B, Gemma-2 9B, Qwen-2.5 7B)。基线涵盖无训练方法(如Zero-Shot、Self-Reflection、MAD)和有训练方法(如ACC-Collab、SCoRe、Zero-Shot GRPO)。
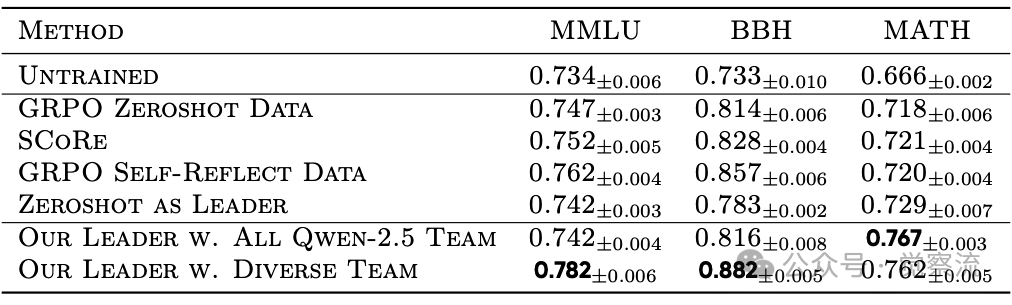
核心结果解读
- 如下表:全面超越。MLPO在所有任务上均显著优于基线。在最具挑战性的BBH上,SFT+MLPO领导者达到了88.2%的准确率,远超SCoRe(82.8%)和MAD(79.9%)。一个关键发现是,即使在无智能体团队的零样本模式下,MLPO训练的领导者(如MLPO Leader的BBH 86.5%)也超过了标准的Zero-Shot GRPO(79.1%),这证明了多智能体引导的训练过程本身就在"增强"领导者。
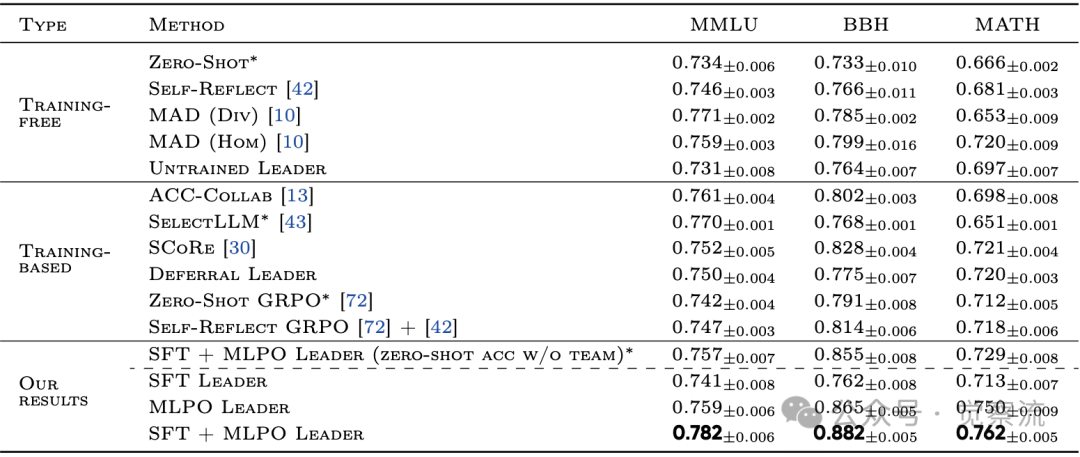
MLPO在MMLU、BBH和MATH基准测试上的准确率表现
- 如下图:测试时扩展性。在40次LLM生成的严格预算下,通过多数投票(majority voting),MLPO取得了最高的准确率。这得益于其双多样性来源:一是智能体团队固有的模型多样性,二是领导者自身生成的随机性。这种双重多样性为投票机制提供了更丰富的输入,有效降低了错误答案被选中的风险。
在40次LLM生成样本限制下的多数投票性能
- 如下图:零样本能力的飞跃。该图显示了MLPO最惊人的发现之一:训练过程本身就在"升级"领导者。
a.一个通过标准Zero-Shot GRPO训练的Qwen模型,在BBH上的准确率是 79.1%。
b.而一个通过SFT+MLPO训练的Qwen模型,即使在不使用任何智能体团队的零样本模式下,其BBH准确率也达到了 85.5%。
c.这意味着,仅仅因为训练时"看到"了其他模型的解题过程,这个领导者在独立工作时,就比一个经过标准强化学习训练的同类模型强了6.4个百分点。这不仅仅是"聚合",而是一种真正的"认知提升"和"知识迁移"。
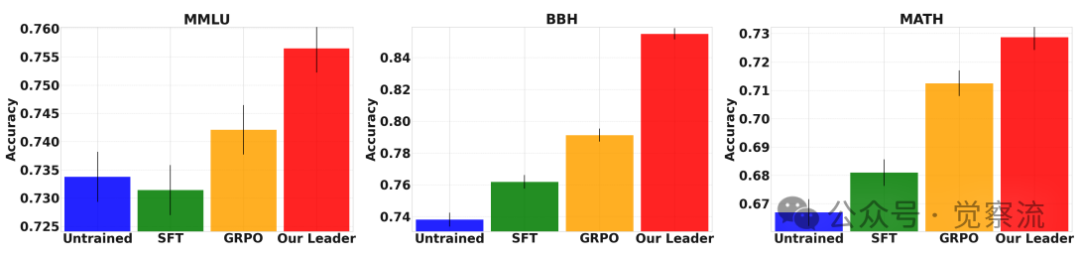 零样本性能:Qwen在不同训练方式下的表现对比
零样本性能:Qwen在不同训练方式下的表现对比
- 下图:对智能体性能的鲁棒性。当智能体团队表现不佳时(例如,3个智能体中只有1个正确),MLPO领导者依然能保持高准确率,尤其是在BBH数据集上。这表明领导者不仅学会了信任正确的智能体,更重要的是,它具备了独立解决问题的能力和评估智能体质量的元能力,而非简单地模仿或依赖。
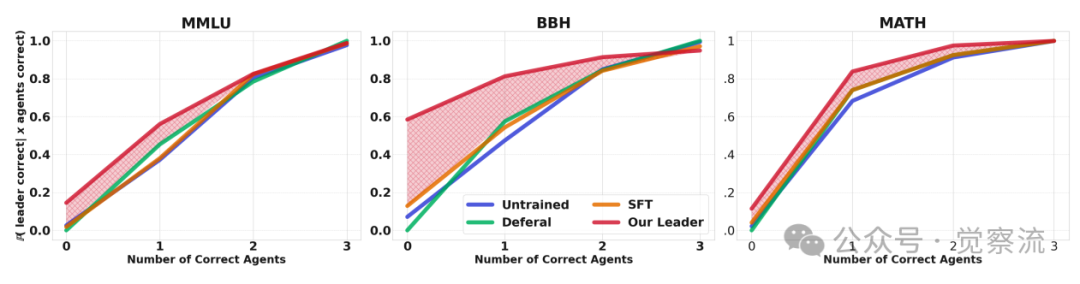
领导者性能与智能体团队正确率的关系
消融研究:最佳实践指南
- 智能体信息的利用(如下图):提供智能体的完整响应(推理过程+最终答案)效果最佳。仅提供推理过程次之,这迫使领导者进行独立验证。而仅提供最终答案效果最差,容易导致领导者盲目信任,丧失批判性。
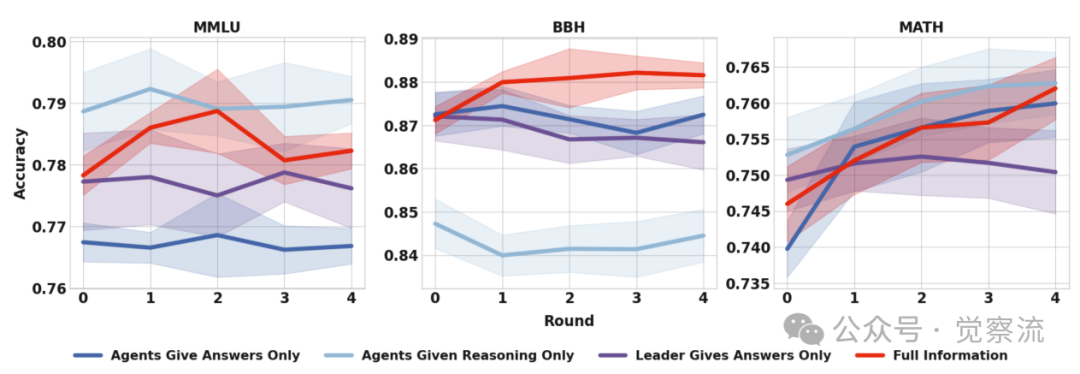
不同信息共享方式下领导者的性能表现
- 团队构成(如下图):异构团队(不同模型)的表现显著优于同构团队(相同模型的副本)。多样性是激发领导者聚合能力的关键,单一模型的重复无法提供足够丰富的视角。
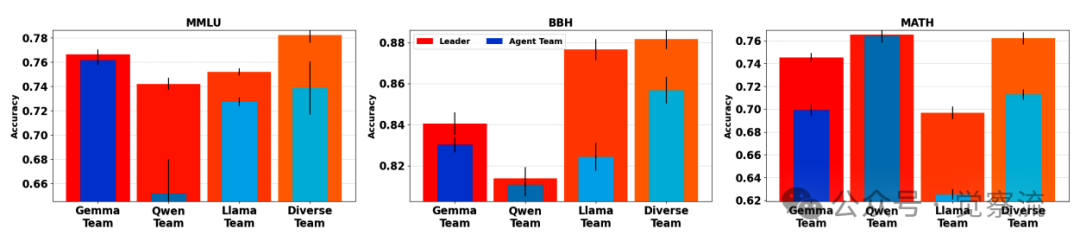
不同团队构成下领导者与团队的准确率对比
- 训练数据策略:每任务提供4组智能体响应是性能与成本的最佳平衡点,超过此数性能趋于饱和。过滤掉"简单任务(>75%智能体正确),能有效避免领导者在训练中过度依赖智能体,从而提升其在困难任务上的领导力。
不同训练方法在5轮推理后的准确率对比

训练过程中,每个任务使用不同数量的解集时,模型在 BBH 上的领先准确率(±2 标准误)

BBH 任务中,leader 模型在“按难度过滤训练”与“不过滤训练”下的准确率比较(已给出 ±2 标准误)
MLPO的理论意义与实践启示
为什么MLPO有效?——超越聚合的"认知提升"
MLPO的成功不止是一个高效的聚合器。其深层机制在于,它通过一个丰富的训练信号,实现了对领导者认知能力的"升级"。
- 批判性评估:领导者在训练中不断接触正确与错误的推理路径,学会了识别逻辑漏洞和计算错误。
- 知识整合:它从多样化的解题策略中提炼出更稳健、更通用的推理模式。
- 元认知能力:SFT阶段注入的"回溯"行为,赋予了领导者在推理中自我监控和纠正的元技能。
- 搜索空间的拓宽:标准GRPO的训练信号是"问题",而MLPO的信号是"问题+多种可能的解答"。这相当于为领导者提供了一个巨大的"解决方案池",极大地拓宽了其探索和学习的边界,使其能发现更优的推理策略。
这一丰富的训练信号带来了双重收益。首先,它提升了领导者的独立推理能力。如下图所示,即使在无智能体的零样本模式下,MLPO训练的领导者也超越了标准GRPO模型,这证明其在训练中通过分析多样化解,拓宽了自身的"解决方案池",实现了"认知升级"。
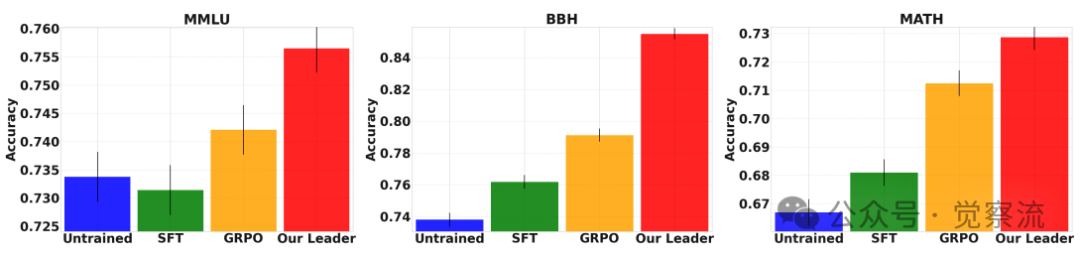 零样本性能:Qwen在不同训练方式下的表现对比
零样本性能:Qwen在不同训练方式下的表现对比
其次,它赋予了领导者强大的评估能力。如下图所示,当智能体团队表现不佳时,领导者仍能保持高准确率,说明其并非简单依赖智能体,而是学会了独立解决问题和判断智能体质量。这种"批判性评估"与"知识整合"的双重能力,正是MLPO超越简单聚合的核心所在。
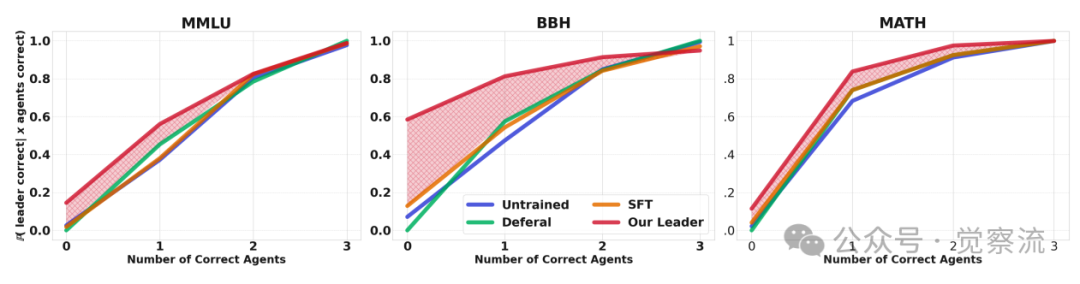
领导者性能与智能体团队正确率的关系
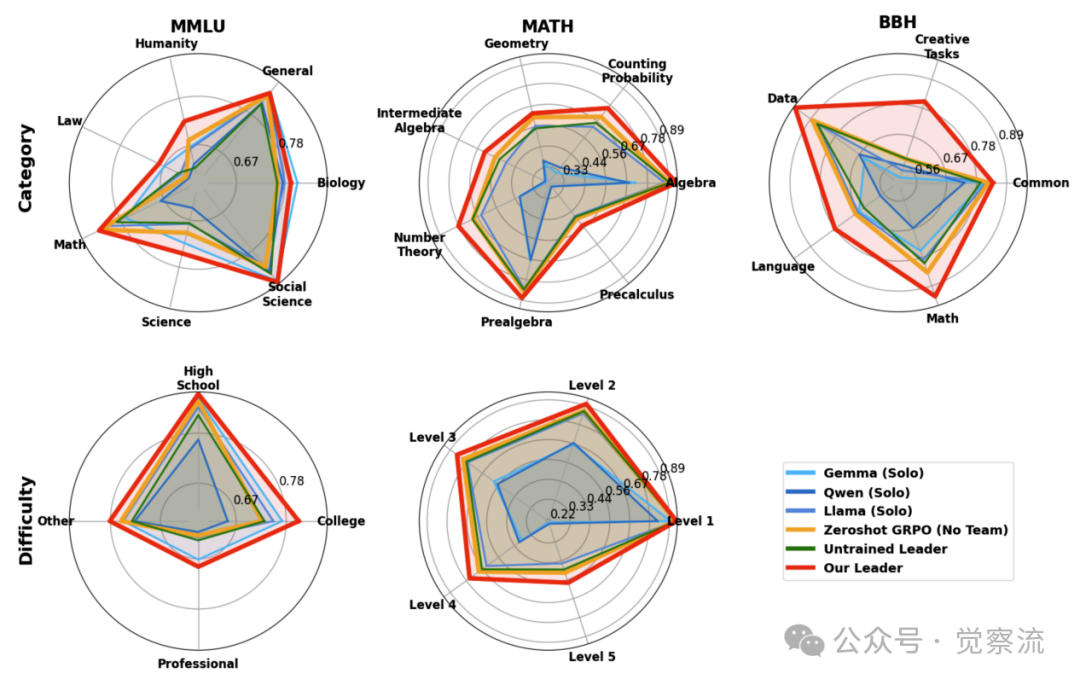
领导者在不同类别和难度级别上的性能表现
与现有工作的对比与定位
方法 | 训练模型数 | 是否需要智能体团队推理 | 核心机制 |
MAD | 0 | 是 | 多方辩论,涌现协作 |
ACC-Collab | 2+ | 是 | 联合训练Actor-Critic |
SCoRe | 1 | 否 | 自我反思与更新 |
MLPO (Ours) | 1 | 是(可选) | 领导者聚合与评估 |
MLPO的独特价值在于其极佳的权衡。它在训练成本(仅1个模型)、推理性能(SOTA)和部署灵活性(单模型/多模型)之间取得了前所未有的平衡。
潜在局限
尽管MLPO优势显著,但仍存在局限:
- 上下文长度瓶颈:领导者需一次性处理K个智能体的长篇响应,对模型的上下文窗口提出了极高要求。
- 顺序依赖与延迟:T轮的迭代过程本质上是串行的,难以并行化,可能影响高吞吐场景的延迟。
- 领导者能力瓶颈:实验表明,领导者自身的推理能力是整个框架的性能上限。当使用Qwen-2.5 7B作为领导者时,MLPO在BBH上达到88.2%;而当使用能力较弱的Gemma-2 9B作为领导者时,尽管训练方法相同,其性能提升幅度显著减小(BBH: 81.3% vs. 88.2%)。这表明,一个有效的领导者必须具备足够的基础推理能力,才能有效评估和整合智能体团队的输出。
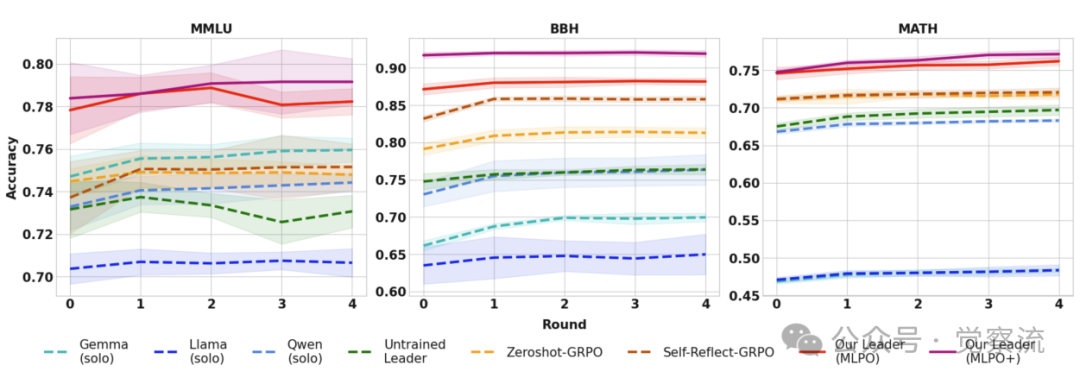
多轮交互过程中的性能变化
未来方向值得探索:
- 选择性查询:设计机制让领导者动态决定是否调用智能体,或选择性地调用最相关的智能体,以降低计算成本。
- 异步与并行化:探索非迭代的、更高效的交互协议。
- 轻量级智能体微调:研究是否可以通过极小的智能体微调,与领导者形成协同进化,进一步释放潜力。
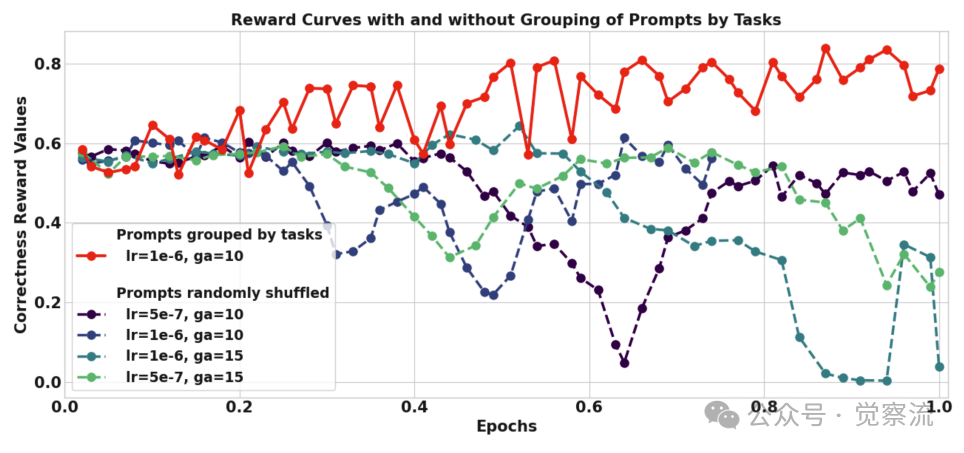
不同解决方案集排序方式的训练奖励曲线对比
总结:从技术到人类组织的思考
MLPO的突破性价值不仅在于技术层面,它还揭示了高效协作系统的普适原则。该框架通过仅训练一个领导者模型,便能系统性提升整个多智能体系统的性能,实现了训练成本与推理性能的最佳平衡。实验数据清晰表明,MLPO在MMLU、BBH和MATH三大基准上全面超越现有方法,甚至在零样本模式下也优于传统训练方案,这验证了"多智能体引导训练"的有效性。
从人类社会角度看,MLPO提供了深刻的组织管理启示:卓越的领导力不在于领导者自身掌握所有知识,而在于其评估、整合与引导团队的能力。这与人类高效组织的运作逻辑是高度一致的——优秀的经理人不需要是所有领域的专家,而是能识别团队成员的优势与不足,引导集体智慧的涌现。在教育领域,这呼应了"同伴学习"(peer learning)理念,学生通过相互讨论和反馈深化理解,而教师作为引导者而非知识灌输者。在科研协作中,这解释了为何跨学科团队往往能突破单一学科的局限。这很有趣。。
更深远地,MLPO框架揭示了"分布式认知"的本质:智能不仅存在于个体中,更分布在整个协作系统中。当领导者学会如何有效利用团队的多样性时,整个系统的认知能力会超越任何单一成员。这对构建未来AI系统乃至人类组织都具有指导意义——与其追求每个成员的全能,不如培养关键的"认知整合者",让系统整体实现"1+1>2"的协同效应。


