2018 年,LSTM 之父 Jürgen Schmidhuber 在论文中( Recurrent world models facilitate policy evolution )推广了世界模型(world model)的概念,这是一种神经网络,它能够根据智能体过去的观察与动作,预测环境的未来状态。
近年来,世界模型逐渐受到大家的关注,当然也包括深度学习三巨头之一的 Yann LeCun,他将世界模型视为通向人类智能的核心路径。
然而,训练出有效的世界模型仍面临诸多挑战。
首先是数据问题:大规模、高质量的视频数据集获取成本高昂,尤其是在包含动作标注的情况下。目前世界模型的成功应用仍然局限于特定领域,如自动驾驶或电子游戏等。
其次,任务本身也非常困难:在无约束、部分可观测的环境中,准确建模物理规律与行为仍是一个尚未解决的问题,即使只考虑短时间尺度也是如此。目前最先进的基于像素的生成模型对计算资源的消耗极其庞大,例如 COSMOS 的训练耗时高达 2200 万 GPU 小时。
更令人担忧的是,这种算力可能被浪费在无关紧要的细节上。比如,在自动驾驶系统中,为了预测未来场景而去建模每一片树叶在风中的精确运动,并无必要。因此,以合适的抽象层级建模环境,对于提升世界模型的效率与效果至关重要。
最后,如何评估预训练的视频世界模型本身也是一大难题。
为了解决上述问题,来自 Meta 的研究者提出了一个强大的通用视频世界模型 DINO-world,用于预测未来帧。在实现方法上,DINO-world 在冻结的视觉编码器(如 DINOv2 )潜在空间中预训练视频世界模型,随后再通过动作数据进行后训练,以实现规划与控制。

论文地址:https://arxiv.org/pdf/2507.19468v1
论文标题: Back to the Features: DINO as a Foundation for Video World Models
这一方法具有多个优势:
将视频预训练与基于动作 - 条件的微调解耦,可以利用大量未标注的视频学习通用知识,从而显著降低对标注数据的需求;
训练潜在世界模型,避开了像素级建模带来的挑战,而像素级建模对大多数下游任务来说并非必要;
冻结的编码器 DINO 能直接提供强大的语义和几何理解能力,加速了学习过程,并避免了同时训练编码器与预测器所带来的技术复杂性。
此外,该研究还引入了一种更高效的世界模型架构,相比当前最先进的模型,在训练与推理阶段都显著减少了资源消耗。
在一个包含约 6000 万条未经清洗的网络视频的大规模数据集上训练预测器,使其能够获得可以良好迁移到不同领域的通用特征。
在 VSPW 分割预测任务中,当预测未来 0.5 秒发生什么时,模型的 mIoU 提高了 6.3%,显著优于第二佳模型。在对动作数据进行后训练并在规划任务上进行评估时,实验结果进一步验证了大规模无监督预训练的优势。
方法介绍
图 1 概述了 DINO-world 主要组件,包括帧编码器(frame encoder)和未来预测器(future predictor)。
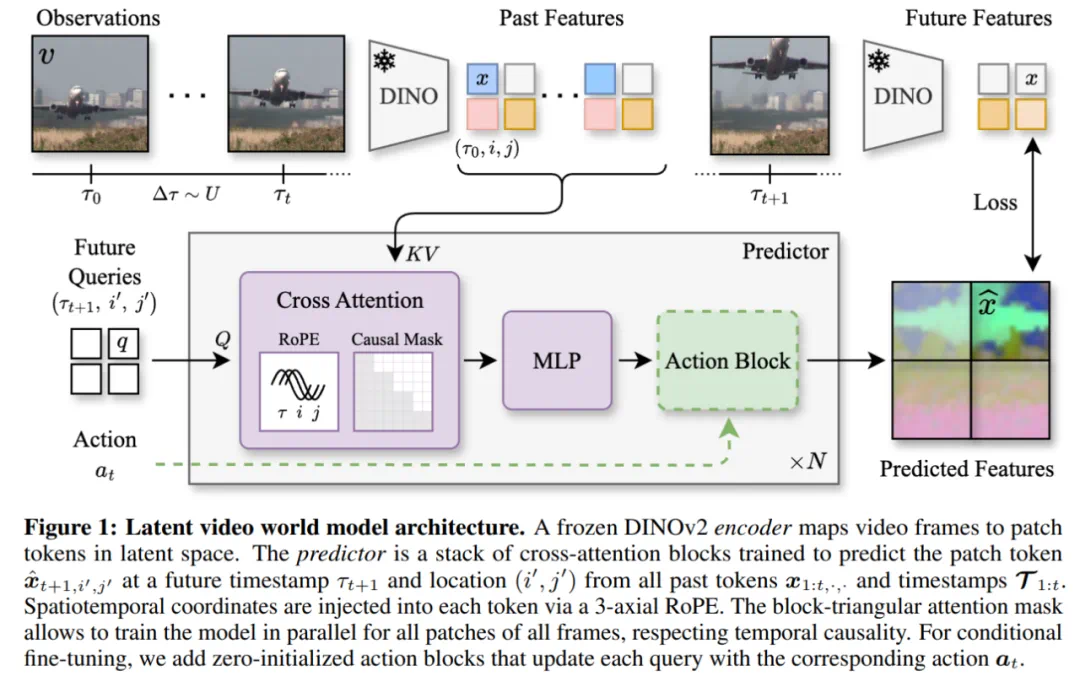
帧编码器
当今几乎所有世界模型都不再直接建模像素,而是基于视频块(video patches)的潜在表示进行建模。以 V-JEPA 为例,它包含一个编码器和一个预测器,这两个组件是联合优化的。
与此不同,本文选择使用专为表征学习而设计、并通过自监督训练的基础模型 DINOv2 对视频帧进行编码。
在这种潜在空间中进行建模显著降低了训练预测器所需的计算成本。实际上,本文成功实现了参数量少于 10 亿的世界模型的有效训练,而当前最先进的生成式模型(如 COSMOS)的参数规模可高达 120 亿。
预测器架构和训练
架构。本文将预测任务建模为一个解码问题,并将预测器设计为由 N 个残差预归一化交叉注意力块堆叠而成的结构。
为了预测在坐标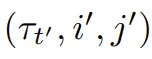 上的未来状态,本文从一个可学习的嵌入中初始化一个查询 token
上的未来状态,本文从一个可学习的嵌入中初始化一个查询 token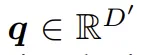 。在每个模块中,查询 token 会对所有历史 patch token 构成的键值对执行交叉注意力操作,之后再接入一个 MLP 模块。
。在每个模块中,查询 token 会对所有历史 patch token 构成的键值对执行交叉注意力操作,之后再接入一个 MLP 模块。

在最后一个模块之后,通过一个线性映射将查询 token q 投影为预测的 patch token。
位置编码。在上述建模形式中,查询向量 q 和上下文特征 x 并不携带关于其在视频中位置的信息。为了使模型能够理解 token 之间的时空关系,本文在多头注意力机制中引入了旋转位置编码(RoPE)。
具体而言,本文将注意力头的维度 Dₕ 分成三部分,分别对每个 token 的时间坐标、水平坐标和垂直坐标进行编码。
对于空间坐标 (i, j),采用定义在 [−1, +1]² 网格上的相对位置表示,从而确保输入分辨率的变化不会影响 patch 之间的相对距离。
而对于时间坐标 τ,采用以秒为单位的绝对时间戳,使得模型能够区分高帧率与低帧率的序列,并具备对更长视频进行外推的能力。
训练目标。为了便于并行化,本文采用「下一帧预测」作为训练目标,即令 t′ = t + 1,并使用 teacher forcing 策略。在给定 T 帧的序列下,关于第 t+1 帧的查询只能访问到第 t 帧及之前的 patch token。对于参数为 θ 的预测器,其训练目标如下:
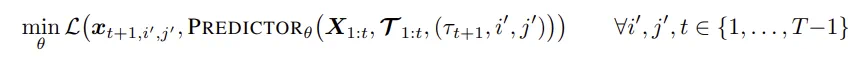
相比之下,掩码重建类的损失(如 V-JEPA 或 DINO-Foresight)仅对掩码位置的 token 计算损失,这些 token 只占处理总量的一小部分。
可变帧率(Variable FPS)。对于每段视频,本文从预设范围 [Δτ_min, Δτ_max] 中均匀采样 T−1 个时间间隔,并通过累加这些间隔以及一个随机起始点来生成 T 个时间戳。
这样一来,解码出最接近的帧及其实际时间戳用于训练。该方法确保了模型在训练时能够接触到均匀分布的时间间隔,从而具备更强的时间泛化能力。
动作条件微调
本文提出的视频世界模型可以通过自监督的方式,在大规模无标注视频数据集上进行训练。然而,许多下游应用往往涉及某种条件信号,例如智能体的动作或语言指令,而这类数据通常较为有限。
本文关注的是以观测 - 动作对 (v_t, a_t) 表示的智能体轨迹。
在预训练的视频世界模型基础上,本文提出了一种简单的适配方法,用于将预测第 t+1 帧的过程与当前动作 a_t 相结合。
具体而言,他们加入了一个动作模块,利用对应的动作更新查询向量,其更新方式为: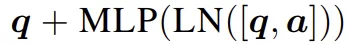 。这些动作模块可以初始化为恒等映射(identity),并在一个小规模的动作条件轨迹数据集上进行训练。可选地,视频世界模型本身可以保持冻结,仅训练动作模块,以缓解过拟合风险,并实现基础模型在不同任务中的泛化。
。这些动作模块可以初始化为恒等映射(identity),并在一个小规模的动作条件轨迹数据集上进行训练。可选地,视频世界模型本身可以保持冻结,仅训练动作模块,以缓解过拟合风险,并实现基础模型在不同任务中的泛化。
实验结果
密集预测任务
本文在 Cityscapes、VSPW 和 KITTI 数据集上进行了评估。
评估类型包括:短期预测,即预测约 200 毫秒后的帧;以及中期预测,目标时间点为 0.5 秒后。
表 1 结果表明,DINO-world 世界模型优于像 V-JEPA 这样的联合预测架构,也优于像 COSMOS 这样的生成模型。DINO-Foresight 在 Cityscapes 和 KITTI 上略微占优,这归因于其在驾驶视频上的领域特定训练。
然而,DINO-world 在多个评测基准上表现稳健,验证了这一范式的有效性:在冻结的自监督学习编码器基础上训练潜在空间的世界模型。事实上,相较于 V-JEPA,本文预测的特征质量更高;相较于 COSMOS,本文对视频动态的建模也更为准确。
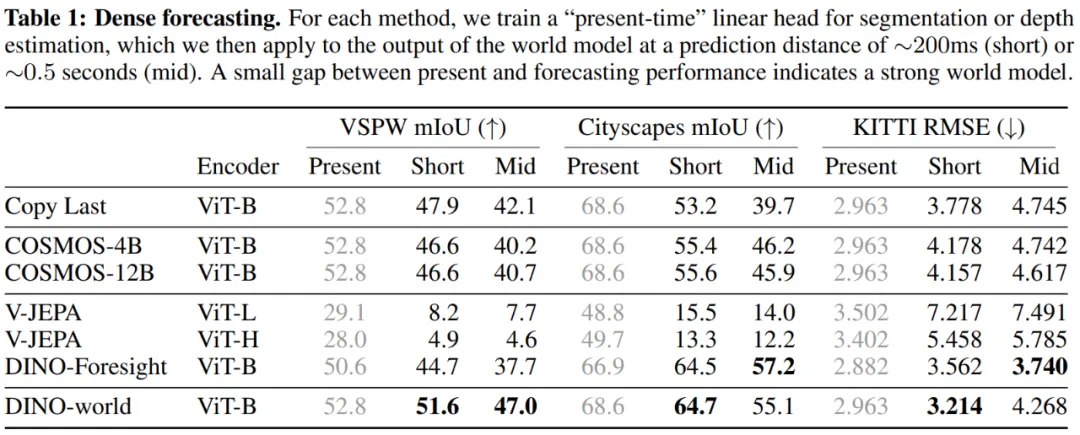
表 1:密集预测。当前表现与预测表现之间的差距越小,说明世界模型越强。
直觉物理(Intuitive physics)
本文采用了三个直觉物理测试基准:IntPhys 、GRASP 和 InfLevel 。并基于模型的预测定义了一个惊讶分数(surprise score),用于衡量模型输出与预期物理行为的偏差。
从表 2 的结果可以看出,所有在大规模数据集上训练的世界模型均表现出一定程度的物理理解能力。DINO-world 的表现与使用更大编码器的 V-JEPA ViT-H 相当。DINO-Foresight 在 IntPhys 和 GRASP 上的相对劣势,可归因于其训练域未包含合成视频。COSMOS 在相对简单的 IntPhys 任务中表现几乎完美,但在另外两个任务上明显不足。
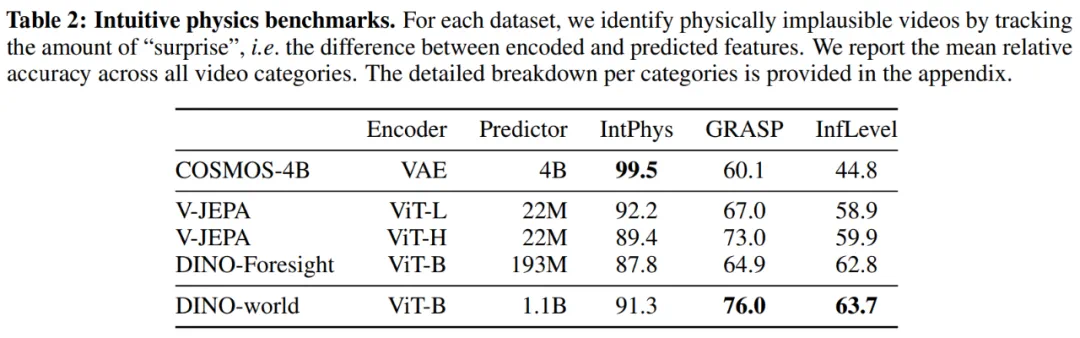
表 2:直觉物理测试基准,报告了所有视频类别的平均相对准确率。
实验表明,潜在空间世界模型在性能上具有显著优势,同时也凸显了大规模预训练的重要性。
动作条件微调与规划评估
本文以预训练的基础模型为起点,在每个环境的离线轨迹上对动作条件模型训练 25 个 epoch,使用帧数 T = 4、分辨率为 224 像素的视频片段。
作为对比,本文还训练了两个模型:一个是仅训练动作模块、冻结其他所有参数的模型,另一个则是从头开始训练的模型。
表 4 报告了每个环境下、512 个测试回合中的成功率。主要发现是,与从零训练相比,大规模预训练显著提升了模型性能。作者预计,在更复杂、与预训练数据分布更接近的环境中,这一性能提升将更加明显。
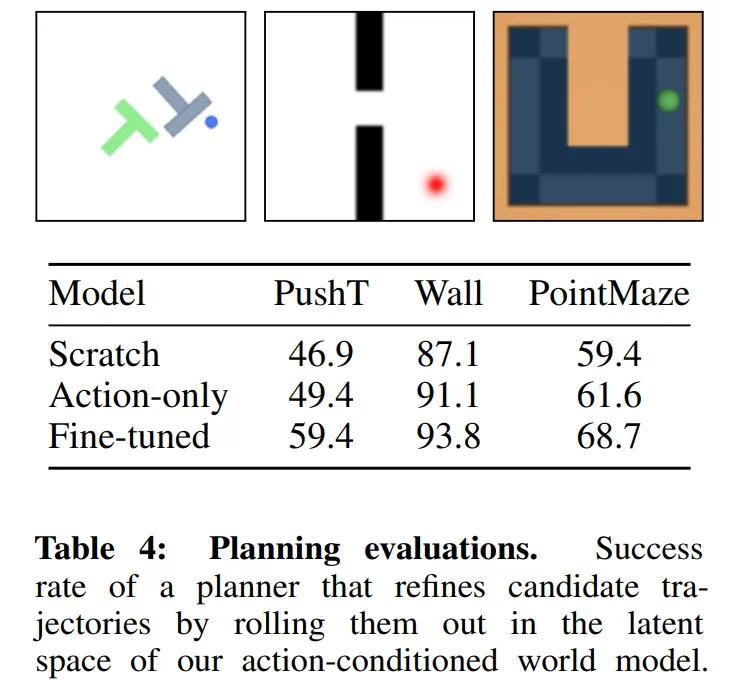
表 4:规划评估。规划器在动作条件世界模型的潜在空间中展开候选轨迹并进行优化,其成功率如表所示。
更多实验细节、消融实验,请参阅原论文。


