闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
Transformer的时代,正在被改写。
月之暗面最新发布的开源Kimi Linear架构,用一种全新的注意力机制,在相同训练条件下首次超越了全注意力模型。

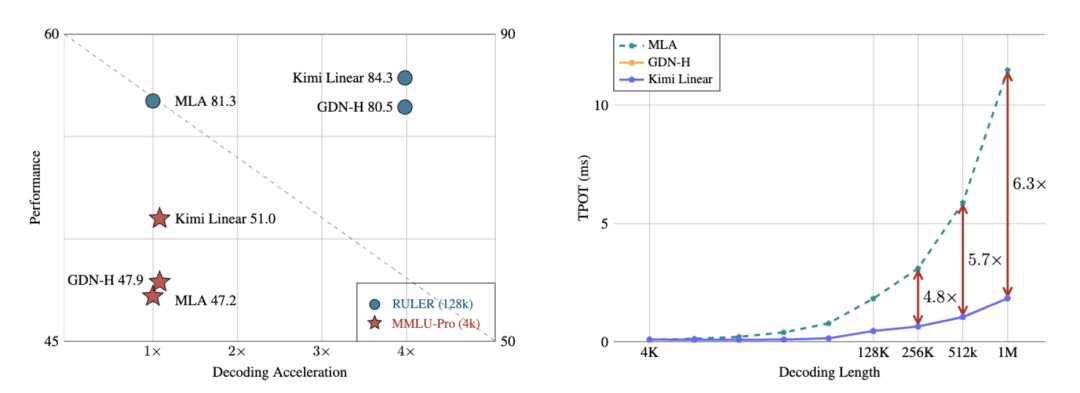
在长上下文任务中,它不仅减少了75%的KV缓存需求,还实现了高达6倍的推理加速。
有网友表示期待:这个架构下的Kimi K2.5何时来??

不过,咱还是先来看一下Kimi Linear是如何挑战传统Transformer的。
Transformer确实聪明,但聪明得有点太烧钱。
它的注意力机制是全连接的,每个token都要和其他所有token打交道。
计算量也随着输入长度呈平方增长(O(N²)),而且每生成一个新词,还要查一遍之前的所有缓存。
这就导致推理阶段的KV Cache占显存极大,尤其是在128K以上的上下文中,显卡直接崩溃警告。
模型越强,显卡越崩,钱包越痛。

所以,过去几年无数团队都在研究线性注意力,希望把计算从 O(N²) 降到 O(N),让模型能又快又省。
但问题是,以前的线性注意力都记不住东西,快是快了,but智商打折。
现在,Kimi Linear以既要又要还要的姿态登场了。
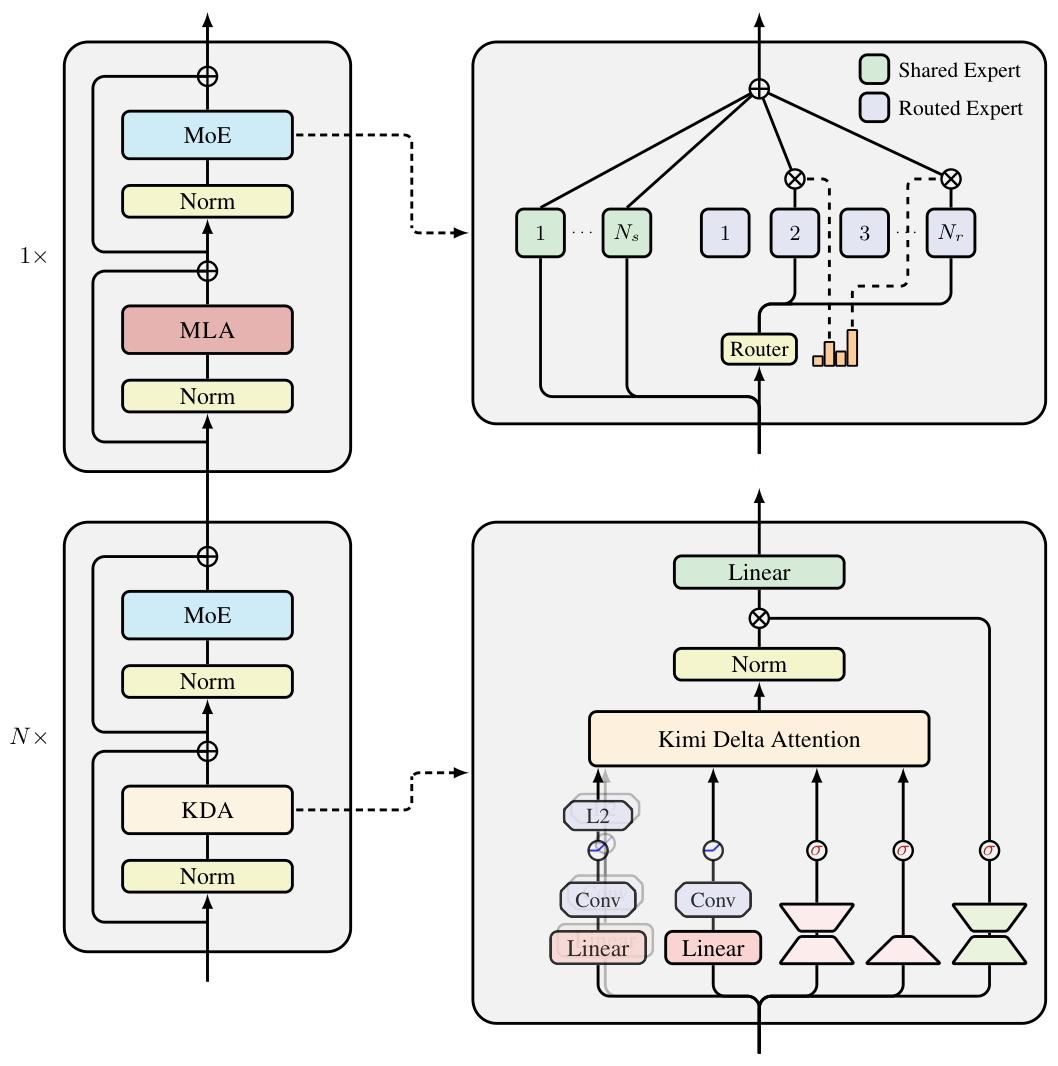
Kimi Linear的核心创新是Kimi Delta Attention(KDA)。
它在原有线性注意力的基础上,引入了细粒度遗忘门控,不再像传统线性注意力那样一刀切地遗忘,而是让模型可以在每个通道维度上独立地控制记忆保留,把重要信息留下,把冗余信息扔掉。
更关键的是,KDA的状态更新机制是基于一种改进的Delta Rule(增量学习规则)。
它在数学上保证了稳定性,即使是在百万级token序列中,梯度也不会爆炸或消失。
这也让Kimi Linear能在超长上下文中跑得稳。
整个模型采用3:1的混合层设计,每3层线性注意力(KDA)后加1层全注意力。这样既保留全局语义的建模能力,又能在多数层用线性计算节省资源。
团队还干脆把传统的RoPE(旋转位置编码)砍掉,让KDA自己通过时间衰减核函数学习序列位置信息。
结果,没有RoPE,模型反而更稳、更泛化。

在KDA的状态更新过程中,Kimi Linear用了一种叫Diagonal-Plus-Low-Rank(DPLR)的结构。
核心思路是把注意力矩阵拆成「对角块+低秩补丁」,这样GPU在并行计算时能一次性处理更多内容,吞吐率直接翻倍。
此外,团队还引入了分块并行计算和kernel fusion优化(内核融合),极大地减少了显存I/O开销。
在工程部署上,它还能无缝对接vLLM推理框架,不需要改模型结构,也不需要改缓存管理,直接替换即可。
这意味着,任何基于Transformer的系统在理论上都能一键升级为Kimi Linear。
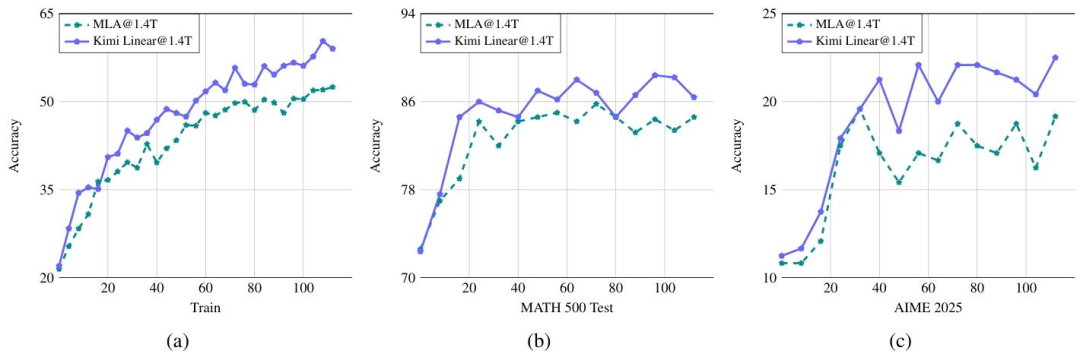
实验结果显示,在相同训练规模下,比如1.4T tokens,Kimi Linear在MMLU、BBH、RULER、GPQA-Diamond等多个基准测试上全面超越Transformer。
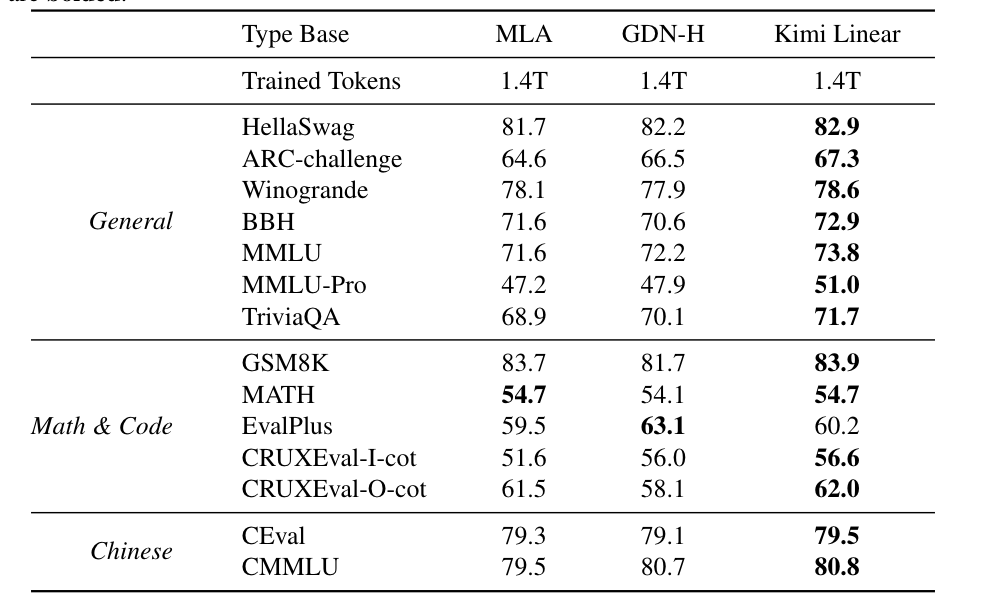
长上下文推理中,解码速度提升最高达6倍,KV缓存减少75%。
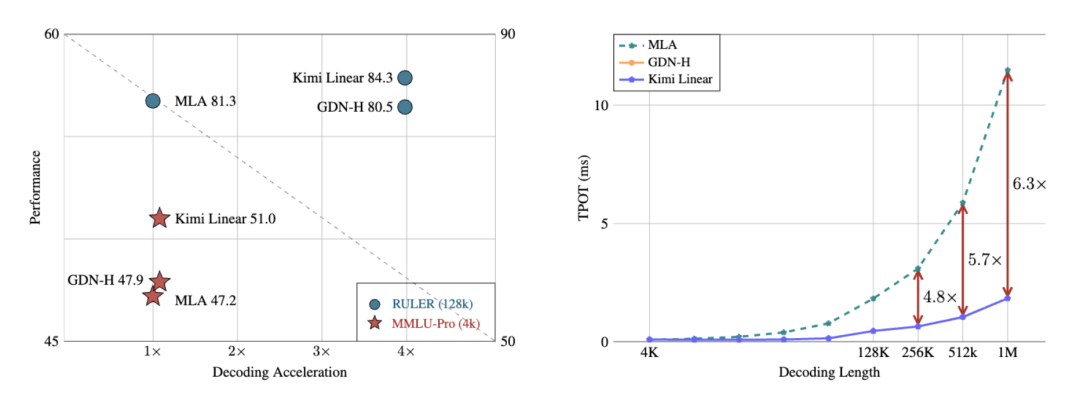
不仅没丢精度,还在数学推理、代码生成等任务上更稳定、更高分。
不得不说,Transformer的地位正在被重新审视。
Mamba的作者曾用长文论述Transformer并非最终解法,状态空间模型(SSM)在长序列建模和高效计算上展现出强大的替代潜力,这也让人们重新思考注意力是否真的是唯一答案。
之前谷歌推出的MoR架构,探索用递归结构取代部分注意力,通过动态计算深度来减少冗余推理,进一步提升效率。
苹果公司也在多项研究中倾向采用Mamba,而非传统Transformer,理由很现实——SSM架构更节能、延迟更低、适合在终端设备上部署。
现在,Kimi Linear则从另一条路线突围,在线性注意力方向上取得突破。
或许这也预示着,AI架构正在告别对传统Transformer的路径依赖,迈向多元创新时代。
但值得一提的是,刚刚坐上开源模型王座的MiniMax M2,却重新用回了全注意力机制。
技术报告:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
— 完 —


