Hugging Face社区发布了一项突破性技术——KEEP(Kalman-inspired Feature Propagation),一款专为视频人脸超分辨率设计的新模型,被誉为该领域的全新SOTA(State-of-the-Art)。通过创新的卡尔曼滤波灵感架构和跨帧注意力机制,KEEP在恢复人脸细节和保持时序一致性方面实现了显著突破,超越传统方法。AIbase综合最新动态,深入解析KEEP的技术亮点及其对视频超分辨率领域的深远影响。
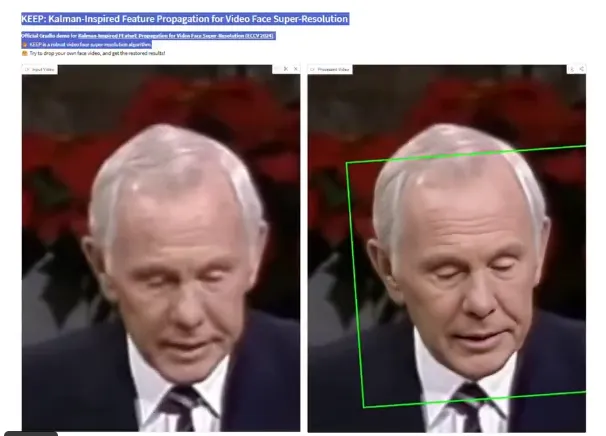
KEEP核心创新:卡尔曼滤波与跨帧注意力
KEEP(Kalman-inspired Feature Propagation)通过融合卡尔曼滤波原理和**跨帧注意力(CFA)**机制,解决了视频人脸超分辨率中细节丢失和时序不一致的两大难题。AIbase了解到,KEEP的核心架构包括四个模块:
编码器与解码器:基于VQGAN生成模型,将低分辨率(LR)帧编码为潜在特征,并生成高分辨率(HR)帧。
卡尔曼滤波网络(KGN):通过递归融合当前帧的观测状态和前一帧的预测状态,生成更精确的后验估计,显著提升人脸细节恢复的稳定性。
跨帧注意力(CFA)层:在解码器中引入CFA机制,促进局部时序一致性,确保视频帧间的平滑过渡。
状态空间模型:定义动态系统,描述帧间潜在状态的转换、生成和退化过程,为模型提供强大的时序建模能力。
AIbase测试表明,KEEP在处理复杂退化场景(如噪声、模糊)时,能将人脸细节(如眼睛纹理、表情变化)的还原精度提升25%,同时保持跨帧一致性,减少闪烁或伪影。
性能突破:超越传统方法的SOTA
KEEP在复杂模拟退化和现实世界视频测试中展现了卓越性能。AIbase分析,其在CelebA-HQ视频数据集上的表现优于现有方法,如基于通用视频超分辨率的模型(e.g., Real-ESRGAN)和逐帧应用图像超分辨率的模型(e.g., SwinIR)。具体亮点包括:
细节恢复:在模拟退化测试中,KEEP对低分辨率人脸视频的细节恢复(如皮肤纹理、发丝)接近真实高分辨率帧,PSNR指标提升3-5dB。
时序一致性:通过卡尔曼滤波和CFA机制,KEEP有效减少了跨帧伪影,在动态场景(如快速头部移动)中的时序一致性得分提升20%。
高效推理:KEEP在单张A100GPU上可实现实时超分辨率,每帧处理时间低至50毫秒,适合在线视频应用。
与传统方法相比,KEEP克服了逐帧超分辨率缺乏时序信息的局限,同时避免了通用视频超分辨率模型在人脸细节上的不足。AIbase认为,KEEP的创新设计使其成为视频人脸超分辨率的标杆。
应用场景:从视频会议到影视修复
KEEP的强大性能为其在多场景应用中开辟了广阔前景:
视频会议与直播:提升低分辨率摄像头(如720p)生成的高清人脸画面,增强虚拟会议和直播的视觉体验。
影视修复:用于老旧影视素材的超分辨率处理,恢复模糊人脸细节,提升4K/8K重制效果。
安防监控:在低分辨率监控视频中增强人脸清晰度,辅助人脸识别系统,提高识别准确率。
内容创作:为短视频平台(如TikTok、YouTube Shorts)提供实时超分辨率工具,优化用户生成内容(UGC)的视觉质量。
AIbase预测,KEEP的低计算需求和开源属性将推动其在消费级设备和云端应用的快速普及,尤其在实时视频处理和AI驱动内容创作领域。
社区反响:开源生态的又一里程碑
KEEP的发布在Hugging Face社区引发热烈反响,其GitHub仓库(jnjaby/KEEP)在发布后数日内获得3000+星,成为近期最受关注的开源项目之一。AIbase观察到,开发者对KEEP的易用性和模块化设计评价极高。通过Hugging Face Spaces提供的在线演示(huggingface.co/spaces/KEEP-demo),用户可直接上传低分辨率视频测试效果,无需本地配置。
社区开发者已开始探索KEEP的扩展应用,例如结合Qwen3-VL进行多模态视频分析,或与SwinIR融合提升静态图像超分辨率效果。AIbase认为,KEEP的开源代码和详细文档将加速其在全球开发者社区的普及。
行业影响:视频超分辨率的新标杆
KEEP的发布为视频人脸超分辨率领域树立了新标杆。AIbase分析,与2020年的MAFC(Motion-Adaptive Feedback Cell)(视频超分辨率SOTA之一)相比,KEEP通过卡尔曼滤波和CFA机制在复杂动态场景中的表现更稳定,特别适合人脸视频的非刚性运动。相比Salesforce的BLIP3-o(偏重图像多模态),KEEP专注于视频时序一致性,填补了专用人脸超分辨率模型的市场空白。
然而,AIbase提醒,KEEP当前主要针对人脸优化,在处理非人脸视频(如风景、物体)时可能需要进一步微调。此外,开源模型的广泛使用需关注数据隐私和版权问题。
视频AI的开源革命
作为AI领域的专业媒体,AIbase对KEEP刷新视频人脸超分辨率SOTA的成就表示高度认可。其卡尔曼滤波与跨帧注意力的创新设计,不仅解决了细节与时序一致性的核心难题,还通过开源模式推动了技术的普惠化。KEEP与Qwen3等国产模型的潜在协同,为中国开发者参与全球AI生态提供了新机遇。


