刚刚,又一个人工智能国际顶会为大模型「上了枷锁」。
ICLR 2025 已于今年 4 月落下了帷幕,最终接收了 11565 份投稿,录用率为 32.08%。
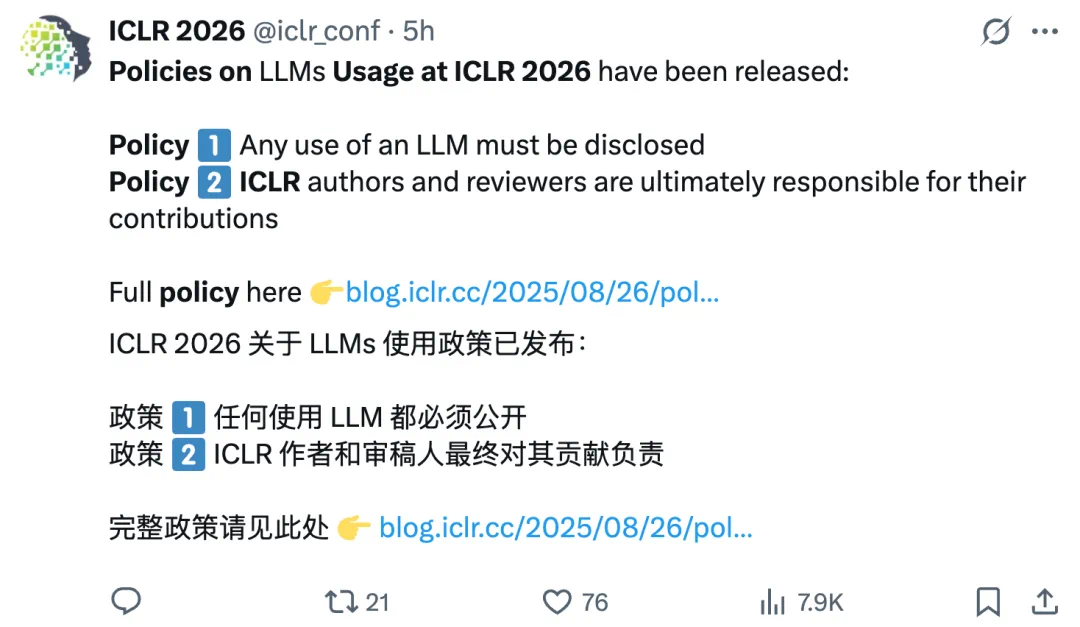
就在今天,ICLR 2026 出台了大语言模型(LLM)使用政策,以明确规范论文作者与审稿人在研究过程和审稿过程中使用 LLM 的做法。
这届会议将于明年 4 月 23 日至 27 日在巴西里约热内卢举办。
此次发布的所有政策均以 ICLR《道德准则》为基础,旨在确保学术诚信,同时规避 LLM 可能带来的风险,如事实幻觉、剽窃或数据失实。

以下是两项核心政策:
政策1:任何对 LLM 的使用都必须如实披露,这遵循了《道德准则》中「所有对研究的贡献都必须得到承认」以及「贡献者应期望……为其工作获得认可」的政策。
政策2:ICLR 的论文作者和审稿人最终要为自己的贡献负责,这遵循了《道德准-则》中「研究人员不得故意做出虚假或误导性的声明,不得捏造或伪造数据,也不得歪曲结果」的政策。
违反上述政策的投稿将面临具体处罚,其中最严重的后果之一是直接拒稿 (desk rejection)。
具体应用场景说明
为阐明政策的实际应用,ICLR 官方列举了几个关键场景:
辅助论文写作
作者在使用 LLM 辅助润色语法、调整措辞甚至草拟章节后,必须明确披露其使用情况。作者对论文的全部内容,包括 LLM 生成的任何错误或不当内容,承担全部责任。
辅助研究
当 LLM 被用于提出研究思路、生成实验代码或分析结果时,同样需要披露。人类作者必须对 LLM 贡献的有效性和准确性进行验证。ICLR 强调,即使研究工作由 LLM 大量完成,也必须有一名人类作者来承担最终责任。
辅助撰写审稿或元审稿意见
审稿人或领域主席 (Area Chair) 在撰写审稿或元审稿意见时使用 LLM 必须披露。审稿人不仅要对审稿意见的质量和准确性负责,还必须确保使用 LLM 的过程不会泄露投稿论文的机密信息。违反保密规定可能会导致该审稿人自己提交的所有论文被直接拒稿。
禁止「提示词注入」
严禁作者在论文中插入旨在操纵审稿流程的隐藏「提示词注入」(例如,用白色字体诱导 LLM 给出好评)。详见机器之心报道:真有论文这么干?多所全球顶尖大学论文,竟暗藏 AI 好评指令
这种行为被视为串通 (collusion),是一种严重的学术不端行为。论文作者和审稿人都将为此负责。
ICLR 不是孤例,其他顶会也有相关规定
随着大语言模型能力的持续增强,应用范围不断拓展,其触手也伸向了论文写作。从论文撰写到审稿反馈,LLM 的使用能够显著提升效率。
与此同时,过度依赖或不当使用 LLM 也引发了担忧,并导致一些学术不端现象的出现,包括虚假引用、抄袭拼接或责任模糊,这些都对科研诚信以及学术评价的公正性构成了挑战。
而作为人工智能领域最具影响力的科研平台,各大顶会投稿数量正以每年数以千计的规模递增,不可避免地面临着 LLM 所带来的种种压力。
为了确保研究成果得到公平的评判并对审稿过程进行有效监督,近年来,包括 NeurIPS、ICML 以及如今的 ICLR 等国际顶会都相继制定 LLM 使用细则,以约束论文作者和审稿人的行为。
其中,NeurIPS 2025 规定了:
「允许 LLM 作为工具,但论文作者若将其作为核心方法则必须详细描述;审稿人则严禁将任何机密信息(如稿件内容)输入 LLM,仅可在不泄密的前提下用于辅助理解或检查语法。」

网站地址:https://neurips.cc/Conferences/2025/LLM?utm_source=chatgpt.com
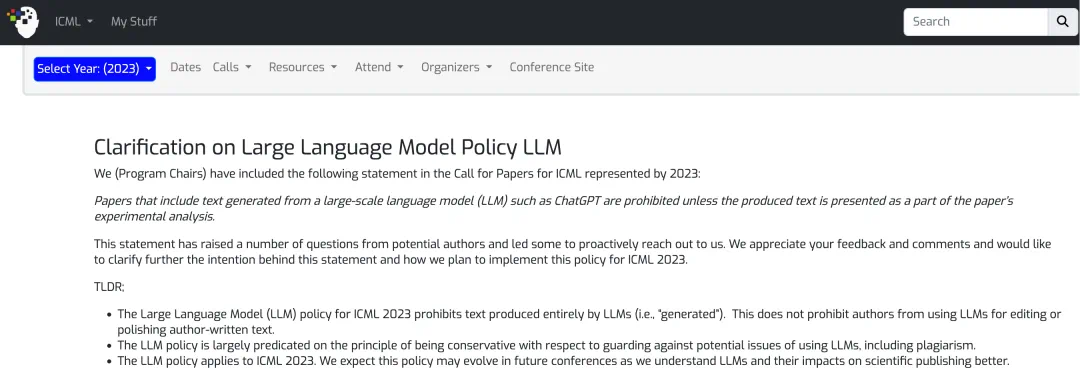
更早时候的 ICML 2023 规定:
「禁止提交完全由大语言模型(如 ChatGPT)生成的论文文本,但允许使用其编辑和润色作者自己撰写的文本,以防范剽窃等潜在风险。」
网站地址:https://icml.cc/Conferences/2023/llm-policy?utm_source=chatgpt.com
其他如 IEEE 相关会议也规定了:
「需要负责任地使用生成式 AI 作为辅助研究的工具,但强调人类作者和审稿人必须对工作的科学诚信与保密性负全部责任。对于作者,必须在致谢部分明确声明所用 AI 工具及具体用途,并对所有内容的准确性和原创性负责,同时严禁利用 AI 伪造数据。对于审稿人,则出于严格的保密原则,绝对禁止将所审稿件的任何信息输入到任何 AI 系统中。」

网站地址:https://www.ieee-ras.org/publications/guidelines-for-generative-ai-usage?utm_source=chatgpt.com
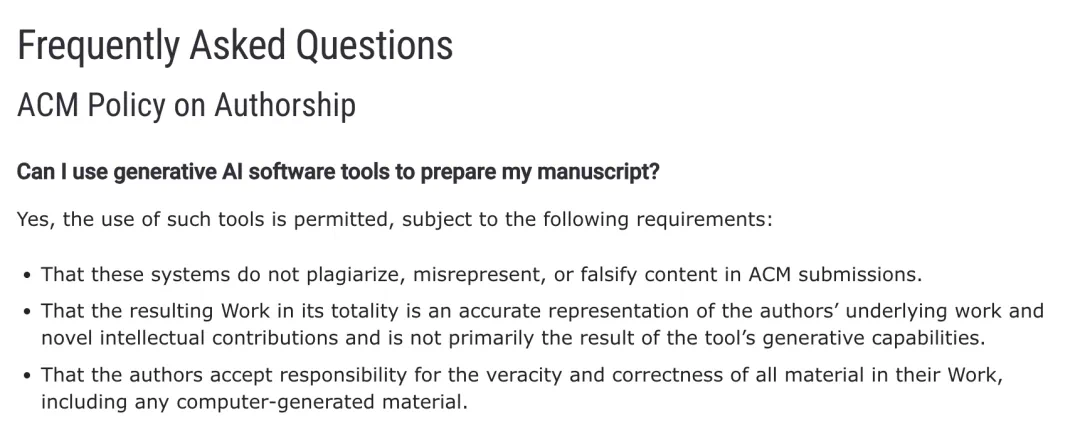
ACM 相关会议同样有类似规定:
「如果使用 LLM(如 ChatGPT)生成文本、表格、代码等,必须在致谢或正文中明确披露对应工具和使用方式;仅用于语言润色的小规模修改可以不用披露。」
网站地址:https://www.acm.org/publications/policies/frequently-asked-questions?utm_source=chatgpt.com
可以预见,越来越清晰的 LLM 使用细则,可以进一步促进 AI 工具的透明、合理使用,并形成更系统的学术规范。