
7 月初知识星球的会员微信群中,有几个星友问到一个条款存在内容和顺序差异的协议对比问题,以及如何进一步封装一个可视化页面进行实现的需求。我在过去的咨询项目中做过一个类似 demo,但是不是很完善。过去两天花了点时间做了一些工程调参的优化,初步效果比较稳定了,这篇来做个思路分享。
这个需求可能会有盆友第一反应是,WORD中不是有合同对比的功能吗,为什么还要重复造轮子?这是因为传统的文本比对工具(如 WORD自带的比较)在处理顺序不一致的文档时,会产生大量混乱的“伪差异”,几乎无法使用。

解决这个顺序差异的关键,就是要结合嵌入模型的“语义比对” 功能(本篇以 RAGFlow 的知识库为依托实现)。也就是先是通过计算向量相似度来建立不同文档顺序差异段落间的正确对应关系,再进行传统的精细化差异分析(Diff 算法),就能准确地高亮出文字的增、删、改。
这篇试图说清楚:
测试文档的使用场景和实际修改设计、WORD中的比较 vs 该系统的实现效果、系统的核心架构、核心环节拆解、工程实践总结等内容。
以下,enjoy:
1、测试场景说明
测试文档包含两份协议,协议 A 是原合同,协议 B 则是修改后的版本。设定的使用场景是当下比较应景的甲方委托乙方进行大模型应用技术开发。

在协议修订设计上, 为了尽量模拟真实场景中的谈判要点,设计了以下几处增删改内容:
条款主题 | 协议 A(甲方初稿) | 协议 B(乙方修订稿) | 差异分析 |
总费用 | 50 万元 | 55 万元 | 乙方涨价 5 万元 |
支付方式 | 50%首付 + 50%验收付 | 30%启动+30%PoC+40%验收 | 乙方分阶段收款降低风险 |
知识产权归属 | 全部归甲方 | 应用使用权归甲方,底层技术归乙方 | 乙方保留核心技术所有权 |
源代码托管 | 强制要求托管 | 删除该条款 | 乙方拒绝技术公开 |
甲方责任 | 未明确 | 新增数据提供、API 支持等义务 | 乙方要求甲方承诺资源支持 |
功能要求 | 未提及 PoC 阶段 | 明确 PoC 验收节点 | 乙方增加阶段性验证 |
2、实现效果对比
通过实际的效果截图,来先直观对比下 WORD 自带对比工具和该系统的实际分析结果,最后再来总结下核心对比差异:
2.1WORD 实现效果


2.2该系统实现效果
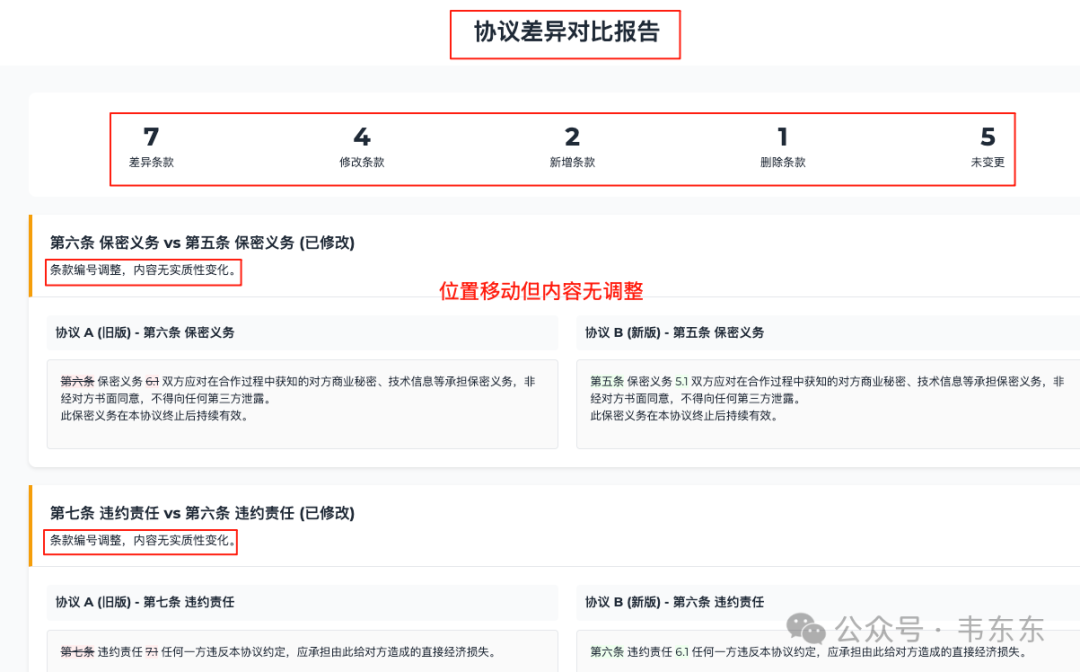

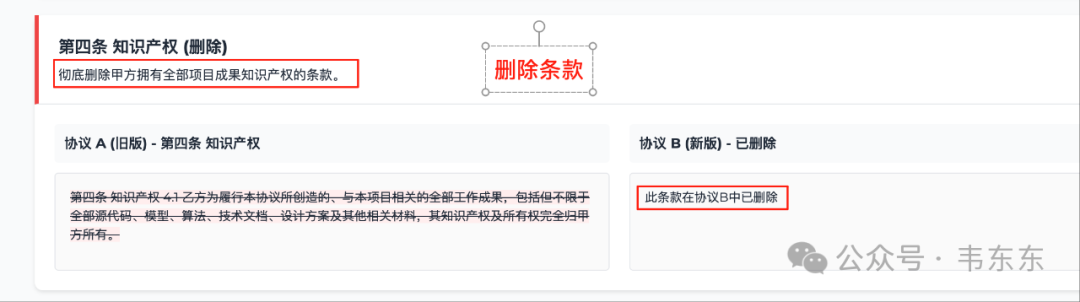
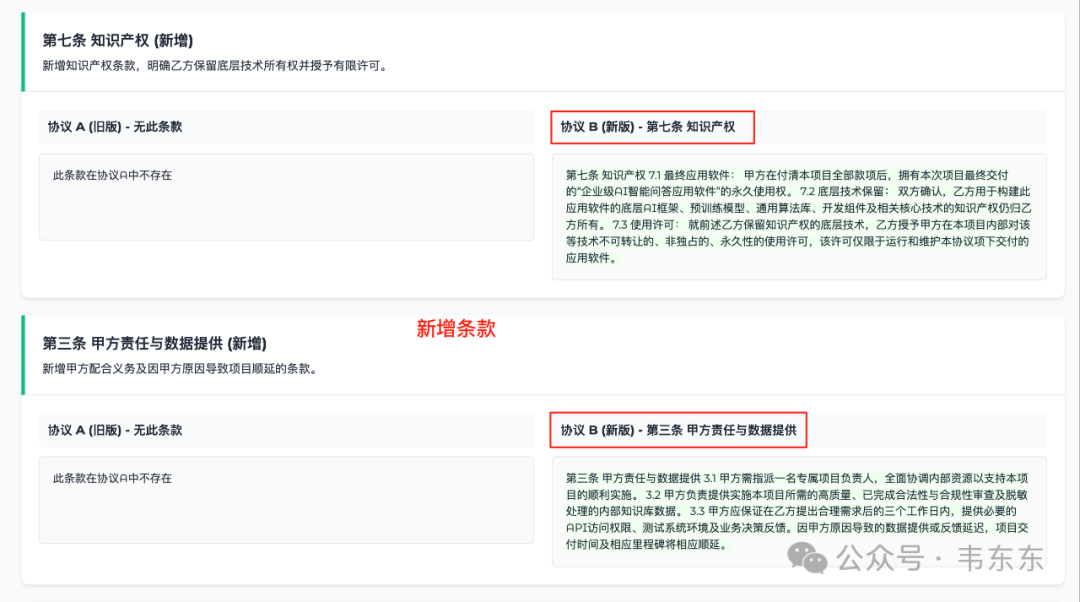
检测场景 | 该系统表现 | 与传统工具对比 |
1. 条款彻底删除(如源代码托管) | ✅ 主动标记删除(高亮协议 A 第五条内容,标注“删除源代码托管要求”) | ❌ Word:仅显示条款消失,无原因说明 |
2. 条款内容替换(如第五条从“源代码托管”→“保密义务”) | ✅ 识别实质替换(对比新旧第五条内容,标注“原章节被其他条款取代”) | ❌ Word:误判为“删除旧条款”+“新增无关条款”,掩盖乙方移除甲方技术控制权的意图 |
3. 支付条款重组(50 万→55 万,首付 50%→分期 30%+30%+40%) | ✅ 数值变更捕捉+结构分析(并列对比金额、支付节点,标注“总费用增加”“改为里程碑分期支付”) | ❌ Word:整段标黄,需人工核对数字;无法识别分期支付带来的现金流风险 |
4. 新增限制性条款(如乙方保留知识产权) | ✅ 语义关联分析(将协议 B 第七条与协议 A 删除的第四条关联,揭示“权益降级”链条) | ❌ Word:孤立显示“新增条款”,未关联删除动作,无法发现乙方用技术保留条款替代甲方所有权 |
5. 条款位移无修改(如保密义务条款位置调整) | ✅ 智能消歧(标注“条款内容未变,仅章节编号调整”) | ❌ Word:错误标记为“删除+新增”,制造虚假变更点 |
3、系统架构一览
整个协议比对分析流程可以大致分为三个主要阶段:
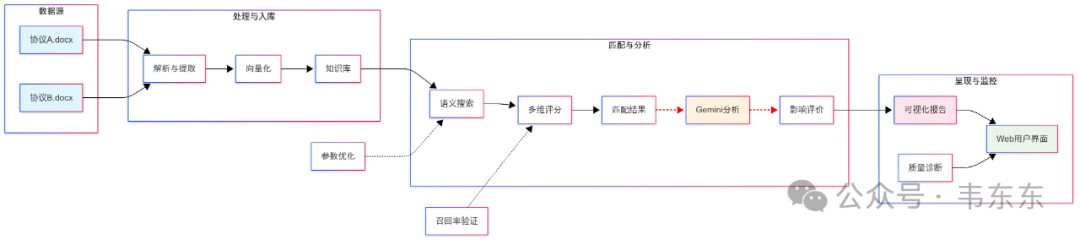
3.1处理与入库
数据输入与解析:系统首先接收“协议 A.docx”和“协议 B.docx”作为“数据源”。接着,通过“解析与提取”步骤,把两份文档结构化,提取出独立的条款或段落。
向量化与建库:提取出的文本块经过“向量化”处理,被存入 RAGFlow 知识库,为后续的语义检索做好准备。
3.2匹配与分析
语义检索与匹配:以协议 A 的条款为基准,在知识库中进行“语义搜索”,以查找协议 B 中与之最相似的对应条款,从而找出所有可能的新增、删除和修改项。
评分与结果生成:搜索到的条款对会经过“多维评分”系统,根据语义相似度等多个维度进行打分,最终形成明确的“匹配结果”。
智能分析与评估:匹配结果(即差异项)被送入“Gemini 分析”(本案例使用的是Gemini-2.5-flash)模块,评估这些差异可能带来的潜在影响。
3.3呈现与监控
报告生成与展示:通过Web 用户界面呈现给用户。用户可以在界面上看到类似传统 Diff 工具的高亮对比、由Gemini 生成的变更摘要以及深度的影响分析。
4、核心环节拆解
为了更清晰的展示每个核心环节的实现要点,下面按照数据流逐一进行拆解说明:DOCX 解析 → 条款分块 → RAGFlow 向量化 → 语义匹配 → LLM 分析 → HTML 展示
4.1DOCX 解析阶段 (universal_contract_parser.py)
功能: 从 Word 文档提取结构化条款
复制双重正则匹配:match1 处理标准格式,match2 处理缺失编号的情况
容错机制:自动补充缺失的条款编号
4.2条款分块阶段(universal_contract_parser.py)
复制元数据分离:条款标题等元数据单独存储,不参与向量化

分隔符设计:使用""分隔条款,避免向量化时的干扰
结构化存储:每个条款包含 title、content、source_document 等字段
4.3RAGFlow 向量化阶段(ragflow_correct.py)
复制
向量化模型:使用 embedding 模型为每个条款生成语义
向量相似度计算:支持跨位置的语义相似度匹配
分块策略:使用"naive"分块保持条款完整性
阈值控制:通过 score_threshold 控制匹配精度
4.4语义匹配阶段 (contract_comparer.py )
复制脚本遍历协议 A 的所有条款,在协议 B 的知识库中搜索相似条款
通过相似度阈值判断是否匹配
匹配成功且内容相同 → UNCHANGED
匹配成功但内容不同 → MODIFIED
匹配失败 → DELETED
检查哪些 B 条款没有被匹配过,直接标记为ADDED。
4.5LLM 分析阶段(gemini_client.py)
复制4.6HTML 展示阶段 (htmlreporteroptimized.py )
智能排序:核心变更优先显示,高风险条款突出显示
精确对比:句子级和词级的双重diff算法
复制5、工程实践梳理
5.1分块不准的问题
预处理之后 markdown 文档虽然是按照 RAGFlow 的 naive 模式的默认的双换行符进行分块,默认的分块大小是 128,第一次测试时发现两份协议中的 10 个分段并不是被分成了 10 个块。而是协议 A 生成 6 个分块,协议 B 生成 7 个分块。这说明 RAGFlow 在处理时自动合并了一些过短的条款。
过短分块的情况
协议 A 有 6 个分块长度 < 100 字符
协议 B 有 4 个分块长度 < 100 字符
最短的只有 43 字符(第七条 违约责任)
RAGFlow 合并逻辑
RAGFlow 猜测是有最小分块大小限制(比如 100 字符)当检测到过短的分块时,会与相邻分块合并。本着工程优化的理念,需要通过调整参数来解决这个自动合并的问题,而不是对抗系统逻辑。
总的来说,RAGFlow 的分块预设逻辑是默认先按分隔符切分,然后根据 chunk_token_num 目标大小合并小片段。如果设置很小的 chunk_token_num,系统就倾向于保持原始分隔符的分割结果。为了更好的测试分块的最佳数值,我写了一个测试脚本 test_ragflow_chunk_size.py 进行了对比测试结果如下:
配置 | 协议 A 分块数 | 协议 B 分块数 | 效果 |
默认配置 128 | 6 | 7 | 分块合并严重 |
chunk_size=30 | 10 | 10 | ✅ |
chunk_size=20 | 10 | 10 | ✅ |
chunk_size=10 | 10 | 10 | ✅ |
经过测试最后选择了 30 作为分块大小。需要说明的是,这个分块选择比较小和我设计的这个测试用例有直接关系,各位再自己手头项目进行复现时,要根据实际情况调整。目标是确定的,就是要保证按照预处理的条款进行单独的分块,否则会影响后续流程的准确性。
复制5.2召回率和精度平衡的问题
在协议对比场景中,召回率=正确匹配的条款对数量/实际应该匹配的条款对总数,预期目标肯定是尽可能找到所有真实的条款对应关系。关于召回率的高低,首先需要考虑大致三种情形:
小幅修订:85-95%(大部分条款应该找到对应)
中等修订:70-85%(有一些删除重组但主体保留)
大幅重构:50-70%(结构性变化较大)
对于协议对比场景来说,核心原则是宁可多召回让 LLM 判断,也不要遗漏真实匹配。通过多维度评分过滤低质量匹配。同样的,经过专门的测试脚本(test_matching_params.py )对 Top-k 和相似度阈值多组对照之后发现:
复制总之,Top_k 并非越大越好,虽然增加找到正确匹配的概率,尤其是对于位置变化大的条款更有效。但会增加计算开销,可能引入更多噪音,也可能会降低匹配精度(如果阈值设置不当)。
复制5.3优化效果验证问题
有了前两步的调优后,还差个最后一步闭环验证。通过 verify_optimization.py脚本最后评估下:量化指标验证(匹配率、变更分布、问题密度)、多维度质量评估(不仅看召回率,还要看误匹配率、可疑匹配数)、智能诊断机制(基于经验模式识别问题并提供具体建议)、基准线建立(为后续迭代提供质量基准)。
复制这种验证驱动的调试模式确保了理论优化到实际效果的转化,防止过度优化破坏系统稳定性,同时把调试经验固化为可执行的验证逻辑,形成完整的"测试→优化→验证"工程闭环。
6、写在最后
6.1技术路线迭代
传统算法(如 Myers差分、Levenshtein 距离)本质是文本序列比对工具,其技术基因决定了其局限性。上述示例展示的协议对比优化效果总结如下:
- 语义理解: 识别内容相同但位置不同的条款
- 智能匹配: 处理条款编号变化和结构调整
- 深度分析: 区分实质性修改 vs 格式调整
- 可视化: 提供清晰的差异展示和统计
数据驱动决策
在众多工程优化方向中,一种经典且有效的做法就是通过实际测试找到最优配置。在这个协议对比场景中,可以为不同类型的协议找到合适的参数,也建议将测试无误的最优参数保存为配置文件以便长期维护复用。


