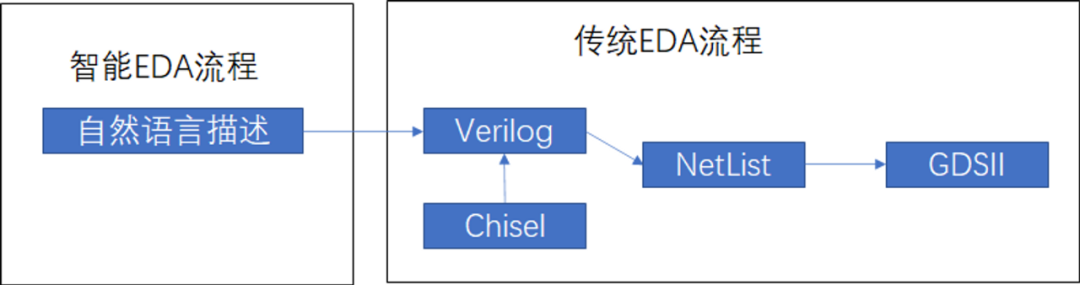
特征工程是模型训练之前运行的关键过程,因为输入数据的质量直接决定了模型输出的质量。
虽然深度学习模型擅长从图像或文本等非结构化数据中自动学习特征,但明确的特征工程对于表格数据集仍然至关重要。
在本文中,云朵君将展示特征工程对回归任务的影响,特别关注具有混合数字、分类和基于时间的特征的大型表格数据集。
什么是特征工程
特征工程是从原始数据中选择、转换和创建新特征以提高机器学习模型性能的过程。
它涉及使用领域知识从数据中提取最相关的信息,并以适合所选机器学习算法的方式表示它。
特征工程的好处
精心设计的特征可以显著提高模型的预测能力,即使是简单的模型也可以掌握复杂的关系,因为它可以:
- 降低数据稀疏性:大多数现实世界的数据集都是稀疏的,包含许多零值和缺失值。特征工程可以整合信息并创建更密集的表示,使模型更容易学习。
- 处理多种数据类型: 原始数据有多种格式,例如数值、分类、文本和时间。特征工程将这些类型转换为模型可以处理的数字格式。
- 解决数据噪声和异常值:特征工程减轻了噪声数据和异常值的影响,从而产生了更稳健的模型。
当我们可以将特征格式化为直接对应于问题域中的有意义的概念时,它可以使模型的决策更具解释性、准确性和稳健性。
特征工程中的常用技术
一些常见的特征工程技术包括:
对数转换
- 将对数应用于数值特征。
- 可以使分布更加对称,使模型呈现正态分布。
- 最佳情况:处理倾斜的数值特征。
多项式特征创建
- 通过将现有特征提升到幂(例如 x2、x3)来生成新特征。
- 创建交互项(例如,x∗y)。
- 最佳情况:捕捉非线性关系。
分箱(离散化)
- 将连续的数值分组到箱中。
- 可以减少微小波动的影响并使关系更加线性。
- 最佳情况:用线性模型处理非线性关系,数据包含显著的异常值或偏差。
基于时间的特征
- 提取星期几、月份、年份、小时、季度,甚至更复杂的特征,如“是周末”、“是假期”。
- 计算事件之间的时间差。
- 最佳情况:季节性影响预测。
工作流程
虽然没有一刀切的方法,但特征工程的一般工作流程通常涉及从定义问题和成功指标开始的整个项目生命周期。
在本文中,我将演示第 1 阶段和第 2 阶段(图中的蓝色框),特别关注特征工程。
 图:具有特征工程的机器学习项目工作流程
图:具有特征工程的机器学习项目工作流程
对于第 3 阶段,“通过机器学习实现准确性”涵盖了泛化的核心概念,假设了损失的根本原因。!
第一阶段:基础
1. 问题
对于在线零售业务,了解未来客户支出对于营销、库存管理和战略规划至关重要。
让我们想象这样一个场景:企业在销售增长方面苦苦挣扎,寻找可行的见解。
2. 成功指标
我选择平均绝对误差 (MAE)作为主要指标,因为它对偏斜数据具有稳健性(稍后,在 EDA 期间,我将讨论目标变量:销售额的数据分布)并选择MSE作为支持指标。
3. EDA 和特征工程
这是初始阶段数据准备的基础部分。
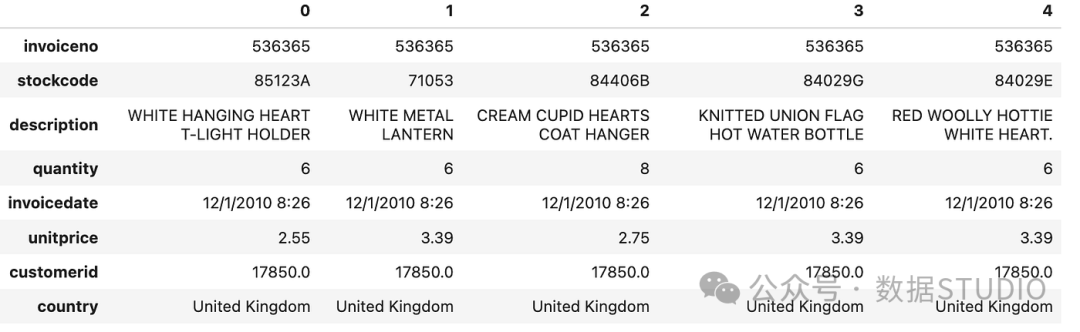
为了演示,我将使用来自加州大学欧文分校机器学习库的在线零售数据:直接在@公众号:数据STUDIO 原文文末留言需要即可,云朵君将回复给大家:
 图:变量表
图:变量表
 图片
图片
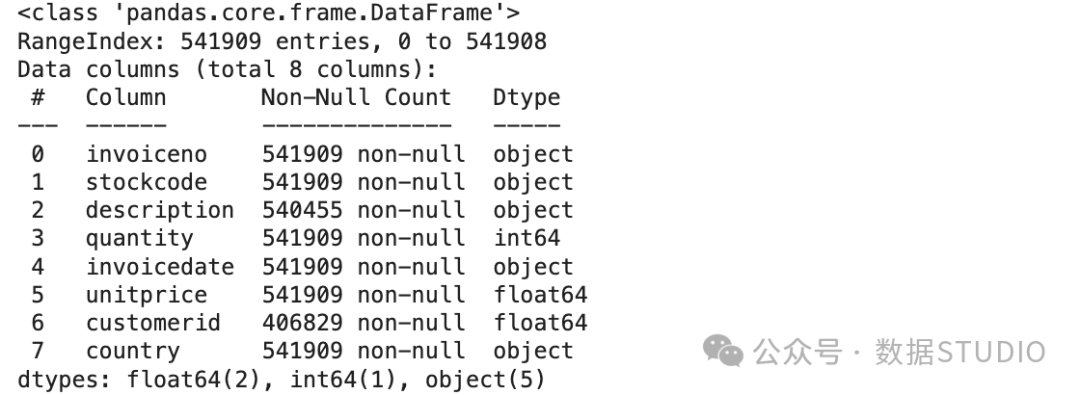
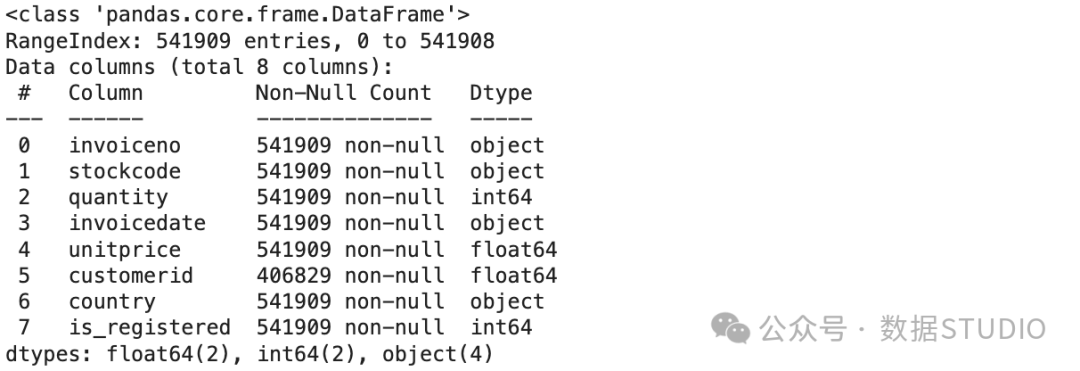
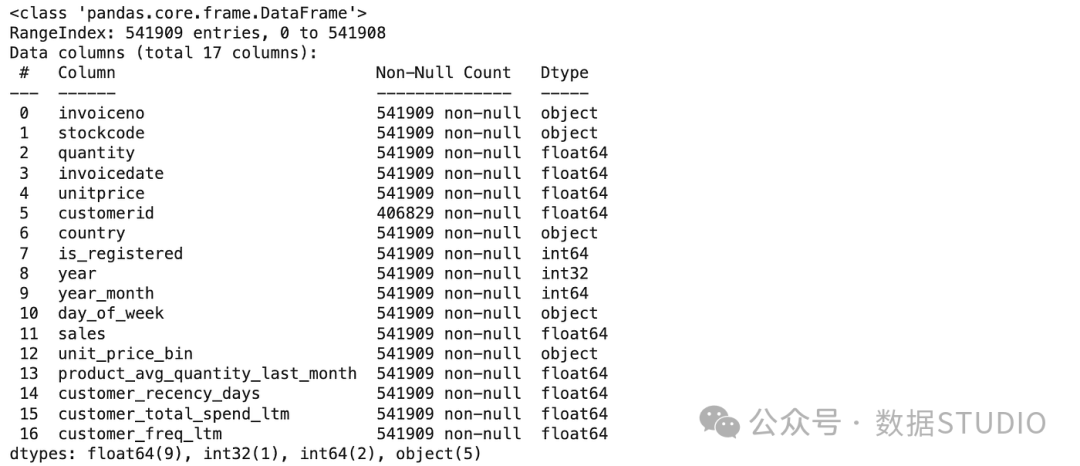
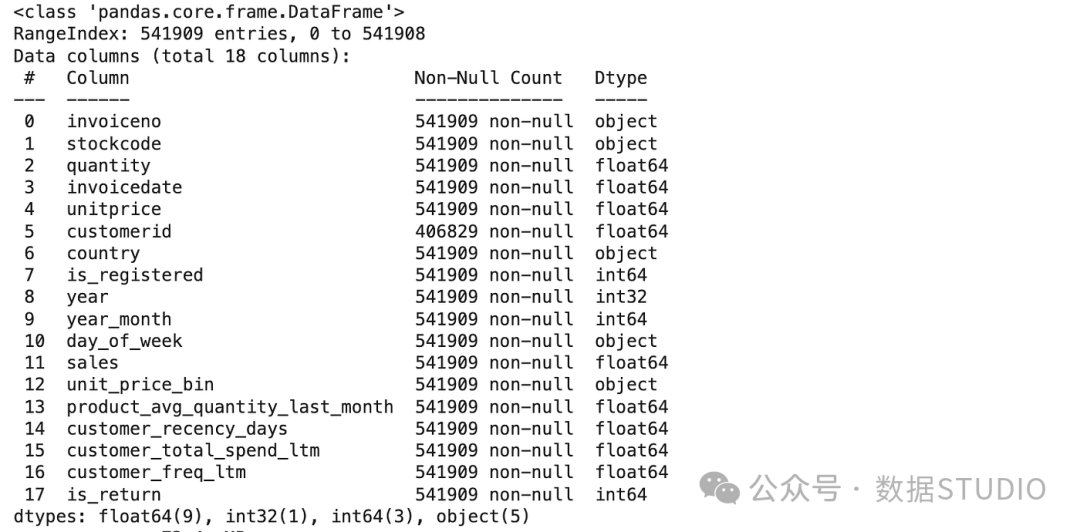
该数据集有541,909 个数据点,具有八个特征:
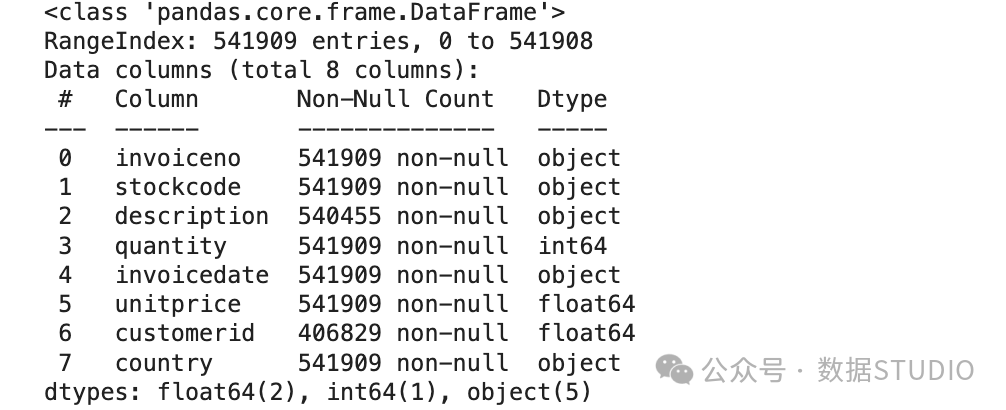 已加载数据集
已加载数据集
实际上,这些数据可以是简单的 Excel 表,也可以是存储在云服务器上的信息,或者我们可以组合多个数据源。
数据清理
在进入 EDA 之前,我将按照一般原则清理数据:
- 保留数字类型: 如果某列应为数字(例如quantity、unitprice、customerid),请保留该列。使用数字类型进行数字运算会更加高效且更有意义。
- 混合/字符串数据的对象类型: Pandas 中的dtypeobject指的是包含混合类型或主要为字符串的列。如果某列确实包含数字和字符串的混合,object则 dtype 为默认值。
- 各种缺失数据: Pandas 会处理NaN缺失的数字数据和None缺失的对象数据。然而,当我们读取数据时,缺失值可能表示为空字符串、特定文本(例如“N/A”),甚至只是空格,而 Pandas 可能无法自动将其解释为NaN。我们需要识别这些值。
识别 NaN
对于具有混合数据类型的列,我将潜在的缺失值(如空格或“nan”字符串)转换为NumPy’s NaN。
这对于后期的准确归集是一个至关重要的准备。
 图片
图片
现在,识别每列中缺失的数据(NumPy 的 NaN):
 图:每列中发现的缺失值
图:每列中发现的缺失值
处理description和customerid列中缺失的数据:
- 我决定删除description列,因为假设它对未来预测的影响有限。 注意:文本数据对于产品因式分解可能很有价值,尤其是在缺失部分比较有限的情况下。
- 我保留了原有的customerid列来评估唯一用户的影响,同时引入了一个新的is_registered二分类列(1:已注册,0:未注册),该列对应于每个客户 ID,假设没有 ID 的客户未注册。 注意:customerid这会导致基数过高。稍后我将使用二分类编码来解决这个问题。
转换数据类型
最后,考虑到潜在的特征工程,我转换了invoicedate和 customerid的数据类型:
 添加了第 7 列。第 5 列的数据类型已更新。
添加了第 7 列。第 5 列的数据类型已更新。
探索性数据分析(EDA)和特征工程
清理完数据集后,我们现在可以转到 EDA。
探索性数据分析 (EDA) 是一种专注于总结和可视化数据以了解其主要特征的数据分析技术。
从技术角度来说,我们可以执行无数次 EDA,尤其是在复杂数据集上。但我们的主要重点是揭示需要设计哪些特征,并深入了解数据预处理,从而提升模型性能。
任何其他分析都应该由模型本身处理,因为真正的底层模式要么太微妙,要么太复杂,我们无法手动发现。
因此,EDA 成为模型确定哪些分析(例如隐藏趋势、群体差异)值得转化为预测的第一步。
EDA 必须包含:
- 用于理解数据的基本分析(以单变量为重点) ;
- 基于与项目目标直接相关的假设进行的项目特定分析(以双变量为重点)
1)基本分析(单变量重点)
这个初始阶段是通过单独分析每个变量来从根本上了解数据集。
首先,为了准备 EDA,我从列中提取了year、month,并按以下顺序对数据进行排序:day_of_week,invoicedate,invoicedate
还推出了sales销售分析专栏:
数据集如下:
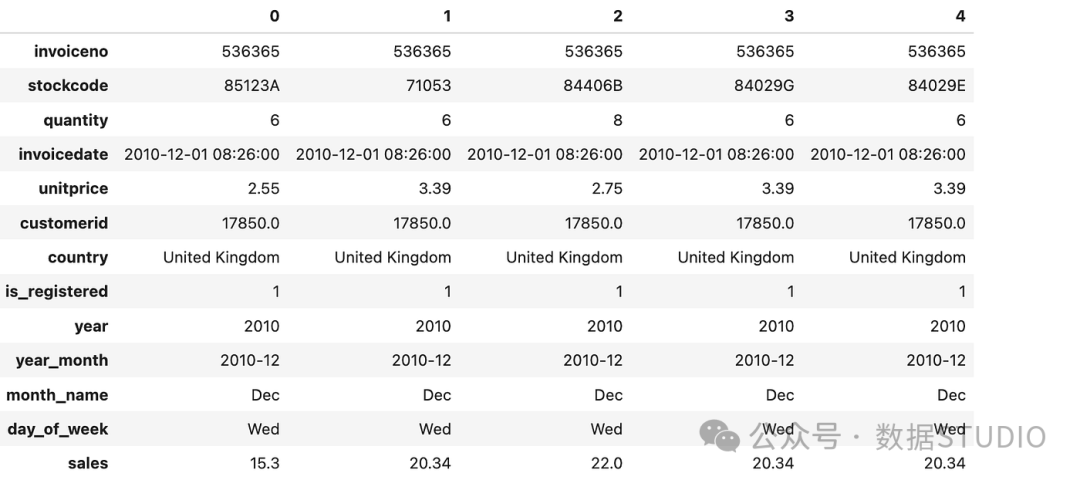 图片
图片
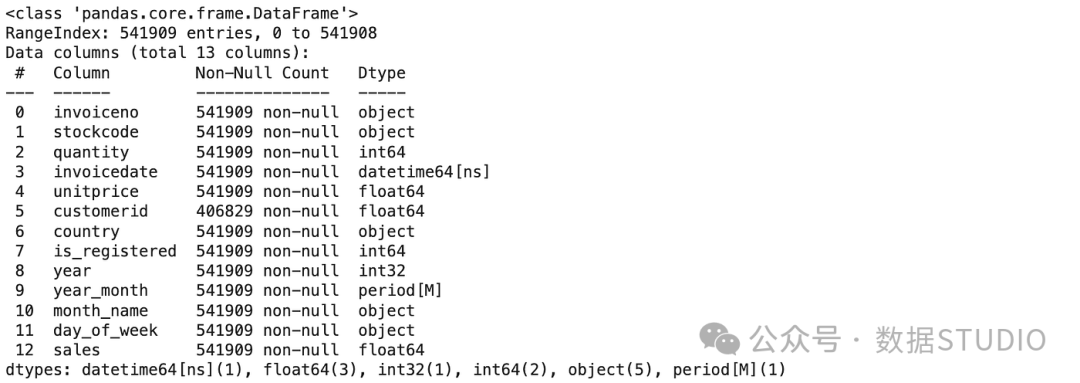 添加了第 8 列至第 12 列
添加了第 8 列至第 12 列
了解数据分布
我绘制了数值特征的 PDF 和分类特征的直方图,以识别异常值、倾斜和重尾等特征。
尽管真实的数据分布过于复杂而难以完全掌握,但分析对于有效的预处理和模型选择至关重要。
数值列的 PDF
unitprice 和sales都是稀疏的,并且尾部严重,存在显著的异常值。我将使用MAE作为评估指标,因为它对倾斜数据具有较好的鲁棒性。
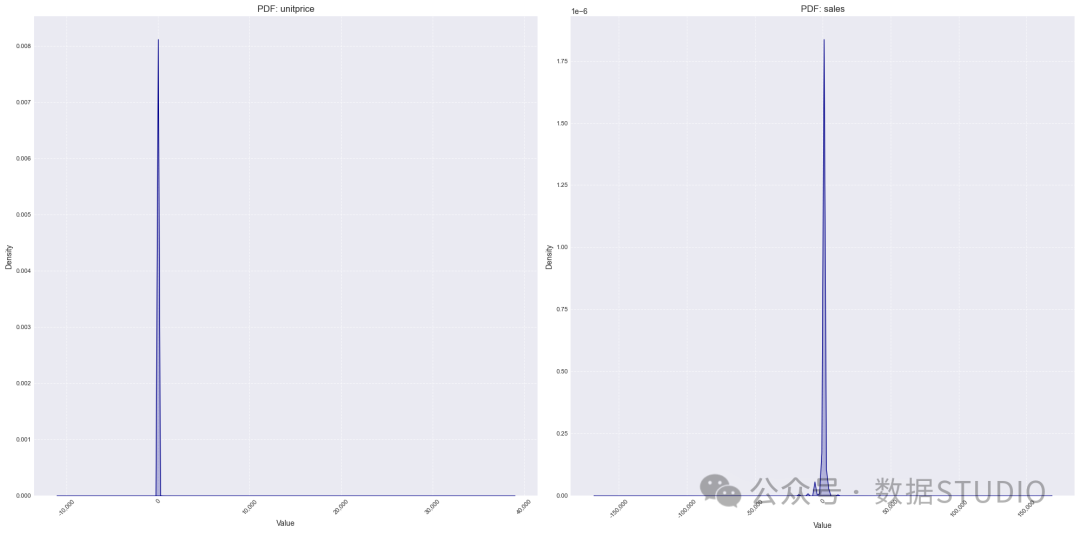 图:unitprice和sales的PDF
图:unitprice和sales的PDF
图:unitprice和sales的PDF
- unitprice:最大值:38,970.0,最小值:-11,062.1,平均值:4.6,标准差:96.8
- sales:最大值:168,469.6,最小值:-168,469.6,平均值:18.0,标准差:378.8
分类特征直方图
invoiceno、year_month和day_of_week均匀分布:
 图片
图片
 图片
图片
 图片
图片
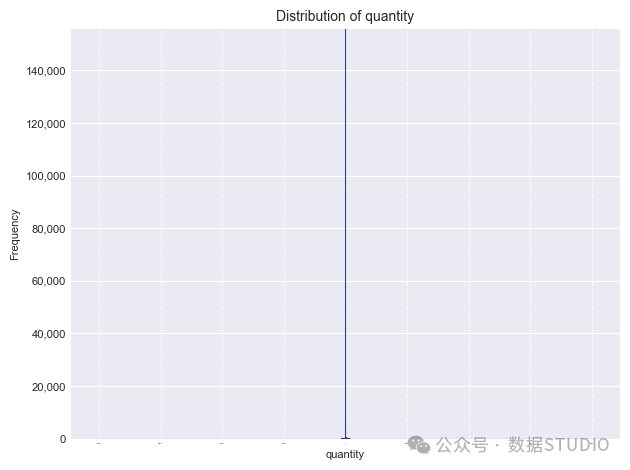
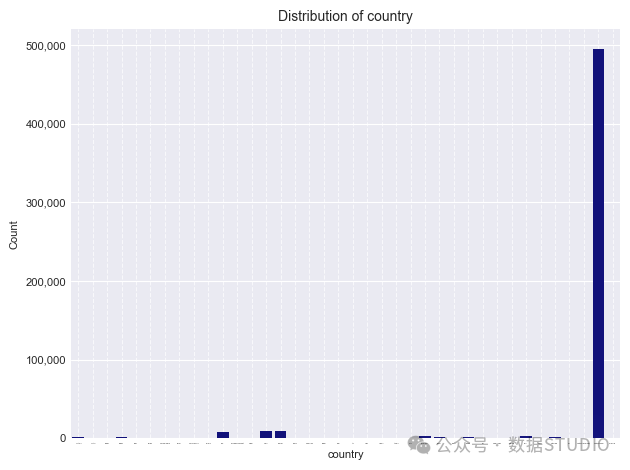
stockcode左侧有一个峰值,右侧有一个长尾,而quantity和country则显示出退化分布,其中数据集中在几个类别中:
 图片
图片
 图片
图片
 图片
图片
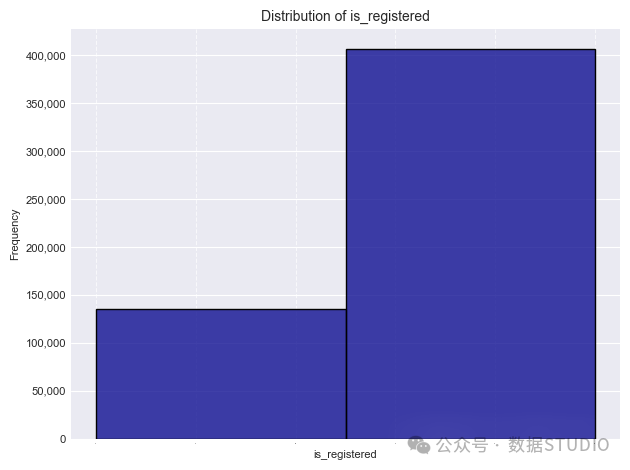
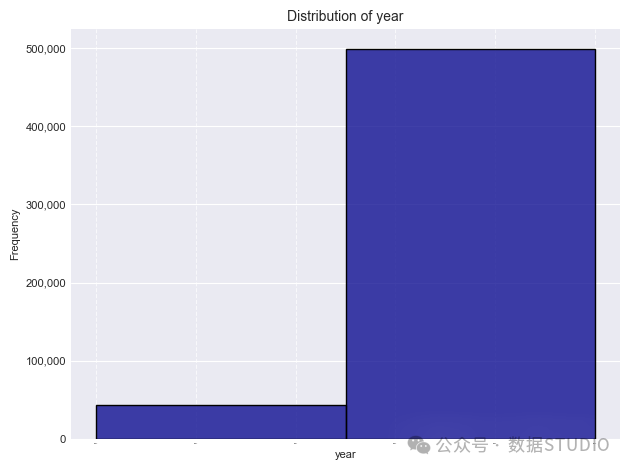
is_registered和year结果也是二分类的:
 图片
图片
 图片
图片
在此基础上,我将进行针对特定项目的 EDA,以找出额外的特征工程机会。
2)项目特定的EDA
此阶段深入研究,特别是寻找变量之间的关系,特别是潜在特征和目标变量之间的关系:sales。
首先,我将根据“销售增长”这一挑战的潜在解决方案提出三个假设。实际上,可以利用商业和专家的见解来完善这些假设。
假设1
“销售趋势是由一周中的某天或一个月中的某天决定的。”
鉴于数据集有限的 13 个月的销售数据(二进制year),我关注较短的趋势周期。
- 需要设计的潜在特性is_weekend:day_of_month
- 潜在商业解决方案:顺应趋势的大量促销。
假设2
“产品销售受时间和价格点驱动。”
需要设计的潜在特性:
- unit_price_bin:unitprice离散化为“低”、“中”、“高”类别,直接解决价格影响和非线性。
- product_avg_quantity_last_month:计算每个产品quantity在上一日历月的平均销量stockcode并获取近期产品的受欢迎程度。
- product_sales_growth_last_month:从 2 个月前到上个月stockcode的销售额百分比变化,以确定流行产品。
潜在的商业解决方案:
- 动态定价(通过促销时机预测最佳价格点的模型)。
- 定制产品推荐(预测产品因素相似性的模型)。
假设3
“活跃的顾客往往会购买更多商品,从而促进销售。”
需要设计的潜在特性:
- customer_recency_days:预测日期(上个月底)与客户上次购买日期之间的天数,以评估近期购买的可能性。
- customer_total_spend_ltm:客户过去三个月产生的总销售收入。这是对客户近期货币价值的直接衡量。
- customer_freq_ltm:过去三个月内客户开具的唯一发票总数。这是直接影响销售额的参与度指标之一。
潜在的商业解决方案:
- 分层客户忠诚度计划(预测唯一用户保留时间的模型)
- 营销媒体组合优化(预测新客户价值的模型)
现在,执行 EDA 并决定要设计哪些特性。
假设 1
“销售趋势受一周中的某天或一个月中的某天的影响。”
除了11月的峰值之外,按月和按周划分的销售趋势没有出现明显的模式。因此,我选择不添加基于此假设的其他特征。
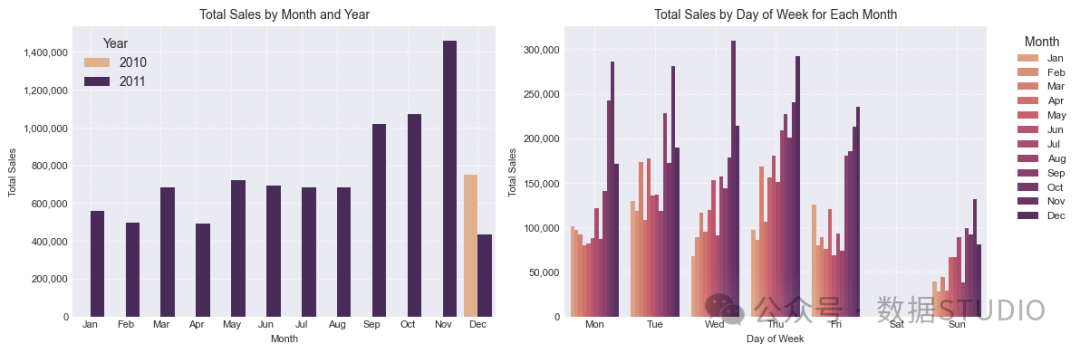 图:按月份和星期几划分的销售趋势
图:按月份和星期几划分的销售趋势
图:按月份和星期几划分的销售趋势
假设2
“产品销售受时间和价格点驱动。”
对于unit_price_bin,几乎所有月份的三个价格区间的中线都接近于零。所有区间的四分位距 (IQR) 也很短,这表明 25-75 百分位数数据落在一个非常小的低量范围内。
然而,我们可以看到异常值占据了主导地位,形成了明显的分层。
因此,我决定添加特征unit_price,同时保留原有的粒度,使用箱内的精确值来预测数量。
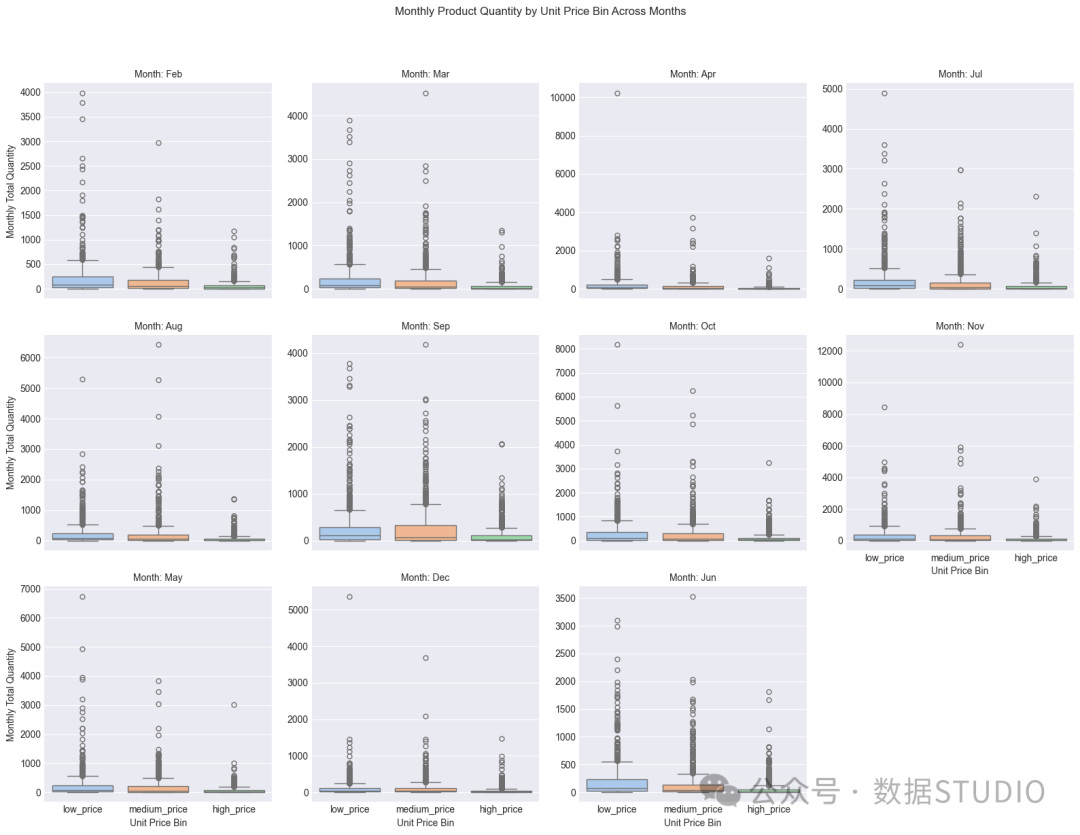 图:按价格范围(低、中、高)划分的月销售总量及中位数和四分位距
图:按价格范围(低、中、高)划分的月销售总量及中位数和四分位距
添加unit_price_bin到最终数据集:
 添加了第 13 列
添加了第 13 列
product_avg_quantity_last_month也显示出非常强的正相关性,这可以作为一个动量特征,表明上个月销量好的产品本月也容易销量好。我会添加这个特征。
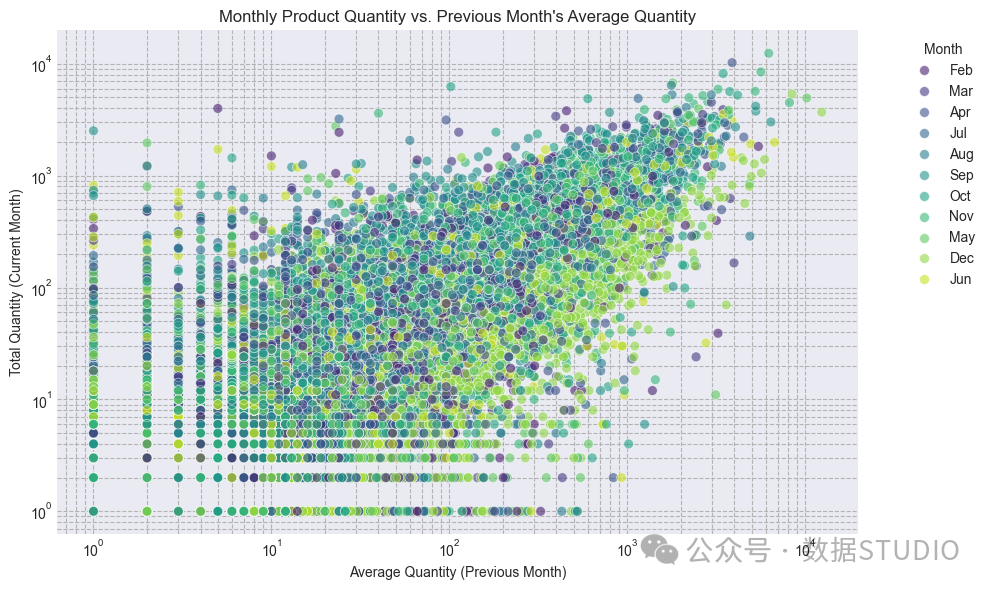 图:本月和上个月销售的平均产品数量
图:本月和上个月销售的平均产品数量
添加product_avg_quantity_last_month到最终数据集(也处理插补):
 添加了第 14 列
添加了第 14 列
另一方面,product_sales_growth_last_month它没有表现出很强的线性/单调关系。考虑到这个特征的预测能力有限,我选择不添加它。
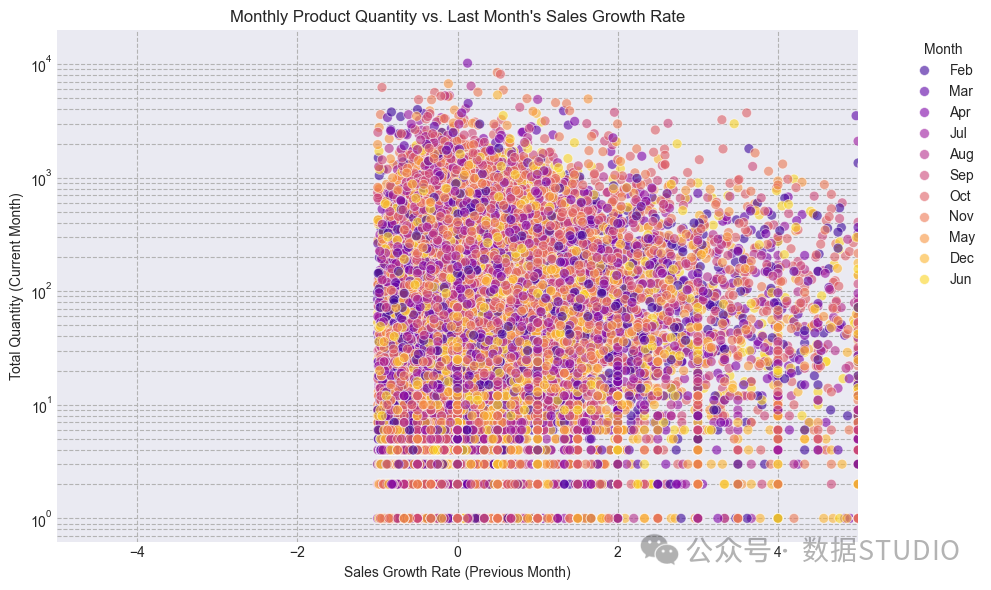 图:月度产品数量与上月销售额增长率
图:月度产品数量与上月销售额增长率
假设3
“活跃顾客倾向于购买更多产品并对销售做出贡献。”
customer_recency_days表明新近度较低的客户(最近的购买,例如 x < 60 天)往往表现出更高的月销售收入,表明呈反比关系(图中红色虚线)。
我将添加此特征来预测每月的销售收入。
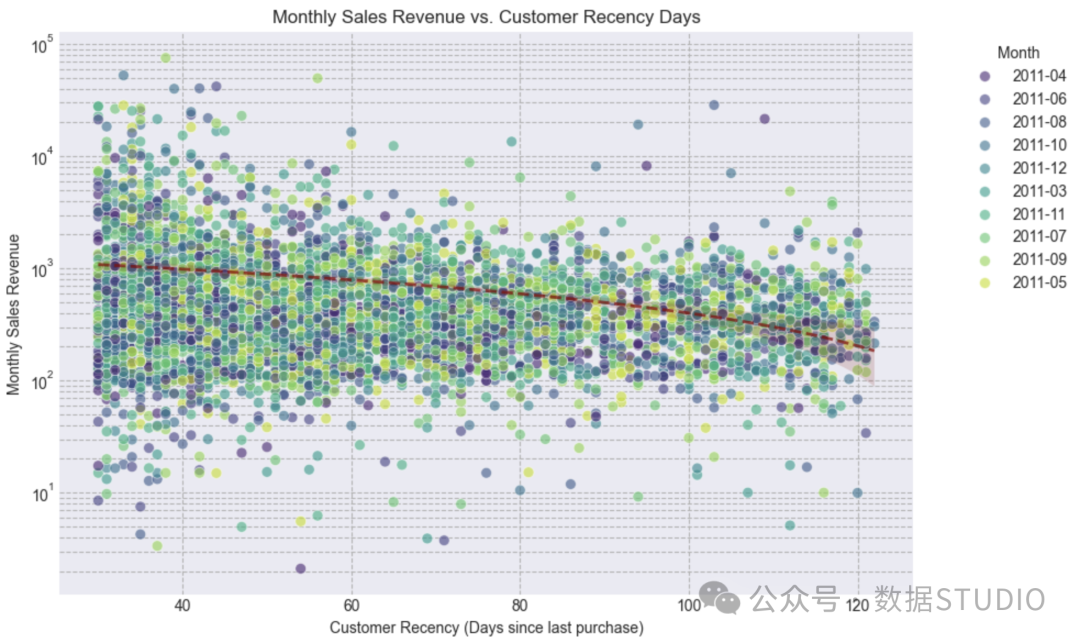 图:月销售额与客户最近消费天数
图:月销售额与客户最近消费天数
添加customer_recency_days到数据集:
 添加了第 15 列
添加了第 15 列
customer_total_spend_ltm显示出客户过去三个月的总支出与其当前月销售收入之间存在明显的正相关关系。这表明,过去支出越高,当前收入就越高,这是一个非常有效的预测特征。我会添加这个特征。
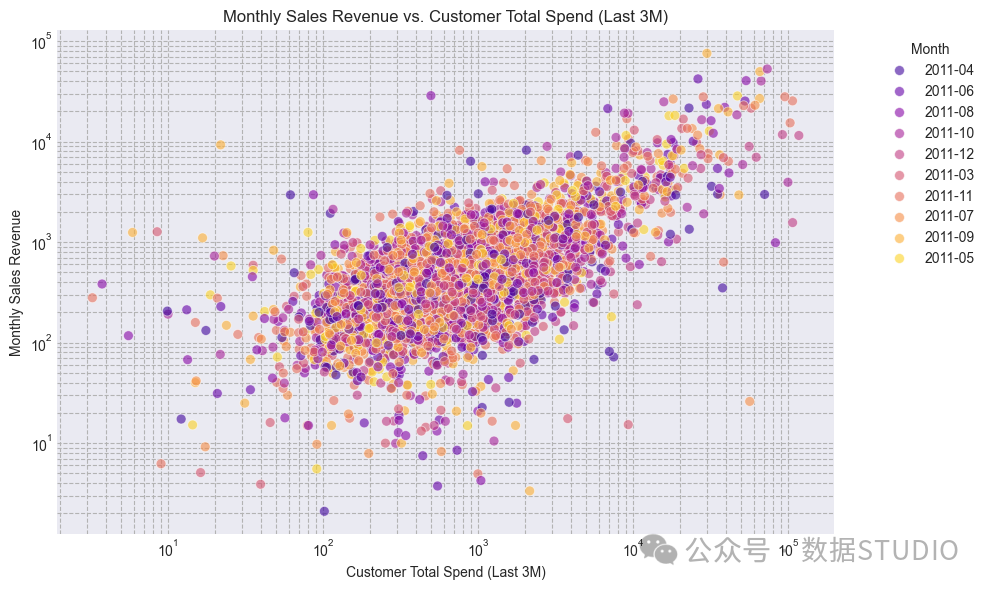 图:过去三个月的月销售额与客户总支出
图:过去三个月的月销售额与客户总支出
添加customer_total_spend_ltm:
 添加了第 16 列
添加了第 16 列
customer_freq_ltm还展示了客户过去三个月的购买频率与其当前月销售收入之间的正相关关系。过去三个月拥有更多独立发票的客户往往能带来更高的月收入。我也会添加此特征。
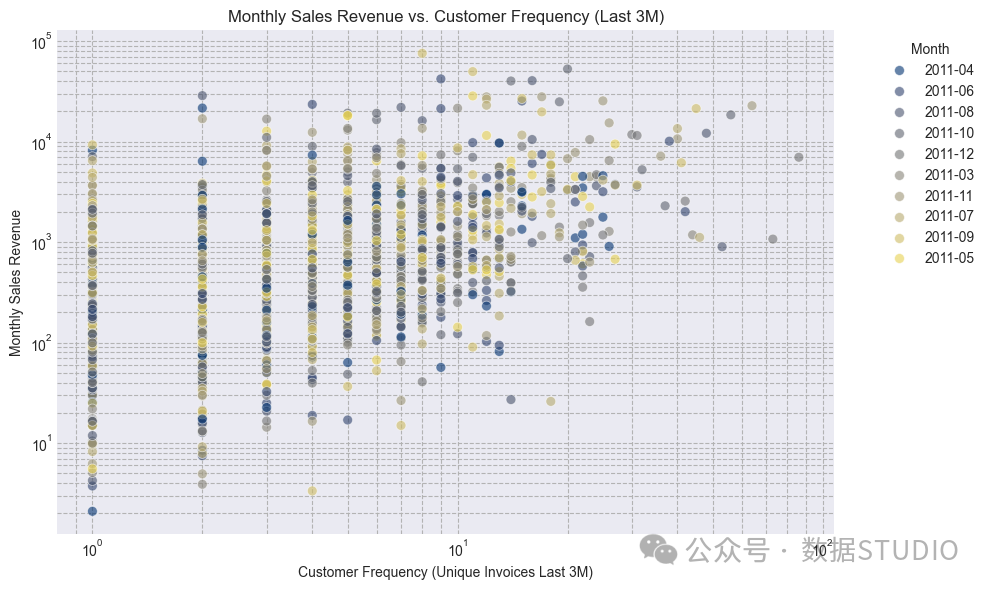 图:过去三个月的月销售额与客户频率
图:过去三个月的月销售额与客户频率
添加customer_freq_ltm:
 添加了第 17 列
添加了第 17 列
对缺失值的最终检查
特征工程完成后,我检查了剩余的缺失值,在更新后的数据集中的stockcode、quantity、unit_price_bin和country列中发现了五个缺失项:
 我会在编码过程中处理丢失的客户 ID)
我会在编码过程中处理丢失的客户 ID)
我会在编码过程中处理丢失的客户 ID)
逐一检查这些缺失的项目并进行估算。
注意:鉴于 540k+ 个样本中最多只有 20 个有缺失值,因此可以选择按行删除(即从数据集中删除这些样本)。
对于stockcode和unit_price_bin,样本中缺失stockcode或unit_price_bin的其他值看起来是合法的。
我用“unknown”(字符串)和“low”换替换了stockcode和unit_price_bin中的缺失的值:
 图片
图片
country采取同样的过程,和列中的缺失值quantity分别用其众数值和销售额/单价值填充:
最后,转换数据类型以最终确定数据集:
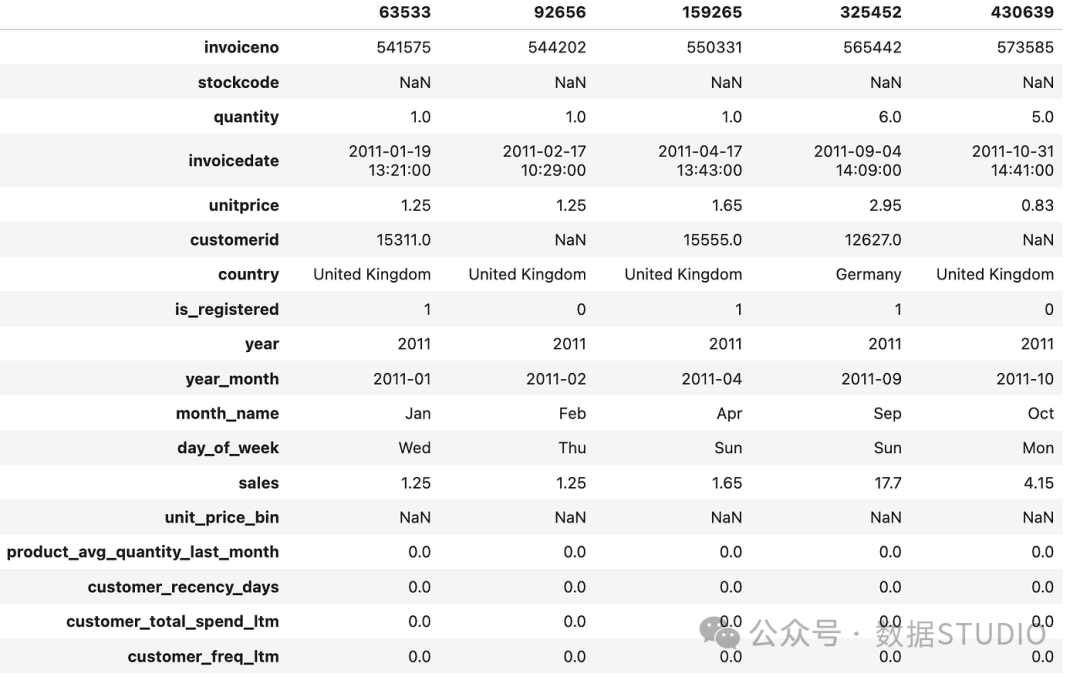
 最终数据集
最终数据集
该数据集的最终版本有541,909 个样本,包含17 个特征:
回顾——第一阶段的特征工程
根据 EDA 结果,我添加了 11 个特征:
- 来自单变量EDA :is_registered,year,year_month,month_name,day_of_week,sales
- 来自双变量EDA:unit_price_bin,product_avg_quantity_last_month,customer_recency_days,customer_total_spend_ltm,customer_freq_ltm
并删除了一个特征:description由于其缺失值量较大且对预测的影响有限。
一文带你用sklearn做特征工程
一文详尽特征工程与数据预处理
4. 模型选择
鉴于数据集复杂且庞大,我选择了以下三种模型:
- 弹性网络:正则化线性回归模型,适合作为线性可分数据的基线。
- 随机森林:一种能够捕捉复杂、非线性关系的强大机器学习模型。
- 深度前馈网络:一种深度学习模型,可作为非线性可分离数据的强大基础。为了有效地管理大型数据集,我使用了PyTorch库。
原理+代码,总结了 11 种回归模型
万字长文,演绎八种线性回归算法最强总结!
总结了九种机器学习集成分类算法(原理+代码)
理论+股市数据实战,总结了五种常用聚类分析算法
总结了17个机器学习的常用算法!
5. 在预处理数据上训练模型
首先,我将数据集分成所有模型的训练集、验证集和测试集。
我故意没有对数据集进行打乱,以保留其时间顺序。
每个模型对预处理的需求不同:
 图:按模型划分的数据预处理要求
图:按模型划分的数据预处理要求
因此,我将准备用于分别训练每个模型的数据集。
弹性网络
弹性网络需要在缩放和编码的数据集上进行训练。
对于数值特征,我应用RobustScaler来处理我们在 EDA 期间发现的显著异常值。
对于分类特征,我应用了BinaryEncoder来限制维度的增加,同时用零替换
customerid列中的缺失值:
随机森林
对于随机森林,我们可以跳过缩放部分:
DFN
DFN 需要缩放和编码。对于数值特征,我使用了StandardScaler,因为它在处理复杂数据方面具有良好的鲁棒性。之后,数据集被转换为TensorDataset:
然后,启动模型:
训练模型:
结果
平均辅助能量吸收
- 弹性网络:训练:19.773 → 验证:18.508
- 随机森林:训练:4.147 → 验证:10.551
- 深度前馈网络:训练:10.570 → 验证:10.987
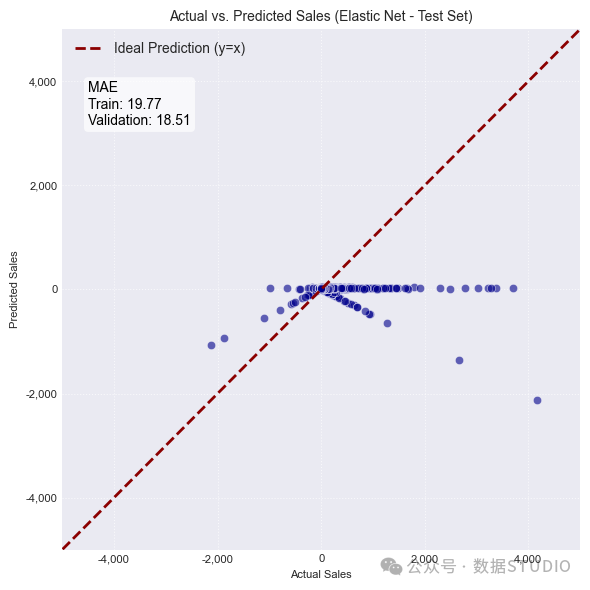
Elastic Net 的泛化能力良好(训练集 19.77,验证集 18.51),但平均误差最高。其预测与实际销售额的偏差约为18.50 美元至 19.77 美元。
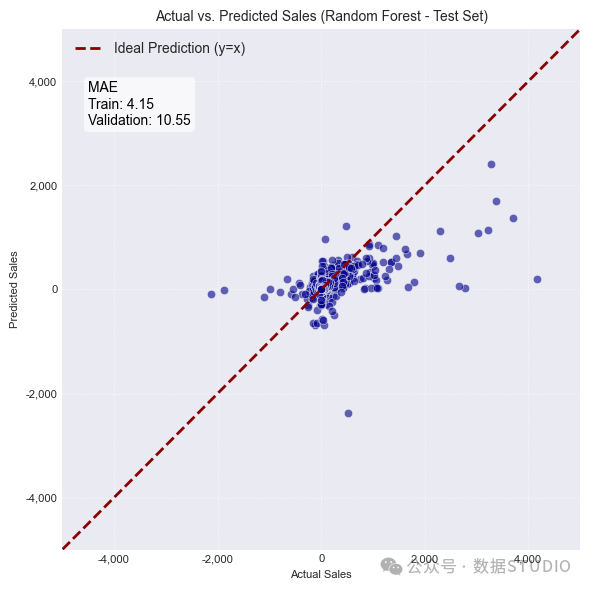
随机森林过拟合严重(训练集 4.15,验证集 10.55)。平均而言,其对新数据的预测偏差约为10.55 美元。
深度前馈网络 (DFN)表现出了出色的泛化能力(训练集 10.57,验证集 10.99),并且在未见数据上实现了较低的平均误差。其预测偏差约为10.99 美元。
总而言之,随机森林是表现最好的模型,但 DFN 在泛化方面也表现出色。
 图片
图片
 图片
图片
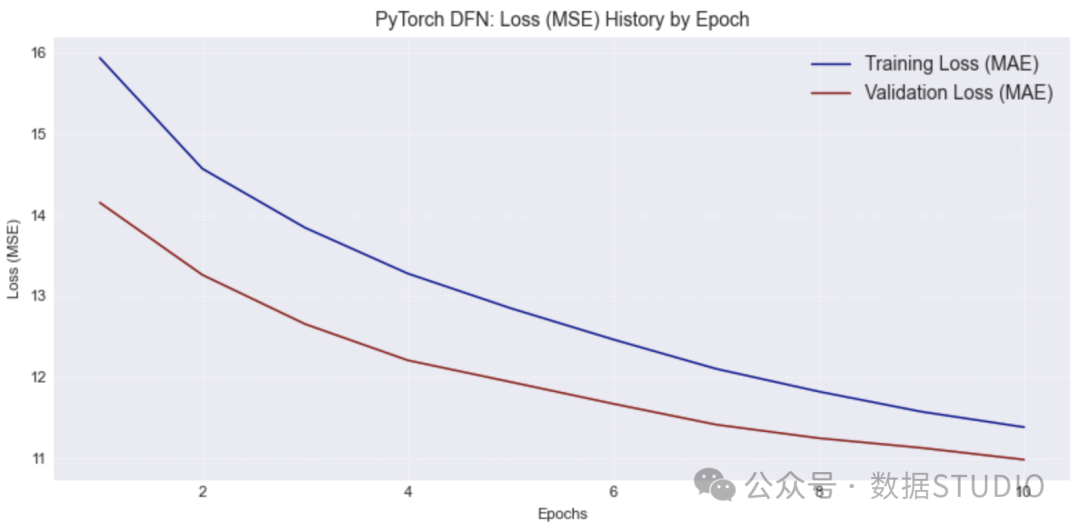 图片
图片
图:实际销售额与预测销售额(左:弹性网络,中:随机森林),DFN 的损失历史记录(右)
第二阶段:迭代改进
第一阶段的结果表明,这三个模型的泛化能力仍有提升空间。
我对销售值应用了对数转换,以便为模型的目标变量创建更加对称的分布。
为了区分退款(sales列中的负销售额)和正销售额,我创建了一个is_return二分类token(1 表示退款,0 表示销售额)。这样一来,sales列就可以只关注正销售额。
从数学上讲,对负值取对数的结果是NaN。因此,我先用零替换负销售额,然后应用拉普拉斯平滑法。这也能避免对数销售额中出现负无穷值。
 添加第 17 列。变换第 11 列。
添加第 17 列。变换第 11 列。
在确保数据集中除 customerid 列外不存在缺失值后:
 图片
图片
我使用相同的预处理步骤和超参数重新训练了模型:
结果
使用记录的销售数据的MSE和实际值销售的MAE来评估模型性能:
弹性网络:
- 对数销售的 MSE:训练集:1.133 → 1.132,泛化集:1.122
- 实值销售的 MAE:训练集:15.825 → 14.714,泛化集:16.509
随机森林:
- 对数销售额的 MSE:训练集:0.020 → 0.175,泛化集:0.176
- 实值销售的 MAE:训练集:4.135 → 7.187,泛化集:9.041
DFN:
- 对数销售额的 MSE:训练集:1.079 → 0.165 泛化集:0.079
- 实值销售的 MAE:训练集:5.644 → 5.016,泛化集:6.197
(基于 50,000 个测试样本的概括。)
与第一阶段相比,所有模型中实际销售额的 MAE 都有所提高,这表明目标变量密度的重要性。
其中,DFN 在训练集(5.64)和泛化集(6.20)中均表现出较低的 MAE,展现出最佳性能,表明其在复杂、大型数据集上的学习和泛化能力较强。其对未见数据的预测偏差约为6.20 美元。
Elastic Net表现出了极好的泛化能力,但其对未见数据的预测偏差为16.51 美元,是所有模型中偏差最大的,这表明其在处理复杂数据集时遇到了困难。
随机森林表现出严重的过拟合,其较低的训练 MAE(4.14)与较高的泛化 MAE(9.04)之间存在较大差距。该模型的下一步可以进行超参数调整,以收紧正则化变量和树结构。
实验总结
实验表明,PyTorch 上的 DFN 在具有 EDA 期间识别的特征的转换数据集上表现最佳。
回到业务解决方案的初始假设,我们可以将这一发现直接用于营销媒体组合优化,例如,使 DFN 能够预测新客户的终身价值并优化对高价值客户渠道的预算分配。
下一步,我们可以在第 2 阶段进一步探索特征工程,或者进入第 3 阶段调整超参数以完善结果。
写在最后
特征工程不仅仅是数据操作;它是一种从原始数据中获取强大洞察力并显著提高模型解决当前问题的能力的战略方法。
在我们的实验中,我们观察到特征工程显著提升了模型的性能,尤其是在与 EDA 和业务目标紧密结合的情况下。通过与领域专家和业务利益相关者合作完善假设,我们有望实现进一步的改进。
通过投入时间和精力来制定有效的输入,我们从根本上增强了模型的学习、概括和提供卓越预测性能的能力。