在大模型(LLM)通过人类反馈进行对齐(RLHF)的过程中,核心的偏好建模方法Bradley-Terry模型(BTM)存在固有理论缺陷,导致模型训练不稳定、效果受限,甚至引发安全隐患。来自作业帮教育科技(北京)有限公司的研究团队,在ICML 2025上提出了一种基于能量的新型偏好模型(EBM),名为无限偏好模型(IPM),并基于此设计了实用的能量偏好对齐(EPA)损失函数。理论分析和大量实验表明,该方法从根本上解决了BTM的缺陷,在多个关键指标上显著超越DPO、IPO、KTO等主流离线对齐方法,为构建更稳定、更可靠、更安全的AI系统提供了新路径。
论文标题: Energy-Based Preference Model Offers Better Offline Alignment than the Bradley-Terry Preference Model作者: Yuzhong Hong, Hanshan Zhang, Junwei Bao, Hongfei Jiang, Yang Song单位: Zuoyebang Education Technology (Beijing), Co., Ltd
论文链接:https://openreview.net/forum?id=t5QNCIltAnICML论文主页:https://icml.cc/virtual/2025/poster/43792
BTM的核心挑战:三大理论缺陷掣肘LLM对齐
基于人类反馈的强化学习(RLHF)的离线版方法(如DPO)是当前LLM对齐的主流技术。然而,其广泛依赖的Bradley-Terry偏好模型(BTM)存在难以克服的理论瓶颈:
“最优解不唯一”难题 (MLE非唯一性): 在LLM生成的海量、近乎无限的文本候选空间中,BTM的最大似然估计常常无法找到一个唯一确定的最佳解,导致模型训练像在“迷雾中寻路”,难以稳定收敛到最优状态。
“奖励失真”风险 (斜率-1线性性偏离): 理想的RLHF要求模型学到的奖励与真实奖励保持严格的“1:1”增长关系(斜率-1)。但BTM难以保证这点,学到的奖励信号可能“失真”,导致模型优化方向偏离人类真实意图。
“数据盲区”隐患 (数据依赖性强): BTM的性能高度依赖已有偏好数据。对于数据未覆盖或未观测到的样本,模型容易产生偏差,如同在“已知地图”外迷失方向。
这些缺陷在智能助手(回答矛盾)、内容生成(质量波动)、安全对齐(危险指令识别不稳)等场景中尤为突出,成为LLM迈向实用化、安全化的关键障碍。
能量模型IPM:为“无限选择”提供理论最优解
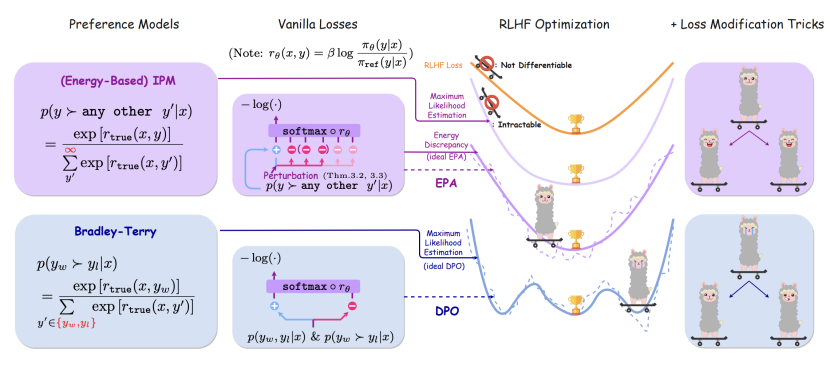
作业帮研究团队另辟蹊径,提出基于能量的无限偏好模型(IPM)。其核心思想是:一个回复的“好”,体现在它比所有其他可能的回复都要好。这通过玻尔兹曼分布形式进行建模。
理论基石稳固:IPM 严格保证了最大似然估计(MLE)的唯一存在性,为模型训练提供了清晰、唯一的优化目标。这直接解决了BTM的“迷雾寻路”问题。
“1:1奖励”的保证: 理论证明,IPM找到的最优解,恰好能使学到的奖励与真实奖励完美满足斜率-1的线性关系,从根本上杜绝了“奖励失真”。
拥抱“无限可能”: IPM通过“全局归一化”的概念,天然适应无限候选空间,有效缓解了BTM在“数据盲区”的偏差问题。
EPA:让理论优势落地的高效“引擎”
然而,IPM的计算涉及对所有可能回复的求和,这在实践中(无限空间)无法直接实现。为此,团队设计了能量偏好对齐(EPA)损失函数,作为寻找IPM最大似然估计的高效近似方案。
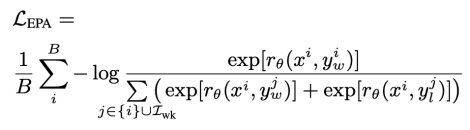
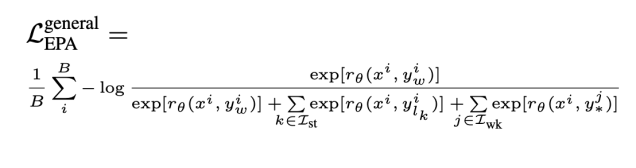
“三样本”对比学习: EPA创新性地结合了三种样本:一个优质正样本(赢家),一个或一组强负样本(普通输家),以及一组弱负样本(错配的样本)。这种组合平衡了信息的明确性和样本的多样性。
“软约束”防过拟合: 损失函数设计巧妙,不仅让赢家得分高于输家,还通过弱负样本引入一种“软约束”或正则化效应,它们的的作用如同“围栏”,防止模型过度关注有限的训练样本对,提升了泛化能力和训练稳定性。
计算高效: 该设计避免了直接处理无限空间,实现了计算可行性。
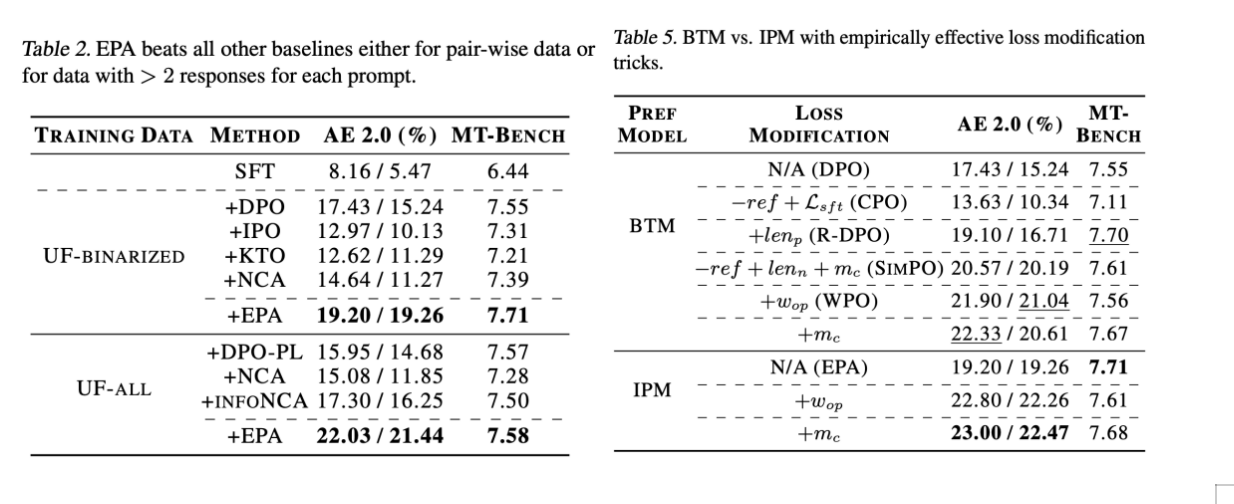
实验验证:全面领先,优势显著
研究在Ultrafeedback、Alpaca-Eval 2.0、MT-Bench等权威基准上,将EPA与DPO、IPO、KTO等前沿方法进行了系统对比:
更“真”的奖励: 在衡量奖励与真实奖励线性关系的关键指标上,EPA显著优于DPO(Pearson系数:0.5808 vs 0.4693;斜率-1线性误差:5.01 vs 5.78),验证了其理论优势在实际优化中的体现。
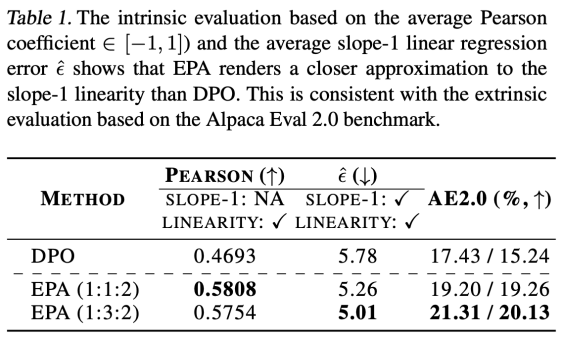
更“优”的生成效果: 在反映人类偏好的黄金基准Alpaca Eval 2.0上,EPA的最高胜率达到21.31%,相比DPO(17.43%)提升接近4个百分点,生成质量获得人类评判者更高认可。
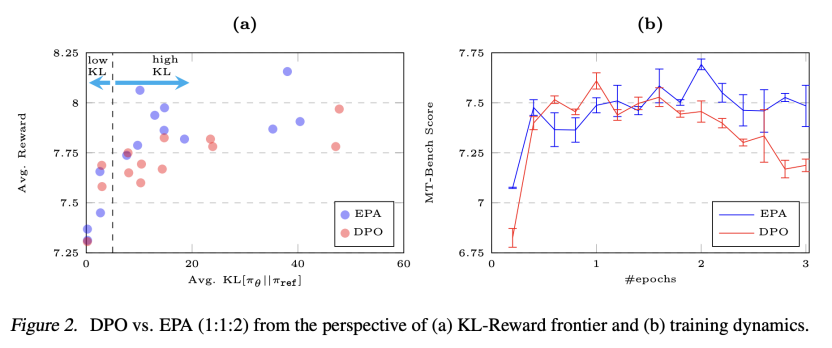
 更“稳”的训练过程: 分析显示,当模型探索空间增大(高KL散度区域)时,EPA学到的奖励质量更高;在MT-Bench上的训练过程也显示出更强的稳定性,过拟合更慢,印证了弱负样本“正则化”的有效性。
更“稳”的训练过程: 分析显示,当模型探索空间增大(高KL散度区域)时,EPA学到的奖励质量更高;在MT-Bench上的训练过程也显示出更强的稳定性,过拟合更慢,印证了弱负样本“正则化”的有效性。
应用潜力广阔,助力安全可控AI
EBM(IPM/EPA)框架为解决LLM离线对齐的核心挑战提供了新范式,具有重要应用前景:
低资源高效对齐: 更高效利用有限偏好数据,降低对海量标注的依赖。
加固安全护栏: 稳定的奖励学习特性,为模型规避有害输出提供更可靠的安全约束。
多模态扩展: 理论框架可推广至图文、视频等多模态内容的偏好对齐。
未来方向将聚焦于提升EPA的计算效率,并探索专门针对能量模型的优化技巧,进一步释放其潜力。
结语:从理论缺陷到更优解
本研究不仅深刻揭示了广泛应用的Bradley-Terry模型在LLM偏好对齐中的理论缺陷,更重要的是,提出了基于能量的无限偏好模型(IPM)及其高效实现方案EPA。坚实的理论保证(MLE唯一性、斜率-1线性性)和全面的实验验证(奖励更真、效果更优、训练更稳)共同表明,EBM为LLM的离线偏好对齐提供了一条更可靠、更优越的技术路径。这一进展有望推动RLHF技术发展,为构建行为更可控、输出更安全的新一代AI系统奠定更坚实的基础。