
随着以GPT为代表的大模型在近年来取得的巨大成功,深度神经网络+SGD+scaling的机器学习范式再次证明了其在AI领域的主导地位。为什么基于深度神经网络的范式能够取得成功?比较普遍的观点是:神经网络具有从海量的高维输入数据中自动学习抽象而可泛化的特征的能力。遗憾的是,受限于当前分析手段和数学工具的不足,目前我们对于“(深度)神经网络如何实现这样的特征学习过程”这一问题的理解仍然很不深刻。也正因如此,目前学界的相关研究大多还停留在“解释”模型已经学到的特征的层面,而很难通过对于其学习过程的“干预”来得到更加数据高效、泛化性更强的模型。
当我们讨论神经网络的特征学习过程时,一个最基本的问题是:神经网络会从输入数据中学到什么特征?从目标上看,神经网络的特征学习是任务驱动下的“副产品”,其目的就是为了最小化训练误差。因此我们会直观地想,神经网络应该从数据中提取“任务相关”的特征,而剩余的“任务无关”的特征则相当于数据噪声。那么,由于神经网络自带“非必要不学习”(更准确地说是simplicity bias)的特点,神经网络就应当倾向于不对它们进行学习。这也是目前文献中比较普遍的观点。
然而,在我们最近的一篇被ICML 2024接收的工作中,我们发现这样的直观认知实际上是错误的!具体而言,我们发现非线性神经网络在学习任务相关的特征时还会同时有学习任务不相关特征的倾向(我们称之为"特征污染"),并且这种倾向会导致神经网络难以泛化至具有分布偏移(distribution shift)的场景。理论上,我们证明了特征污染即使在简单的两层ReLU网络中都会出现,并且和神经网络中神经元激活的类别不对称性息息相关;实验上,我们也给出了一系列证据表明特征污染在ResNet、Vision transformer等深层网络中也同样存在,并且会对其泛化性产生不利影响。
值得一提的是,我们发现的这种failure mode和当前分布外(out-of-distribution, OOD)泛化文献中主流的基于虚假相关性(spurious correlations)的分析是完全正交的。因此,从更大的角度看,我们的发现侧面表明了神经网络自身的归纳偏置(inductive bias)对于OOD泛化的重要性,同时也表明:我们关于神经网络特征学习和泛化的很多已有直觉可能也都需要被重新思考。
接下来,我们介绍一下文章的具体内容:
研究背景
在数据分布发生变化的场景中的泛化能力(也即OOD泛化能力)是衡量机器学习系统能否在现实环境中部署的关键指标之一。然而,当前的神经网络在OOD泛化场景中经常会遭遇显著的性能损失。关于OOD泛化失败的原因,文献中比较主流的说法是表征中存在的虚假相关性(spurious correlations),也即模型会学习到与任务目标相关但无因果关系的特征。于是,当这些特征和任务目标之间的相关性由于分布偏移而发生变化时,依赖于这些特征进行预测的模型就无法保证原有性能。
以上这个理论解释相当直观且自然,也成为了指导近年OOD算法研究的主线,即通过设计更好的优化目标函数和正则项来使得模型学习到更好的、没有虚假相关性的表征,以期得到更强的泛化性能。近年来,已经有大量工作沿着这条主线试图通过算法设计来提升模型的OOD泛化性。然而,近来的工作表明很多自带理论保障的算法在基于真实数据的OOD泛化任务上的性能提升却非常有限。
为什么会出现这样的情况?我们认为,目前 OOD 泛化研究的困难可能来源于现有分析的两个局限性:
现有研究大部分仅考虑虚假相关性导致的failure mode;目前研究大部分局限于线性模型,而没有考虑神经网络的非线性和SGD的inductive bias,因而已有的分析结果也未必适用于我们实际使用的神经网络。换言之,目前对OOD泛化的解释和理论模型可能无法准确地反映真实世界的分布偏移场景。因此我们认为,考虑神经网络和SGD的inductive bias对于理解基于深度神经网络的OOD泛化是十分必要的。
实验
首先,我们尝试通过实验设计对当前基于表征学习目标设计的OOD泛化算法所能取得的“性能上界”进行预估。现有工作在虚假相关性理论的引导下,主要尝试通过设计辅助的表征学习目标函数来约束模型学习到可OOD泛化的表征。为了研究优化这样的目标是否能真正提取到期望的表征,我们设计了一个理想化的场景:
首先,在训练过程中,我们允许模型显式拟合一个可OOD泛化的teacher model所提取出的表征,也即表征蒸馏。实验中,这个teacher model可以是一个大规模预训练模型(如CLIP)。为了控制变量,在实际操作时我们控制待训练模型(student model)和teacher model的模型结构完全一样。第二步,我们在训练集上分别基于teacher model和student model所提供的表征训练线性分类器(linear probing)。、最后,我们在同分布测试集和OOD测试集上分别对基于teacher model和student model的线性分类器进行测试,从而度量这两个模型所提取的表征的OOD泛化性。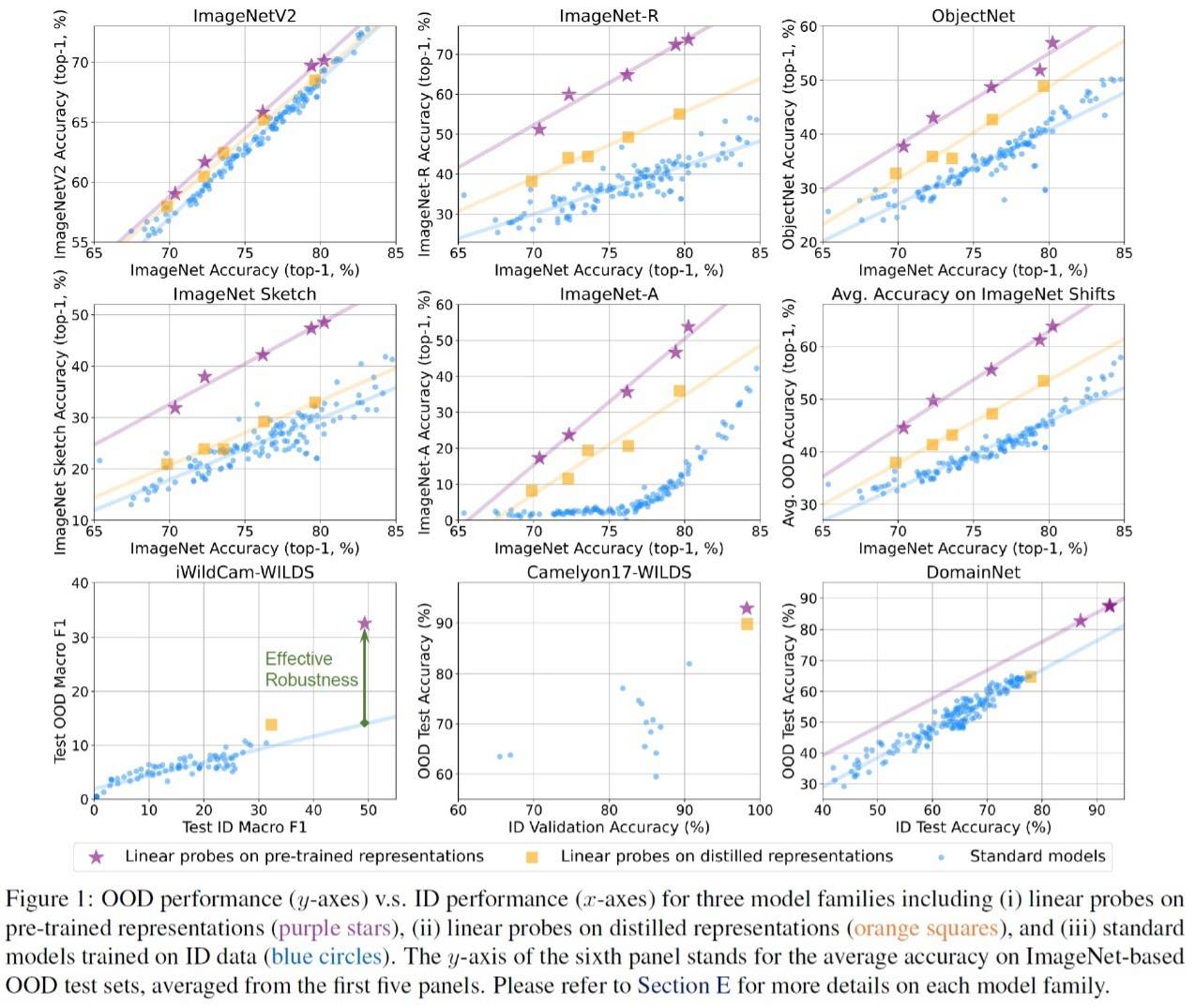
实验结果如上图所示。从图中我们有两个主要发现:
与训练过程中没有直接拟合teacher model表征的标准模型(蓝色)相比,基于student model的线性分类器(橙色)确实有更好的OOD泛化性;然而,基于student model的线性分类器(橙色)的OOD泛化性能仍然明显落后于基于teacher model的线性分类器(紫色)。于是我们自然会问:既然都已经直接拟合了teacher model的表征,那student model和teacher model之间的泛化性gap从何而来?我们发现其实目前已有的理论解释是很难直接解释这个实验现象的:
首先,这个gap不能直接被虚假相关性理论解释:既然student model和teacher model的表征(在训练集上)基本一样,那么基于这两种表征的线性分类器在训练过程中受到虚假相关性特征的影响也应该是类似的,而不应该出现这么大的gap;另一个可能的解释是teacher model(如CLIP)在它自己的预训练过程中可能已经“见过”许多OOD样本了,所以可以针对OOD样本提取一些在训练集上没有的特征。然而最近有研究表明即使从CLIP的预训练数据中把所有和OOD测试样本相似的样本都去掉CLIP仍然有很强的OOD泛化性[1]。这说明单纯从这个角度来解释teacher model和student model之间的gap也是不充分的。简言之,我们认为现有的分析不足以解释我们在实验中实际观测到的OOD泛化能力gap。同时,既然“直接拟合可OOD泛化的表征”都不能保证得到可以OOD泛化的模型,那么我们也就不得不在考虑表征学习的“目标”之外同时考虑表征学习的“过程”,也就是神经网络的特征学习动力学带来的inductive bias。尽管从理论上直接分析深层神经网络的特征学习过程是十分困难的,但我们发现,即使是两层ReLU网络也会表现出很有趣的特征学习倾向,也即“特征污染”,而这一倾向又和神经网络的OOD泛化有着直接的联系。
理论
本节,我们在一个基于两层ReLU网络的二分类问题上证明了“特征污染”现象的存在性,并且分析了这种现象的来源。具体而言,我们假定网络的输入由两种特征线性组合而成:“核心特征”和“背景特征”。其中,核心特征的分布取决于类别标签(可以形象理解为图像分类问题中的待分类物体),而背景特征的分布和标签无关(可以形象理解为图像分类问题中的图片背景等其他要素)。为了排除其他因素的干扰,我们还对这两类特征作如下假设:
背景特征和标签不相关(这样我们就排除了由虚假相关性导致的failure mode)。通过核心特征可以对标签实现100%准确率的预测(这样我们就排除了由于训练集的特征不够导致的failure mode)。核心特征和背景特征分布在正交的子空间中(这样我们就排除由于不同特征难以解耦导致的failure mode)。我们发现,即使在以上的条件下,神经网络仍然会在学习核心特征的同时学习和任务完全不相关的背景特征。由于这两种特征在网络权重空间的耦合,在背景特征上发生的分布偏移也会导致神经网络的误差增大,从而降低网络的OOD泛化性。我们也因此把这种神经网络的特征学习偏好称之为“特征污染”。以下,我们详细介绍特征污染现象的出现原因。整体分析思路的示意图如下:
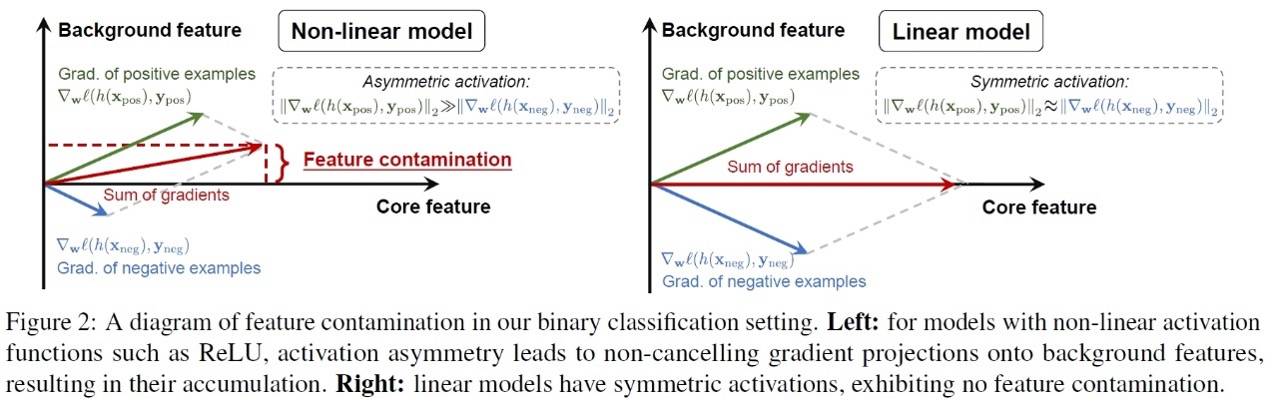
我们分析中的关键点在于:特征污染实际上和神经网络中的神经元往往对不同类别具有不对称激活(asymmetric activation)有关。具体而言,我们可以证明在经过足够的SGD迭代后,网络中至少有相当一部分的神经元都会被倾向于而与一个类别的样本保持正相关(我们称之为该神经元的正样本,并用ypos表示其类别),而与另外一个类别的样本保持负相关(我们称之为该神经元的负样本,并用yneg表示其类别)。这就会导致这些神经元的激活具有类别不对称性,如定理4.1所示:

这样的类别不对称性是怎么影响神经网络的特征学习过程的呢?我们首先注意到,对于网络隐层的第k个神经元,其权重向量wk在第t次迭代后可以被拆分为:
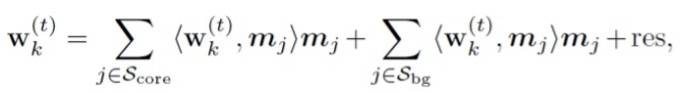
上式中,Score和Sbg分别表示核心特征和背景特征的集合,其中每个mj都对应一个核心特征或者背景特征。从该式中我们可以看出,神经元的权重可以分解为其在不同特征上的投影(这里我们假设不同的mj之间都是正交的单位向量)。进一步地,我们可以证明在wk的负梯度在每一个背景特征mj,j属于Sbg上的投影满足:
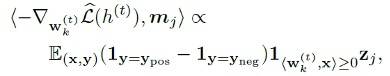
对于具有类别不对称激活的神经元,根据定理4.1我们可得其梯度主要取决于该神经元的正样本y=ypos而和负样本y=yneg几乎无关。这就导致正样本中存在的核心特征和背景特征会同时得到正的梯度投影,而这一过程和特征与标签之间的相关性无关。
如定理4.2所示,我们证明了在经过足够的SGD迭代后,上面这种梯度投影的积累将导致神经元学习到的特征既包含核心特征,也包含耦合的背景特征:

由于核心特征和背景特征在神经元权重中的耦合,背景特征的负向分布偏移会降低神经元的激活,导致额外的 OOD 误差。如定理4.3所示,我们定量描述了特征污染对 ID 和 OOD 泛化风险的影响:

同时,为了进一步说明特征污染源自神经网络的非线性激活函数之间的关系,我们证明了在去除掉神经网络的非线性后,特征污染将不再发生:

如下图所示,我们通过数值实验验证了我们的理论结果。同时,在两层ReLU网络+ SGD之外,我们也把我们的结论扩展到了更一般的设定上,包括其他种类的激活函数、具有自适应步长的优化器等,结果如图3(d)所示,表明特征污染在更一般的设置上也普遍存在。
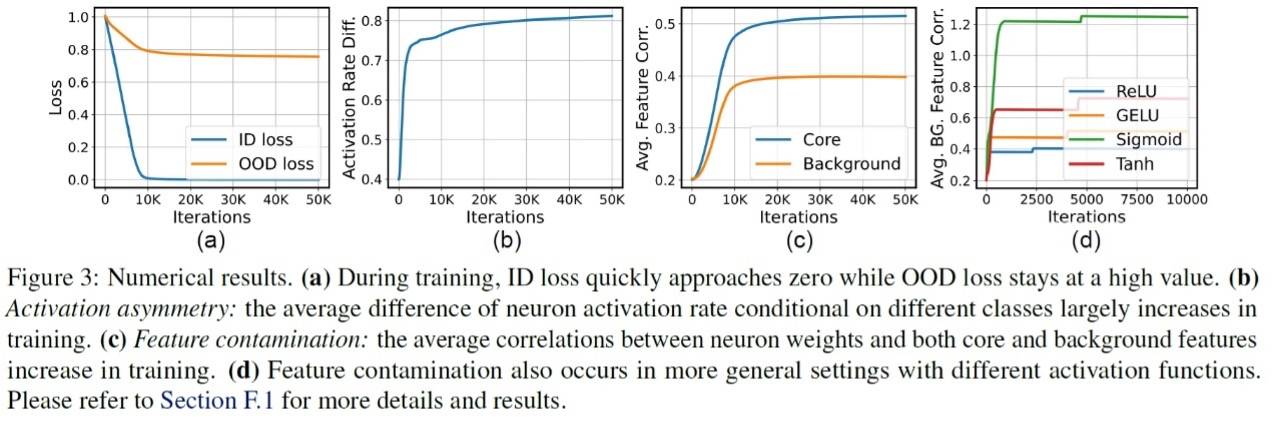
同时,我们也提供了更多的实验证据和特征可视化表明在我们日常使用的ResNet、Vision transformer等深度网络中,特征污染现象同样会出现,并且能够解释我们实验中观测到的OOD泛化gap。对这一部分内容感兴趣的大家可以参考我们原论文的第5章。
总结与讨论
最后,我们列举一些未来可能比较重要/可以继续深入做下去的研究点,也欢迎感兴趣的大家和我们进一步交流:
更深层的网络:虽然我们从实验上证明了深层网络也存在特征污染问题,但目前我们的理论分析还只做了两层的ReLU网络。我们猜想特征污染可能是一个比较general的概念,并且神经元对于类别的激活不对称性可能只是其发生的原因之一。通过分析更加深层的网络或者更加复杂的网络结构(例如引入归一化层等),我们或许可以发掘出引发特征污染的更多原因,并给出针对性的解决思路。预训练的作用:本文的理论分析只考虑了train from scratch的情况,但是我们实际使用的模型往往是预训练模型。目前已有很多实验证据表明预训练是有助于提升模型的OOD泛化性的,那么这种泛化性的提升的本质是否和缓解特征污染问题有关?预训练又是如何做到这一点的?怎么解决特征污染问题:我们的工作虽然指出了特征污染问题,但还没有给出比较明确的解决方案。不过,我们之后的一些工作已经表明,类似的问题在fine-tuning大模型的时候也会出现,并且我们也发现一些基于梯度调整的手段确实能够缓解这个问题,从而显著提升fine-tuning后的模型的泛化能力。关于这部分工作的具体内容我们未来也会放出,欢迎大家持续关注。作者简介 | 本文作者章天任,清华大学自动化系博士研究生,本科毕业于清华大学自动化系,导师为陈峰教授。作者在博士期间主要围绕表征学习和机器学习中的泛化问题展开理论和算法研究,已有多篇文章发表在机器学习顶会和顶刊,例如 ICML、NeurIPS、ICLR、IEEE TPAMI 等。
作者单位 | 清华大学 VIPLAB
联系邮箱 | [email protected]
参考文献
[1] Mayilvahanan, P., Wiedemer, T., Rusak, E., Bethge, M., and Brendel, W. Does CLIP's generalization performance mainly stem from high train-test similarity? In International Conference on Learning Representations, 2024.


