项目主页:https://hyperplane-lab.github.io/vat-mart/
01 研究背景
未来的家庭助理机器人,需要具备感知和操作人类环境中大规模多样性 3D 物体的能力。在 3D 物体中,3D 铰接物体包含具有重要的功能和语义信息的铰接部件(例如,橱柜的门和抽屉),人类和家庭助理机器人经常与它们进行交互,因此值得我们的关注。然而,与只有6个自由度(DoF)的普通刚性物体相比,铰接物体具有更高的自由度,更难以被机器人理解和交互。
先前的工作,大多数使用估计 3D 铰接物体的关节、部件姿态、动力学模型等的方法来理解和操作 3D 铰接物体。在这篇论文里,我们通过预测目标物体铰接部件上每个点的可操作性分数,以及提出每个点上完成目标任务的多样性轨迹,提出了一种新型的可操作性视觉表示(图1)。这样的视觉可操作性表示,可以泛化到不同形状的物体上,且和操作物体的机器人型号无关。为了获得这种视觉可操作性先验表示,我们设计了一个通过交互进行感知学习的框架 VAT-Mart。
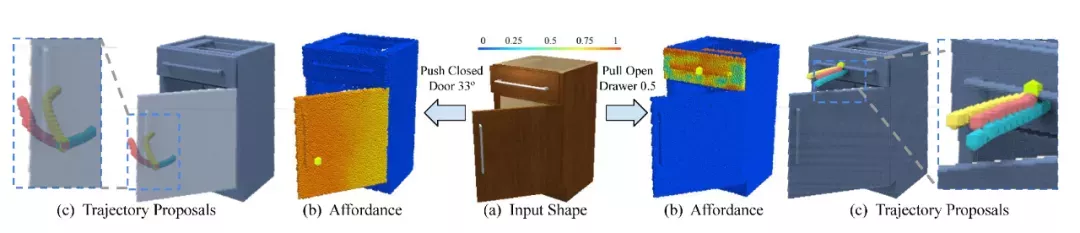
图1. 输入一个3D铰接物体,我们的方法输出了每个点的可操作性分数,以及多样的操作轨迹
02 方 法
我们提出的 VAT-Mart 框架(图2),由两个模块构成:基于强化学习的交互式操作轨迹探索模块,以及视觉可操作性感知模块。轨迹探索模块为感知模块提出可操作性和多样的操作轨迹数据,感知模块从轨迹探索模块的数据中整合可操作性和操作轨迹信息,并且利用好奇心机制,为轨迹探索模块的轨迹多样性提供指导。
具体而言,交互式操作轨迹探索模块,使用基于目标物体状态的强化学习方法,生成不同物体、不同铰接部件上可以完成不同任务的轨迹以及交互点的可操作性。为了收集多样性的轨迹,操作轨迹探索模块使用的强化学习方法的奖励由两部分构成:轨迹是否可以完成任务的外部奖励,以及感知模块提供的、当前轨迹是否新颖多样的内部奖励。感知模块由可操作性预测模块、轨迹提出模块、轨迹打分模块这三个子模块构成,它们分别预测每个点的可操作性、提出多样化的可以完成指定任务的轨迹、预测轨迹是否可以完成指定任务。轨迹打分模块的输出,同时会被作为内部奖励,激励轨迹探索模块以探索多样性的轨迹。
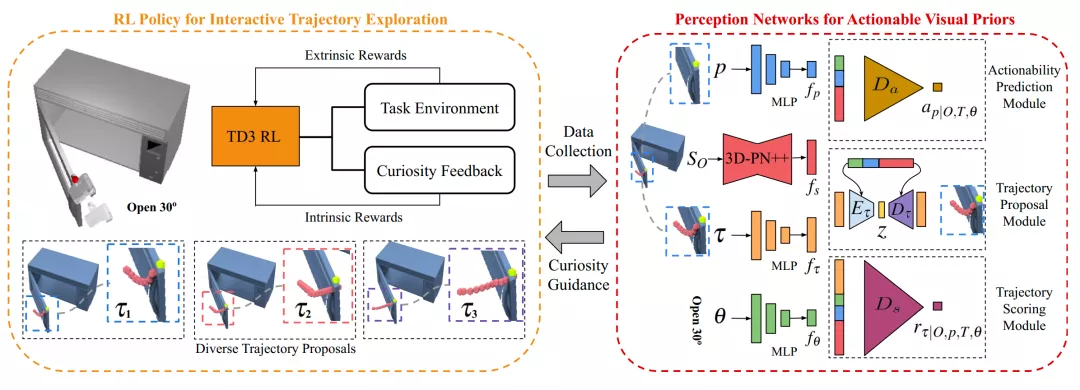
图2. 框架结构
03 实 验
我们使用 SAPIEN 模拟器,在大规模 PartNet-Mobility 数据集上进行实验。我们选取了2类常见的关节类型:门(旋转)和抽屉(平移),选取开关门或抽屉作为4类任务,选取了7类物体,对于每个任务,我们把物体分为训练类别(train-cat)和在训练中没有出现的新类别(test-cat)。对于每个任务,我们的框架预测出物体上每个点的可操作性分数,以及提出多样的操作轨迹(图3)。
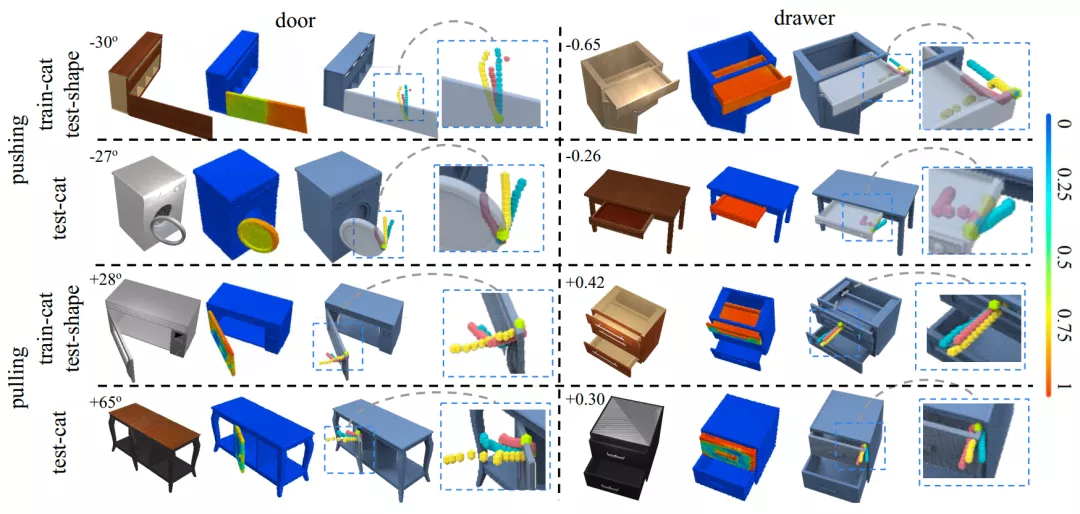
图3. 在不同任务和不同物体上,每个点的可操作性分数,以及多样的操作轨迹
进一步地,我们在真实世界扫描的 3D 物体(Google Scan, RBO, Our Scan)上进行了实验(图4的左半部分),并且使用 franka panda 机械臂进行了真机实验(图4的右半部分)。
在大规模数据集和真实世界数据、真机上,我们的方法展现能够高效地预测可操作性和提出动作轨迹,并且在新环境、新类别物体上展现出了不错的泛化能力。
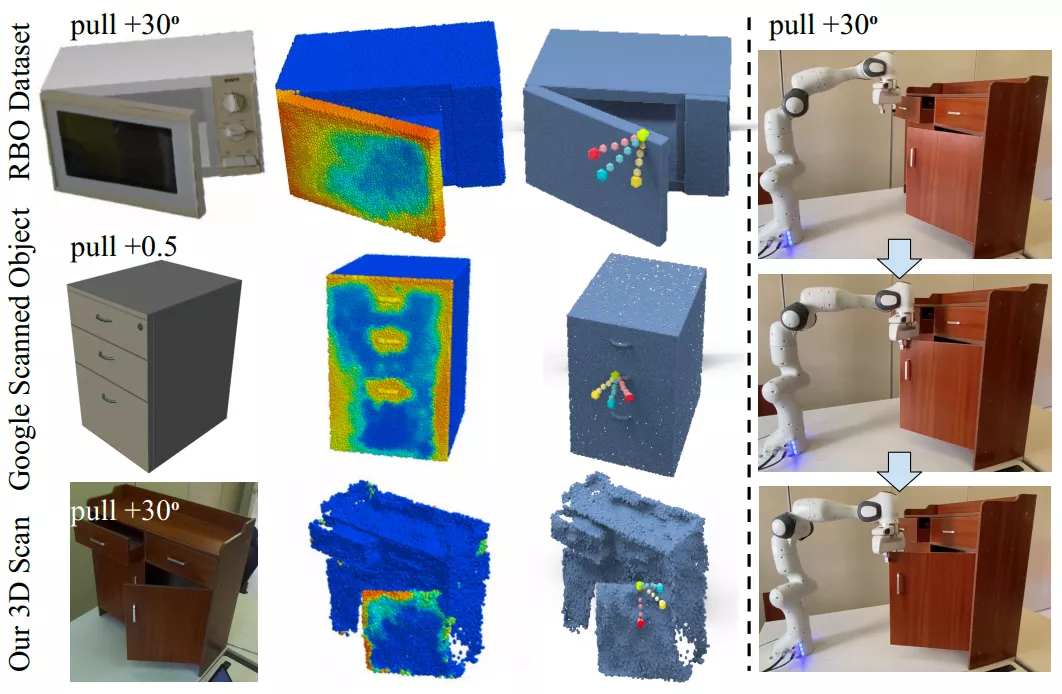
图4. 在真实世界数据上(左),以及真机实验(右)的效果
04 总 结
在这篇论文中,为了感知和操作 3D 铰接物体,我们提出了一个新颖的可泛化的视觉可操作性表示,并且设计了 VAT-Mart 框架,预测目标物体铰接部件上每个点的可操作性,以及提出可以完成目标任务的多样性操作轨迹。在大规模 PartNet-Mobility 数据集和真实世界数据、真实机械臂上的实验,证明了我们提出的框架的高效性。
图文 | 吴睿海
PKU Hyperplane Lab