超长序列推理时的巨大开销如何降低?
中国科学院自动化所李国齐、徐波团队发布的类脑脉冲大模型SpikingBrain (瞬悉)-1.0提出了新思路。
SpikingBrain借鉴大脑信息处理机制,具有线性/近线性复杂度,在超长序列上具有显著速度优势。
在GPU上1M长度下TTFT 速度相比主流大模型提升26.5x,4M长度下保守估计速度提升超过100x;在手机CPU端64k-128k-256k长度下较Llama3.2的同规模模型Decoding速度提升4.04x-7.52x-15.39x。
SpikingBrain适配了面向沐曦MetaX国产GPU集群的高效训练和推理框架、Triton算子库、模型并行策略以及集群通信原语,表明了构建国产自主可控的新型非Transformer大模型架构生态的可行性。

为什么类脑计算有望解决这一难题?
现有的主流大模型基于简单的神经元和复杂的网络架构,在Scaling law驱动下取得了巨大成功。
中国科学院团队在前期的工作中证明,具有复杂内生动态的脉冲神经元可以在数学上等价为若干简单脉冲神经元的组合。
这说明了存在使用由复杂神经元组成的小规模网络代替由简单神经元组成的大规模网络的可能性。
受此启发,一条“基于内生复杂性”的通用智能实现思路被提出,即找到一条融合神经元内部丰富动力学特性的类脑模型发展路径。
SpikingBrain-1.0就是这一思路下的初步尝试。
大模型时代的新视角
人脑是目前唯一已知的通用智能系统,包含约1000亿神经元和约1000万亿突触数量、具有丰富的神经元种类、不同神经元又具有丰富的内部结构,但功耗仅20W左右。
现有大模型通常基于Transformer架构,增加网络规模、算力资源和数据量提升智能水平,但二次方复杂度使其训练和推理开销巨大,超长序列处理能力受限。例如,当前国内外主流大模型仅支持64k或128k长度的序列训练,支持1M以下长度推理。
其基本计算单元为点神经元模型:简单乘加单元后接非线性函数,这条简单神经元加网络规模拓展的技术路径可以被称为“基于外生复杂性”的通用智能实现方法。
相比之下, “基于内生复杂性”的通用智能实现方法的目标是,充分利用生物神经网络在神经元和神经环路上的结构和功能特性,找到构建具有生物合理性和计算高效性的神经网络新路径。
因此,探索脑科学与人工智能基础模型架构之间的桥梁、构建新一代非Transformer的类脑基础模型架构,或将引领下一代人工智能的发展方向、为实现国产自主可控类脑大模型生态提供基础积累。
核心技术
SpikingBrain-1.0基于脉冲神经元构建了线性(混合)模型架构,具有线性(SpikingBrain-7B)及近线性复杂度(SpikingBrain-76B,激活参数量12B)的类脑基础模型(图1)。
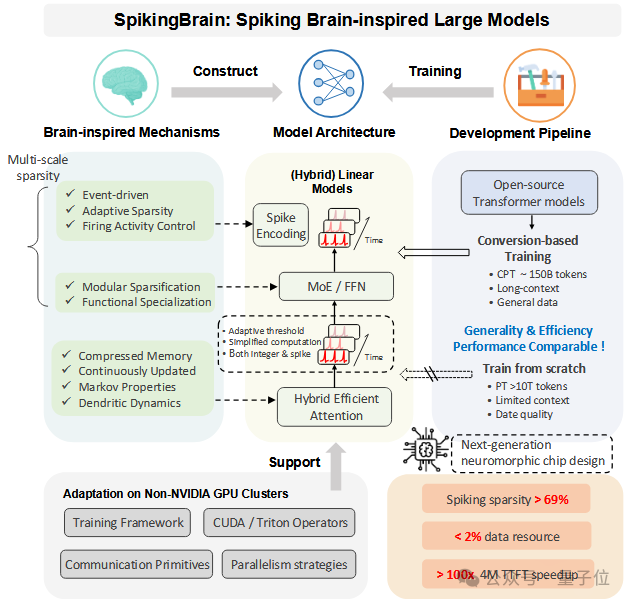
△图1. SpikingBrain框架概览
为解决脉冲编码时的性能退化问题,构建了自适应阈值神经元模型,模拟生物神经元脉冲发放的核心过程,随后通过虚拟时间步策略实现“电位-脉冲”的转换,将整数脉冲计数重新展开为稀疏脉冲序列。
借助动态阈值脉冲化信息编码方案,可以将模型中计算量占比90%以上的稠密连续值矩阵乘法,替换为支持事件驱动的脉冲化算子,以实现高性能与低能耗二者兼顾:脉冲神经元仅在膜电势累积达到阈值时发放脉冲事件,脉冲到达时触发下游神经元活动,无脉冲时则可处于低能耗静息状态。
进一步,网络层面的MoE架构结合神经元层面的稀疏事件驱动计算,可提供微观-宏观层面的稀疏化方案,体现按需计算的高效算力分配。
该团队在理论上建立了脉冲神经元内生动力学与线性注意力模型之间的联系,揭示了现有线性注意力机制是树突计算的特殊简化形式,从而清晰地展示了一条不断提升模型复杂度和性能的新型可行路径。
基于这一理解以及团队前期工作,团队构建了与现有大模型兼容的通用模型转换技术和高效训练范式,可以将标准的自注意力机制转换为低秩的线性注意力模型,并适配了所提出的脉冲化编码框架。
此外,为实现国产算力集群对类脑脉冲大模型的全流程训练和推理支持,团队开发了面向沐曦MetaX国产GPU集群的高效训练和推理框架、Triton算子库、模型并行策略以及集群通信原语。
SpikingBrain-7B 和SpikingBrain-76B分别为层间混合纯线性模型和层内混合的混合线性 MoE 模型(图2)。
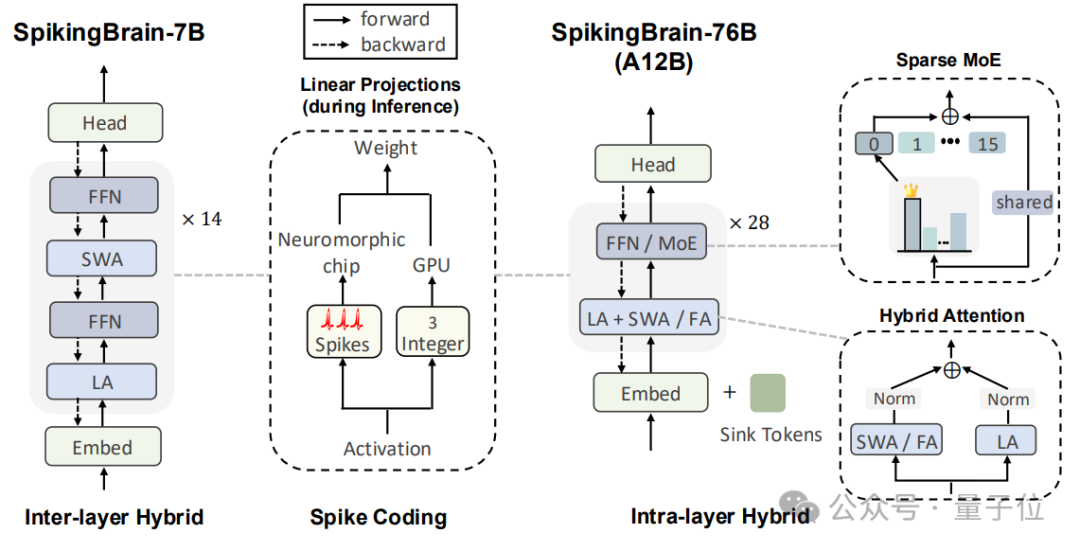
△图2. SpikingBrain网络架构
其中SpikingBrain-7B由线性注意力和滑窗注意力1:1层间堆叠而成。
而SpikingBrain-76B则包含128个sink token、16个路由专家以及1个共享专家;对于线性层,在第[1, 2, 3, 5, 7, 9, 11] 层布置了7个稠密 FFN,其余层均实现为MoE层;对于注意力模块在第[7, 14, 21, 28]层采用线性注意力+Softmax注意力(LA+FA)组合,在其他层均采用线性注意力+滑窗注意力(LA+SWA)组合。
在推理阶段,SpikingBrain利用脉冲编码将激活值转换为整数计数用于GPU执行,或转换为脉冲序列用于事件驱动的神经形态硬件。
性能亮点
SpikingBrain1.0的长序列训练效率显著提升。SpikingBrain-1.0-7B模型能以极低的数据量(约为主流大模型的2%),实现与众多开源Transformer模型相媲美的通用语言建模性能(表1)。
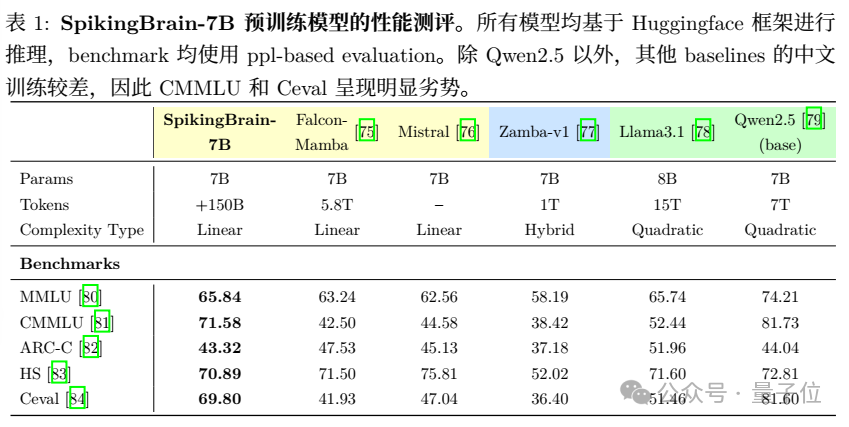
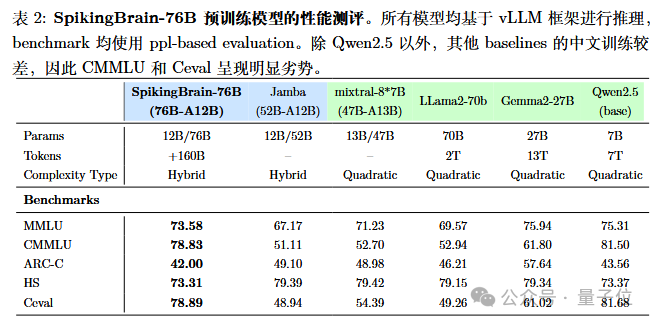
SpikingBrain-1.0-76B混合线形模型通过扩展更多的参数量和更精细的注意力设计,基本保持了基座模型的性能,能使用更少的激活参数接近甚至优于Llama2-70B、Mixtral-8*7B、Gemma2-27B等先进的Transformer模型(表2)。
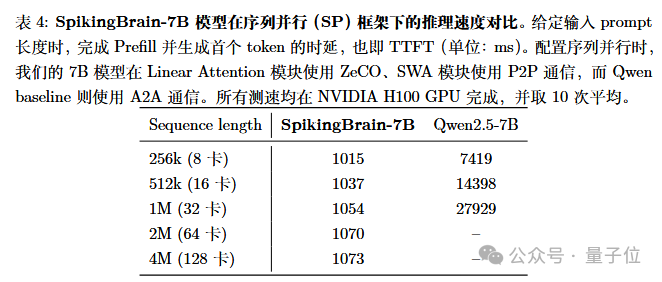
SpikingBrain-1.0-7B模型在Huggingface框架下适配了多卡序列并行推理(使用ZeCO加上P2P通信),并支持4M长度的Prefill。结果显示,相比于使用标准注意力和A2A通信的Qwen baseline,SpikingTime-1.0-7B在512K和1M长度下TTFT(提交提示到生成第一个Token所需的时间)加速分别达到13.88倍和26.5倍,且随序列长度和卡数扩展具有几乎恒定的时间开销,在4M长度下Qwen baseline已经难以评测,根据拟合scaling曲线,保守估计速度提升超过100倍(表4)。
团队将压缩到1B的SpikingBrain-1.0部署到CPU手机端推理框架上,在64k-128k-256k长度下较Llama3.2的1B模型Decoding速度分别提升4.04x-7.52x-15.39x。
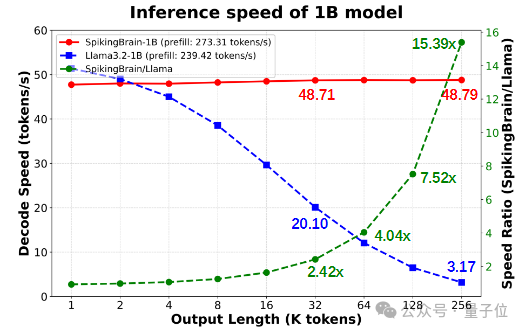
图3 基于CPU移动推理框架下,不同输出长度的解码速度比较
为了在国产曦云C550算力集群上进行训练/推理适配,团队对训练框架(Megatron、Colossal-AI)进行Triton算子加速和通信适配等优化,能在集群上保持百卡规模训练的数周稳定运行;在训练效率上,7B模型进行8k长度训练的MFU达到23.4%,TGS per GPU达到1558 tokens/s(Megatron框架、DP rank为8,PP rank为4,PP-micro batch size为2,global batch size为512)。
对话Demo和网络试用端口:团队提供了SpikingBrain-1.0-76B模型的网络端的试用端口供大家体验,该模型基于vLLM推理框架部署在沐曦MetaX GPU集群上,可以支持数百人的并发请求。为支持类脑研究生态的构建,团队开源了SpikingBrain-1.0-7B模型(详见技术报告)。
总结
本次发布的国产自主可控类脑脉冲大模型探索了脉冲神经元内生复杂神经动力学与线性注意力模型之间的机制联系,设计了线性模型架构和基于转换的异构模型架构,通过动态阈值脉冲化解决了脉冲驱动限制下的大规模类脑模型性能退化问题,实现了国产GPU算力集群对类脑脉冲大模型训练和推理的全流程支持。
超长序列的建模在复杂多智能体模拟、DNA序列分析、分子动力学轨迹等超长序列科学任务建模场景中将具有显著的潜在效率优势。未来该团队将进一步探索神经元内生复杂动态与人工智能基础算子之间的机制联系,构建神经科学和人工智能之间的桥梁,期望通过整合生物学见解来突破现有人工智能瓶颈,进而实现低功耗、高性能、支持超长上下文窗口的类脑通用智能计算模型,启迪更低功耗的下一代神经形态计算理论和芯片设计。
网络端试用端口网址:https://controller-fold-injuries-thick.trycloudflare.com
中文技术报告网址:https://github.com/BICLab/SpikingBrain-7B/blob/main/SpikingBrain_Report_Chi.pdf
英文技术报告网址:https://arxiv.org/abs/2509.05276
模型代码网址:https://github.com/BICLab/SpikingBrain-7B


