近年来,生成对抗网络和扩散模型等创新技术在图像生成领域取得了巨大突破,能够生成逼真的图像和视频内容。但这些技术通常侧重于整体图像的生成,对于需要精确控制多个视觉元素如物体、相机视角和背景的复杂合成场景支持有限。
例如,在一个包含多个物体的场景中,若要将某个物体进行替换、改变其位置或调整其外观,同时保持整个场景的自然过渡和真实感,现有技术往往难以达到理想效果。
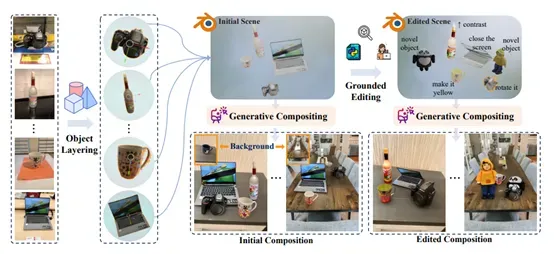
所以,谷歌发布了BlenderFusion通过整合先进的3D图形编辑工具Blender与强大的扩散模型,构建了一个能够实现3D视觉编辑和生成合成的创新框架。

BlenderFusion遵循分层、编辑、合成的流程,能将2D图像转化为可编辑的3D实体,进行精准的3D编辑操作,再将编辑后的3D场景融合为连贯的最终图像。
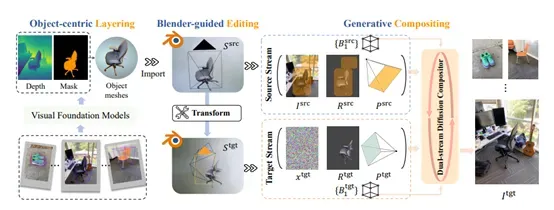
分层阶段是BlenderFusion流程的起点,其核心任务是从输入的2D图像中提取出可编辑的3D对象。研究人员借助诸如SAM2和DepthPro等前沿的视觉基础模型,实现了这一关键步骤。首先,将3D边界框投影到图像空间,获取粗略的2D边界框。随后,利用GroundingDINO模型,结合物体类别标签对这些2D边界框进行精细化调整,以更精准地定位物体在图像中的位置。基于调整后的2D边界框,SAM2模型提取出物体的掩码,同时结合DepthPro模型提供的度量深度预测,得到物体的深度信息。
通过将预测深度的尺度与每个物体的3D边界框对齐,并将调整后的物体深度图反向投影生成3D点云,进而连接相邻点形成三角网格,最终生成一系列3D实体。这些3D实体随后被导入到Blender中,为后续的编辑操作做好准备。
完成分层后,接下来进入编辑阶段,这是BlenderFusion流程的核心环节,充分发挥了Blender作为专业3D图形编辑软件的强大功能。在这一阶段,从分层阶段得到的3D实体被导入到Blender中,用户可以利用Blender提供的丰富工具和功能,对物体、相机以及背景等视觉元素进行各种精准的3D编辑操作。
对于物体的基本控制操作,包括对每个独立物体进行平移、旋转或缩放,以及物体的移除、插入或替换等。由于包含了每个物体的3D模型,这些变换操作可以自动地反映在渲染结果中,为用户提供直观且高效的编辑体验。
例如,用户可以轻松地将一个场景中的物体移动到另一个位置,或者将一个物体替换为另一个具有不同形状和纹理的物体,而无需担心物体之间的空间关系和整体场景的协调性。
在高级物体控制方面,BlenderFusion继承了Blender的强大功能,能够实现物体属性的改变、非刚性物体变换以及新物体的插入等操作。这些操作可以通过Blender的用户界面进行交互式完成,也可以通过自动脚本实现。
例如,用户可以对一个物体的表面材质进行调整,使其呈现出金属质感或透明质感;或者对一个物体的形状进行局部变形,以满足特定的设计需求。这些高级编辑功能为用户提供了极大的创作自由度,使得BlenderFusion能够应对各种复杂的视觉编辑任务。
此外,BlenderFusion还支持对相机和背景的控制。用户可以指定新的背景图像来替换原有的背景,同时通过Blender中的相机对象来模拟相机的运动。这种对相机和背景的灵活控制,使得用户能够在编辑过程中创造出各种独特的视角和场景组合,进一步丰富了视觉内容的表现力。
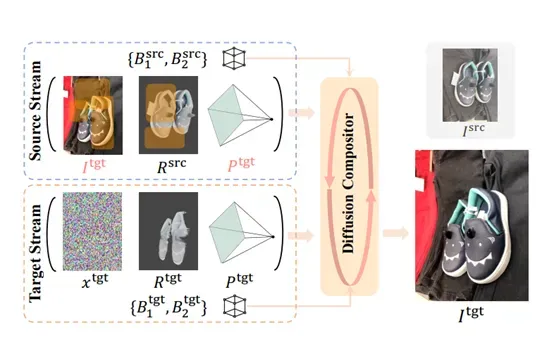
经过编辑阶段后,进入合成阶段,这是BlenderFusion流程的最后一步,其目的是将经过编辑后的3D场景与背景融合,生成最终的连贯图像。这一阶段的关键组件是生成合成器,它基于扩散模型,能够处理来自分层和编辑阶段的两路输入信息:源流和目标流。
源流包含了原始场景的图像、渲染结果、相机参数以及物体姿态。目标流则包含了编辑后的渲染结果、相机参数以及物体姿态。由于编辑过程可能会引入噪声,导致目标渲染出现瑕疵,因此生成合成器需要对这些输入进行处理,以纠正瑕疵并生成高质量的最终图像。
为了有效处理双路输入,研究人员对预训练的扩散模型进行了多项关键架构修改。首先,将模型扩展为双路架构,其中单个权重共享的去噪UNet独立处理两路输入,同时通过自注意力机制实现两路之间的交互。
其次,修改UNet的第一层,以容纳额外的条件输入,将其通道数从4增加到15,并使用零初始化权重。这15个通道中,前4个通道处理源流或目标流的VAE编码图像或噪声;接下来的5个通道处理Blender渲染(4个用于VAE编码的渲染图像,1个用于实例掩码);
最后6个通道使用Plücker嵌入编码相机参数。此外,每路输入都有独立的一组文本标记,这些标记由物体类别标签和姿态组成。标签通过CLIP进行嵌入,而3D边界框则转换为位置编码,并通过MLP进行处理。将得到的嵌入序列拼接起来,作为各自流的文本标记。


