一直以来,AI 领域的研究者都喜欢让模型去挑战那些人类热衷的经典游戏,以此来检验 AI 的「智能程度」。
例如,在 Atari 游戏、围棋(如 AlphaGo)或《星际争霸》等环境中,游戏规则明确,边界清晰,研究者可以精确控制变量(如难度、初始状态、随机性等),确保实验的可重复性。而 AlphaGo 的胜利能直接证明其策略能力,是因为游戏的胜负、得分或任务完成度也天然提供了直观的评估标准(如胜率、通关时间、得分高低),无需设计复杂的评价指标。
此前,有开发者用 AI 挑战过经典之作《神奇宝贝》。这个游戏的画风虽然简单,但是身为策略游戏,其中包含的角色、属性、战术、体系等,都让人类玩家感到「入门容易精通难」。一开始,AI 没有任何的知识和经验,只能够随机按下按钮。但在五年的模拟游戏时间里,它在经历中习得了更多能力。最终,AI 能够抓住宝可梦,进化它们,并击败了道馆馆主。
当我们以为这已经算是高难度的时候,《超级马里奥兄弟》再次刷新了大模型性能测试基准的上限。
最近,加州的一家实验室 Hao labs 推出了「GamingAgent」项目,这是一项测试 AI 性能的新方法,专为实时动作游戏而构建。
项目地址:https://github.com/lmgame-org/GamingAgent
团队采用了《超级马里奥兄弟》等平台游戏与《2048》、《俄罗斯方块》等益智游戏,作为不同 AI 模型的试验场。

GPT-4o 表现

Claude-3.7 表现
这是 Claude 3.7 在《俄罗斯方块》中的表现: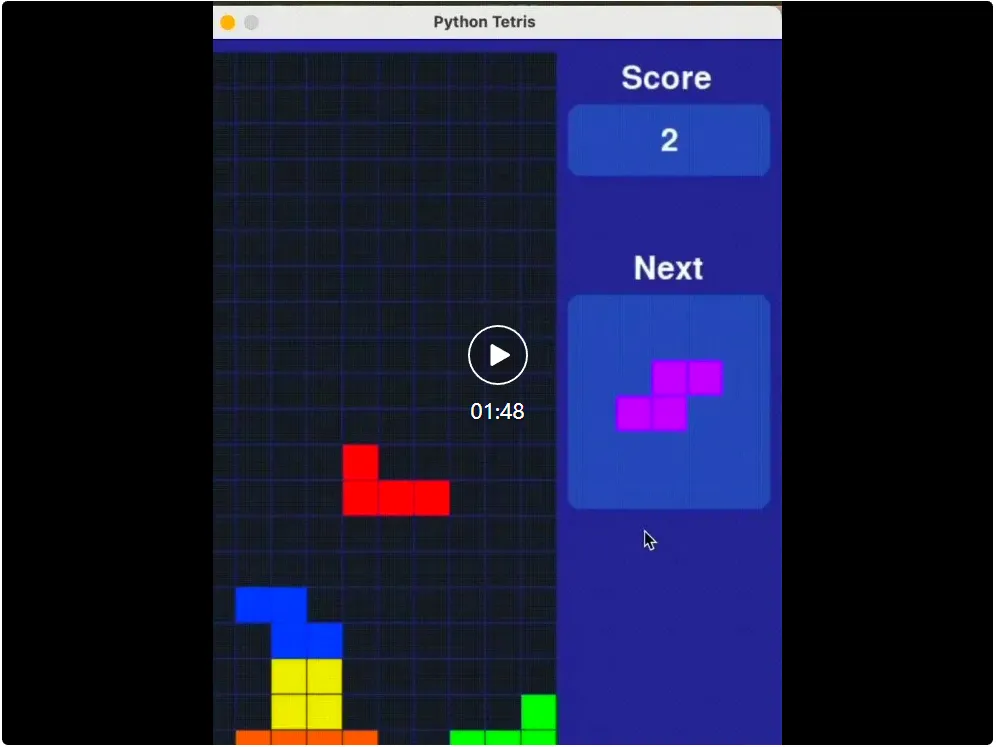
Claude 3.7 表现最好
GPT-4o 举步维艰
这次的一系列实验并不是通过 1985 年版的《超级马里奥兄弟》完成的,而是通过包含 GamingAgent 的模拟器完成的。
实验室发现,这种独特的游戏环境迫使每个模型设计复杂的操作和游戏策略,从而能够考验出它们的适应能力和解决问题的能力。
GamingAgent 模拟器为 AI 提供基本指令和游戏截图,指令类似于:「如果附近有障碍物或敌人,请向左移动 / 跳跃以躲避。」然后 AI 通过 Python 代码生成输入,从而控制马里奥。
在下图的演示中,是四个大模型挑战超级马里奥兄弟 1-1 级的结果。Anthropic 的 Claude 3.7 表现最好,其次是 Claude 3.5。遗憾的是,谷歌的 Gemini 1.5 Pro 和 OpenAI 的 GPT-4o 表现不佳。

有趣的是,尽管 OpenAI 的 GPT-4o 等推理模型在大多数基准测试中总体表现更好,但在这种实时游戏场景中的表现却不佳。这是因为推理模型的决策过程较慢,通常需要几秒钟才能确定如何行动。
另一方面,非推理模型在超级马里奥兄弟游戏中表现更佳,因为时机就是一切,可以决定成败。一秒钟也能导致安全跳过和坠落然后「Game Over」之间的差别。
使用《超级马里奥兄弟》之类的游戏来对 AI 进行基准测试并不是一个新想法。但毕竟游戏具备一些抽象性质,而且与现实世界的挑战相比来说相对简单,领域内的很多专家对其能否确定技术发展程度的价值表示担忧。
换言之,上述测试未必能说明 Claude 3.7 和 GPT-4o 哪个更强大。
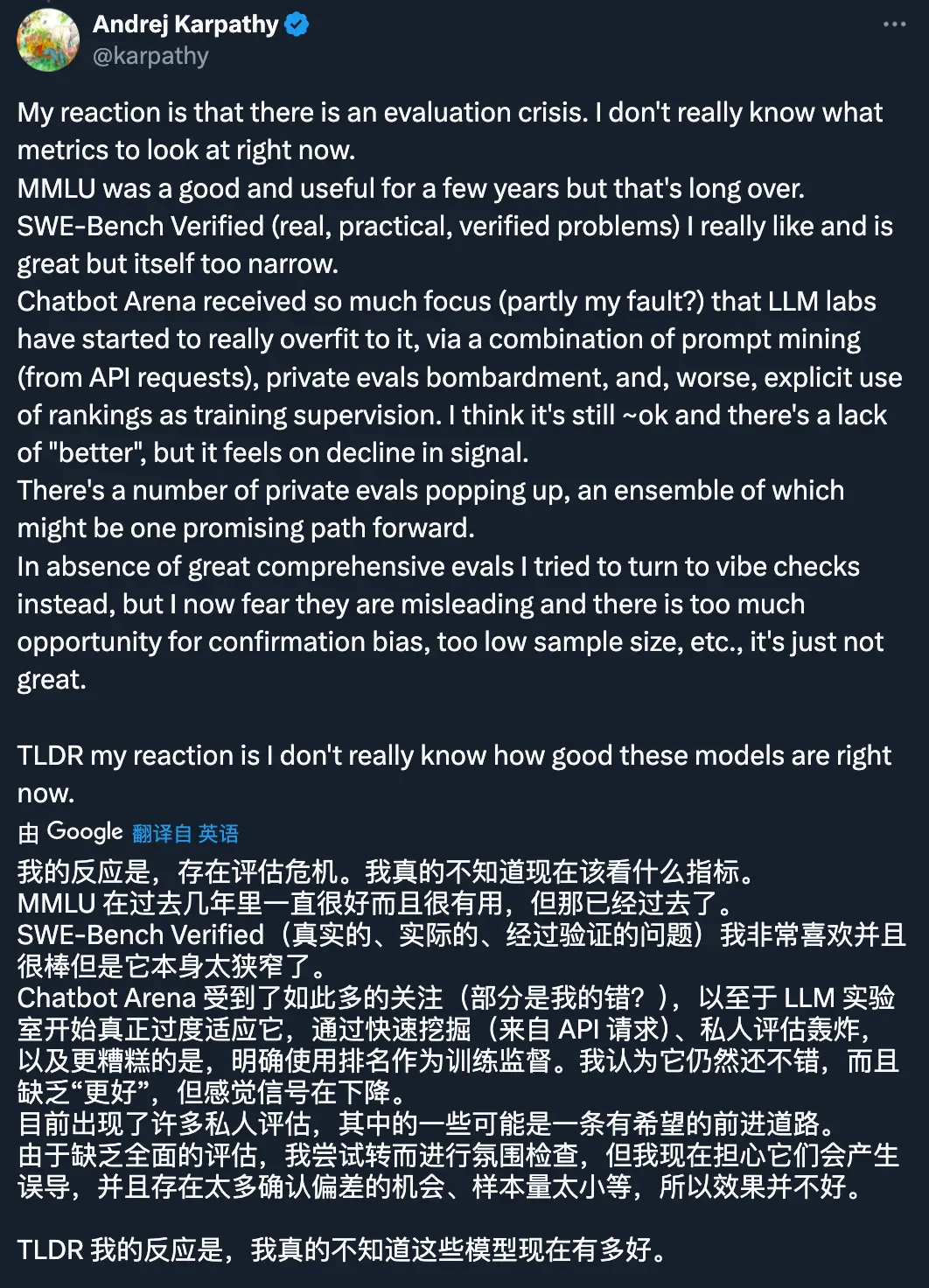
Andrej Karpathy 最近就陷入了「评估危机」:「我真不知道现在应该关注什么(AI)指标。简而言之,我的反应是,我真的不知道这些模型现在有多好。」
而对于不断推出的前沿模型来说,如何判断性能更是个难题。
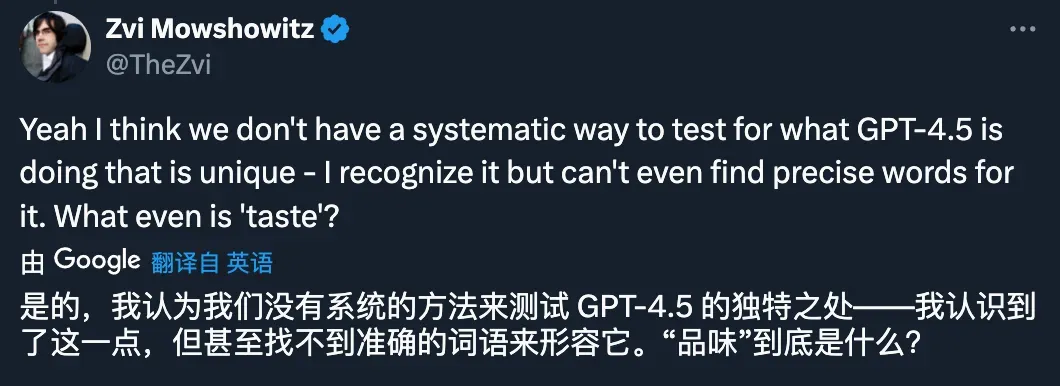
AI 的「评估危机」
我们该如何衡量大模型的性能提升?
与此同时,有业内人士从另外一个维度提出了对大模型性能提升方向的质疑。
Hugging Face 的联合创始人兼首席科学官 Thomas Wolf 周四在 X 平台发文,表达了对 AI 未来的深切忧虑。他担心在缺乏根本性研究突破的情况下,人工智能将沦为「服务器上的好好先生」。在他看来,当前的人工智能发展路径难以培养出真正具备创造性思维的系统 —— 那种能够摘取诺贝尔桂冠的突破性思考能力。

「人们常犯的错误是把牛顿或爱因斯坦简单地视为优等生的放大版,仿佛天才只是把成绩靠前的学生线性延伸出来的结果,」Wolf 写道,「在数据中心里打造一个爱因斯坦,我们需要的不是一个万事通,而是一个敢于提出前人未曾想到或不敢发问的问题的系统。」
这一观点与 OpenAI 首席执行官奥特曼(Sam Altman)的说法形成鲜明对比,后者在今年早些时候撰文称「超级智能」能「极大加速科学发现」。同样,Anthropic 公司首席执行官 Dario Amodei 也预测,AI 将助力大多数癌症的治疗方案研发。
Wolf 认为当下 AI 的问题在于:它不能通过连接原本不相关的事实来创造新知识。即使拥有互联网上的海量信息,现今的 AI 主要只是在填补人类已有知识之间的空白。
包括前谷歌工程师弗朗索瓦・乔莱(François Chollet)在内的一些人工智能专家也表达了类似的观点,他们认为 AI 虽能记忆推理模式,但难以针对全新情境产生真正的「新推理」。
Wolf 认为,AI 实验室目前打造的只是「极其听话的学生」,而非科学革命的缔造者。当今的 AI 不被鼓励质疑或提出可能与训练数据相悖的想法,这使其仅能回答已知范围内的问题。
「在数据中心里打造一个爱因斯坦,关键在于培养一个能提出前人未曾想到的问题的系统,」沃尔夫强调,「一个当所有教科书、专家和常识都持相反观点时,仍会问『如果大家都错了呢?』的系统。」
Wolf 指出,AI 领域的「评估危机」是问题的症结所在。目前评估 AI 进步的标准大多由具有明确、显而易见的「封闭式」答案的问题构成。
作为解决之道,Wolf 建议行业转向能够评估 AI 是否具备「大胆的反常规思考」、基于「微弱线索」提出普适性建议,以及提出能开辟「研究新径」的「非显而易见问题」的能力标准。
他承认,确定这种评估标准的具体形式是个难题,但认为这值得投入精力。
「科学的精髓在于提出正确问题并挑战既有知识的能力,」Wolf 总结道,「我们不需要一个靠常识拿 A+ 的学生,而需要一个能看到并质疑所有人都忽略之处的 B 等生。」
参考链接:
https://techcrunch.com/2025/03/03/people-are-using-super-mario-to-benchmark-ai-now/
https://techcrunch.com/2025/03/06/hugging-faces-chief-science-officer-worries-ai-is-becoming-yes-men-on-servers/