扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临推理速度较慢且生成逻辑不连贯等问题。
对此,华为小艺香港团队、香港城市大学及香港大学的研究人员们共同提出了一种全新的上下文一致性解码算法(Coherent Contextual Decoding, CCD),充分利用扩散过程中的上下文增广,从理论上纠正了传统 DLM 推理策略的 “短视性”,并进一步采用自适应解码方案在多种开源 DLMs 上同时实现了 3.48 倍的加速和 3.9% 的性能提升。该方案不仅适配 Any-oder 生成,且在半自回归 Block-wise 解码设定下也获得了提升,扩散语言模型的高效推理时代,或许已经到来。

论文标题:Beyond Confidence: Adaptive and Coherent Decoding for Diffusion Language Models
论文地址:https://arxiv.org/pdf/2512.02044
Github 代码:https://github.com/tonyckc/CCD-DLM-code
项目主页:https://tonyckc.github.io/CCD-DLM-Project/
研究背景
今年以来,以 Dream 和 LLaDA 为主的开源扩散语言模型大放异彩,实现了和同尺寸自回归 LLM 相当的通用能力,且展现出了 DLMs 在全局规划和双向上下文理解任务上的优势 。
然而,当前主流 DLM 推理算法存在一个致命缺陷:局部的 “过度自信”。 传统的采样策略(如基于置信度或熵的采样)通常只关注当前扩散步的预测。这种 “短视” 可能会导致 DLM 采样陷入局部最优:模型在当前步骤选了一个看似合适的词,但导致后续生成 “一步错,步步错” 。
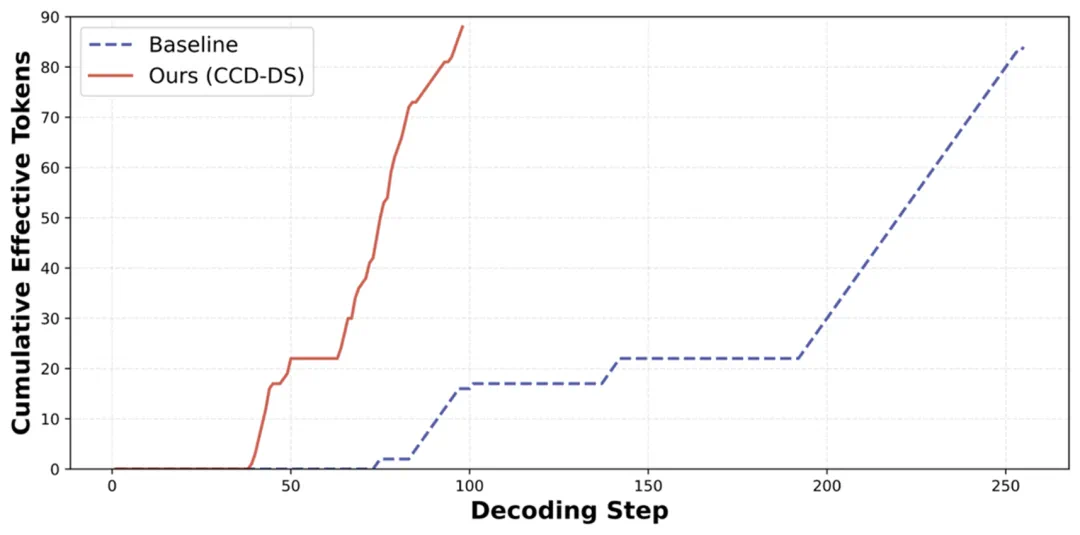
另一个问题是采样预算固化:当前大部分方案每一步解码的 Token 数量(预算)都是固定的,极大地限制了模型的灵活性。同时在解码过程中,在遭遇大量 EOS Token 组成的平原期,会大幅延缓有效 Tokens 的输出,如下图所示:
核心创新:上下文一致性解码算法 (CCD)
为了解决上述问题,研究团队提出了上下文一致性解码(CCD)。其不仅 DLM 推理算法上的一次创新,更是视角上的根本转换 —— 从关注 “单步状态” 转向追求 “轨迹连贯”。
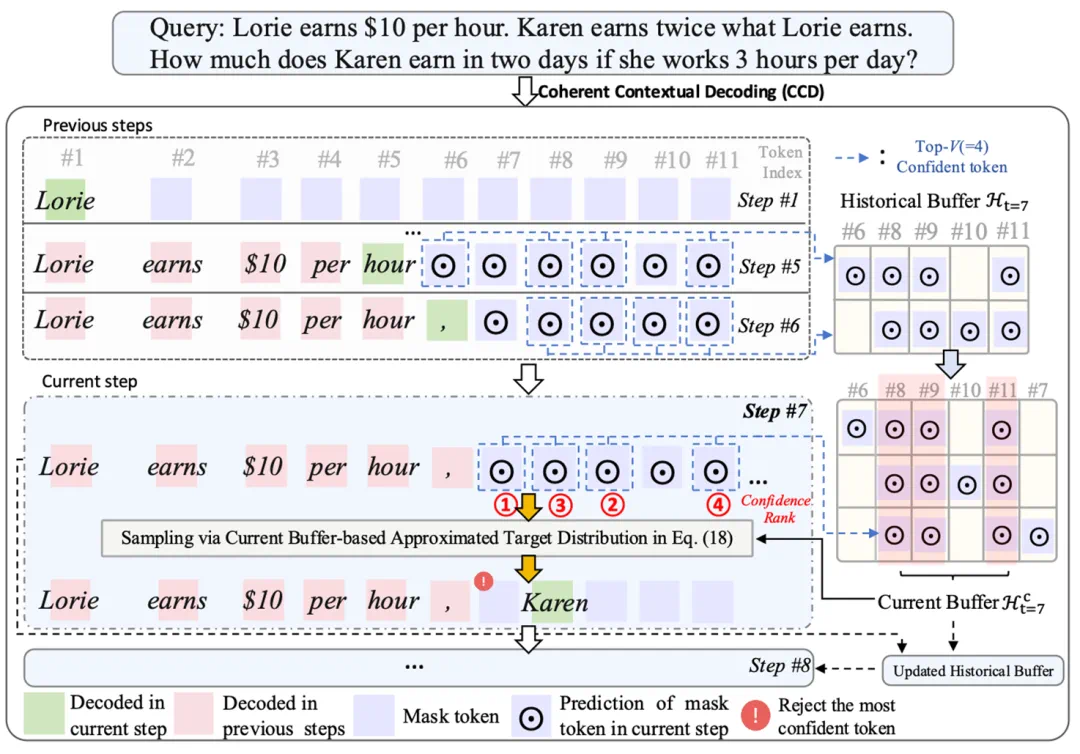
1. 引入 “历史缓冲” 机制,拒绝 “短视”
研究者们指出,DLM 单步推理预测分布中往往会包含训练过程中学习到的噪声,导致在解码时赋予高置信度到 “错误” Token 上。对此,CCD 提出:开源利用过去 N 个扩散步的预测信息来校正当前步的解码选择。
直观上:如果某个位置的 Token 在过去多次扩散步中都有着高置信度,说明它经得起上下文变化的考验,是 “真金不怕火炼” 的优质预测;反之,如果它的置信度分布忽上忽下,即便当前步的置信度高,也可能只是噪声。
理论上:研究团队进一步证明,这种利用历史信息逼近真实分布的解码方法,理论上等价于利用 Token 与上下文之间的条件互信息(Conditional Mutual Information)来建模反向扩散降噪过程中的一致性,并能直接降低采样过程中的 Error 上界。
2. 自适应采样:该快则快,该慢则慢 (CCD-DS)
传统的 DLM 推理就像定速巡航,不管路况如何都保持匀速解码(通常为 1)。研究者们进一步引入了一个滑动历史缓冲区(History Buffer),从而实现了动态调度方案(CCD-DS),在解码过程中完成了 “自动驾驶” 般的变速:
简单区域(如模板句、连词):当检测到 Buffer 中候选 Token 的一致性很高(胡信息较低)时,该算法会倾向于一次性解码多个 Token 实现加速。
困难区域(如逻辑转折、数学计算):当遇到语义模糊的 Token 时,算法会自动控制解码预算,让模型的思考慢下来,以获得高质量的输出。
这种策略打破了模型生成速度与质量的 Trade-off,充分利用模型在解码过程中的 “平台期”,极大地提升了解码效率。
实验结果:速度与质量的双重飞跃
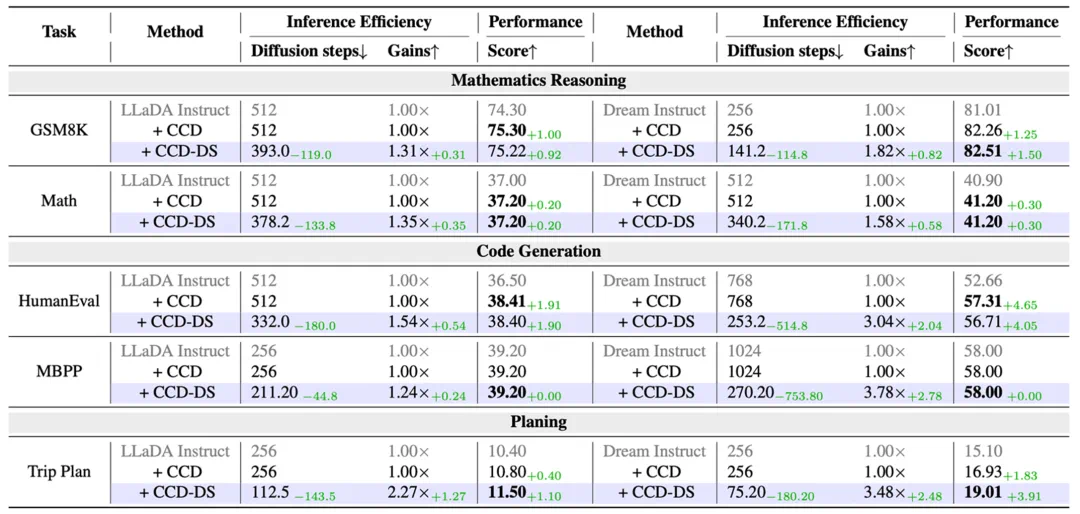
为验证算法效果,研究团队选择了 Dream-7B 和 LLaDA-8B 两个主流开源扩散语言模型,并在数学推理(GSM8K, MATH)、代码生成(HumanEval, MBPP)和规划任务(Trip Plan)进行了全面的实验测试。
推理速度与能力飙升。在自适应策略解码逻辑下(CCD-DS),模型能力获得了出了惊人的提升:
在所有的 Benchmark 评测上,相较于传统的解码算法,CCD-DS 在 Dream 和 LLaDA 上均实现了表现与速度的同步提升。
在 Trip Plan 任务上,相较于 Baseline,Dream 的推理速度提升了 3.48 倍,且表现提升 3.91%。
案例分析:为什么 CCD 有更好的效果?
论文中展示了一个经典的数学推理案例(GSM8K),生动诠释了 CCD 的优越性:

题目:Lorie 每小时赚 10 美元。Karen 赚的是 Lorie 的两倍。如果 Karen 每天工作 3 小时,两天能赚多少?
传统方案:在关键步骤,算法基于单步预测优先解码了连词 “so”,导致后续逻辑被带偏,最终得出错误答案 360。
CCD 方法:利用多步上下文的一致性,CCD “拒绝” 了语法上通顺但语义空洞的 “so”,而是优先解码了 “Karen”。这一步之差,让模型构建了正确的推理轨迹,从而得出正确答案 120。
这证明了 CCD 能够区分语法流畅性与语义重要性,在关键决策点上避免了多次单步推理带来的级联错误。
总结与展望
该工作通过上下文一致性解码(CCD),为扩散语言模型推理提供了一套理论完备且行之有效的解决方案。不仅通过引入一致性建模解决了多步采样中的问题,更通过自适应预算让 DLM 在推理效率上得到了提升。CCD 不仅打破了传统 DLMs 速度与准确率的 Trade-off,更为扩散模型在更复杂推理任务中的应用铺平了道路。
作者简介
陈柯成:论文第一作者,香港城市大学电机工程系博士生在读,由严洪教授和李皓亮教授共同指导。 目前在华为莱布尼茨研究所 - 小艺香港团队实习,研究方向为扩散语言模型。
刘子儒:项目 Leader,博士毕业于香港城市大学 DS 系,导师为赵翔宇教授与周定轩教授。目前就职于华为莱布尼茨研究所 - 小艺香港团队,主要研究方向为扩散语言模型,Agentic RL 算法。