
在大语言模型(LLM)主导的现代 NLP 领域,密集检索已成为问答、摘要、知识问答等任务的核心支撑 —— 毕竟模型再强大,也需要精准的外部上下文来避免 “幻觉”、获取最新信息。但检索效果的好坏,往往卡在一个容易被忽视的环节:文本分块。
传统分块方法(按句子、段落或固定长度切割)就像用尺子机械丈量文本,完全忽略了内容的语义关联性:要么把一个完整的概念拆得七零八落,导致检索片段上下文残缺;要么把多个无关主题硬塞进一个块里,引入大量噪声。这些问题在处理长篇叙事文本(如小说、自传、法律文档)时尤为突出,直接拖累检索性能,甚至让后续的 RAG (检索增强生成)系统 “巧妇难为无米之炊”。
2024 年 EMNLP 收录的论文 LumberChunker 为这一痛点提供了新思路:不依赖固定规则,而是让 LLM 直接 “读懂” 文本语义,动态判断分块边界。本文将带你深入拆解这一方法,看看它如何通过简单的提示词策略,实现比传统方法更优的分块效果,以及它为检索和生成任务带来的实际提升。
论文地址:https://arxiv.org/pdf/2406.17526
项目地址:https://github.com/joaodsmarques/LumberChunker
1、为什么需要重新思考 “文档分块”?
在聊 LumberChunker 之前,我们先明确一个核心问题:分块到底有多重要?以及现有方法的瓶颈在哪里?
研究动机:分块是检索的“第一道门槛”
现代 NLP 任务对检索的依赖越来越深,但传统分块方法正在拖后腿:
- 语义独立性缺失:按句子、段落分割时,可能把“人物背景-事件起因”拆成两个块,或把“案件描述-判决结果”混在一个块里,导致检索到的片段要么“不完整”,要么“冗余”;
- 长篇文本处理乏力:面对小说、自传等叙事性文本,固定粒度分块无法适应内容的逻辑跳转(比如从“回忆”切换到“现实”),检索时容易定位到错误片段;
- LLM“幻觉”风险加剧:如果检索到的分块上下文残缺或无关信息过多,LLM 在生成响应时可能基于错误信息“胡编乱造”,这在法律、医疗等对准确性要求极高的场景中风险巨大。
研究现状:现有分块方法的局限
学术界并非没有尝试解决分块问题,但现有方案仍有明显短板:
分块方法 | 核心思路 | 局限性 |
固定粒度分割(句子/段落) | 按语法结构或固定长度切割 | 完全忽略语义关联性,叙事文本中效果差 |
语义聚类分割 | 用文本嵌入向量聚类,找嵌入距离突变点作为分割点 | 依赖嵌入质量,对长文本的逻辑结构捕捉不足 |
命题级分割 | 拆分成“单个事实”的最小单元 | 粒度过细,破坏叙事文本的上下文连贯性 |
查询调整方法(如 HyDE) | 不优化分块,而是让 LLM 改写查询以匹配文档 | 回避分块问题,对“查询无法覆盖关键信息”的场景无效 |
正是这些局限,让 LumberChunker 的出现有了明确的目标:用 LLM 的语义理解能力,实现“按需分块”——该长则长,该短则短,确保每个块都是语义独立且完整的单元。
2、LumberChunker:动态切割语义块
LumberChunker 的名字很形象——把 LLM 比作“木匠(Lumberjack)”,文档比作“木材”,木匠会根据木材的纹理(文本语义)决定切割位置,而不是用尺子硬切。
核心理念:两大突破
- 动态粒度,而非固定规则:每个分块的大小由内容语义决定,比如“人物生平”部分可能需要较大的块来保持连贯性,而“事件时间线”则可能拆成多个小块;
- LLM 直接判断,无需微调:不训练专门的分块模型,而是通过精心设计的提示词,让 LLM 直接识别“内容开始变化的段落”,从而确定分割点——这意味着实现成本极低,只需调用 LLM API 即可。
具体流程:四步完成动态分块
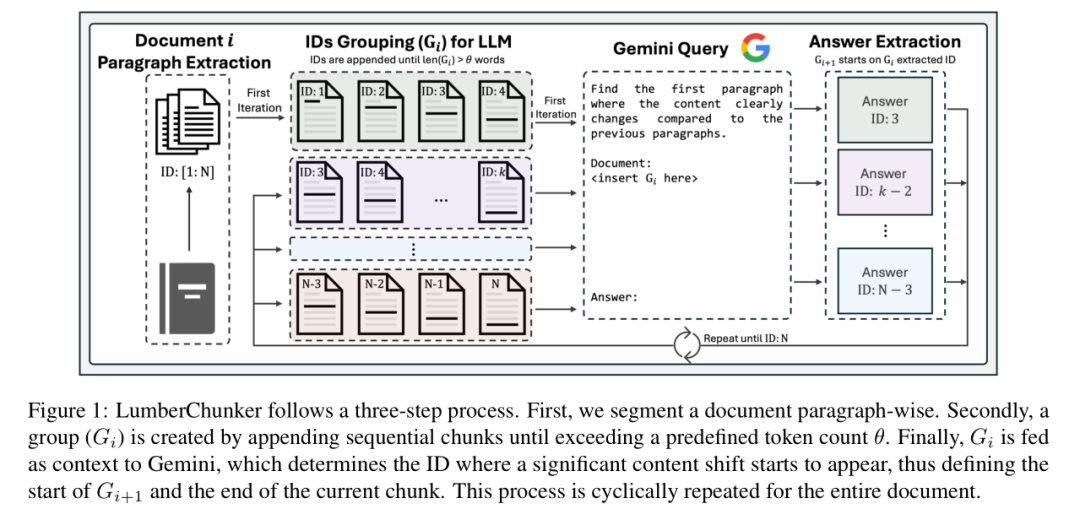
- 步骤 1:段落提取与编号先将文档按原始段落拆分,给每个段落分配唯一的递增 ID(如 P1、P2、P3...),确保后续能精准定位分割点。
- 步骤 2:分组输入(控制上下文长度)把段落按顺序拼接成“分组 G_i”,直到该分组的总 Token 数达到预设阈值 θ(论文中重点研究了 θ 的最优值)。设置 θ 的目的是平衡:既不让上下文太短导致 LLM 看不到完整语义,也不让上下文太长影响 LLM 的判断精度。
- 步骤 3:LLM 判断分割点将分组 G_i 输入 LLM(论文使用 Gemini 1.0-Pro),通过提示词让 LLM 回答:“G_i 中哪个段落开始,内容与前文发生了显著变化?”比如输入 P1-P5 的分组,LLM 可能判断“P3 开始内容切换”,那么 P1-P2 就构成一个分块,P3 则作为下一个分组 G_{i+1} 的起始点。
- 步骤 4:循环迭代,覆盖全文档重复“分组→判断”过程,直到所有段落都被分配到对应的分块中,最终得到一系列语义独立的块。
关键细节:提示词设计
LLM 能精准判断分割点,离不开高质量的提示词。论文中的提示词如下:

3、GutenQA
要证明 LumberChunker 有效,需要一个能精准测试“分块-检索”能力的数据集——现有数据集要么问题太泛(如“总结文档大意”),要么文本太短(无法体现分块价值)。因此,论文团队手动构建了 GutenQA 基准数据集。
数据集特点:“针在草堆”式问答
GutenQA 的核心设计目标是:测试检索系统能否从长篇叙事文本中,精准定位到“唯一且具体”的信息——就像在草堆里找一根特定的针。具体特点包括:
- 数据来源:从 Project Gutenberg(古腾堡计划,免费公共领域书籍库)中手动提取 100 本叙事类书籍(小说、自传等),避免自动提取的编码错误(如乱码、段落错位);
- 问题设计:用 GPT-3.5 生成“事实性、低重复”的问题,比如“主角在 1923 年居住的城市是哪里?”“第三章中提到的实验设备名称是什么?”——这类问题的答案只存在于文本的某个特定片段,无法通过泛泛检索回答;
- 数据规模:每本书筛选 30 个高质量问题,最终包含 3000 个问答对,覆盖多种叙事风格。
为什么 GutenQA 适合评估分块?
传统数据集的问题可能有多个答案片段,或答案分布在多个位置,即使分块不好,也能通过“凑信息”答对。而 GutenQA 的问题答案高度集中且唯一——只有分块精准,才能检索到包含答案的块;分块一旦出错,检索必然失败。这种设计能最大化区分不同分块方法的优劣。
4、实验验证
论文通过三组核心实验,从“参数优化”“检索效果”“生成质量”三个维度验证了 LumberChunker 的价值,我们逐一拆解关键结果。
实验 1:最优 Token 阈值 θ 是多少?
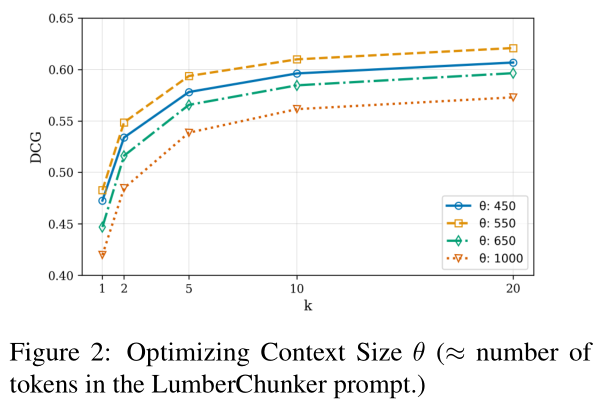
问题:分组 G_i 的 Token 阈值 θ(即每次输入给 LLM 的上下文长度)对分块效果有影响吗?最优值是多少?
实验设计:测试 θ ∈ [450, 1000] 时,LumberChunker 在 GutenQA 上的检索性能(用 DCG@k 和 Recall@k 衡量,分数越高越好)。
关键结果:
当 θ = 550 时,LumberChunker 在所有 k 值下(k=1,5,10,20)均获得最高 DCG 分数。
- θ 太小(如 450):LLM 看不到足够的上下文,容易误判分割点;
- θ 太大(如 1000):上下文过长,LLM 难以聚焦语义变化,判断精度下降;
- θ=550:在“上下文完整性”和“判断精度”之间达到最佳平衡。
实验 2:LumberChunker 比传统分块方法好吗?
问题:在检索任务中,LumberChunker 能否超越语义分块、段落分块、递归分块等基线方法?
实验设计:用 GutenQA 的 3000 个问题,对比 LumberChunker 与 5 种基线方法的检索性能。
关键结果:
LumberChunker 在所有指标上全面领先:
- 在 DCG@20 上,LumberChunker 得分为 62.09,而最接近的基线(递归分块)仅为 54.72;
- 在 Recall@20 上,LumberChunker 同样显著高于其他方法,说明它能更精准地定位到包含答案的块。
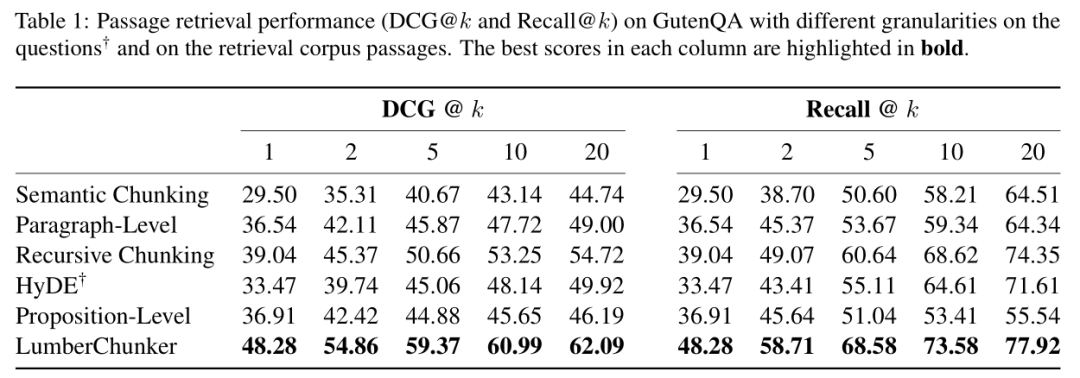
基线方法的局限:
- 段落分块/语义分块:粒度过细,块数量多,检索时容易混入无关块;
- 命题级分块:破坏叙事连贯性,答案可能被拆到多个块中,导致检索失败;
- HyDE(查询调整方法):虽然优化了查询,但分块本身质量差,无法弥补基础缺陷。
实验 3:分块好,生成质量就一定高吗?
问题:LumberChunker 的分块能否提升 RAG 系统的生成质量(即问答准确率)?
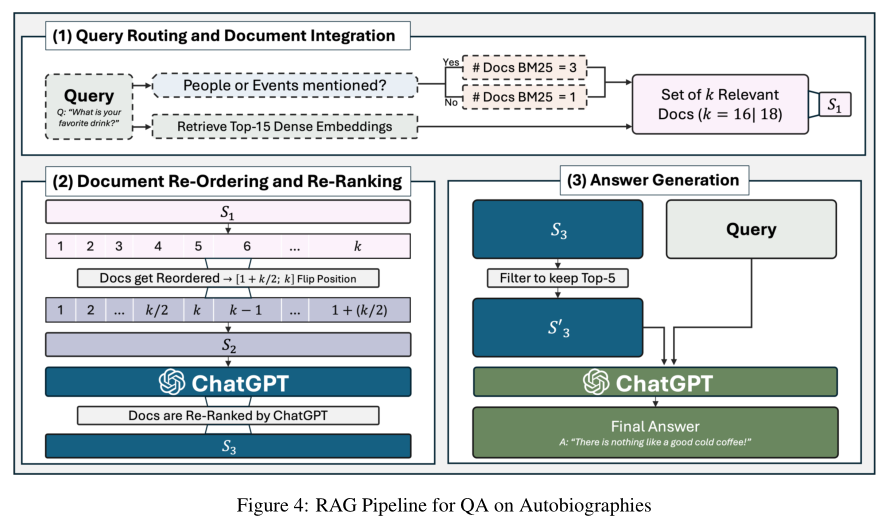
实验设计:将 LumberChunker 集成到 RAG 流程中,基于 4 本自传创建 280 个测试问题,对比它与“手动分块(黄金标准)”“Gemini 1.5 Pro 分块”“闭卷生成”的问答准确率。
关键结果:
LumberChunker 集成的 RAG 系统表现出色:
- 在 k=20 时,LumberChunker 的问答准确率显著高于递归分块、Gemini 1.5 Pro 分块;
- 仅略低于“手动分块”(手动分块准确率最高,但成本极高,无法大规模应用);
- 闭卷生成(不检索)的准确率最低,再次证明“好分块→好检索→好生成”的逻辑链。
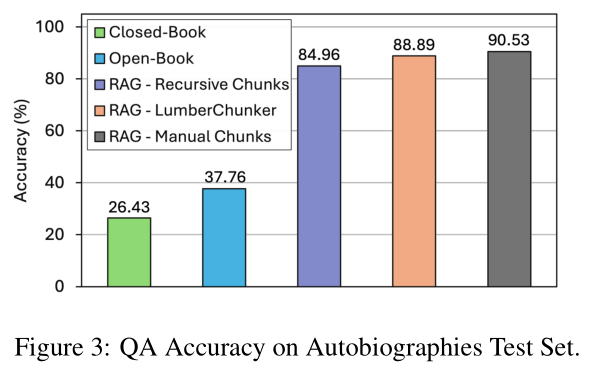
这一结果说明:LumberChunker 不仅能优化检索,还能直接为下游生成任务带来实际价值,是 RAG 系统的“优质燃料”。
补充:分块数量与效率对比
除了性能,分块的“实用性”也很重要——比如块数量太多会增加检索成本,处理时间太长会影响实时性。论文给出的统计结果如下:
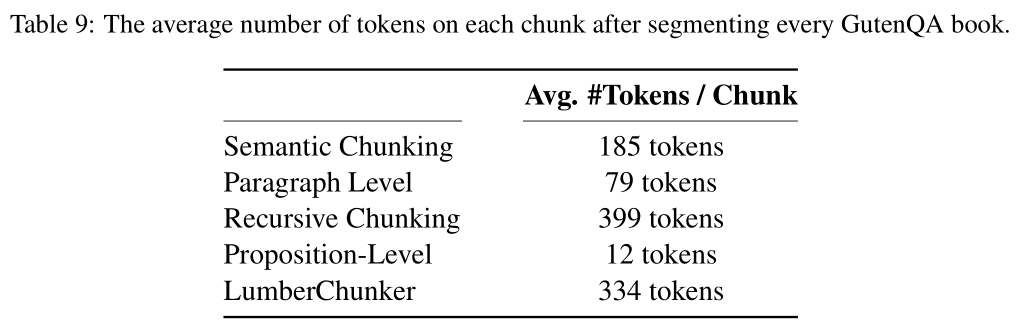
- 分块数量:LumberChunker:由于其动态分割的特性,生成的块数量会根据文档内容的变化而变化,但总体上能够保持块的独立性和连贯性。语义分割和段落级分割:由于分割粒度较细,生成的块数量较多,导致每个块的上下文信息可能不足。递归分割:生成的块数量适中,但块的大小固定,无法动态调整。命题级分割:生成的块数量最多,但每个块的粒度过细,可能导致上下文信息丢失。
- 处理效率:LumberChunker:虽然处理时间较长,但其动态分割方法在语义独立性和检索性能上具有显著优势。未来可通过“减少 LLM 查询次数”“并行处理”进一步优化速度。递归分割:处理时间最短,但缺乏语义理解。适用于对效率要求极高的场景,但可能牺牲一定的语义分割精度。语义分割和命题级分割:处理时间较长,但能够捕捉一定的语义信息。优化方向包括优化嵌入计算和简化聚类算法。HyDE:处理时间适中,但分割粒度固定,灵活性较差。

5、总结
LumberChunker 给我们的最大启示是:在 LLM 时代,分块不需要“另起炉灶”训练模型,而是可以直接利用 LLM 已有的语义理解能力,通过提示词实现低成本、高质量的动态分块。
核心优势
- 效果优:在长篇叙事文本的检索和 RAG 任务中,显著超越传统分块方法;
- 易实现:无需微调,仅靠提示词+LLM 调用即可落地,代码开源(见文末链接);
- 普适性强:不局限于特定文本类型,理论上可应用于法律、医疗、文学等多种领域的长文档。
待优化方向
- 效率:调用 LLM 导致分块时间较长,需探索“批量处理”“轻量模型替代”等方案;
- 极端长文档:对于百万 Token 级别的超长篇文档,如何进一步优化分组策略,减少 LLM 上下文压力。
在实际应用过程中,分块效果对RAG的影响确实远优于固定分块,并且LumberChunker同样适用于中文文本分块。如果你正在做 RAG 系统优化,或被长文档分块问题困扰,不妨试试 LumberChunker——毕竟,好的分块,是让 LLM 发挥实力的第一步。


