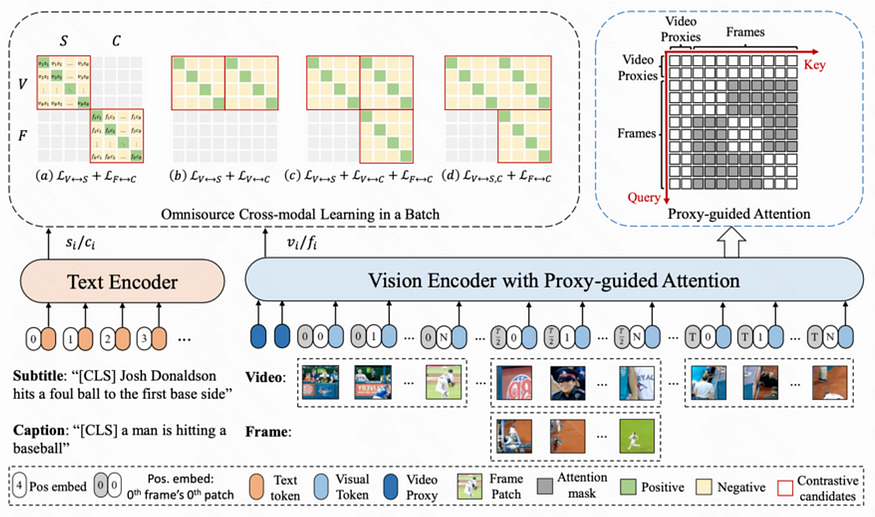
随着视频应用的发展,大量视频被上传到网上。因此,如何利用视频及其对应的弱字幕进行表征学习成为近期的热门话题。本文将回顾大规模视频语言预训练任务的最新进展、后续应用、基础数据集和技术。
1. 简介
本系列的第一部分回顾了大规模视频语言预训练的进展、应用、数据集和技术。该任务使用弱字幕和视频进行表征学习。预训练和微调是深度学习中的一种标准学习范式,用于在大型数据集上对模型进行预训练,然后在较小的数据集上针对特定任务进行微调。这消除了为不同任务训练新模型的需要,并降低了计算成本。
预训练通常使用自监督学习在 ImageNet 等大型数据集上进行,而无监督学习在自然语言处理 (NLP) 和计算机视觉 (CV) 领域也表现出色。预训练模型的权重随后会在较小的数据集上进行微调,以实现特定任务的学习目标。
视频语言预训练利用大规模视频文本数据进行自监督/无监督学习,以获得泛化表征。主要的代理任务包括掩码语言模型 (MLM)、掩码帧模型 (MFM)、语言重构 (LR)、视频语言匹配 (VLM)、句子排序模型 (SOM) 和帧排序模型 (FOM)。这些任务分别侧重于语言预测、帧预测、句子生成、视频语言对齐、句子排序和帧排序。这些任务旨在从序列视角学习共现关联、语义限制、视频字幕生成、对齐和关系。
2.最新进展及应用
预训练模型的最新进展凸显了数据集大小对于表征学习的重要性。因此,研究人员正在使用来自互联网的大规模、弱标记跨模态数据,例如图像-字幕对和视频-字幕数据。这引发了跨模态任务研究的激增,尤其是视觉-语言任务和视频-语言任务。
视觉语言预训练的一项重要进展是对比语言图像预训练 (CLIP),它使用对比损失从弱监督数据中学习多模态表征。该模型基于 4 亿个图像-文本对的数据集进行训练,在图像分类等零样本视觉识别任务中表现出色。
视频数据本身就具有多模态性,包含标题、音频和旁白等元素,其处理也取得了进展。诸如 Howto100M 之类的大型视频数据集已被提出,该数据集包含 1.36 亿个包含旁白文本数据的视频。这促进了视频语言预训练的发展,为视频理解任务开辟了新的领域。
Transformer 模型最初是为机器翻译而提出的,在计算机视觉领域表现出色。它计算元素的相似度,并聚合这些元素的长程依赖关系,从而能够在更大的数据集上进行训练。
视频语言预训练旨在将知识从大型数据集迁移到下游任务,这些任务应包含文本和视频输入。下游任务包括视频文本检索、动作识别、视频问答和视频字幕。每个任务都需要采用不同的方法将信息从预训练迁移到下游任务,这凸显了预训练和下游任务之间兼容性的重要性。
3. 开放视频语言预训练数据集
预训练数据集的规模和质量对于学习鲁棒的视觉表征至关重要,尤其对于基于 Transformer 的模型而言。视频语言预训练的关键数据集可分为两类:基于标签的数据集和基于字幕的数据集。
基于标签的视频数据集:
1. Kinetics:一个具有多种类别的大规模动作识别数据集,包含多达 650,000 个视频片段,涵盖 400/600/700 个人类动作类别。
2. AVA:在 15 分钟的电影剪辑中密集注释 80 个原子视觉动作,产生 1.62M 个动作标签,并且每个人经常出现多个标签。
基于字幕的视频数据集:
1. ActivityNet Captions:包含 20k 个视频,总计 849 个视频小时,总共 100k 个描述,每个描述都有其独特的开始和结束时间。
2. YouCook2:最大的面向任务的教学视频数据集之一,包含 89 种烹饪食谱的 2000 个较长的未剪辑视频。
3. Howto100m:一个大规模的旁白视频数据集,包含超过 1.36 亿个视频片段,其字幕来自 120 万个 YouTube 视频。
4. WebVid:一个包含超过两百万个弱字幕视频的数据集,这些视频均从互联网上抓取。目前有两个版本:WebVid-2M 和 WebVid-10M。
5. HD-VILA:第一个高分辨率数据集,包含 1 亿个视频片段和来自 330 万个视频的句子对,其中 371.5K 小时为 720p 视频。
这些数据集对视频语言预训练方法的进步起到了重要作用,为训练稳健模型提供了多样化和大规模的数据。

4. 视频语言预训练方法
近期的视频语言预训练方法主要使用 Transformer 作为特征提取器,从大规模多模态数据中进行学习。这些方法可以分为两类:单流 (Single-Stream) 和双流 (Two-Stream)。
单流方法:
1. VideoBERT:第一个使用基于 Transformer 的预训练方法探索视频语言表示的模型。
2. HERO:一种单流视频语言预训练框架,以分层结构对多模式输入进行编码。
3. ClipBert:提出了一个通用框架,通过采用稀疏采样,实现视频和语言任务的经济实惠的端到端学习。
4. DeCEMBERT:开发该技术是为了解决预训练数据集中自动生成的字幕嘈杂且偶尔与视频材料不一致的问题。
5. VATT:一种使用无卷积 Transformer 结构从未标记数据中学习多模态表示的方法。
6. VIOLET:提出了一种端到端模拟视频时间动态的变换框架。
7. ALPRO:一种用于视频语言预训练的单流框架,提出了视频文本对比以促进多模式交互。
双流方法:
1.CBT:提出对比噪声估计(NCE)作为视频语言学习的损失目标。
2.UniVL:提出用于多模态理解和生成的模型。
3.Frozen in Time(FiT):旨在学习联合多模态嵌入,以实现有效的文本到视频检索。
4.CLIP-ViP:建议在视频语言数据上预训练 CLIP 模型,以进一步将视觉语言对齐扩展到视频级别。
这些方法在各种应用中都展现出了良好的效果,包括动作识别、视频字幕、动作预测和视频分割。单流和双流方法的选择取决于任务的具体要求。单流方法通常能够捕捉文本和视频之间更细粒度的关系,而双流方法则通过分别提取不同模态的特征来提供更大的灵活性。