
两个月前,知识星球中有个关于银行流水分析的提问:
想问问对于流水识别是否有比较好的解决方案呢?我们现在想用大模型能够对多家银行进行识别,但是发现识别准确率很一般,经常出现表格识别数据错乱的情况,而且效率也不太行
这个问题在企业信贷的贷前风控场景经常出现,不同银行的流水格式一般有所区别,而且一家企业往往涉及多家银行的账户使用。这也导致了流水解析和分析工作复杂度确实高很多。
我其实去年底在 Github 上开源过一个见知流水格式的流水分析报告Demo,当时是针对单一银行格式,不过也是完整实现了指标加工逻辑的和报告生成方法的介绍,感兴趣的可以瞅瞅:https://github.com/weiwill88/bank-statement-analysis
这篇试图说清楚:
信贷场景的贷前尽调背景、多银行流水的非标特点,以及如何基于 Dify 实现对多源异构银行流水的自动化分析报告生成。
基于Dify动态解析异构银行流水,韦东东,8分钟
以下,enjoy:
1、项目背景
熟悉信贷行业的盆友应该都知道,在贷前风控体系中,通过线上方式获取到的企业的工商、司法、税务及征信等多类型数据,因为有非常多成熟的解析和清洗做法,各家更多的是基于经验来构建规则引擎进行自动化审批。但是,这套体系存在一个关键的盲区,也就是下述要展开提到企业真实的经营现金流情况。
分析企业银行流水,是判断企业经营稳定性和真实贸易背景的最重要手段之一。尤其是其中收入是否稳定、支出是否合理、是否存在异常的资金往来。当然,既然大家都没普遍采用这类数据肯定是因为有众多显示的难点:
1.1线下获取问题
银行流水不像税务数据一样,可以线下或线上完成授权后,直接线上获取后处理分析。而且一家企业往往会涉及多个常用的银行账户,所以需要业务人员线下方式向企业收集,最常见的格式是 Excel 或 PDF 格式(这篇以 EXCEL 格式为例进行演示)。
1.2人工分析的瓶颈
抛开纯线上的企业贷款产品不谈,一般线下授信的贷前尽调环节,客户经理都需要从客户收集多家银行格式各异的流水表格,然后再手动进行汇总和分析。这个过程不仅效率低下,更容易因人为疏忽而遗漏关键的风险点,比如一笔伪装成正常经营的大额融资款流入,或一笔隐藏的关联方资金占用等。
2、核心挑战
要利用 LLM Agent 实现对银行流水的全自动分析,我们必须克服几个现实的技术难题:
2.1表头位置不固定
不同银行的流水导出格式差异很大。最棘手的问题是,列标题(Header)并不是总在文件的第一行,有的在第二行,有的甚至在第四、第五行,上方可能包含银行 Logo、账户信息等元数据。
这种不确定性也让传统的硬编码脚本(如 pandas.read_excel(header=0))完全失效。所以,现在市面上多家
SaaS 的做法就是穷举所有银行或支付公司的模板。虽然这种做法看起来和务实,但确实属于上一个时代的做法,既不优雅也无法应对银行未来可能发生的格式调整。
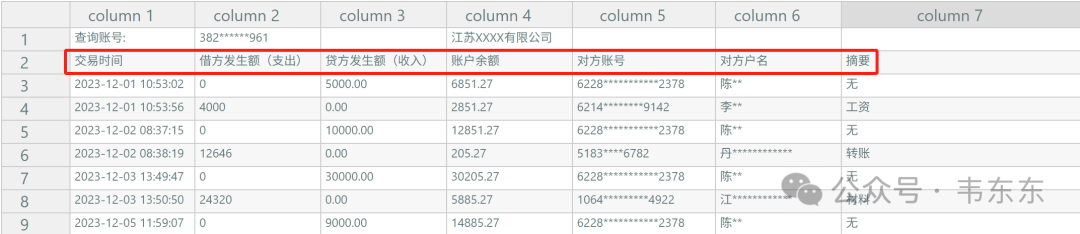
2.2核心字段名称不统一
即便定位了表头,还需要把不同银行的列名映射到统一的分析字段上。例如,关注的核心指标是“交易时间”、“收入”、“支出”、“账户余额”、“交易对手”和“摘要”。但在实际流水中,它们可能被命名为“记账日”、“贷方发生额(收入)”、“借方发生额(支出)”、“余额”、“对方户名”、“附言”等等。如何准确理解这些“同义词”,是实现自动化的关键。

2.3摘要信息定性难
判断一笔交易的真实性质(如销售回款、采购支出、工资发放),强依赖于对“摘要”或“附言”字段的理解。人工判断不仅耗时,且极度依赖个人经验。要让机器做出精准判断,就必须为其注入两类核心知识:
交易分类知识:如何根据摘要关键词(如“货款”、“工资”)将交易归入正确的业务类别?
风险分析知识:当某些数据模式出现时(如客户高度集中、大额对私转账),它们具体意味着什么风险?
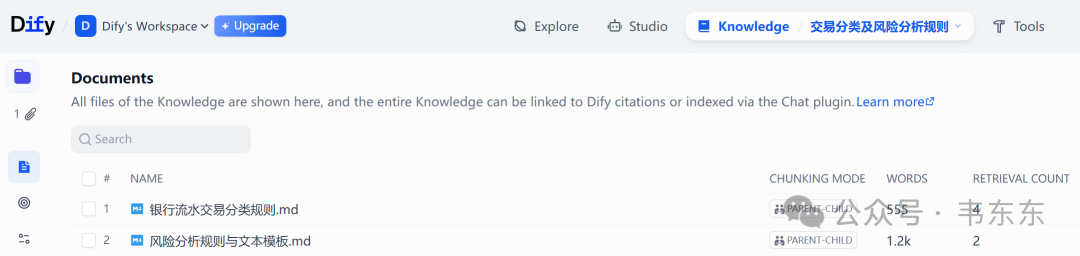
为了系统性地解决这个问题,我提供了两个核心知识库作为示例:银行流水交易分类规则.md 和风险分析规则与文本模板.md。这两个文件把风控专家的经验规则化、文本化,是驱动 LLM 进行贴合场景深度分析的必要参考。
3、解决方案架构
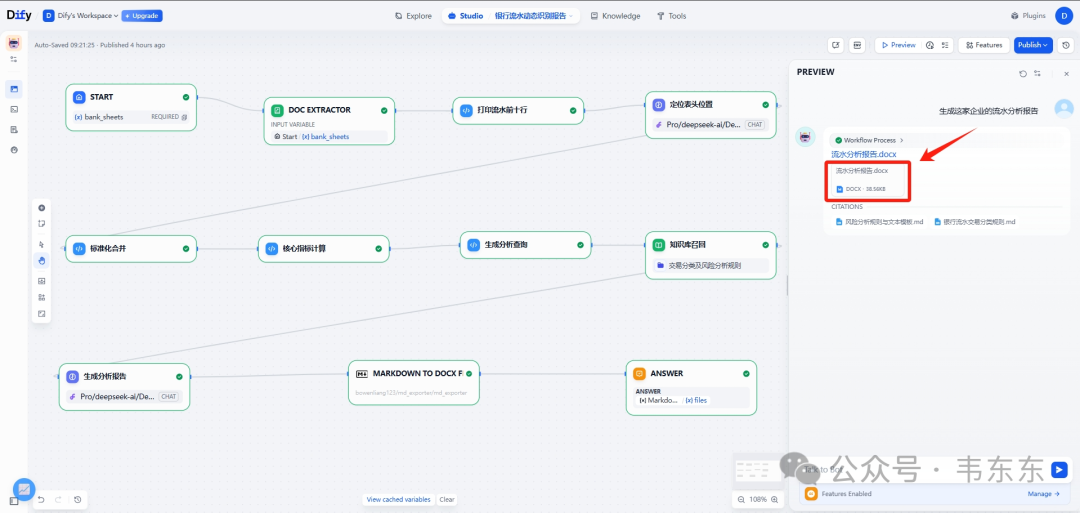
为了解决上述提到的问题,下面演示一个基于 Dify 的工作流方案。其核心思想是“分而治之”,引入了很多代码和 LLM 节点,让不同的节点各司其职,最后完成一份流水分析报告。核心架构参考下图:
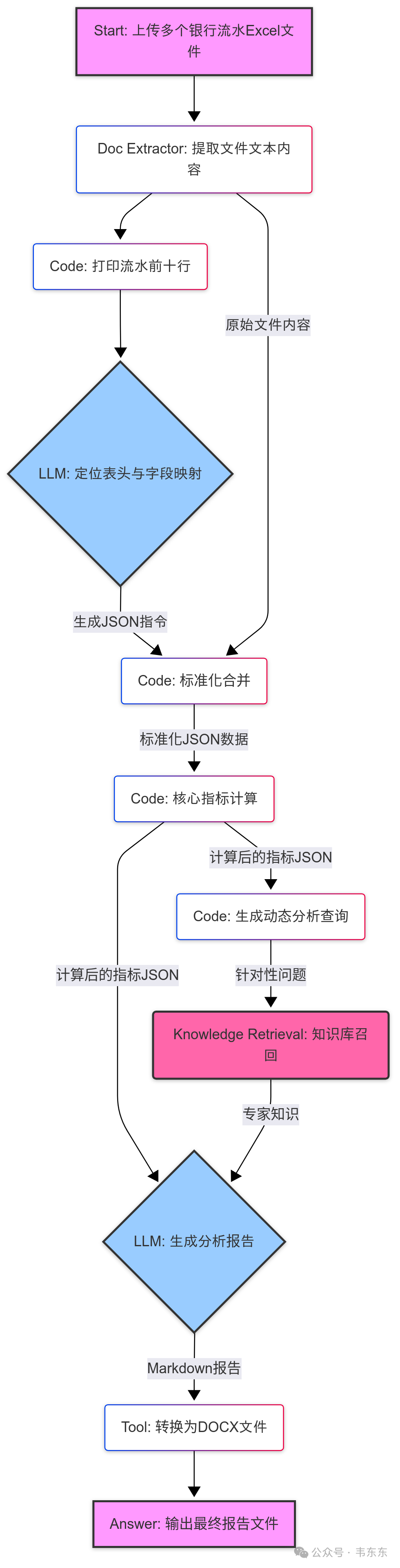
3.1动态识别与解析
核心节点:打印流水前十行 (Code) -> 定位表头位置 (LLM)
实现方式:不直接让 LLM 处理整个流水文件,而是先用一个 Code 节点(打印流水前十行)提取每个文件的前 10 行作为“预览”。这一般足以暴露表头的位置和命名方式。
然后把这些预览喂给定位表头位置 LLM 节点,并给它一个非常明确的指令(来自 定位表头位置 节点):
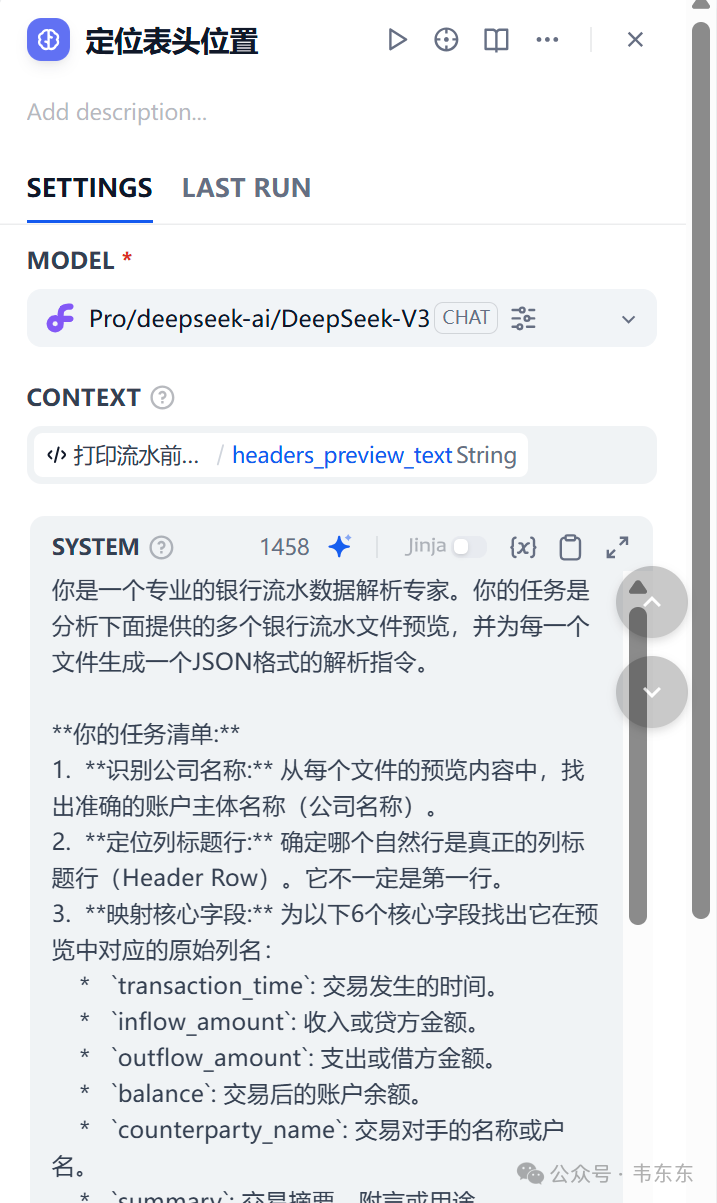
LLM 会输出一个结构化的 JSON 指令,精确地告诉后续节点每个文件的表头在哪一行,以及“收入”、“支出”等标准字段对应原始表中的哪一列。
3.2标准化与计算
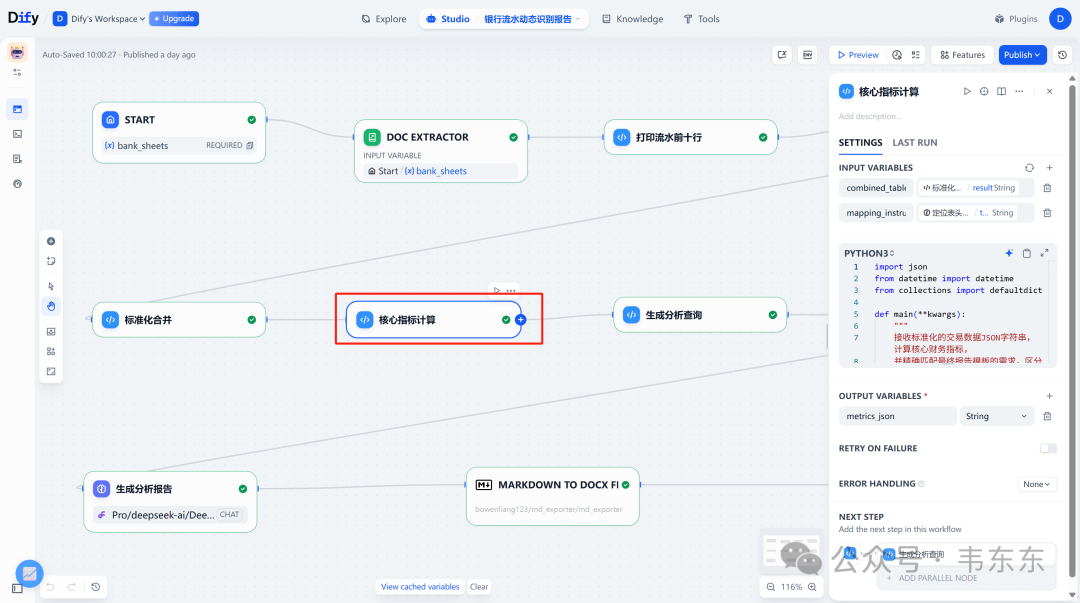
核心节点:标准化合并 (Code) -> 核心指标计算 (Code)
实现方式:标准化合并 Code 节点接收上一步 LLM 生成的 JSON 指令和原始文件全文。它会严格按照指令解析每一个格式各异的文件,把所有交易记录清洗、转换并合并成一个统一格式的 JSON 数组。
随后,核心指标计算 Code 节点对标准化的数据进行纯粹的数学计算,得出月度趋势、流入流出构成、核心对手方等关键指标,并输出为 JSON。值得一提的是,在此节点中,引用了银行流水交易分类规则.md 的核心思想。 对于高频且明确的交易类型,我们直接在代码中内置了关键词分类逻辑,以保证计算的效率和准确性。
这个知识库定义了如何将模糊的交易摘要映射到标准的财务类别:
在 核心指标计算 节点的代码中,实现了下述这个逻辑。这种“规则代码化”的方式确保了基础分类的稳定,而完整的知识库文件则用于后续 LLM 的深度理解。
3.3知识增强与洞察
核心节点:生成分析查询 (Code) -> 知识库召回 (Knowledge Retrieval) -> 生成分析报告 (LLM)
实现方式:这一步是提升分析深度的关键。此阶段深度依赖第二个知识库 风险分析规则与文本模板.md。这个知识库以“规则-模板”的形式存在。它告诉 AI 在发现特定数据模式时,应该生成什么样的风险提示。
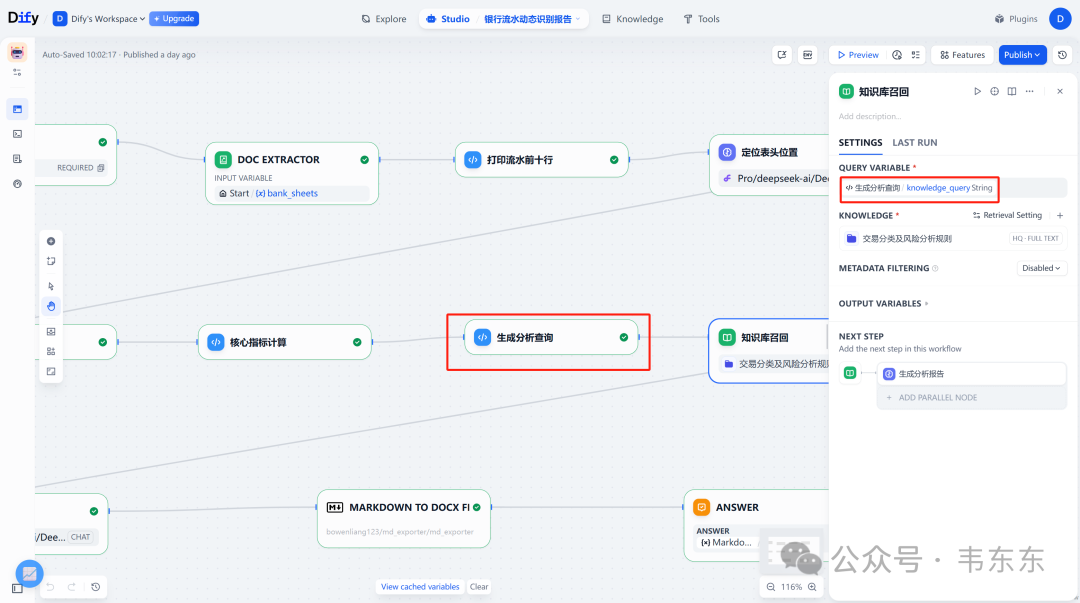
工作流程如下:
1、生成分析查询 节点基于计算指标,动态生成查询,如“客户集中度为 85%,这存在什么风险?”。
2、知识库召回 节点接收到这个问题后,从风险分析规则与文本模板.md 中精确匹配到“客户集中度风险”的规则和模板。
3、最后,生成分析报告 LLM 节点会拿到三样东西:数据(指标 JSON)、问题(动态查询)、以及答案模板(从知识库召回的文本)。LLM 最后把实时计算出的数据(如{concentration_ratio}的值)填充到分析模板中,最终生成一份数据翔实分析报告。

4、工程经验与架构升级方向
4.1工程经验提炼
LLM 与 Code 的“指令-执行”模式
这个项目演示的一大亮点在于,把 LLM 定位成生成结构化指令(JSON)的“动态解析器生成器”。由确定性的 Code 节点来执行这些指令,确保了数据处理的稳定性和可靠性。
“预览+认知”策略的有效性
通过让 LLM 先看“预览”来降低问题难度,可以显著提升其识别复杂格式的准确率,并节约处理 Token 的成本。
动态 RAG
相比于用一个笼统的问题去检索知识库,先通过 Code 节点先分析数据,再提出“数据驱动”的、具体的问题。这使得 RAG 的召回内容更具针对性,极大地提升了最终报告的分析深度。
混合分类方法
在 核心指标计算 节点中,内置了基于关键词的简单分类规则,用于处理明确的交易(如“工资”、“税”)。这是一种有效的“人机协作”,将简单、高频的任务交给代码,把复杂、模糊的定性任务留给知识库和 LLM,实现了效率和质量的平衡。
4.2架构升级参考
引入多模态能力处理 PDF 和图片
当前工作流主要处理 Excel(文本化后)。下一步可以集成其他工具作为前置节点,把扫描版的 PDF 或图片格式的流水单据转换为文本,从而将处理范围扩大到所有常见流水格式。
构建交易对手知识图谱
当前的对手方分析停留在 TOP N 列表。未来可以引入知识图谱技术,将所有交易对手构建成一个网络,用于挖掘隐性的关联关系、识别资金的循环流动(空转)或疑似的壳公司交易。
增加自修正的闭环反馈机制
可以在标准化合并节点后增加一个校验环节。如果解析失败或数据出现逻辑错误(如余额对不平),可以将错误信息和原始预览再次反馈给定位表头位置 LLM 节点,让其再试一次,形成一个自修正的循环,提升鲁棒性。
人机协同
对于 LLM 无法准确分类的“未分类交易”,可以设计一个简单的标注界面。系统将这些模糊的交易推送给人工进行标注,标注结果再反哺到知识库,使系统在持续使用中变得越来越聪明。


