编辑丨&
当下,各类实验室非常热衷于把大型语言模型(LLMs)和视觉—语言模型(VLLMs)当作科研助手,但科学工作不像聊天那样单一:它要求把图像、表格、谱图、实验装置等多模态信息整合并进行多步推理与决策。
一个全面有效的评估基准显然是当下急缺的。来自德国耶拿大学(Friedrich Schiller University Jena)等的团队提出了一个面向真实科研流程的评测框架——MaCBench,把科研活动粗分为「信息抽取」「实验执行」与「结果解读」三大支柱,以便系统评估模型在真实化学/材料任务中的表现与失败模式。
该成果以「Probing the limitations of multimodal language models for chemistry and materials research」为题,于 2025 年 8 月 11 日刊登在《Nature Computational Science》。

论文链接:https://www.nature.com/articles/s43588-025-00836-3
任务设计与覆盖面
科学研究一直需要整合和融合多种信息形式,捕捉科学研究的基本特征——即灵活地解释和连接多种信息模式,将会由人工智能尤其是大规模语言模型(LLMs)进行进一步的开发与探索。
为了填补不同模型之间,如何科学的处理相互作用的系统性评估的问题,以及了解当下模型的极限究竟能达到什么地步,提出了材料与化学基准(MaCBench),这是一个全面的基准测试,评估多模态能力在科学过程三大核心支柱上的表现:文献信息提取、实验执行和数据解释。

图 1:MaCBench 框架概览,涵盖多模态化学与材料科学研究生命周期。
MaCBench 收集并构建了一个多样化的任务集:总计包含若干子任务,覆盖表格与图表的数值抽取、有机反应与化学结构理解、晶体学、光谱学(如质谱、NMR)与表面成像(如 AFM)等场景。
在上述提到的三个关键方面里,各自涵盖了各种科学活动的任务,包括 779 道多项选择题和 374 道数值回答题。该基准并不仅仅问「能不能识别图像」,而是刻意把问题设计成贴近科研流程的多步推理题,以便暴露模型在跨模态整合与科学推理上的缺陷。
性能评估与失败剖析
不同任务类型和模态之间,模型性能存在较大差异,如 Claude 3.5 Sonnet 等在整体平均成绩上领先,但模型表现呈现出明显的不均衡。
总体上,模型在标准化的感知性任务(例如识别实验设备)表现良好,设备识别的平均准确率约为 0.77;而在复杂的空间推理与谱图解释方面则表现疲软,例如对 AFM 图像的平均准确率仅约 0.24,质谱与 NMR 的平均准确率约 0.35,表格中成分的抽取平均准确率约 0.53。
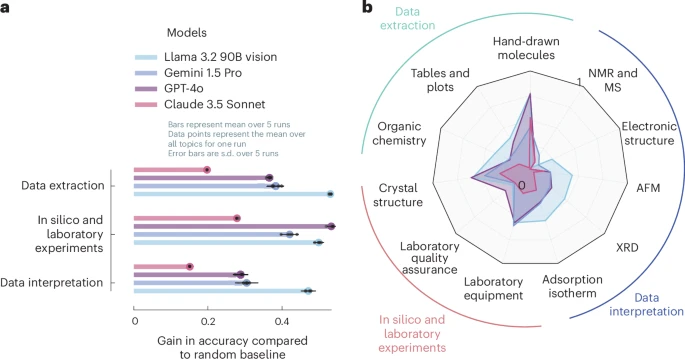
图 2:前沿 VLLM 的性能。
总体呈现的趋势是,单模或感知类任务上接近可用,但在需要跨模态综合、多步逻辑推导或精细测量的任务中会失速。为了继续研究,团队准备了深入的消融实验来进一步了解 VLLMs 的失败模式。
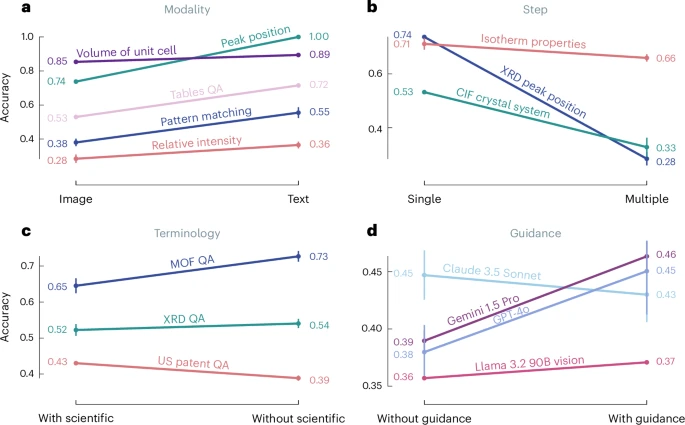
图 3:VLLMs 在化学和材料科学任务中性能的四个关键维度上的消融研究结果。
通过一系列消融实验,团队将模型失败归结为两大类:一是核心推理限制,即当前体系架构或训练范式难以支撑多步、跨模态的科学推理;二是对输入与推理设置(inference choices)的敏感性,模型在信息呈现形式、术语专业性和多步推理的复杂度上高度波动。
这些问题的具体表现有:
1.当同一信息以文本呈现时模型往往做得更好,但把相同内容以图片或图谱呈现时性能大幅下降。
2.当需要多步逻辑(例如从图谱上读峰位、再根据化学原理推断结构)时,准确率随步骤数迅速下滑。
设计团队强调,当前的 VLLM 更像是「强大的模式匹配器」,而非能做出稳健科学判断的推理引擎。他们的工作揭示的是最先进的 VLLMs 在科学任务中的潜力和局限性,同时他们的发现也指出了可行的发展路径。他们建议纳入泛化测试,以确保稳健的能力发展。
小结
研究者表示,他们把「评估多模态在科学中能做什么」这件事做成了一个可重复、可量化的工程:既彰显了模型在系统处理科学信息能力上的进步,也指出在综合任务与视觉模态上的结构性弱点。
研究结果表明,在科学中推动 AI 的发展不仅需要模型改进,还需要更好的科学知识表示方法——尤其是在解决空间推理能力和跨模态整合能力的观察差距时。对科研组织与自动化实验室的决策者来说,这意味着可以把 VLLM 用作「加速工具」,但不可把它视为能独立承担复杂科学判断与安全决策的替代者。