DeepSeek V4 预览版开源上线后,第一波来自第三方榜单的测评结果已经出炉。多家测评显示,DeepSeek V4性能尤其在代码任务上冲进开源第一梯队,同时以“百万级上下文+低价”把开发者侧的使用门槛进一步压低。
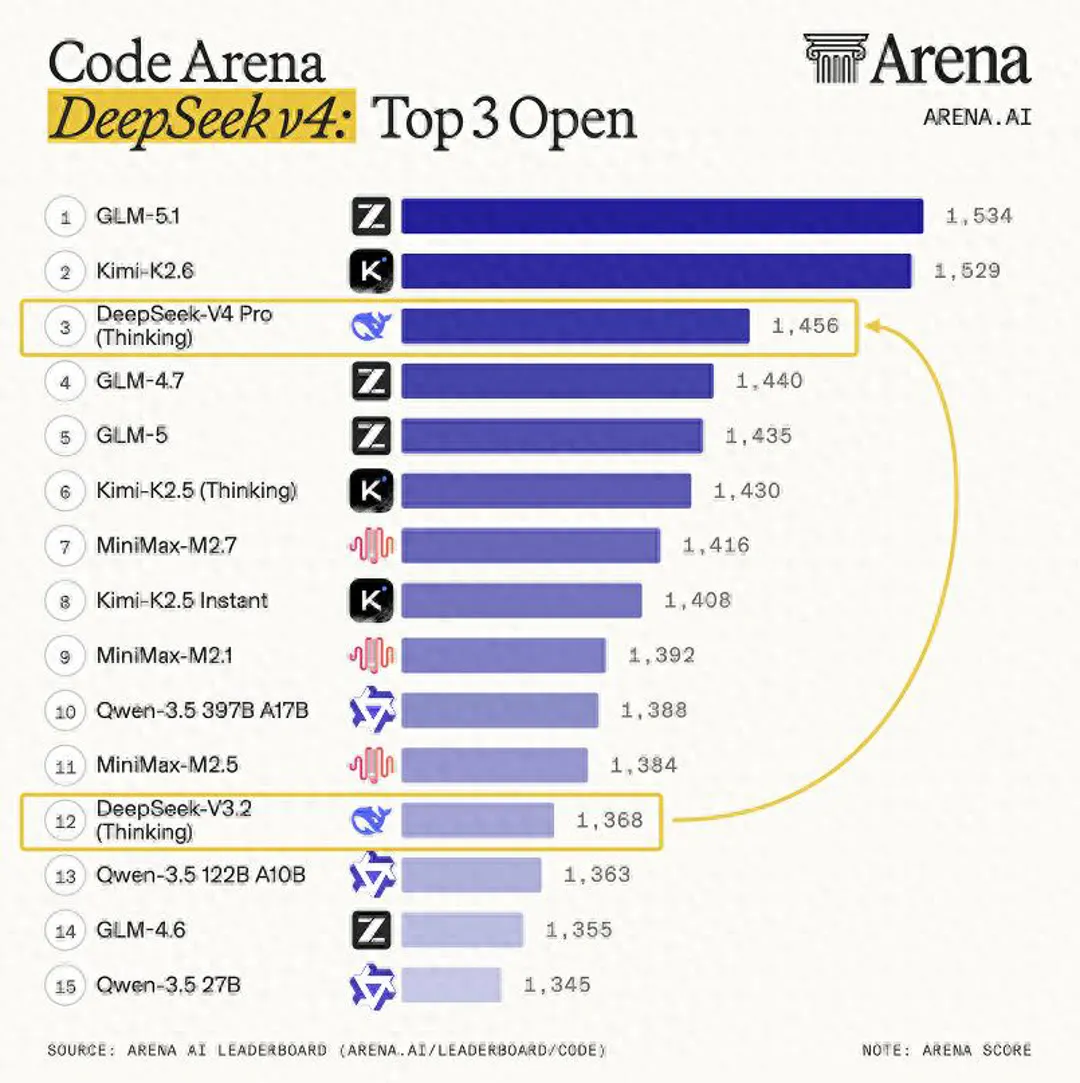
从第三方评测来看,评测平台 Arena.ai 在 X 上将V4 Pro(思考模式)定性为"相较DeepSeek V3.2的重大飞跃",在其代码竞技场中列开源模型第3位、综合第14位;另一家测评方 Vals AI 则称,V4在其Vibe Code Benchmark中以"压倒性优势"拿下开源权重模型榜首,击败Gemini 3.1 Pro等闭源模型,较上代V3.2实现约10倍性能跃升。
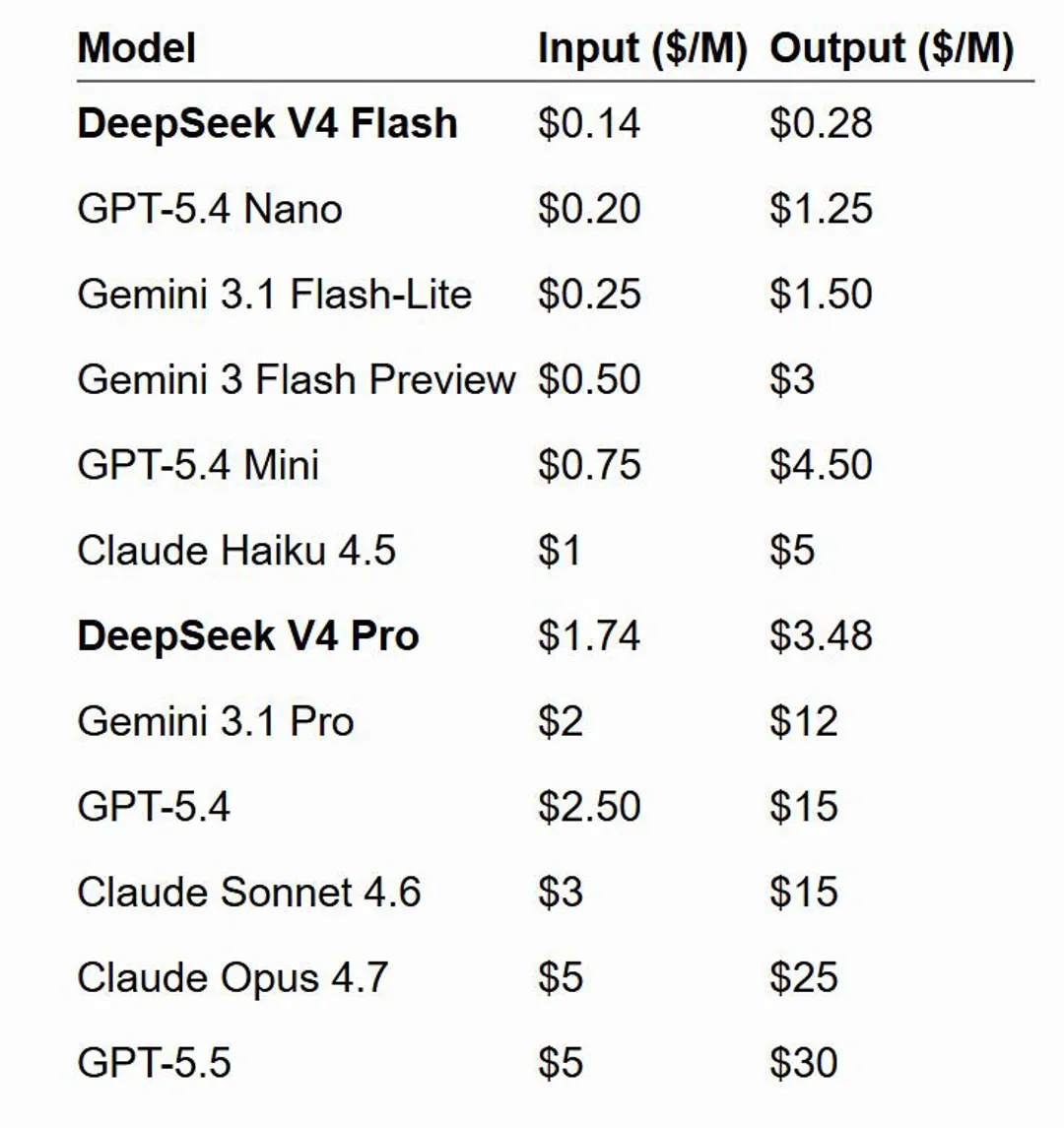
定价层面,V4-Flash输出价格为每百万token 0.28美元,较Claude Opus 4.7低逾99%;V4-Pro输出价格为3.48美元,是同级别前沿模型中定价最低的选项之一。对比表格显示,Flash 处于小模型区间最低档,Pro 也处于“大模型前沿”区间低位。
围绕实际体验的讨论开始分化。多位网友在 X 上称其性价比“打穿”。而DeepSeek在自述材料中则保持克制,称在知识与推理上接近闭源系统但仍有约3到6个月差距,同时提示“受限于高端算力”,Pro 服务吞吐有限,后续价格存在下调预期。
第三方测评:代码能力独占鳌头,综合排名紧追顶级
就在OpenAI GPT-5.5发布不久后,DeepSeek-V4预览版正式上线并同步开源,涵盖参数总量1.6万亿(激活参数49B)的V4-Pro,以及参数总量2840亿(激活参数13B)的V4-Flash,两款模型均支持100万token超长上下文窗口,采用MIT开源协议。

模型评测平台Arena.ai在V4发布当日宣布,DeepSeek V4 Pro(思考模式)在其代码竞技场中排名开源模型第3位,综合排名第14位,并将此次发布定性为"相较DeepSeek V3.2的重大飞跃"。Arena.ai同时测试了V4 Flash,两款模型均支持100万token上下文。
Vals AI的评测结果更具看点。该平台表示,DeepSeek V4在其Vibe Code Benchmark中"以压倒性优势"成为开源权重模型第一,不仅超越第2名Kimi K2.6,更击败Gemini 3.1 Pro等闭源前沿模型。

Vals AI特别强调,V4较V3.2实现了约10倍的性能跃升——"V3.2在该基准上仅得5分,这不是笔误。"在Vals综合指数排名中,V4以第2位收官,与榜首Kimi K2.6仅相差0.07%。
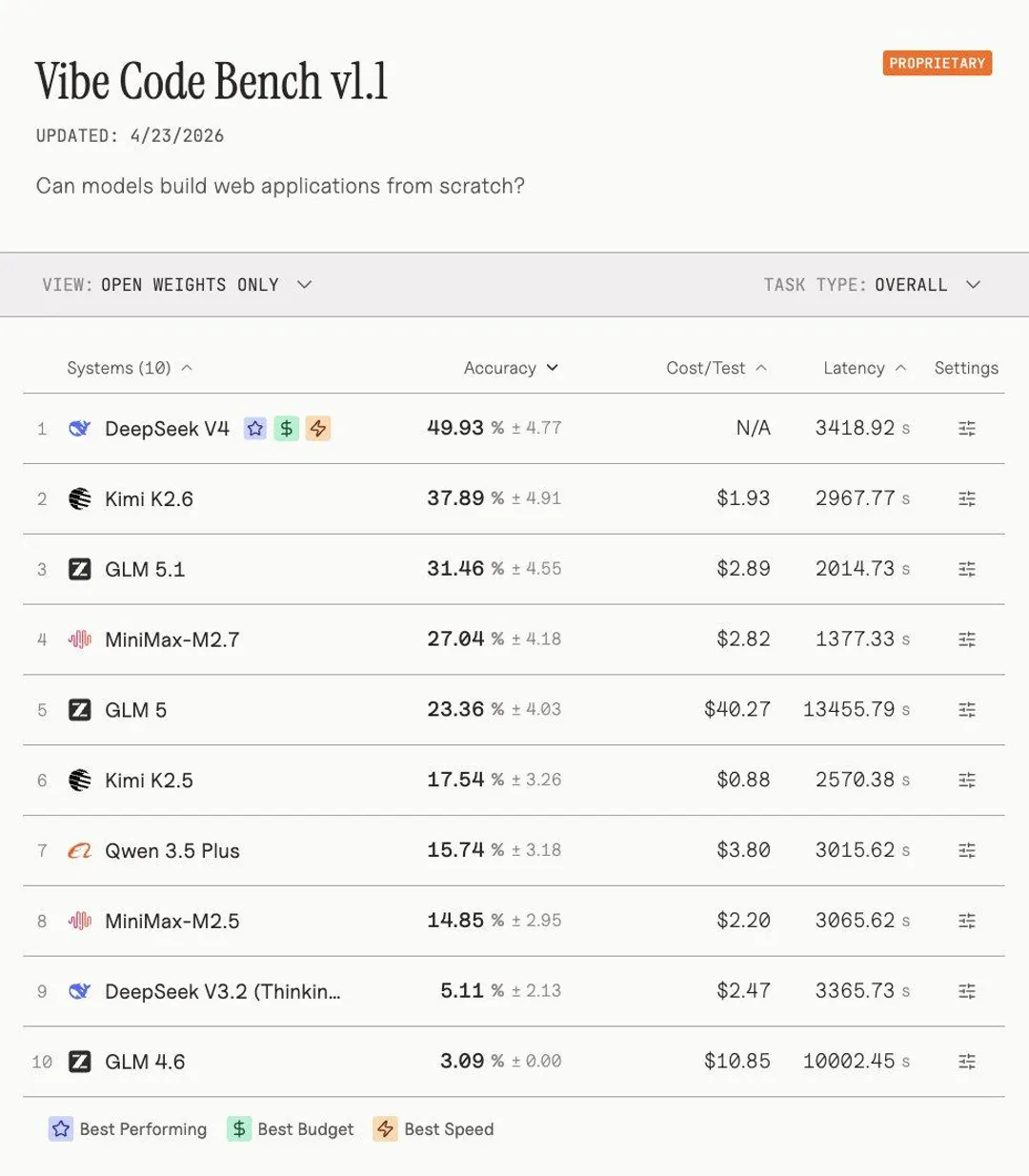
社区反应十分积极。在X平台上,用户Sigrid Jin称其带来新的“shocking moment”,并提到“现在可以在家里跑 gpt 5.4-ish 的模型”。他写道:
"GPT-5.5,对不起,DeepSeek V4才是新的震撼时刻,它在代码竞技场中击败了GPT-5.4高强度模式。"
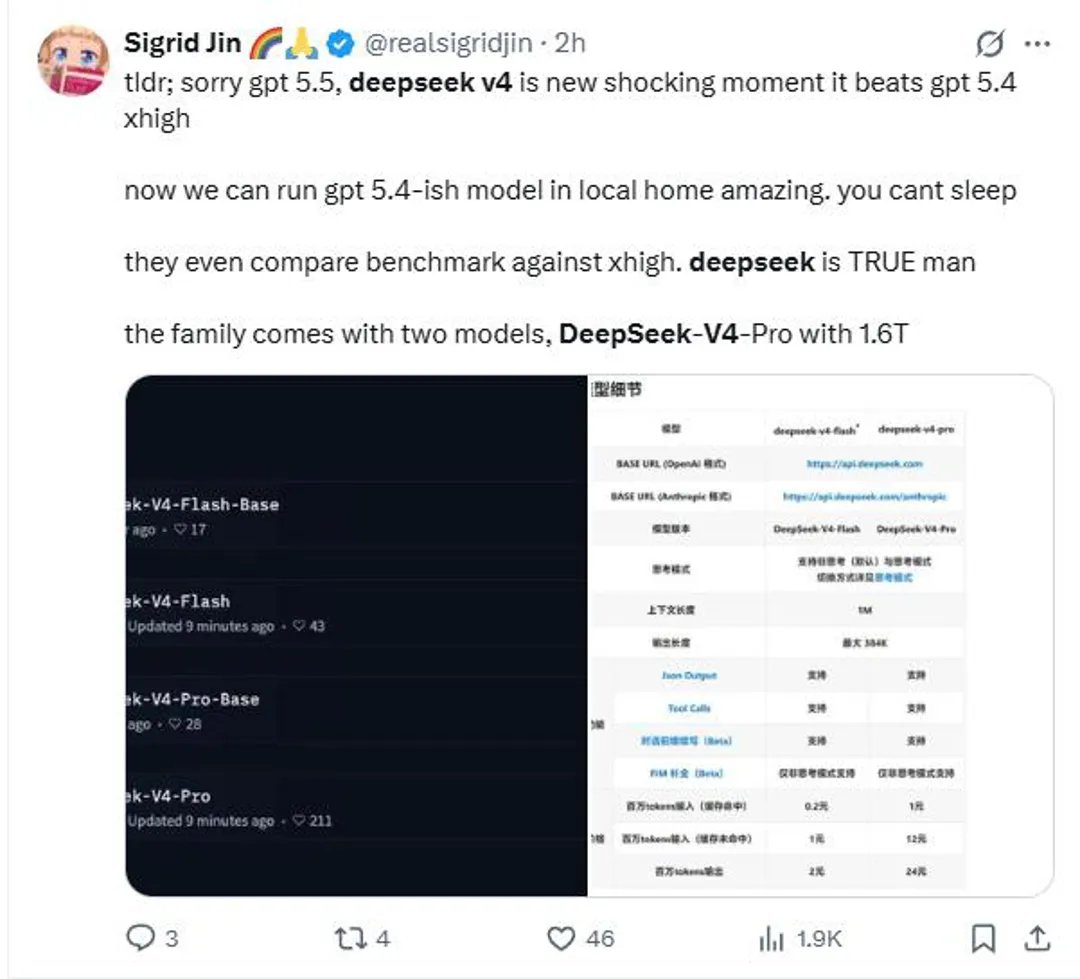
用户Ejaaz则称:
"中国正在主导AI,他们已经追上来了。DeepSeek V4 Flash比Opus 4.7便宜99%,每百万token仅需0.28美元,代码竞技场排名第一,这不是笔误。"
也有用户表达保留意见,X用户Michael Anti在试用后表示,V4 Flash的实际体验未能超越此前已相当成熟的V3.2,认为对老用户而言升级体验令人失望。
官方自评:措辞克制,代码与Agent领域差距最小
DeepSeek对自身性能的评述保持了一贯的审慎风格。官方文件显示,在知识与推理任务上,V4-Pro已超越主流开源模型,接近Gemini等闭源系统,但与最先进的前沿模型仍存在约3至6个月的差距。在Agent和代码任务上,表现接近甚至部分超过Claude Sonnet。
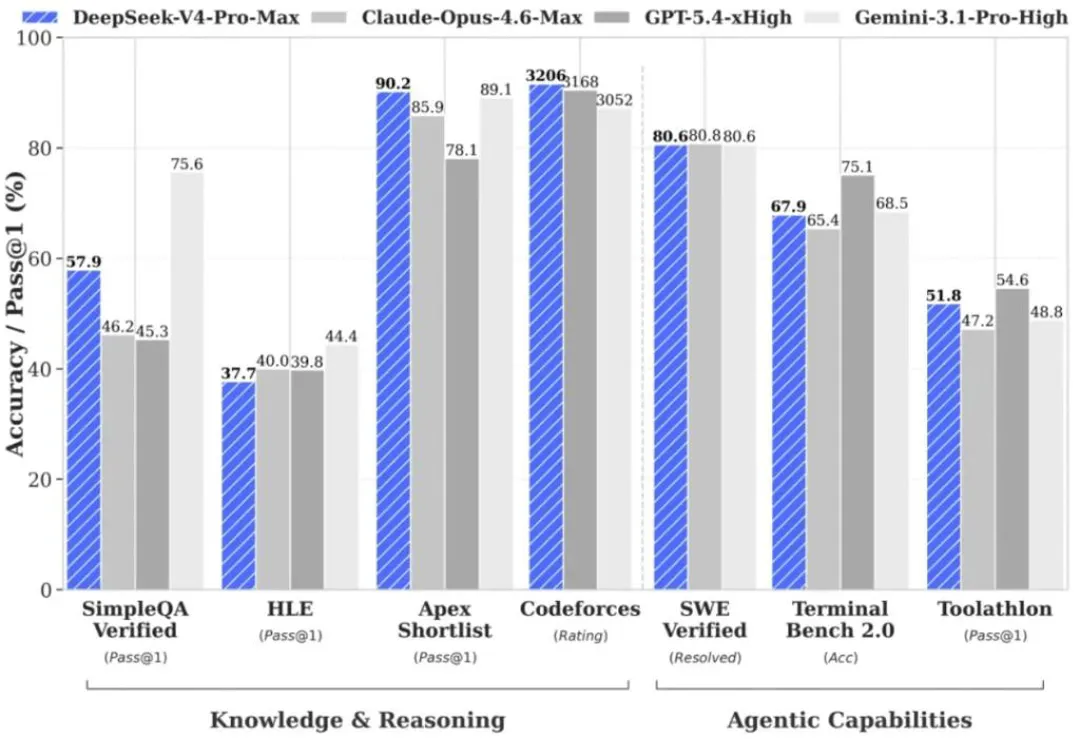
内部使用数据方面,DeepSeek表示,V4已成为公司内部员工的Agentic Coding(智能体编程)主力模型,评测反馈显示其使用体验优于Claude Sonnet 4.5,交付质量接近Opus 4.6非思考模式,但与Opus 4.6思考模式仍有一定差距。
在数学、STEM及竞赛级代码评测中,V4-Pro超越目前已公开评测的所有开源模型,包括月之暗面的Kimi K2.6 Thinking和智谱GLM-5.1 Thinking,并取得比肩顶级闭源模型的成绩。
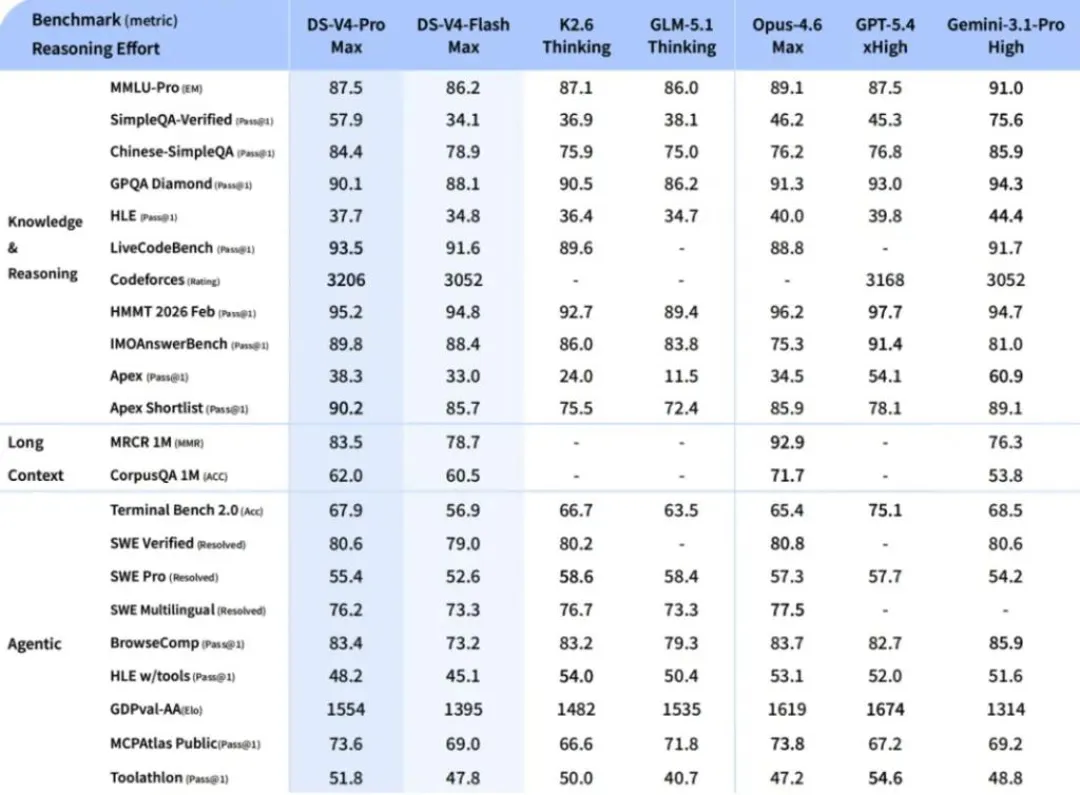
博主Simon Willison在其测评文章中指出,V4-Pro(1.6万亿参数)是目前已知最大的开源权重模型,超过Kimi K2.6(1.1万亿)、GLM-5.1(7540亿)以及DeepSeek V3.2(6850亿),为有意本地部署的企业用户提供了新的选项。
他还晒出了不同模型做出的鹈鹕图例:
这是DeepSeek-V4-Flash的鹈鹕:
至于DeepSeek-V4-Pro:


价格体系:最低仅为竞品1%,下半年仍有进一步降价空间
DeepSeek的定价策略是此次发布中最受市场关注的部分。V4-Flash的输入/输出价格分别为每百万token 0.14美元/0.28美元,低于OpenAI GPT-5.4 Nano(0.20美元/1.25美元)和Gemini 3.1 Flash-Lite(0.25美元/1.50美元),是目前小型模型中定价最低的选项。
V4-Pro的输入/输出价格为1.74美元/3.48美元,同样低于Gemini 3.1 Pro(2美元/12美元)、GPT-5.4(2.50美元/15美元)、Claude Sonnet 4.6(3美元/15美元)和Claude Opus 4.7(5美元/25美元)。
博主Simon Willison汇总的价格对比数据显示,V4-Pro是目前大型前沿模型中成本最低的选项,V4-Flash则是小型模型中成本最低的,甚至低于OpenAI的GPT-5.4 Nano。
DeepSeek将上述低价能力归因于模型在超长上下文场景下的极致效率优化。官方数据显示,在100万token场景下,V4-Pro的单token推理算力仅为V3.2的27%,KV缓存仅为10%;V4-Flash则分别低至10%和7%。
值得关注的是,DeepSeek在价格说明中附注称,"受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调",暗示当前定价仍有进一步下调空间。
技术架构:混合注意力机制突破长上下文瓶颈,适配国产算力
DeepSeek-V4的核心技术创新在于首创的"CSA(压缩稀疏注意力)+HCA(重度压缩注意力)"混合注意力架构,旨在解决传统注意力机制在超长上下文场景下呈平方级复杂度攀升、显存与算力难以工程落地的行业痛点。CSA将每4个token压缩为一个信息块并通过稀疏检索获取最相关内容,在保留中段细节的同时大幅降低计算量;HCA则将海量信息浓缩为框架级信息块,专注全局逻辑处理。
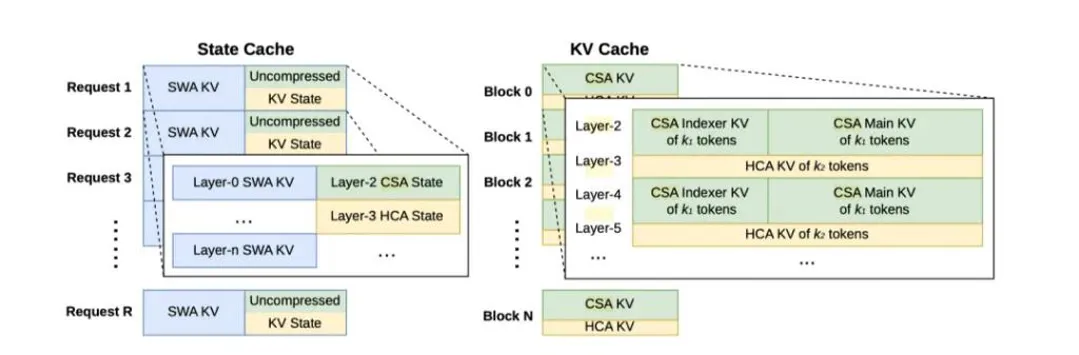
在此之外,V4还引入mHC流形约束超连接(升级传统残差连接,将信号传播约束在稳定流形上)以及Muon优化器(替代传统AdamW,适配MoE大模型与低精度训练)。官方数据显示,全链路工程优化可实现推理加速最高接近2倍。
在国产算力适配方面,DeepSeek-V4在华为昇腾NPU平台上完成细粒度专家并行优化方案的全面验证,在通用推理负载场景下可实现1.50至1.73倍的加速比。DeepSeek官方表示,V4是全球首个在国产算力底座上完成训练与推理的万亿参数级模型,但目前昇腾平台适配代码暂未对外开源,属于闭源优化。此外,寒武纪已通过vLLM推理框架完成对V4-Flash和V4-Pro的适配,相关代码已开源至GitHub社区。


