测评

让模型“看视频写网页”,GPT-5仅得36.35分!上海AI Lab联合发布首个video2code基准
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。 然而,一个网页的真正价值远不止于其静态布局。 用户的点击、筛选、表单提交,乃至游戏中的每一步操作,都构成了其核心的交互功能。

秘塔AI整大活,国内首个免费「深度研究」来了!搞研究证据链惊人
就在刚刚,国内第一家免费公开可用的「深度研究」产品来了! 这个产品,可以直接对标海外的Deep Research能力,性能十分强大。 在BrowseComp等评测集上,它们超越了上周刚开源且达到最好结果的WebSailor模型,准确率有明显提升。

AI Agent、传统聊天机器人有何区别?如何评测?这篇30页综述讲明白了
论文作者包括来自上海交通大学的朱家琛、芮仁婷、单榕、郑琮珉、西云佳、林江浩、刘卫文、俞勇、张伟楠,以及华为诺亚研究所的朱梦辉、陈渤、唐睿明。 本文第一作者是朱家琛,上海交通大学博士生,主要研究兴趣集中在大模型推理,个性化 Agent。 本文通讯作者是张伟楠,上海交通大学教授,研究方向包含强化学习、数据科学、机器人控制、推荐搜索等。

首个面向科学任务、真实交互、自动评估的多模态智能体评测环境,ScienceBoard来了
第一作者孙秋实是香港大学计算与数据科学学院博士生,硕士毕业于新加坡国立大学数据科学系。 主要研究方向为 Computer-using agents 和 Code intelligence,在 NLP 和 ML 顶会 ACL,EMNLP,ICLR,COLM 等发表多篇论文。 本文的 OS-Copilot 团队此前已发布了 OS-Atlas、OS-Genesis 和 SeeClick 等同系列电脑智能体研究成果,被广泛应用于学术界与产业实践中。

17款大模型PK八款棋牌游戏,o3-mini胜出,DeepSeek R1输在中间步骤
AI社区掀起用大模型玩游戏之风! 例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。 针对这一场景,来自港大、剑桥和北大的研究人员发布了一个更全面、客观可信的LLM评测基准:GameBoT。

DeepSeek-V3-0324 发布:更智能的编码体验,加速码农编码效率!
DeepSeek V3 迎来了全新版本的更新;消息一经发布,众多专业人士纷纷对其进行测评,结果令人惊叹不已。 尽管官方将此次升级定义为小版本更新,但在实际的编码能力测试中,其表现丝毫不逊色于大版本的 DeepSeek V4。 在此,我为大家提供一个专业的测评网址:。

探索跳跃式思维链:DeepSeek创造力垫底,Qwen系列接近人类顶尖水平
AIxiv专栏是AI在线发布学术、技术内容的栏目。 过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。 如果您有优秀的工作想要分享,欢迎投稿或者联系报道。

OpenAI首个智能体Operator大测评,你也能拥有24小时私人管家!
演唱会抢票终于不用自己蹲守了,公司订餐也可以直接「无脑托管」,这就是OpenAI今天发布的Operator。 顾名思义,Operator就是能帮你端到端处理任务的AI智能体。 比较有趣的是,OpenAI针对Operator新开了一个网页operator.chatgpt.com,而不是像之前发布的功能都直接统一内置在ChatGPT中。

揭秘大模型强推理能力幕后功臣“缺陷”,过程级奖励模型新基准来了
截止目前,o1 等强推理模型的出现证明了 PRMs(过程级奖励模型)的有效性。 (“幕后功臣” PRMs 负责评估推理过程中的每一步是否正确和有效,从而引导 LLMs 的学习方向。 )但关键问题来了:我们如何准确评估 PRMs 本身的性能?

NeurIPS 2024 | 可信大模型新挑战:噪声思维链提示下的鲁棒推理,准确率直降40%
当前,大语言模型(Large Language Model, LLM)借助上下文学习(In-context Learning)和思维链提示(Chain of Thoughts Prompting),在许多复杂推理任务上展现出了强大的能力。 然而,现有研究表明,LLM 在应对噪声输入时存在明显不足:当输入的问题包含无关内容,或者遭到轻微修改时,模型极容易受到干扰,进而偏离正确的推理方向。 如图 1 左所示,Q1 中的「We know 6 6=12 and 3 7=10 in base 10」 是关于 base-9 计算的噪声信息,该信息容易误导模型输出错误的结果。

集成500+多模态现实任务!全新MEGA-Bench评测套件:CoT对开源模型反而有害?
随着人工智能技术的进步,多模态大模型正逐渐应用于多个领域,极大地提升了机器在视觉、文本等多种信息模式下的理解和生成能力。 这些模型不仅用于对话、图片标注、视频分析等较常见的任务,还被广泛应用在复杂场景中,如程序编写、医疗影像诊断、自动驾驶、虚拟助手中的多模态交互,甚至用于游戏策略分析与操作应用程序。 然而,全面、系统地评测多模态大模型的能力需要投入大量的资源。
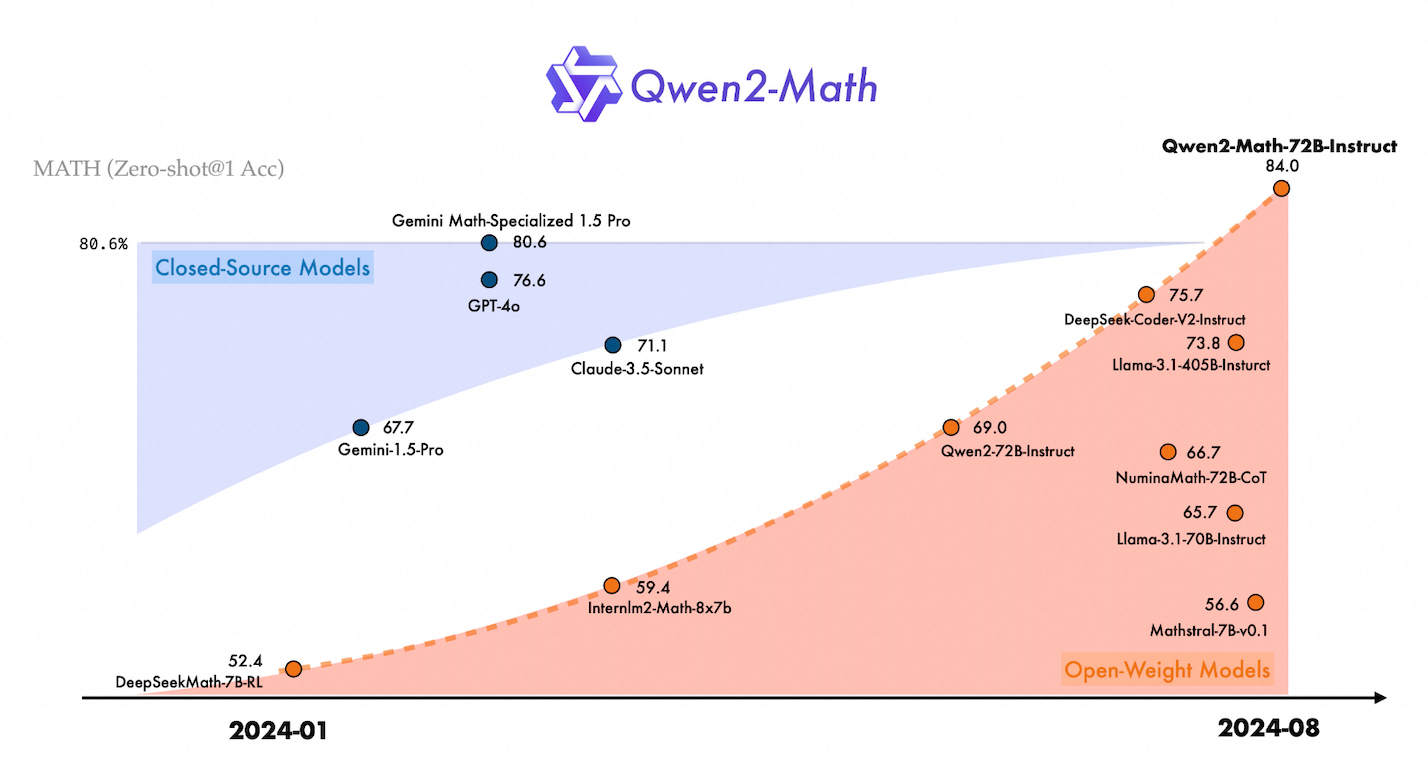
通义千问开源Qwen2-Math,成为最先进的数学专项模型
8月9日消息,阿里通义团队开源新一代数学模型Qwen2-Math,包含1.5B、7B、72B三个参数的基础模型和指令微调模型。Qwen2-Math基于通义千问开源大语言模型Qwen2研发,旗舰模型 Qwen2-Math-72B-Instruct在权威测评集MATH上的得分超越GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro、Llama-3.1-405B等,以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题,成为最先进的数学专项模型。注:在MATH基准测评中,通义千问数学模

中文多模态大模型 SuperCLUE-V 基准 8 月榜单发布,腾讯混元居首
感谢据腾讯科技今日报道,中文多模态大模型 SuperCLUE-V 基准 8 月榜单发布,腾讯混元大模型位居国内大模型首位(71.95 分)。腾讯科技方面宣称,该模型准确识别图像元素并生成自然语言描述,全方位理解并洞察细节。此次测评覆盖了 12 个国内外高代表性的多模态理解大模型,腾讯混元模型在多模态基础能力和应用能力中获得 71.95 的分数。AI在线查询得知,8 月榜单中涵盖国内外最具代表性的 12 个多模态理解大模型。腾讯混元大模型在总榜上位居第二,仅次于 GPT-4o。GPT-4o 取得 74.36 分,领跑

SuperCLUE 中文大模型基准测评2024上半年报告
SuperCLUE 发布了《中文大模型基准测评2024上半年报告》,在AI大模型发展的巨大浪潮中,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。
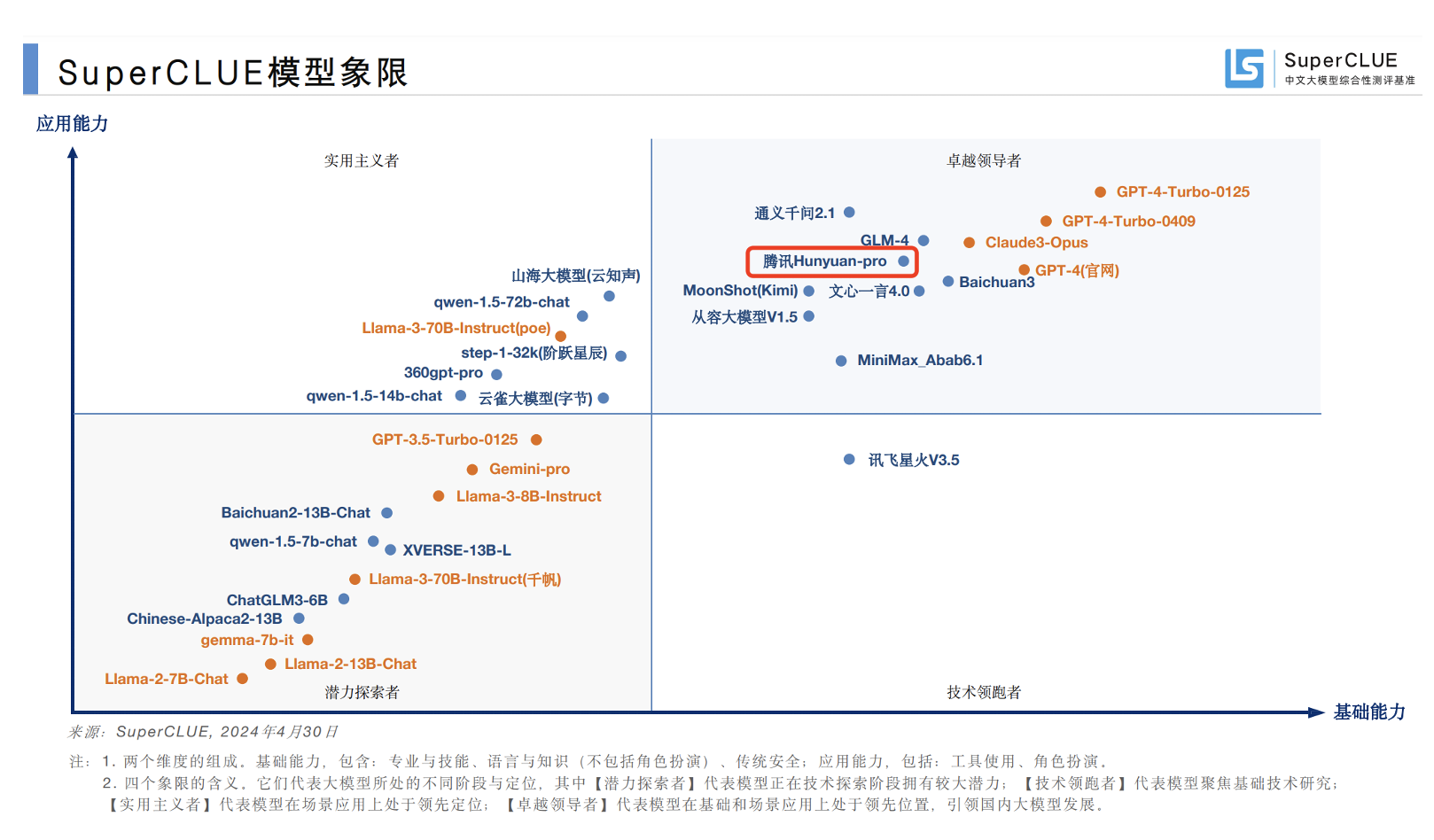
最新中文大模型测评出炉,腾讯混元居卓越领导者象限
5月6日 记者获悉,国内权威的大模型评测机构SuperCLUE最新发布了《中文大模型基准测评2024年度4月报告》。其中,腾讯混元大模型位列国内大模型第一梯队,在基础和场景应用上均处于领先位置,位于卓越领导者象限。SuperCLUE是国内权威的通用大模型综合性测评基准,其前身是知名的第三方中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)。SuperCLUE基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准,由十

最新中文大模型测评:百川智能 Baichuan 3 国内第一
感谢IT之家从百川大模型官方公众号获悉,今日国内大模型评测机构 SuperCLUE 发布了《中文大模型基准测评 2024 年度 4 月报告》,报告选取国内外具有代表性的 32 个大模型 4 月份的版本,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。报告显示,百川智能的 Baichuan 3 在国内大模型中排名第一,智谱 GLM-4、通义千问 2.1、文心一言 4.0、Moonshot (Kimi) 等大模型位列其后。从全球范围来看,国外同行的 GPT-4、Claude3 得分更胜一筹。SuperCLU
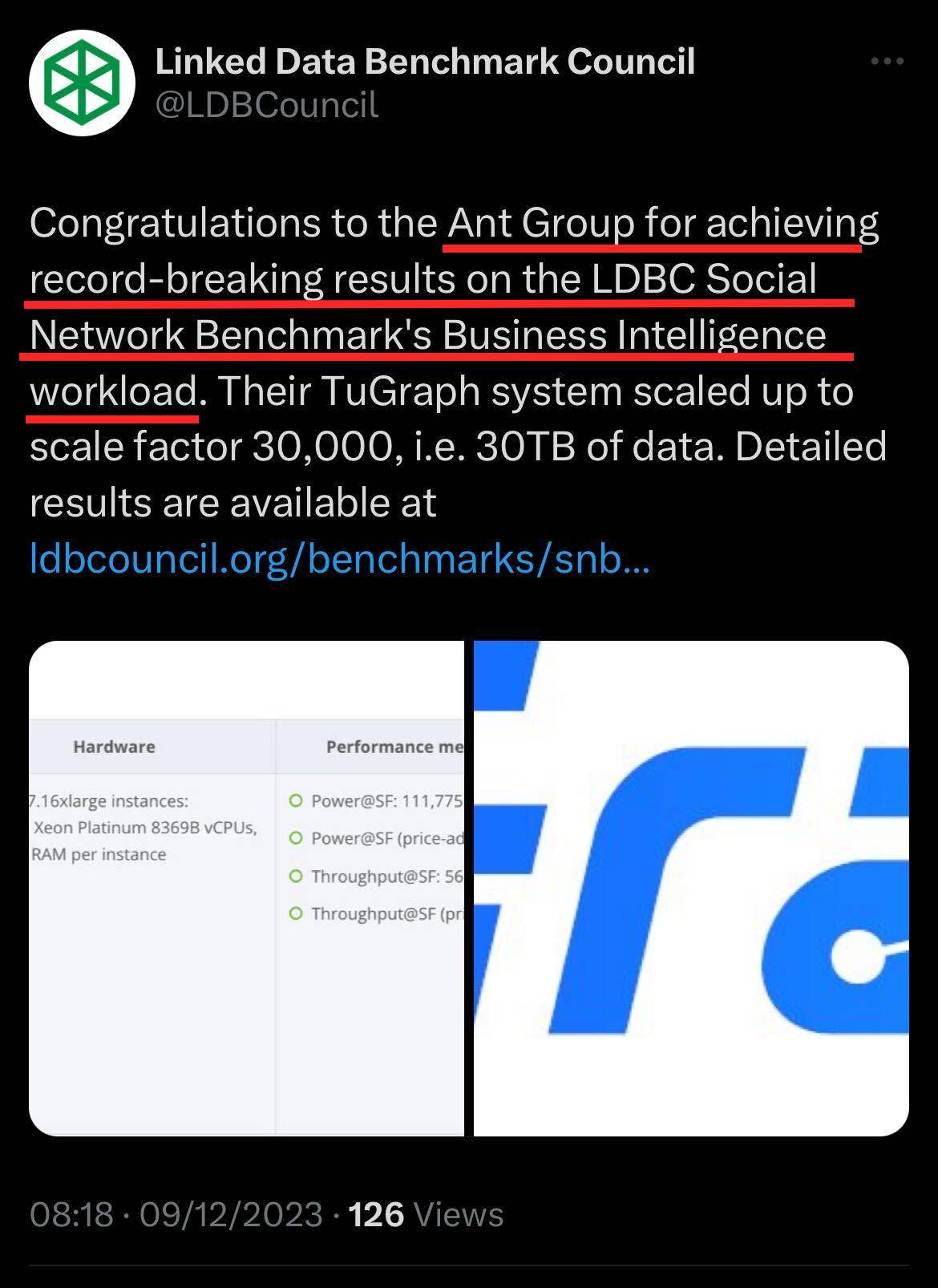
为通用人工智能提速,蚂蚁图计算连续四次打破权威测评世界纪录
近日,国际关联数据基准委员会(Linked Data Benchmark Council,以下简称LDBC)发布了图数据基准测评“LDBC SNB-BI”最新结果。由蚂蚁集团自研的流式图计算引擎TuGraph Analytics在30TB规模的数据集上成功完成了基准测试,数据规模和性能打破了此前美国某图数据库厂商的公开纪录,关键指标中的并发吞吐量提升至2.84倍,查询能力提升至1.86倍。 LDBC官方公布蚂蚁LDBC SNB-BI测评新纪录在本次测评中,测试产品需要快速导入和分析30TB 规模的数据,处理多达72
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉