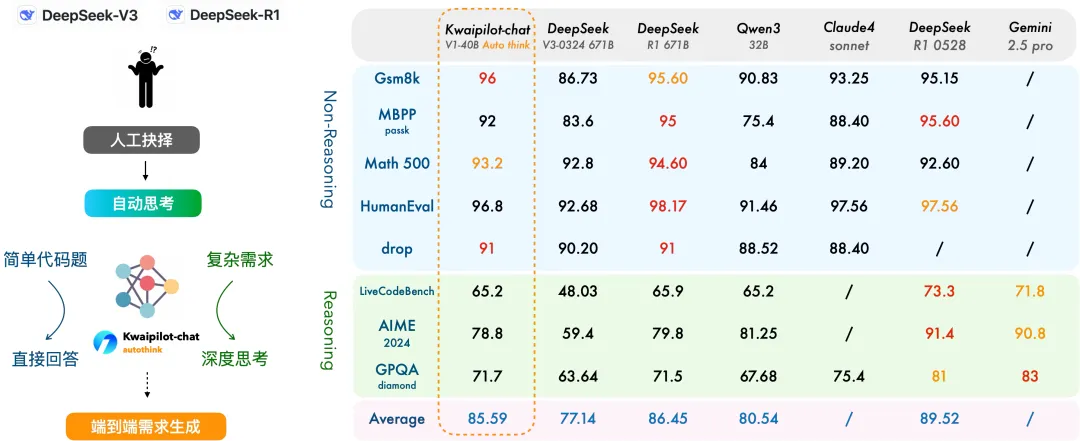
据介绍,该模型融合了“思考”和“非思考”能力,号称“DeepSeek-V3 & R1 合体”,具备根据问题难度自动切换思考形态的能力。通过进行这种思考形态训练,模型在多个“思考”和“非思考”评测榜单上均实现了性能提升,其中在部分代码和数学类的任务上,开启自动思考模式下的模型得分提升高达 20 分左右。官方表示,在部分榜单中,即使模型没有开启思考模式,受益于更优的推理形态,性能也有小幅上涨。
快手技术表示,Kwaipilot 未来将基于 preview 版本模型,进一步增强推理能力,支持更完善的思考中工具使用能力,也会将全部技术细节、训练方法开源。AI在线附模型开源地址:
https://huggingface.co/Kwaipilot/KwaiCoder-AutoThink-preview