一、背景
在现实生活中,我们常常需要解决各种复杂的多步推理问题,这些问题往往需要从多个网页中获取信息,并进行综合分析和推理才能得出答案。例如,当我们想要了解某个历史事件的详细经过时,可能需要查阅多个不同来源的网页,对比和分析其中的信息,才能还原事件的全貌。这种复杂的信息检索任务,对于传统的搜索引擎来说是非常困难的,因为它们通常只能提供单步的搜索结果,而无法像人类一样进行多步的推理和决策。
近年来,随着大型语言模型(LLMs)和大型推理模型(LRMs)的发展,人们开始尝试将这些模型应用于信息检索任务中。然而,这些模型在处理复杂的多步推理任务时,仍然存在一些局限性。例如,直接利用提示工程技术来引导这些模型执行复杂任务,往往无法充分利用模型的推理能力;而将搜索或浏览能力整合到智能体中,虽然可以通过监督微调(SFT)或强化学习(RL)来训练,但现有的训练数据集相对简单,无法涵盖现实世界中的复杂挑战。
为了解决这些问题,WebDancer应运而生。它基于ReAct框架,通过一种数据驱动和分阶段训练的方法,构建了一个能够自主进行多步信息检索的智能体。WebDancer的出现,标志着我们在自主智能体领域,训练类DeepResearch的模型迈出了重要的一步。
二、WebDancer的核心技术
WebDancer的核心创新体现在三个层面:
- 数据合成的层次化设计:通过两种方法来合成数据集实现了兼顾“广度覆盖”与“深度升级”的数据集体系,解决了传统数据集规模小、场景单一的问题。实验表明,混合使用两类数据集可使模型在GAIA基准的Pass@1指标显著提升。
- 长短推理链的协同训练:提出将LLM生成的短推理链与LRM生成的长推理链结合,通过拒绝采样机制融合不同粒度的推理模式。消融实验显示,长推理链对复杂问题(GAIA Level 3)的解决率有显著贡献,验证了多尺度推理的必要性。
- 动态采样的强化学习策略:DAPO算法通过过滤准确率极端的样本(0或1),聚焦难样本的迭代优化,使RL阶段的数据利用效率显著提升。
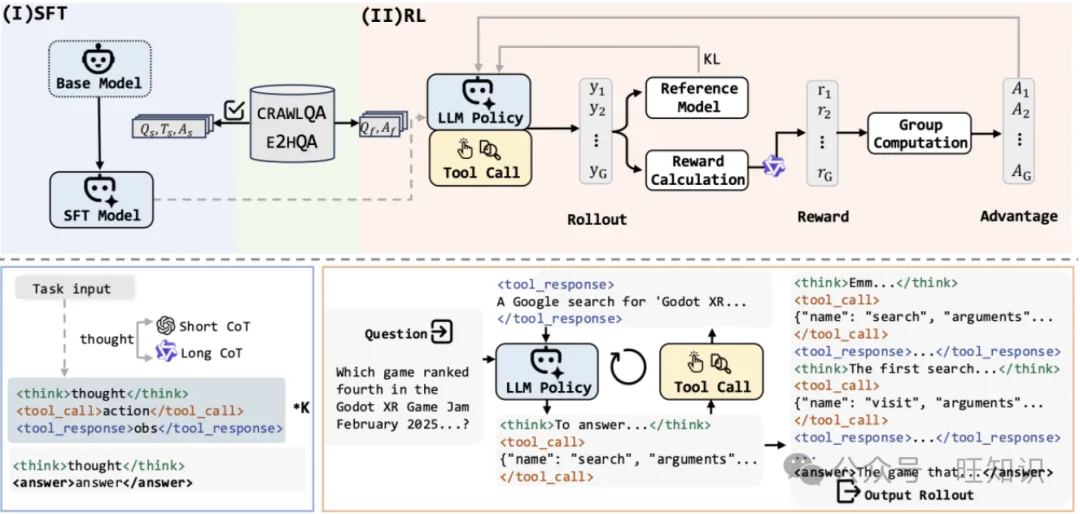
具体来说,WebDancer的构建过程可以分为四个关键阶段:浏览数据构建、轨迹采样、监督微调以及强化学习。
(一)浏览数据构建
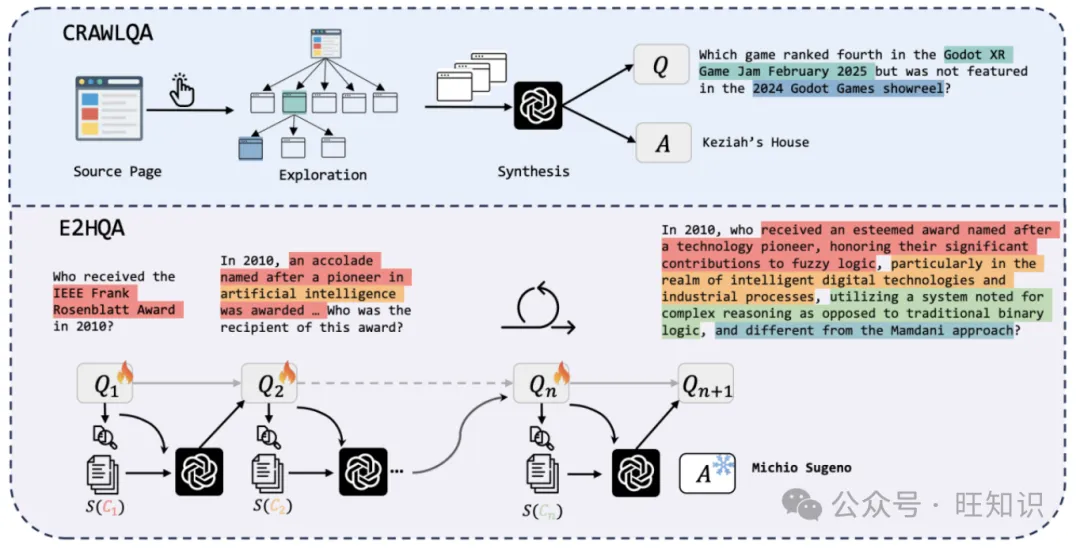
为了训练WebDancer,首先需要构建高质量的浏览数据。这些数据需要反映多样化的用户意图和丰富的交互上下文。WebDancer采用了两种方法来合成数据集:CRAWLQA和E2HQA。
CRAWLQA通过爬取网页来构建基于网页信息的问答对。它从一些富含知识的网站(如arxiv、github、wiki等)的source页面开始,模拟人类的浏览行为,递归地导航到子页面,并收集页面上的信息。然后,利用GPT-4o等大型语言模型,根据收集到的信息生成合成的问答对。这些问答对涵盖了多种类型的问题,如计数问题、多跳问题和交集问题等,能够有效地激发模型的多步推理能力。
 图片
图片
E2HQA则采用了一种从简单到复杂的问答对合成方法。它从简单的问答对开始,通过逐步增加问题的复杂性,将简单的问题转化为复杂的多步问题。具体来说,它首先从简单的问题中选择一个实体,然后利用搜索引擎获取与该实体相关的信息,并根据这些信息重新构造问题。通过这种方式,可以逐步将一个简单的问题转化为一个需要多步推理才能解决的复杂问题。
(二)轨迹采样
在构建了高质量的问答对之后,WebDancer需要采样出高质量的轨迹来指导智能体的学习过程。轨迹采样采用了拒绝采样方法,结合了短链思考(Short-CoT)和长链思考(Long-CoT)两种策略。
短链思考轨迹是通过直接利用ReAct框架,使用强大的模型(如GPT-4o)来收集的。而长链思考轨迹则是通过逐步提供历史动作和观察结果给推理模型(如QwQ-Plus),让模型自主决定下一步的动作。在采样过程中,会进行多次拒绝采样,以确保生成的轨迹的质量和连贯性。
(三)监督微调
监督微调阶段的目的是让模型适应智能体任务的格式和环境。在这个阶段,WebDancer利用前面采样得到的高质量轨迹,对模型进行微调。通过这种方式,模型能够学习到如何在智能体任务中交替进行推理和行动,从而更好地完成多步信息检索任务。
(四)强化学习
强化学习阶段的目标是将智能体能力内化到推理模型中,增强模型在多步、多工具使用场景下的能力。WebDancer采用了Decoupled Clip and Dynamic Sampling Policy Optimization(DAPO)算法来进行强化学习。DAPO算法通过动态采样机制,有效地利用了在监督微调阶段未充分利用的问答对,提高了数据效率和策略的鲁棒性。
 图片
图片
三、WebDancer的实验结果
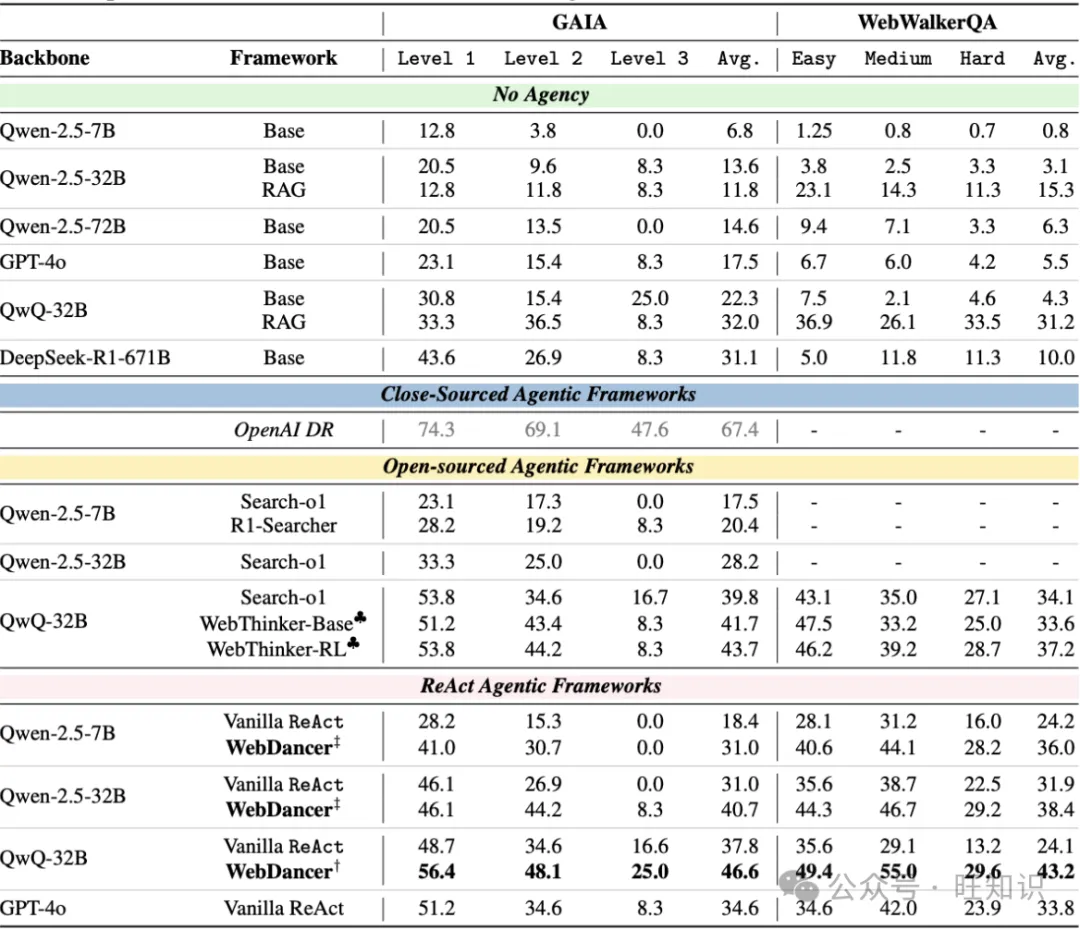
WebDancer在两个具有挑战性的信息检索基准测试——GAIA和WebWalkerQA上进行了实验评估。实验结果表明,WebDancer在这些基准测试中取得了显著的性能提升,证明了其训练范式的有效性。 我们表现最佳的模型在GAIA基准测试中达到了61.1%的Pass@3分数,在WebWalkerQA基准测试中达到了54.6%的Pass@3分数。
 图片
图片
四、未来展望:WebDancer 的新征程
尽管 WebDancer 已经取得了令人瞩目的成就,但它的发展之路还远未结束。未来,WebDancer 将在多个方向上继续探索和创新。
(一)更多工具的集成
目前,WebDancer 仅集成了两种基本的信息检索工具,未来计划引入更多复杂的工具,如浏览器建模和 Python 沙盒环境。这些工具将使智能体能够执行更复杂的任务,如网页浏览、数据抓取、API 调用等,从而拓展智能体的能力边界,使其能够应对更广泛的挑战。
(二)任务泛化与基准扩展
目前的实验主要集中在短答案信息检索任务上,未来 WebDancer 将扩展到开放域的长文本写作任务。这将对智能体的推理能力和生成能力提出更高的要求,需要设计更可靠和更有效的奖励信号。同时,WebDancer 也将参与更多基准测试,以验证其在不同任务类型和领域中的泛化能力。
五、讨论:Post-train Agentic Models
相比于一些驱动于强大的具有很强的agentic能力的闭源模型,例如gpt-o4,claude的promtpting工程框架,本研究的侧重点在从头训练一个具有强大agent能力的模型,这对于实现agent model的开源以及推进我们对agent在开放系统中如何产生和scale的基本理解至关重要。我们使用的的原生ReAct框架秉持着简洁性,体现了大道至简的原则。 Agentic models是指那些在交互式环境中,天生支持推理、决策以及多步骤工具使用的foundation models。这些模型仅通过任务描述的提示,就能展现出诸如规划、自我反思以及行动执行等突发性能力(emergent capabilities)。 近期的 DeepSearch 和 Deep Research 等系统,展示了强大的底层模型如何作为智能体的核心,通过其对工具调用和迭代推理的天然支持,实现自主的网络交互。然而,由于网络环境本质上是动态的且部分可观察的,强化学习在提升智能体的适应性和鲁棒性方面发挥了关键作用。在本研究中,我们的目标是通过有针对性的后训练(post-training),在开源模型中激发自主智能体的能力。
六、WebDancer的意义与展望
WebDancer的出现,不仅为解决复杂的多步信息检索问题提供了一种新的方法,也为自主智能体的研究和发展提供了重要的启示。通过数据驱动和分阶段训练的方法,WebDancer成功地构建了一个能够自主进行多步信息检索的智能体,为未来智能体的发展提供了新的思路和方向。
WebDancer与Deep Research在目标上具有一致性,如果通过更系统化的方法来构建和训练智能体,使其能够更好地适应复杂的网络环境仍是一个开放并且具有挑战的课题。
总之,WebDancer的出现为我们解决复杂的网络信息检索问题提供了一种新的可能性。随着技术的不断发展和完善,我们有理由相信,未来的自主智能体将在更多的领域发挥重要作用,为我们的生活和工作带来更多的便利和创新。
参考资料
- 《WebDancer: Towards Autonomous Information Seeking Agency》,Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou,阿里巴巴通义实验室,https://arxiv.org/pdf/2505.22648
- 《ReAct: Synergizing Reasoning and Acting in Language Models》,Shunyu Yao等,普林斯顿大学,https://arxiv.org/abs/2210.03629
- 《GAIA: A Benchmark for General AI Assistants》,Grégoire Mialon等,Meta AI,https://arxiv.org/abs/2311.12983


