当你构建一个大规模AI系统时,你其实是在把不同的代理设计模式组合起来。每个模式都有自己的阶段、构建方法、输出和评估。如果我们退一步,把这些模式归类,它们可以分成17种高层架构,这些架构捕捉了代理系统可能采用的主要形式……
- Multi-Agent System,在这个系统中,几个工具和代理一起合作来解决问题。
- Ensemble Decision System,在这个系统中,多个代理各自提出一个答案,然后投票选出最好的那个。
- Tree-of-Thoughts,在这个系统中,代理会探索很多不同的推理路径,然后选择最有前景的方向。
- Reflexive approach,在这个方法中,代理能够认识到并承认自己不知道的东西。
- ReAct loop,在这个循环中,代理会在思考、采取行动,然后再思考来完善它的过程之间交替。 还有很多其他……
在这篇博客里,我们要拆解这些不同的代理架构,并展示每个架构在完整AI系统中扮演的独特角色。
我们会视觉化地理解每个架构的重要性,编码它的工作流程,并评估它,看看它是否真的比基准性能有所提升。
所有代码都在我的GitHub仓库里可用:
GitHub - https://github.com/FareedKhan-dev/all-agentic-architectures
目录
- 设置环境
- Reflection
- Tool Using
- ReAct (Reason + Act)
- Planning
- PEV (Planner-Executor-Verifier)
- Tree-of-Thoughts (ToT)
- Multi-Agent Systems
- Meta-Controller
- Blackboard
- Ensemble Decision-Making
- Episodic + Semantic Memory
- Graph (World-Model) Memory
- Self-Improvement Loop (RLHF Analogy)
- Dry-Run Harness
- Simulator (Mental-Model-in-the-Loop)
- Reflexive Metacognitive
- Cellular Automata
- 将架构组合在一起
设置环境
在我们开始构建每个架构之前,我们需要设置基础,并清楚我们用的是什么,为什么用这些模块、模型,以及它们如何组合在一起。
我们知道LangChain、LangGraph和LangSmith基本上是行业标准模块,用来构建任何严肃的RAG或代理系统。它们给我们提供了构建、编排所需的一切,最重要的是,当事情变得复杂时,能搞清楚代理内部发生了什么,所以我们就坚持用这三个。
第一步是导入我们的核心库。这样,我们以后就不用重复了,设置保持干净整洁。来做吧。
复制所以,来快速拆解一下为什么我们用这三个。
LangChain是我们的工具箱,给我们核心构建块,比如prompts、工具定义和LLM wrappers。 LangGraph是我们的编排引擎,把一切连成复杂的流程,有循环和分支。 LangSmith是我们的调试器,展示代理每一步的可视化追踪,这样我们能快速发现和修复问题。 我们会用像Nebius AI或Together AI这样的提供商来处理开源LLMs。好处是它们就像标准OpenAI模块一样工作,所以我们不用改太多就能上手。如果我们想本地运行,我们可以换成像Ollama这样的东西。
为了确保我们的代理不局限于静态数据,我们给它们访问Tavily API来做实时网页搜索(每月1000积分够测试了)。这样,它们能主动出去找信息,保持焦点在真正的推理和工具使用上。
接下来,我们需要设置环境变量。这里是我们放敏感信息的地方,比如API键。要做这个,在同一个目录创建一个叫.env的文件,把你的键放进去,比如:
复制一旦.env文件设置好,我们可以用之前导入的dotenv模块轻松把那些键拉进我们的代码。
复制现在,我们的基本设置准备好了,我们可以开始一个一个构建每个架构,看看它们的表现,以及在大规模AI系统中它们最适合哪里。
Reflection
所以,我们要看的第一个架构是Reflection。这个可能是你在代理工作流程中最常见和基础的模式了。
它就是让代理能够退一步,看看自己的工作,然后把它做得更好。
在大规模AI系统中,这个模式完美适合任何阶段,那里生成输出的质量很关键。想想像生成复杂代码、写详细技术报告这样的任务,任何地方一个简单的初稿答案都不够好,可能导致现实问题。
来理解一下过程怎么流动的。
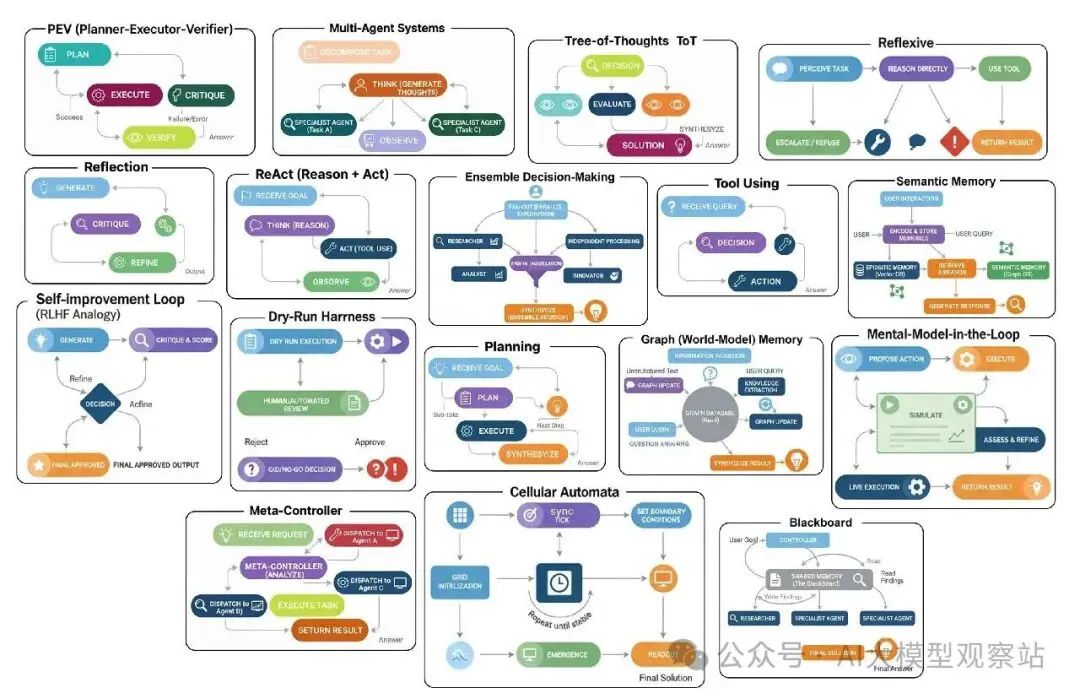
 图片
图片
- Generate: 代理拿用户prompt,产生一个初始草案或解决方案。这是它第一次、未过滤的尝试。
- Critique: 然后代理切换角色,成为自己的批评者。它分析草案找缺陷,问像“是这个正确吗?”、“这个高效吗?”或“我漏了什么?”这样的问题。
- Refine: 最后,用自己的批评,代理生成一个最终的、改进版本的输出,直接解决它发现的缺陷。
在我们创建代理逻辑之前,我们需要定义它要用的数据结构。用Pydantic模型是强迫LLM给我们干净、结构化JSON输出的好办法,这对多步过程很重要,一个步骤的输出成为下一个的输入。
复制用这些schema,我们有了一个清晰的‘合同’给我们的LLM。Critique模型特别有用,因为它强迫一个结构化审查,问特定检查错误和效率,而不是模糊的“审查代码”命令。
首先是我们的generator_node。它唯一的工作是拿用户请求,产生那个初稿。
复制这个节点会给我们初稿和它的解释,然后我们传给批评者审查。
现在是Reflection过程的核心,critic_node。这里代理进入资深开发者角色,给自己的工作一个严格的代码审查。
复制这里的输出是一个结构化的Critique对象。这比模糊的“这个可以改进”消息好多了,因为它给我们的下一步提供了具体、可行动的反馈。
我们逻辑的最后一块是refiner_node。它拿原稿和编辑的反馈,创建最终的、改进版本。
复制好了,我们有三个逻辑部分了。现在,我们需要把它们连成一个工作流程。这就是LangGraph的用武之地。我们会定义在节点间传递的状态,然后构建图本身。
复制流程是一个简单的直线:generator -> critic -> refiner。这是经典的Reflection模式,现在我们准备测试它了。
 图片
图片
为了测试这个工作流程,我们给它一个经典的编码问题,那里一个天真的初次尝试往往低效,找第n个Fibonacci数。这是一个完美的测试案例,因为一个简单的递归解决方案容易写,但计算上很贵,留下了很多改进空间。
复制来看看前后对比,看看我们的代理做了什么。
复制初稿是一个简单的递归函数,没错,但效率极差。批评者指出了指数复杂度和其他问题。精炼代码是一个聪明得多、更健壮的迭代解决方案。这就是模式按预期工作的完美例子。
为了让这个更具体,我们引入另一个LLM作为公正的‘法官’,给初稿和最终代码打分。这会给我们一个定量的改进度量。
复制当我们运行法官对两个版本时,分数告诉了整个故事。
复制初稿的分数很差,特别是效率。精炼代码在各方面都有巨大提升。
这给了我们硬证据,reflection过程不只是改变了代码,它让它变得更好一些。
Tool Using
我们刚建的Reflection模式很棒,用于 sharpening 一个代理的内部推理。
但如果代理需要它不知道的信息,会发生什么?
没有外部工具访问,一个LLM局限于它的预训练参数,它可以生成和推理,但不能查询新数据或与外部世界互动。这就是我们的第二个架构,Tool Use,进来的地方。
在任何大规模AI系统中,tool use不是可选的,而是重要的和必需的组件。它是代理推理和真实世界数据之间的桥梁。不管是一个支持机器人检查订单状态,还是一个金融代理拉取实时股票价格。
来理解一下过程怎么流动的。
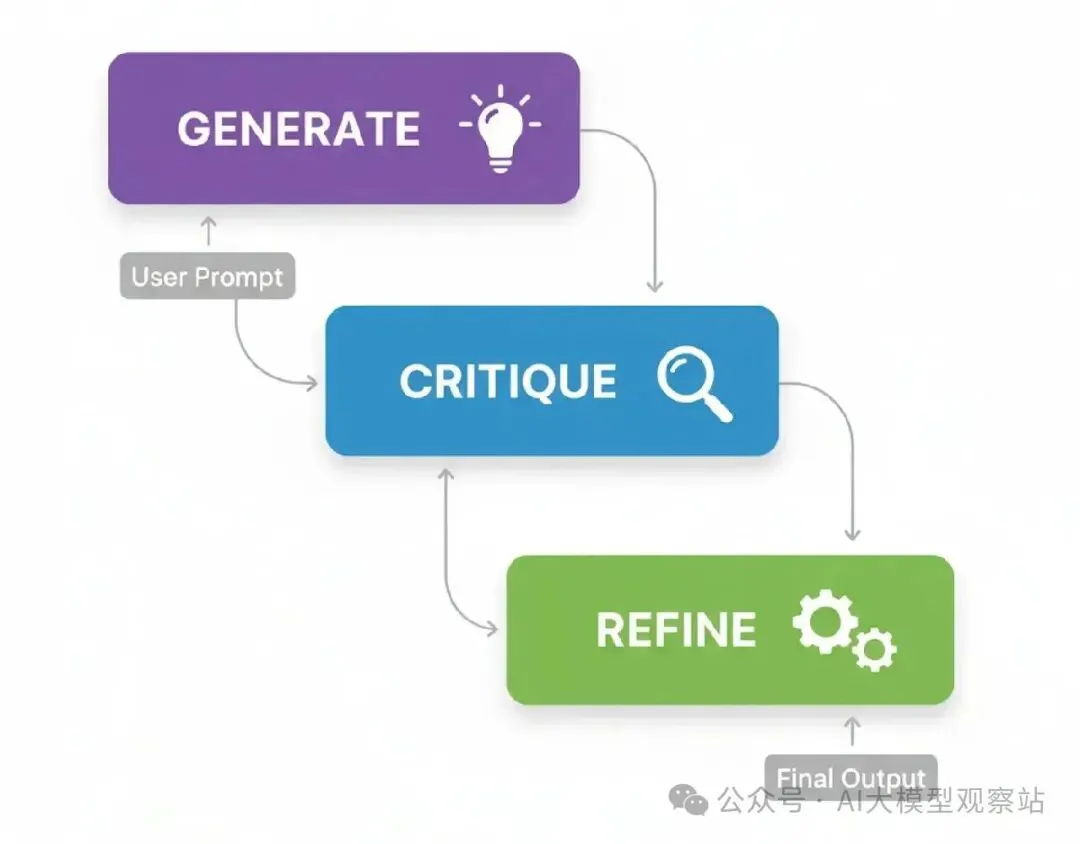
 图片
图片
- Receive Query: 代理从用户那里得到一个请求。
- Decision: 代理分析查询,看看它可用的工具。然后决定是否需要一个工具来准确回答问题。
- Action: 如果需要一个工具,代理格式化一个调用那个工具的请求,比如,一个特定函数带正确的参数。
- Observation: 系统执行工具调用,结果(“观察”)被发回给代理。 Synthesis: 代理拿工具的输出,结合它自己的推理,生成一个最终的、基于事实的答案给用户。
为了构建这个,我们需要给我们的代理一个工具。为此,我们会用TavilySearchResults工具,它给我们的代理访问网页搜索的能力。这里最重要的部分是描述。LLM读这个自然语言描述来搞清楚工具做什么,以及什么时候该用它,所以让它清晰和精确是关键。
现在我们有一个功能的工具,我们可以构建会学着用它的代理。一个tool-using代理的状态挺简单的,就是一个消息列表,跟踪整个对话历史。
接下来,我们必须让LLM“知道”我们给了它工具。这是关键一步。我们用.bind_tools()方法,它本质上把工具的名字和描述注入到LLM的系统prompt中,让它决定什么时候调用工具。
复制现在我们可以定义我们的代理工作流程,用LangGraph。我们需要两个主要节点:agent_node(“大脑”)调用LLM决定做什么,和tool_node(“手”)实际执行工具。
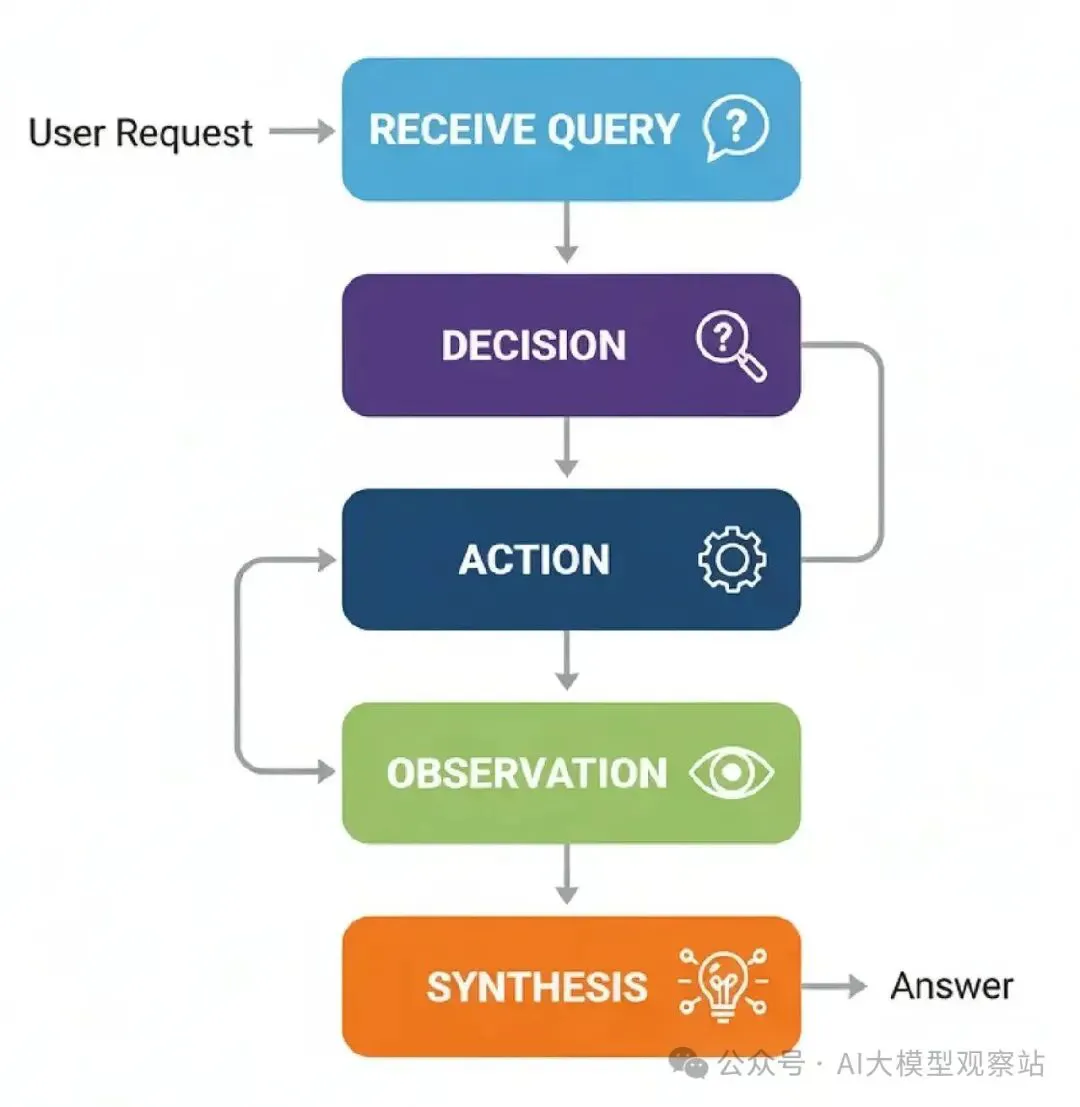
复制在agent_node运行后,我们需要一个路由器决定下一步去哪。如果代理的最后消息包含tool_calls属性,意味着它想用工具,所以我们路由到tool_node。如果没有,意味着代理有一个最终答案,我们可以结束工作流程。
复制好了,我们有所有部分了。来把它们连成一个图。这里关键是条件边,用我们的router_function创建代理的主要推理循环:agent -> router -> tool -> agent。
复制 图片
图片
现在来测试它。我们给它一个它从训练数据不可能知道的问题,强迫它用网页搜索工具找实时答案。
复制来看输出,看看代理的思考过程。
复制追踪清楚展示了代理的逻辑:
首先,agent_node思考,决定需要搜索网页,输出一个tool_calls请求。 接下来,tool_node执行那个搜索,返回一个ToolMessage带原始网页结果。 最后,agent_node再运行,这次拿搜索结果作为上下文来合成一个最终的、有帮助的答案给用户。 为了形式化这个,我们再引入我们的LLM-as-a-Judge,但用特定于评估tool use的标准。
复制当我们运行法官对整个对话追踪时,我们得到一个结构化的评估。
复制高分给我们证据,我们的代理不只是调用工具,而是有效使用它。
它正确识别了什么时候搜索、搜什么,以及怎么用结果。这个架构几乎是任何实用AI助手的基礎构建块。
ReAct (Reason + Act)
我们的上一个代理是个大进步。它可以用工具取实时数据,这很棒。但问题是,它有点一锤子买卖,它决定需要一个工具,调用一次,然后试着回答。
但如果问题更复杂,需要多个、依赖的步骤来解决,会发生什么?
ReAct (Reason + Act)就是创建一个循环。它让代理动态推理下一步做什么,采取行动(像调用工具),观察结果,然后用那个新信息再推理。它是从静态工具调用者到适应性问题解决者的转变。
在任何AI系统中,ReAct是你处理任何需要multi-hop推理的任务的首选模式。
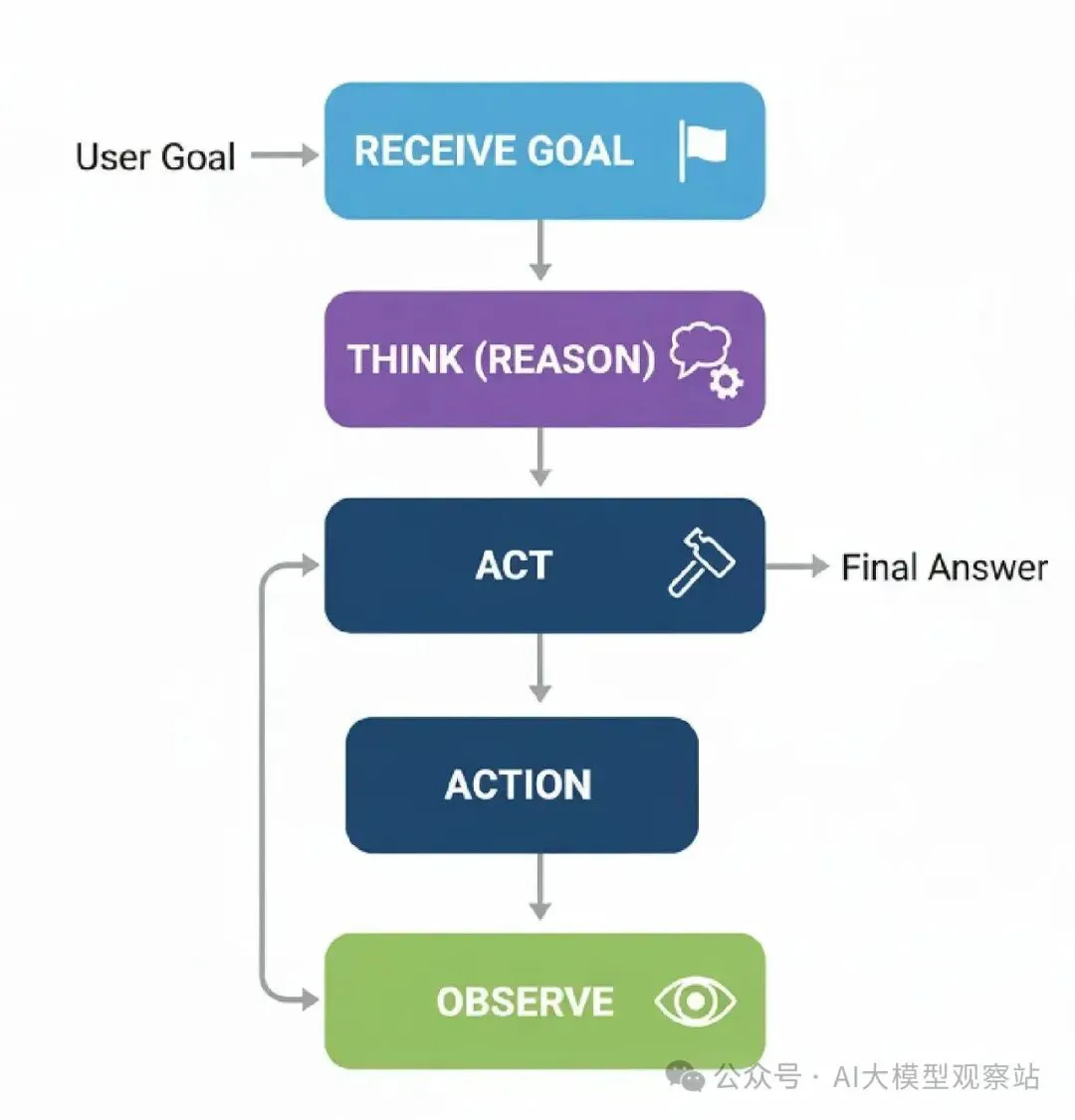
来理解一下过程怎么流动的。
 图片
图片
- Receive Goal: 代理被给一个不能一步解决的复杂任务。
- T- hink (Reason): 代理生成一个想法,像:“要回答这个,我先需要找信息X”。
- Act: 基于那个想法,它执行一个行动,像调用搜索工具找‘X’。
- Observe: 代理从工具得到‘X’的结果回来。
- Repeat: 它拿那个新信息,回第2步,想:“好了,现在我有X,我需要用它找Y”。这个循环继续,直到最终目标达成。
好消息是,我们已经建了大部分部分。我们会重用AgentState、web_search和tool_node。我们图逻辑的唯一变化:在tool_node运行后,我们把输出发回给agent_node而不是结束。这创建了推理循环,让代理审查结果并选择下一步。
复制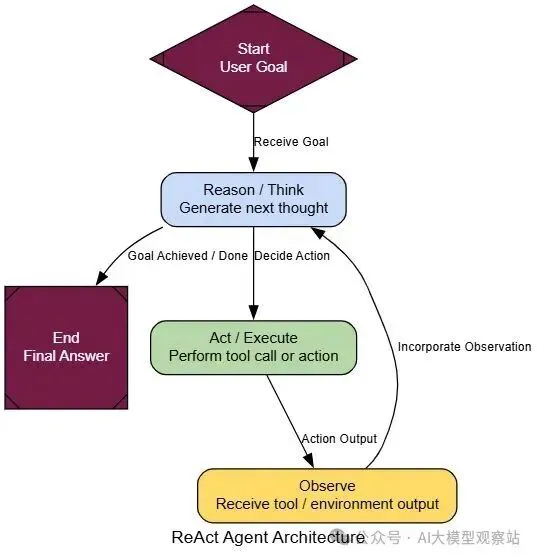 图片
图片
就这了。唯一真正的变化是react_graph_builder.add_edge("tools", "agent")。那一行创建了循环,把我们的简单tool-user变成一个动态ReAct代理。
为了看到为什么这个循环这么强大,来给它一个不可能一击解决的任务,一个经典的multi-hop问题。一个简单的tool-using代理会失败这个,因为它不能把步骤链起来。
复制复制当我们运行这个时,代理的执行追踪显示了一个远更智能的过程。它不只是做一个搜索。相反,它推理它的方式通过问题:
Thought 1: “First, I need to find out which company made the movie ‘Dune’.”
Action 1: It calls web_search('production company for Dune movie').
Observation 1: It gets back “Legendary Entertainment”.
Thought 2: “Okay, now I need the CEO of Legendary Entertainment.”
Action 2: It calls web_search('CEO of Legendary Entertainment') and so on, until it has all the pieces.
为了形式化改进,我们可以用我们的LLM-as-a-Judge,这次焦点在任务完成上。
复制来看分数。一个基本代理试这个任务会得很低分,因为它会失败收集所有所需信息。但我们的ReAct代理表现好多了。
--- Evaluating ReAct Agent's Output --- { 'task_completion_score': 8, 'reasoning_quality_score': 9, 'justification': "The agent correctly broke down the problem into multiple steps... It successfully identified the company, then the CEO. While it struggled to find the budget for the most recent film, its reasoning process was sound and it completed most of the task." }
我们可以看到reasoning_quality_score确认了它的步步过程是逻辑的,并被我们的法官(LLM)验证。
ReAct模式给代理能力处理这些需要动态思考的复杂、multi-hop问题。
Planning
ReAct模式对探索问题和即时搞清楚东西很棒。但对步骤可预测的任务,它可能有点低效。它像一个人每次问一个转弯的方向,而不是先看全地图。这就是Planning架构进来的地方。
这个模式引入了一个关键的预见层。
而不是步步反应,一个planning代理先创建一个完整的‘作战计划’,然后才采取任何行动。
在AI系统中,Planning是你处理任何结构化、多步过程的工作马。想想数据处理管道、报告生成,或任何你提前知道操作序列的工作流程。它带来可预测性和效率,让代理的行为更容易追踪和调试。
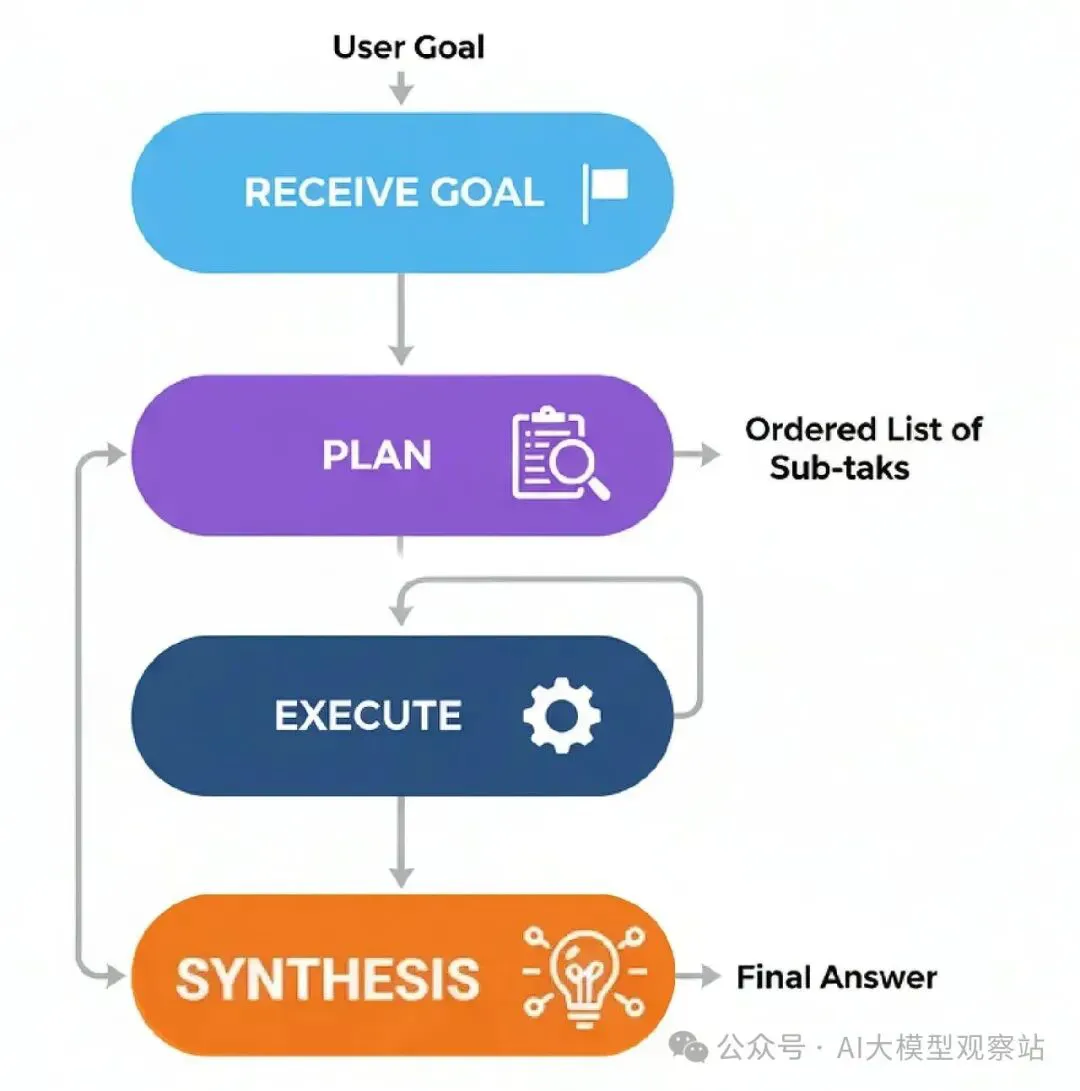
来理解一下过程怎么流动的。
 图片
图片
- Receive Goal: 代理被给一个复杂任务。
- Plan: 一个专用的‘Planner’组件分析目标,生成一个有序的子任务列表来实现它。比如:["Find fact A", "Find fact B", "Calculate C using A and B"]。
- Execute: 一个‘Executor’组件拿计划,按顺序执行每个子任务,需要时用工具。
- Synthesize: 一旦计划所有步骤完成,一个最终组件把执行步骤的结果组装成一个连贯的最终答案。
来开始构建它。
我们会创建三个核心组件:一个planner_node来创建策略,一个executor_node来执行它,和一个synthesizer_node来组装最终报告。
首先,我们需要一个专用的planner_node。这里关键是一个非常明确的prompt,告诉LLM它的工作是创建一个简单、可执行步骤的列表。
复制接下来,executor_node。这是一个简单的工人,只拿计划的下一步,运行工具,把结果加到我们的状态。
复制现在我们只需把它们连在图里。一个路由器会检查计划里是否还有步骤。如果有,它循环回executor。如果没有,它移到最终synthesizer_node(我们可以从之前模式重用)来生成答案。
复制
为了真正看到区别,来给我们的代理一个从预见受益的任务。一个ReAct代理能解决这个,但它的步步过程不太直接。
复制过程的区别立即明显。我们的代理做的第一件事就是铺开它的整个策略。
复制代理在采取一个行动前创建了一个完整的、明确的计划。然后它有条不紊地执行这个计划。这个过程更透明和健壮,因为它在遵循一组清晰的指令。
为了形式化这个,我们会用我们的LLM-as-a-Judge,但这次我们评分过程的效率。
复制当被评估时,Planning代理在它的直接性上闪耀。
复制我们得到好分数,意味着我们的方法确实创建了一个正确的planning系统,所以……
当解决方案路径可预测时,Planning提供了一个比纯反应式更结构化和高效的方法。
PEV (Planner-Executor-Verifier)
我们的Planning代理当路径清晰时工作得很好,它做一个计划并跟随它。但有个隐藏假设……
如果事情出错,会发生什么?如果一个工具失败,一个API挂了,或搜索返回垃圾,一个标准planner就只是把错误传下去,以失败或胡说结束。
PEV (Planner-Executor-Verifier)架构是对Planning模式的一个简单但强大的升级,它加了一个关键的质量控制和自我修正层。
PEV对构建健壮和可靠的工作流程很重要。你在任何代理与可能不可靠的外部工具互动的地方用它。
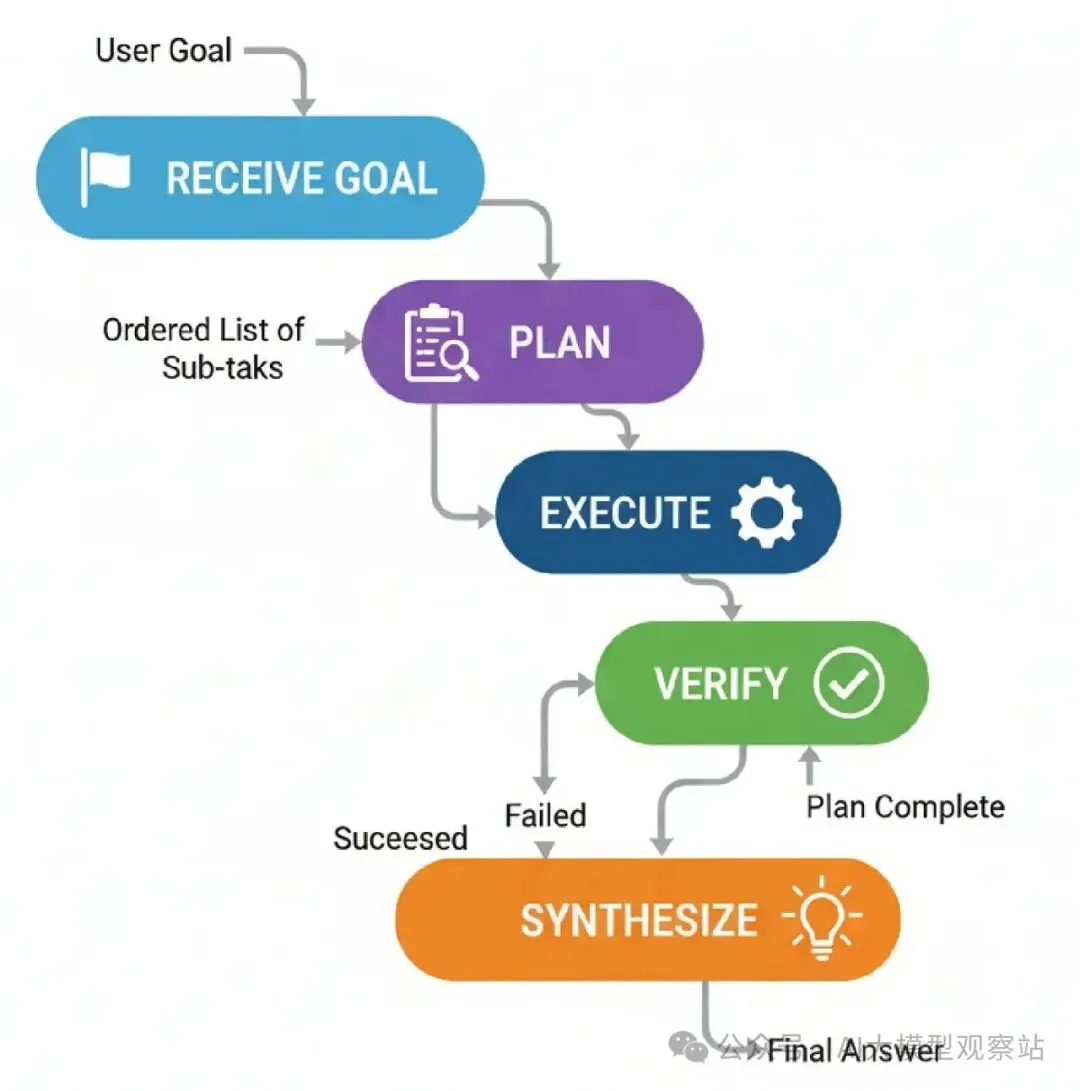
这是它怎么工作的……
 图片
图片
- Plan: 一个‘Planner’代理创建一个步骤序列,就像之前一样。
- Execute: 一个‘Executor’代理拿计划的下一步,调用工具。
- Verify: 这是新步骤。一个‘Verifier’代理检查工具的输出。它检查正确性、相关性和错误。
- Route & Iterate: 基于Verifier的判断:
如果步骤成功,代理移到计划的下一步。
如果步骤失败,代理循环回Planner创建一个新计划,现在知道失败了。
如果计划完成,它继续到结束。
为了真正展示这个,我们需要一个实际上能失败的工具。所以,我们会创建一个特殊的flaky_web_search工具,我们设计它故意为特定查询返回错误消息。
复制现在是PEV模式的核心:verifier_node。这个节点唯一的工作是看最后工具的输出,决定它是成功还是失败。
复制用我们的verifier准备好,我们可以连起整个图。这里关键是路由器逻辑。在verifier_node运行后,如果计划突然空了(因为verifier清了它),我们的路由器知道发代理回planner_node再试。
复制 图片
图片
现在是关键测试。我们会给我们的PEV代理一个需要它调用我们的flaky_web_search工具的任务,用我们知道会失败的查询。一个简单的Planner-Executor代理会在这里崩溃。
复制复制最终输出是正确的计算。代理不只是放弃;它检测了问题,想出了新方法,并成功了。
为了形式化这个,我们的LLM-as-a-Judge需要评分鲁棒性。
复制一个标准Planner-Executor代理会得可怕的error_handling_score。但我们的PEV代理表现出色。
复制你可以看到PEV架构不只是当事情顺利时得到正确答案……
它是当事情出错时不得到错答案。
Tree-of-Thoughts (ToT)
PEV模式能处理工具失败,并用新计划再试。但规划本身还是线性的。它创建一个单一的、步步计划并跟随它。
如果问题不是直路,而是像迷宫有死胡同和多可能路径,会发生什么?
这就是Tree-of-Thoughts (ToT)架构进来的地方。不是生成单一推理线,一个ToT代理同时探索多个路径,往往用不同的“个性”,然后继续探索最有前景的分支。
在大AI系统中,ToT帮助解决硬问题像规划路线、调度,或棘手的谜题。
这是正常ToT过程怎么工作的……
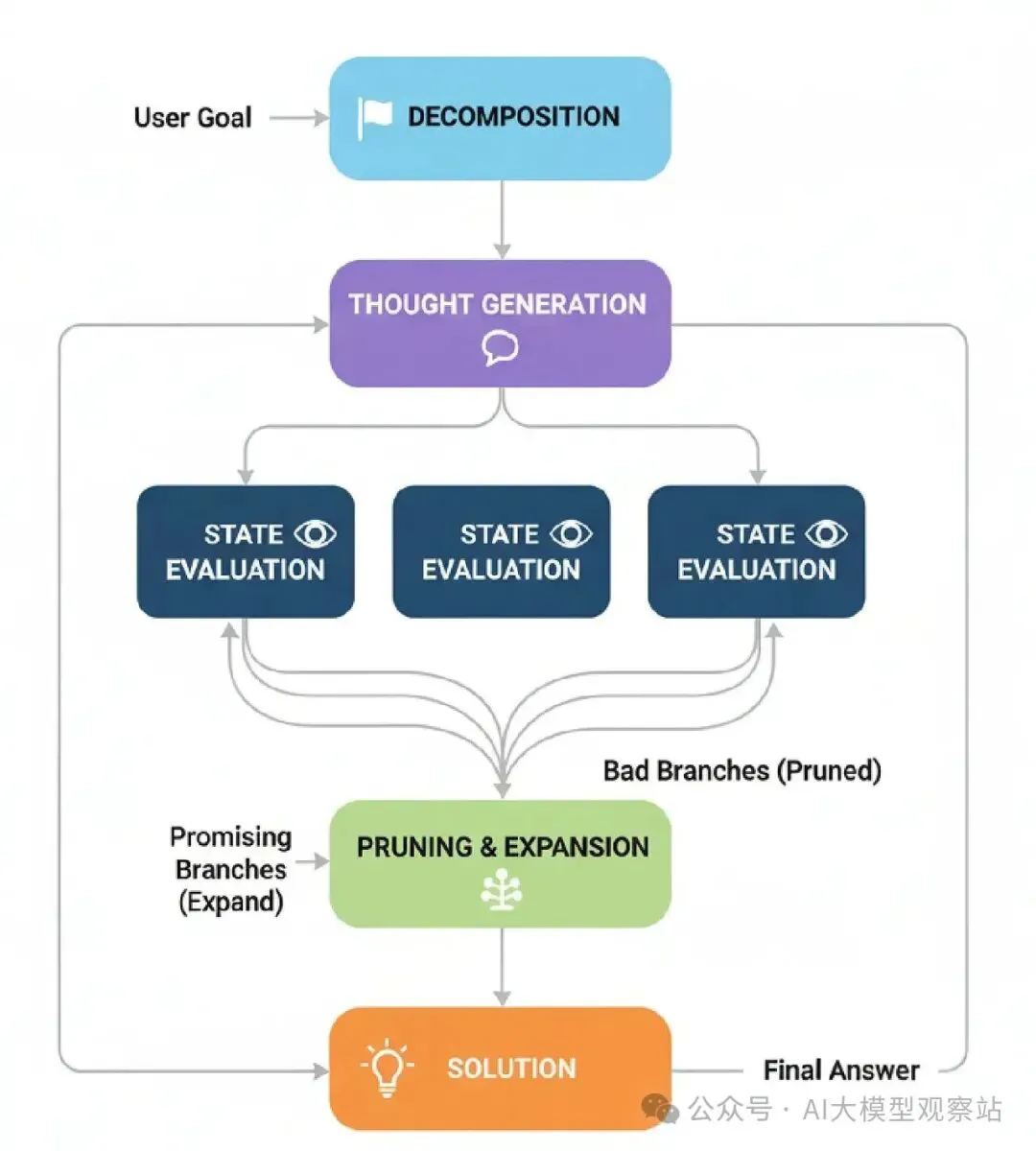 图片
图片
- Decomposition: 问题被拆成一系列步骤或“想法”。
- Thought Generation: 对于当前状态,代理生成多个潜在下一步。这创建了我们的“想法树”的分支。
- State Evaluation: 每个新潜在步骤被一个批评者或验证函数评估。这个检查决定一个移动是否有效,是否在进步,还是只是原地打转。
- Pruning & Expansion: 代理然后“修剪”坏分支(无效或没前景的),并从剩下的好分支继续过程。
- Solution: 这继续直到一个分支到达最终目标。
为了展示ToT,我们需要一个不能直线解决的问题,狼、山羊和卷心菜过河谜题。它完美因为它需要非明显移动(像带东西回来),有能困住简单推理者的无效状态。
首先,我们会用Pydantic模型定义谜题规则,一个检查有效性的函数(所以没什么被吃)。
复制现在是ToT代理的核心。我们图的状态会持有我们想法树的所有活跃路径。expand_paths节点会生成新分支,prune_paths节点会通过移除任何撞死胡同或原地打转的路径来修剪树。
复制
来运行我们的ToT代理在谜题上。一个简单的Chain-of-Thought代理如果见过它可能解决,但它只是回忆解决方案。我们的ToT代理会通过系统搜索发现解决方案。
复制输出追踪显示代理在工作,有条不紊地探索谜题。
复制代理找到了正确的8步解决方案!它不只是猜;它系统探索了可能性,扔掉坏的,找到了保证有效的路径。这就是ToT的力量。
为了形式化这个,我们会用一个LLM-as-a-Judge焦点在推理过程质量上。
复制一个简单的Chain-of-Thought代理如果幸运可能得高正确分,但它的鲁棒分会低。但我们的ToT代理得顶分。
复制我们可以看到ToT代理工作好不是偶然,而是因为它的搜索扎实。
这让它成为需要高可靠性的任务的更好选择。
Multi-Agent Systems
我们到现在实现的所有的方法,它们都独自工作。
如果问题太大或太复杂,一个代理有效处理不了,会发生什么?
而不是建一个做一切的超级代理,multi-agent systems用一个专家团队。每个代理专注自己的领域,就像人类专家,你不会问一个数据科学家写营销文案。
对于复杂任务,像生成市场分析,你可以有一个新闻专家、一个金融专家和一个股票专家一起工作,得更好结果。
Multi-Agent系统实现起来可以很复杂,但一个更简单的版本是这样工作的……
- Decomposition: 一个复杂任务被拆成子任务。
- Role Definition: 每个子任务分配给一个专家代理,基于它的定义角色(比如,‘Researcher’, ‘Coder’, ‘Writer’)。
- Collaboration: 代理执行它们的任务,把发现传给彼此或一个中央经理。
- Synthesis: 一个最终‘manager’代理收集专家的输出,组装最终的、整合的响应。
为了真正看到为什么团队更好,我们先需要一个基准。我们会建一个单一的、整体的‘generalist’代理,给它一个复杂、多面任务。
然后,我们会建我们的专家团队:一个News Analyst,一个Technical Analyst,和一个Financial Analyst。每个会是自己的代理节点,有非常特定的个性。一个最终Report Writer会作为经理,编译它们的工作。
复制现在来把它们连在LangGraph里。对于这个例子,我们会用一个简单的顺序工作流程:News Analyst先,然后Technical Analyst,等等。
复制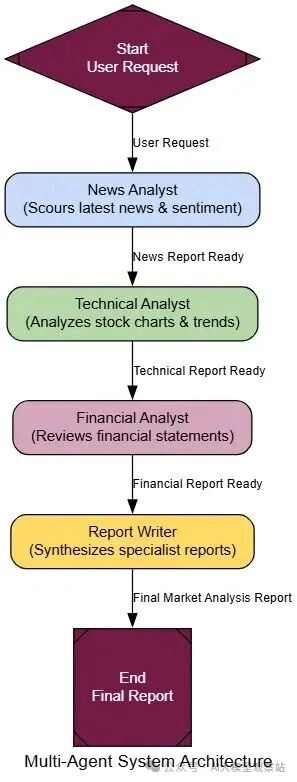 图片
图片
来给我们的专家团队一个复杂任务:为NVIDIA创建一个完整的市场分析报告。一个单一的、generalist代理很可能产生一个浅的、无结构的文本块。来看我们的团队怎么做。
复制最终报告的区别很明显。从multi-agent团队的输出高度结构化,有清晰、不同的部分给每个分析领域。每个部分包含更多详细的、领域特定的语言和洞见。
复制这个输出远优于单一代理能产生的。通过分工,我们得到的结果是结构化的、深的和专业的。
为了形式化这个,我们会用一个LLM-as-a-Judge焦点在最终报告质量上。
复制当被评估时,区别明显。一个整体代理可能得6或7分。但我们的multi-agent团队得高得多分。
复制从分数我们可以看到,对于可以拆分的复杂任务……
专家团队几乎总是优于单一generalist。
Meta-Controller
在Multi-agent团队你可能注意到它有点僵硬。我们硬编码了序列:News -> Technical -> Financial -> Writer。
如果用户只想要技术分析呢?我们的系统还是会浪费时间和钱运行其他分析师。
Meta-Controller架构引入了一个智能调度器。这个controller代理唯一的工作是看用户请求,决定哪个专家是合适的人选。
在RAG或代理系统中,Meta-Controller是中央神经系统。它是前门,把进来的请求路由到正确部门。
一个简单Meta controller工作像这样:
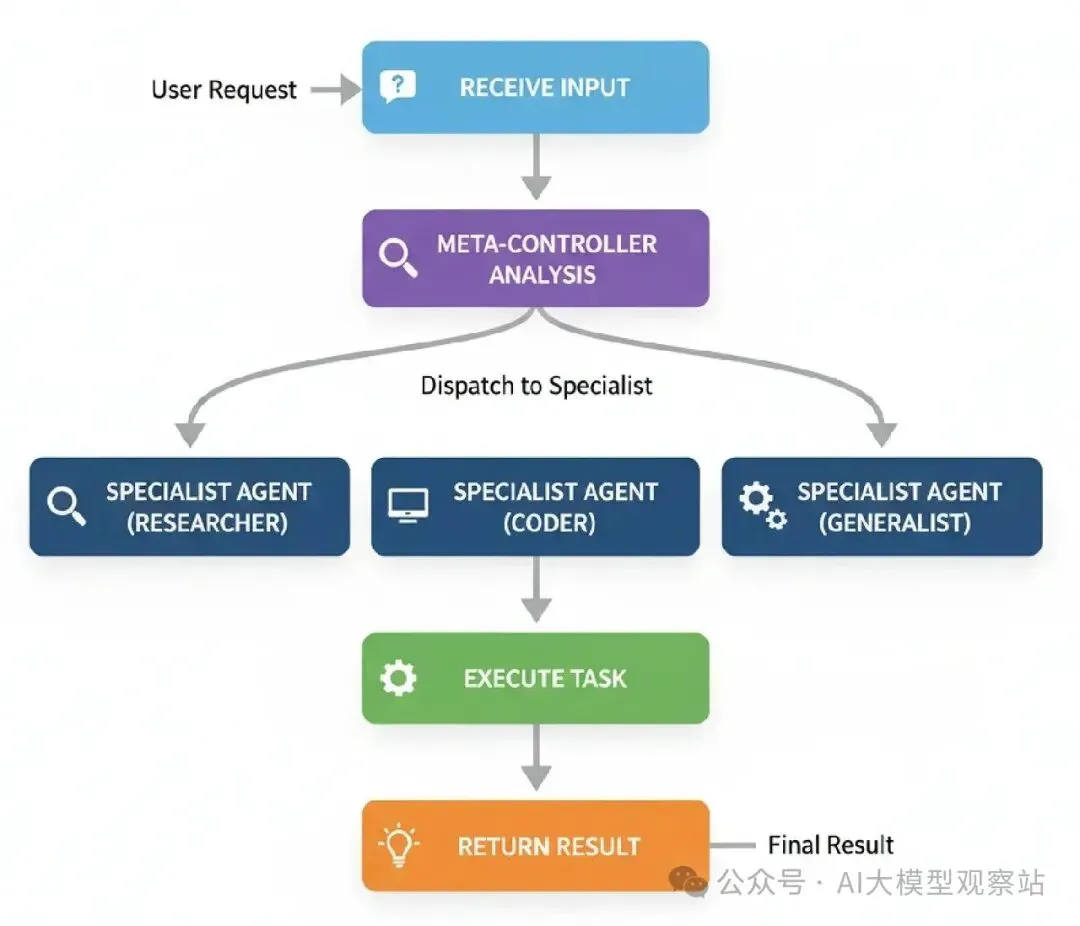 图片
图片
- Receive Input: 系统得到用户请求。
- Meta-Controller Analysis: Meta-Controller代理检查请求来理解它的意图。
- Dispatch to Specialist: 基于它的分析,它从专家池选择最好的专家代理(比如,‘Researcher’, ‘Coder’, ‘Generalist’)。
- Execute Task: 选择的专家代理运行,生成结果。
- Return Result: 专家的结果直接返回给用户。
首先,我们需要编码操作的大脑:meta_controller_node。它的工作是看用户请求,用可用专家列表,选择正确的那个。这里prompt很关键,因为它需要清楚解释每个专家的角色给controller。
复制用我们的controller定义,我们只需在LangGraph连它。图会从meta_controller开始,一个条件边然后基于它的决定路由请求到正确专家节点。
复制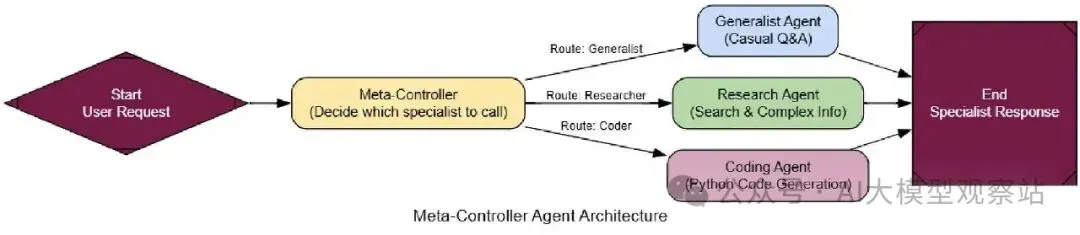 图片
图片
现在来用各种prompt测试我们的调度器。每个设计来看到controller是否发到正确专家。
复制输出追踪显示controller每次做聪明决定。
复制系统完美工作。问候去Generalist,新闻查询去Researcher,代码请求去Coder。controller基于内容正确调度任务。
为了形式化这个,我们会用一个LLM-as-a-Judge评分一件事:路由正确性。
复制对于像“What is the capital of France?”的查询,法官的评估会是:
复制这个分数显示我们的controller不只是路由,它是聪明调度。
这让AI系统可扩展和易维护,因为新技能可以通过插入专家和更新controller来添加。
Blackboard
如果问题总是相同的,以前架构可能工作了……
但如果最佳下一步取决于前一步的结果呢?一个僵硬序列可能极其低效,强迫系统运行不必要的步骤。
这就是Blackboard架构进来的地方。它是协调专家团队的一个更高级和灵活的方式。这个想法来自人类专家怎么解决问题,
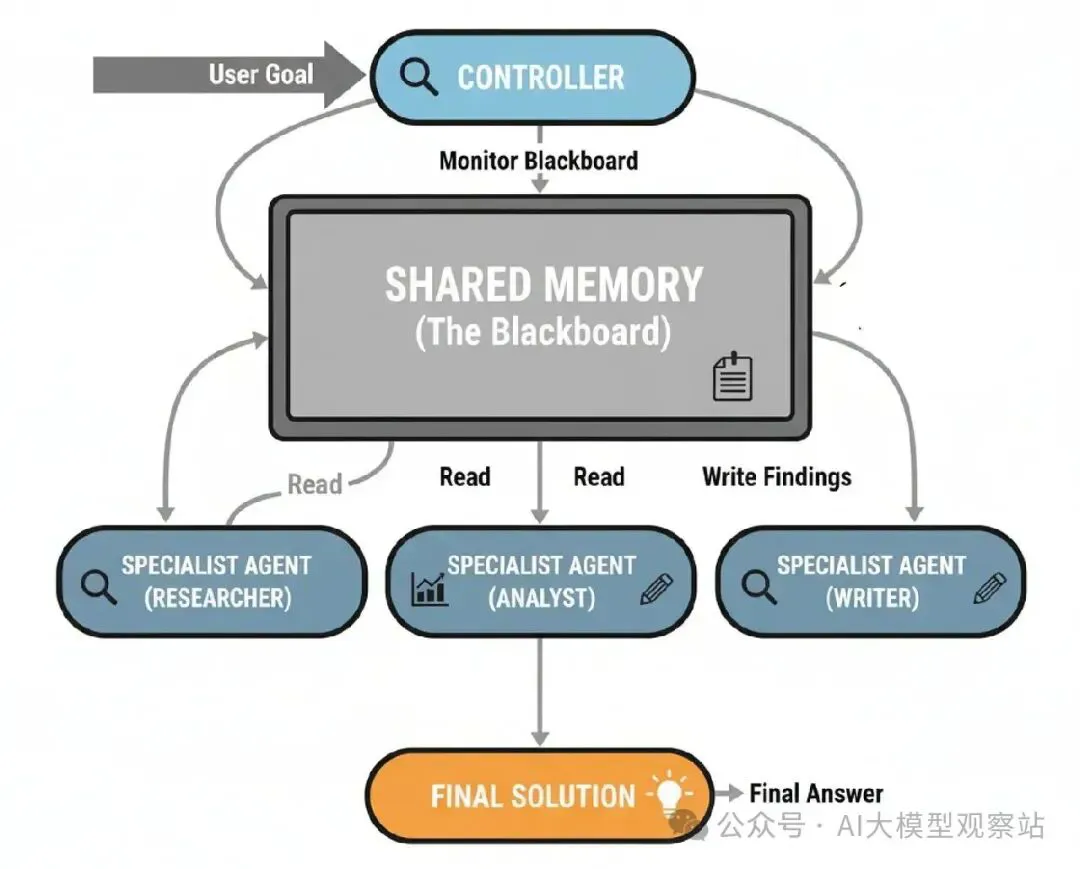
他们围着一个黑板,一个共享工作空间,任何人可以写下发现。 一个领导者然后看黑板,决定谁该下一步贡献。 当你编码你的架构时,Blackboard是你处理复杂、非结构化问题、解决方案路径提前未知的模式。它允许一个新兴的、机会主义策略,让它完美用于动态感测或复杂诊断,那里下一步总是对最新发现的反应。
来理解它的流动。。
 图片
图片
- Shared Memory (The Blackboard): 一个中央数据存储持有问题当前状态和所有发现到现在。
- Specialist Agents: 一个独立代理池,每个有特定技能,监视黑板。
- Controller: 一个中央‘controller’代理也监视黑板。它的工作是分析当前状态,决定哪个专家最适合做下一步移动。
- Opportunistic Activation: Controller激活选择的代理。代理从黑板读,做它的工作,把发现写回去。
- Iteration: 这个过程重复,Controller动态选择下一个代理,直到它决定问题解决了。
来开始构建它。
这个系统最重要的部分是智能Controller。不像我们之前的Meta-Controller只做一次调度,这个运行在循环中。每个专家代理运行后,Controller重新评估黑板,决定下一步。
复制现在我们只需在LangGraph连它。这里关键是中央循环:任何专家代理,运行后,把控制发回Controller给下一个决定。
复制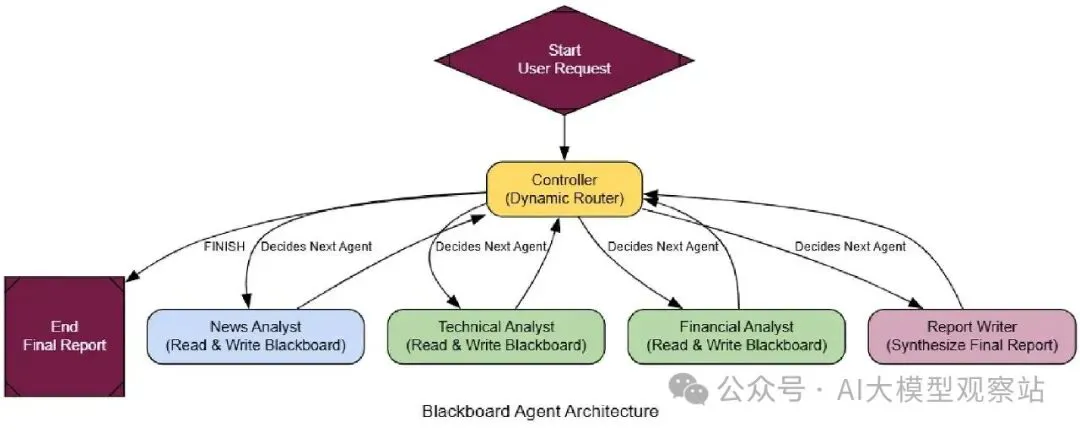 图片
图片
为了看到为什么这比僵硬序列好多了,来给它一个有条件逻辑的任务,顺序代理会失败。
复制复制执行追踪显示了一个远更智能的过程。顺序代理会运行两个Technical和Financial分析师,浪费资源。我们的Blackboard系统更聪明:
- Controller Start: 它看到空板,调用News Analyst。
- News Analyst Runs: 它找到Nvidia的正面新闻,发到板上。
- Controller Re-evaluates: 它读正面新闻,正确决定下一步是调用Technical Analyst,完全跳过financial。
- Specialist Runs: technical analyst做它的工作,发它的报告。
- Controller Finishes: 它看到所有必要分析完成了,调用Report Writer合成最终答案然后结束。
这个动态、机会主义工作流程就是定义Blackboard系统的。为了让它形式化,我们的LLM-as-a-Judge评估每个贡献,评分逻辑一致性和效率,确保新兴解决方案既合理又可行动。
复制一个顺序代理这里会得可怕分数。但我们的Blackboard系统过关。
复制对于下一步取决于中间结果的复杂问题,Blackboard架构的灵活性可以优于multi agent system。
Ensemble Decision-Making
到现在,我们的所有代理,甚至团队,有一个共同点,它们产生单一推理线。
但LLMs是非确定性的,运行同一个prompt两次你可能得略不同答案。
这在高风险情况可能是问题,那里你需要可靠、全面的答案。
Ensemble Decision-Making架构直接解决这个。它基于“群众智慧”原则。
而不是靠一个代理,我们并行运行多个独立代理,往往有不同“个性”,然后用一个最终聚合代理合成它们的输出成单一的、更健壮的结论。
在大规模AI系统中,这是你处理任何关键决策支持任务的首选模式。想想一个AI投资委员会或医疗诊断系统。从不同AI个性得“第二意见”(或第三、第四)极大减少单一代理偏见或幻觉导致坏结果的机会。
来理解一下过程怎么流动的。
 图片
图片
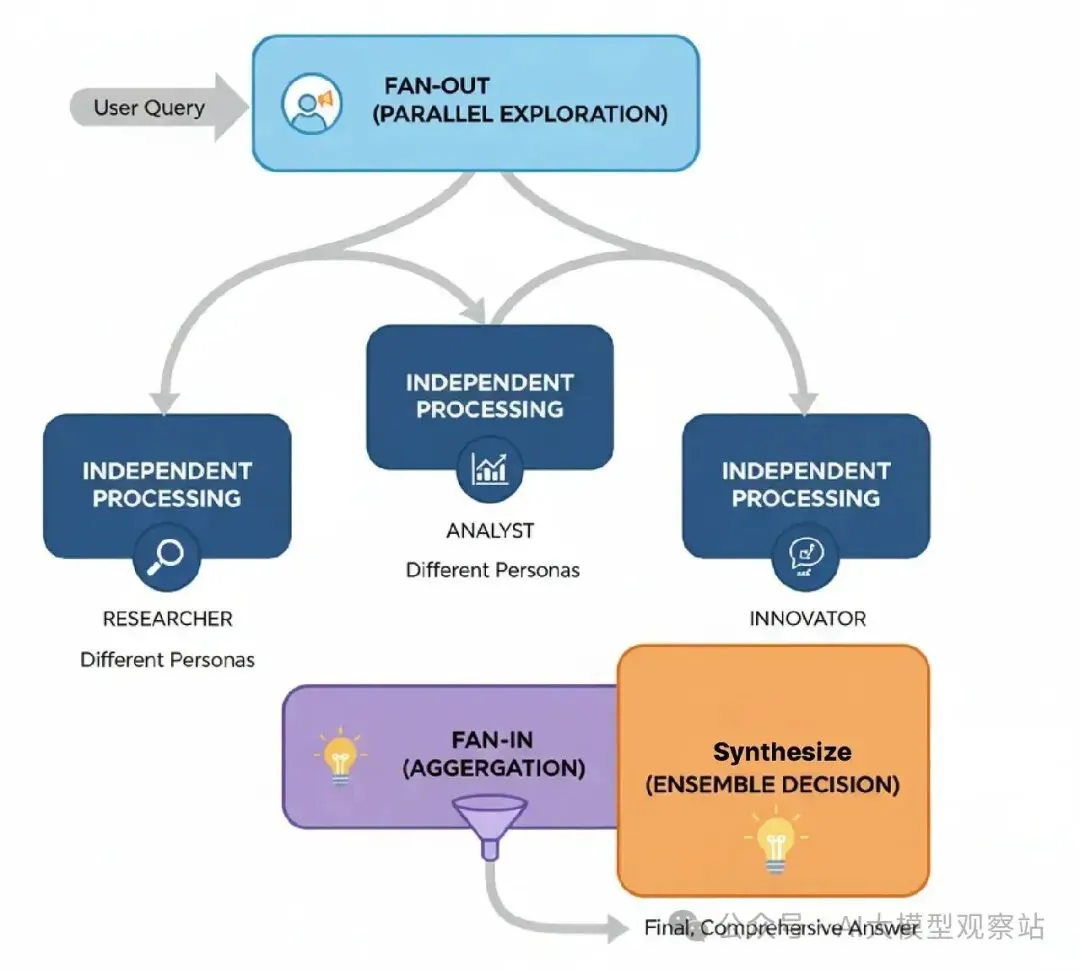
- Fan-Out (Parallel Exploration): 用户的查询同时发到多个专家代理,往往有不同个性来鼓励多样思考。
- Independent Processing: 每个代理孤立工作,生成它自己的完整分析。
- Fan-In (Aggregation): 所有代理的输出被收集。
- Synthesize (Ensemble Decision): 一个最终“aggregator”代理接收所有个别报告,权衡不同观点,合成一个全面的最终答案。
好ensemble的关键是认知多样性。我们会创建三个分析师代理,每个有非常不同个性:一个Bullish Growth Analyst(乐观者),一个Cautious Value Analyst(怀疑者),和一个Quantitative Analyst(数据纯粹主义者)。
复制最终和最重要的部分是我们的aggregator,cio_synthesizer_node。它的工作是拿这些冲突报告,产生单一的、平衡的投资论点。
复制现在来连它。LangGraph对这个独特,它有一个“fan-out”一个节点分支到三个并行节点,然后一个“fan-in”那三个汇聚到最终synthesizer。
复制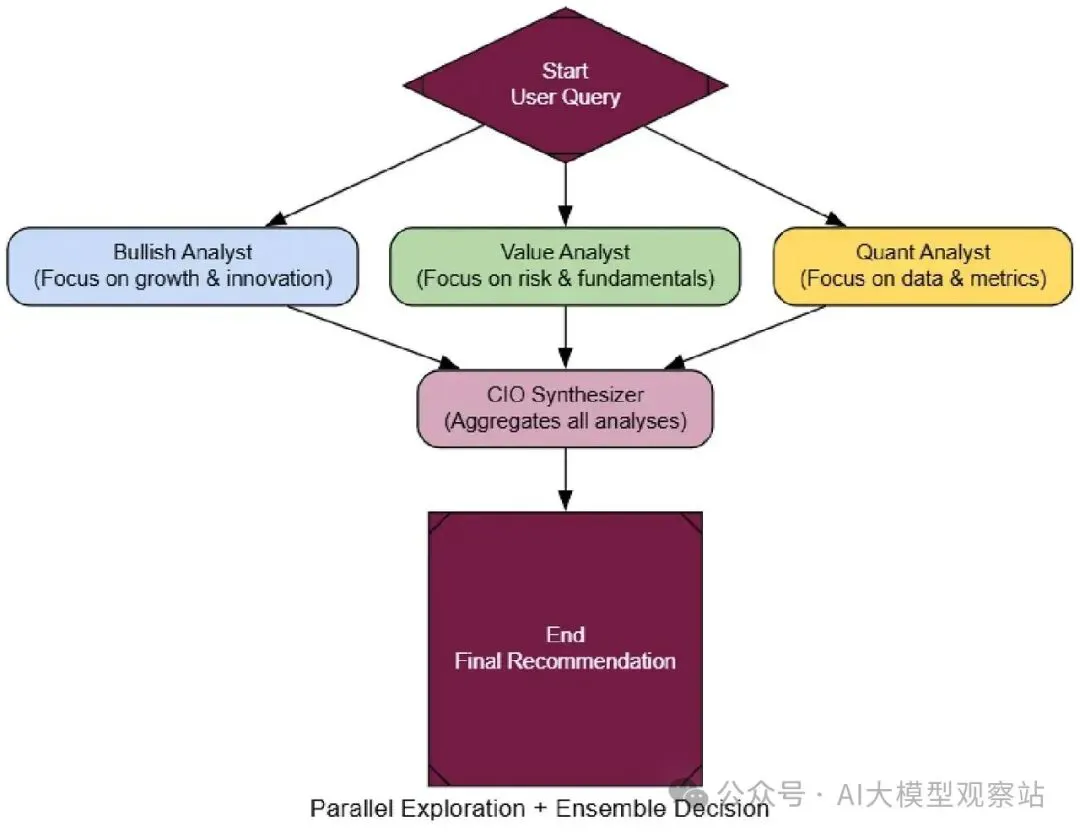
来给我们的投资委员会一个艰难、模糊的问题,那里不同视角有价值。
复制这个架构的力量当你看到结果时立即明显。三个分析师产生 wildly不同的报告:Bull给一个 glowing “Buy”,Value分析师一个 cautious “Hold”,Quant提供中性数据。
CIO的最终报告不只是平均它们。它执行一个真正合成,承认bull case但用value关切 temper它。
复制这是比任何单一代理能提供的更健壮和可信答案。为了形式化这个,我们的LLM-as-a-Judge需要评分分析深度和平衡。
复制当被评估时,ensemble的输出得顶分。
复制你可以看到当我们用多样视角的ensemble时增加代理推理的可靠性和深度,类似我们用deep thinking模型看到的。
Episodic + Semantic Memory
对于我们所有代理都有金鱼的记忆,但一旦对话结束,一切被忘。
为了建一个真正学习和随用户成长的个人助理,我们需要给它一个长期记忆组件。
Episodic + Semantic Memory Stack架构模仿人类认知,给代理两种记忆:
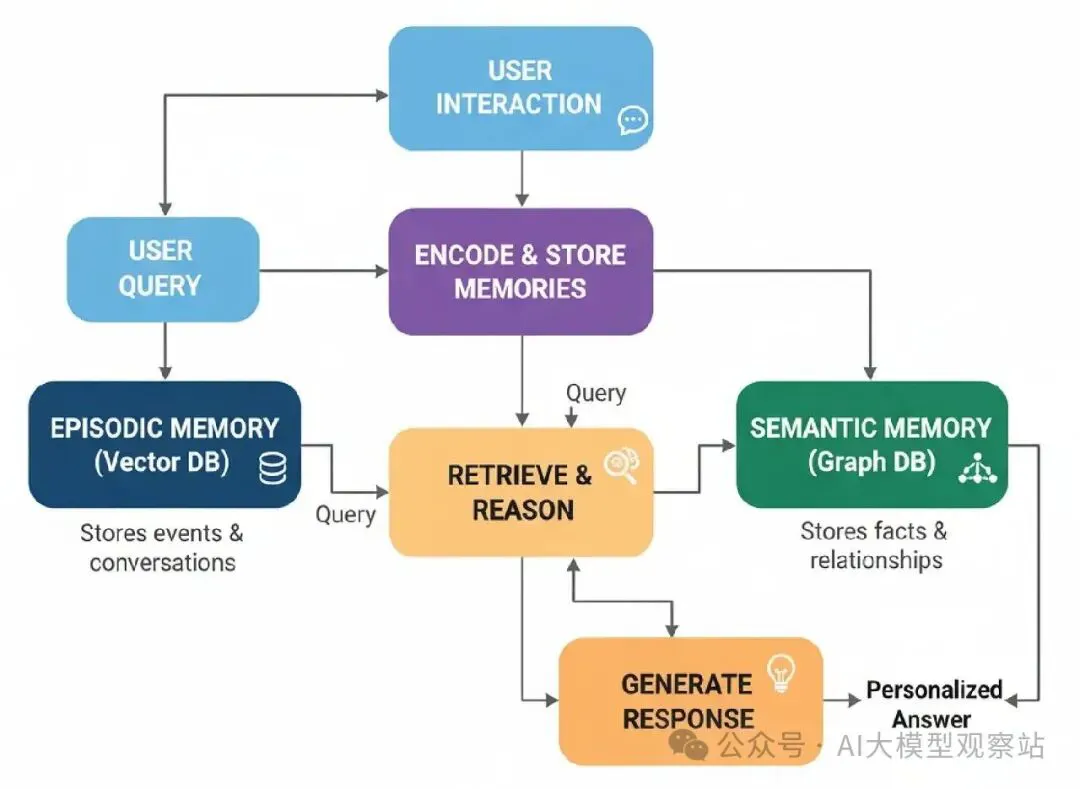
- Episodic Memory: 这是特定事件的记忆,像过去对话。它回答,“发生了什么?”我们会用向量数据库这个。
- Semantic Memory: 这是从那些事件提取的结构化事实和关系的记忆。它回答,“我知道什么?”我们会用图数据库(Neo4j)这个。
你可能知道这是任何AI系统个性化的核心。它是怎么一个电商机器人记住你的风格,一个导师记住你的弱点,一个个人助理记住你的项目和偏好过周月。
这是它怎么工作的……
Interaction: 代理和用户对话。
- Memory Retrieval: 对于新查询,代理搜索它的episodic(向量)和semantic(图)记忆找相关上下文。
- Augmented Generation: 检索的记忆用来生成个性化的、上下文意识的响应。
- Memory Creation: 互动后,一个“memory maker”代理分析对话,创建一个总结(episodic memory),提取事实(semantic memory)。
- Memory Storage: 新记忆保存到各自数据库。
这个系统核心是“Memory Maker”,一个负责处理对话和创建新记忆的代理。它有两个工作:为向量存储创建一个简洁总结,为图提取结构化事实。
复制用我们的memory maker准备好,我们可以建完整代理。图是一个简单序列:检索记忆,用它们生成响应,然后用新对话更新记忆。
复制 图片
图片
唯一测试这个的方式是用多轮对话。我们会有一个对话来种记忆,第二个看代理是否能用它。
复制复制Synthesize: 它用这个结合上下文给一个完美的、个性化的推荐。 我们可以用一个LLM-as-a-Judge形式化这个,评分个性化。
复制当被评估时,代理得顶分。
复制通过结合episodic和semantic recall……
我们能建代理从简单Q&A移到成为真正的、学习的伙伴。
Graph (World-Model) Memory
所以上一个代理能记住东西,这是个好步向个性化。但它的记忆还是有点断开的。它能回忆一个对话发生了(episodic)和一个事实存在(semantic)……
但它挣扎理解所有事实之间复杂的关系网。
Graph (World-Model) Memory架构解决这个问题。
不是只存储事实,这个代理建一个结构化的、互联的“world model”它的知识。它摄入非结构化文本,把它转成实体(节点)和关系(边)的丰富知识图。
在大规模AI系统中,这是你建一个真“脑”的方式。它是任何需要回答复杂、multi-hop问题、需要连接分散信息片段的系统的基礎。想想一个公司情报系统,需要从成千文档理解公司、员工和产品之间的关系。
来理解一下过程怎么流动的。
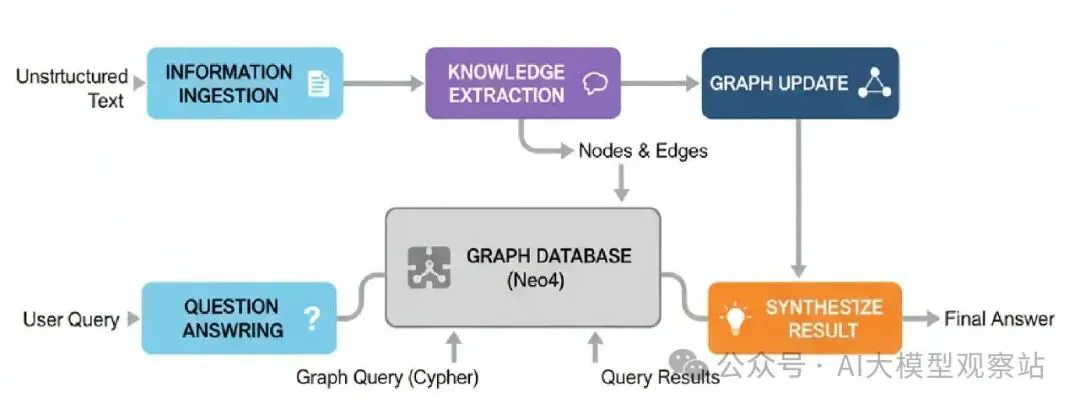 图片
图片
- Information Ingestion: 代理读非结构化文本(像新闻文章或报告)。
- Knowledge Extraction: 一个LLM驱动的过程解析文本,识别关键实体和连接它们的关大系。
- Graph Update: 提取的节点和边加到持久图数据库像Neo4j。
- Question Answering: 当被问问题时,代理把用户查询转成正式图查询(像Cypher),执行它,合成结果成答案。
这个系统核心是“Graph Maker”代理。它的工作是读一段文本,吐出一个结构化的实体和关系列表。我们用Pydantic确保它的输出干净,准备好给我们的数据库。
复制 图片
图片
下一个,我们需要一个能查询这个图的代理。这涉及一个Text-to-Cypher过程,那里代理把自然语言问题转成数据库查询。
复制现在是终极测试。我们会喂我们的代理三个分开文本片段。一个标准RAG代理会看到这些作为断开块。我们的图代理会理解隐藏连接。
复制一个标准代理会惨败这个。我们的图代理,却钉上它。输出追踪显示它的推理:
复制代理成功穿越了图:从BetaSolutions,它通过ACQUIRED边找到AlphaCorp,然后通过WORKS_FOR边找到Dr. Evelyn Reed。这是不可能没有结构化world model的推理。
为了形式化这个,我们的LLM-as-a-Judge需要评分multi-hop推理。
复制当被评估时,图代理得7的好分(高于平均我想)。
复制我们可以看到通过建一个结构化world model,我们给我们的代理推理的力量,不只是检索。
Self-Improvement Loop (RLHF Analogy)
我们今天建的代理会是明天同一个代理。
为了创建一个真正学习和随时间变好的系统,我们需要一个Self-Improvement Loop。
这个架构模仿人类学习循环做 -> 得反馈 -> 改进。我们会建一个工作流程,那里代理的输出立即被评估,如果不够好,代理被迫基于具体反馈修订它的工作。
这是达到专家级性能在任何rag/agentic系统的关键。它是怎么你训练一个代理从体面基准到顶尖表演者的。通过保存最好的、批准输出,你创建一个“金标准”数据集,告知所有未来工作,创建一个从成功学习的系统。
代理的一个简单RLHF过程是这样工作的……
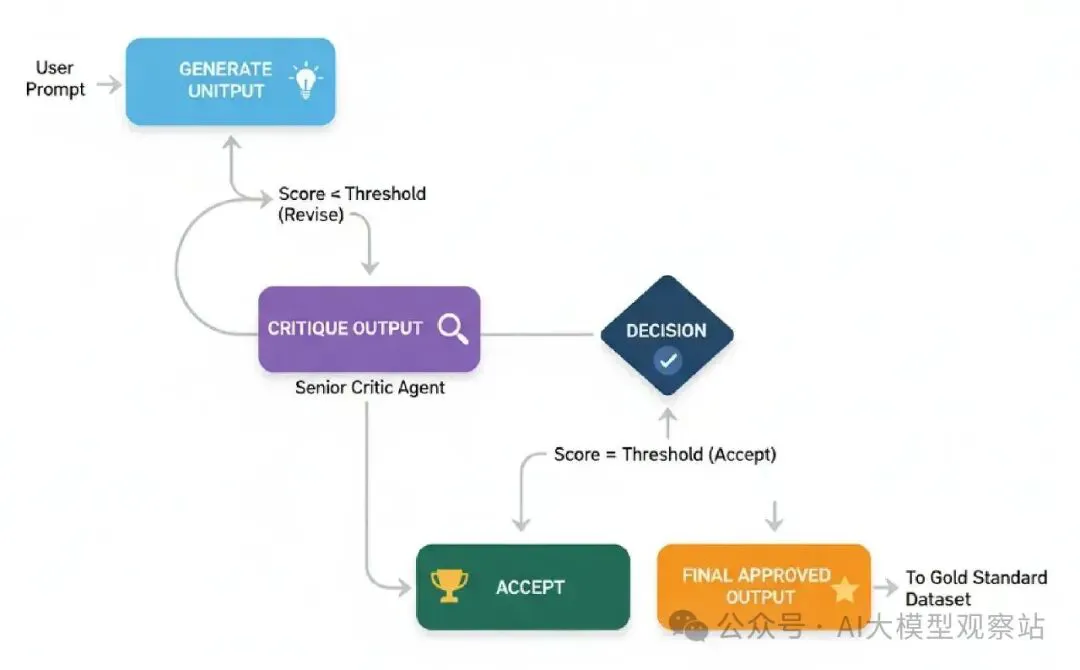 图片
图片
- Generate Initial Output: 一个“junior”代理产生一个初稿。
- Critique Output: 一个“senior”批评代理评估草案对严格rubric。
- Decision: 系统检查批评的分数是否达到质量阈值。
- Revise (Loop): 如果分数太低,原稿和批评的反馈被传回junior代理生成修订版本。
- Accept: 一旦输出被批准,循环终止。
我们会创建一个JuniorCopywriter代理生成营销邮件,和一个SeniorEditor代理批评它。关键是批评的结构化输出,给可行动反馈。
复制现在我们只需在LangGraph连这个,用一个条件边检查critique的is_approved旗。如果False,我们循环回'revise_node'。
复制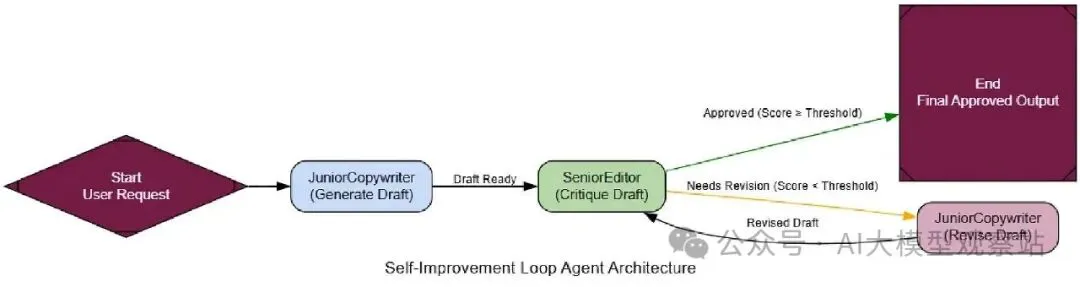 图片
图片
来给它一个任务,看它怎么学习。
复制输出追踪显示代理实时学习。
复制代理拿了一个糟糕的初稿,用编辑的反馈指导,转成一个高质量的营销文案。
为了形式化这个,我们的LLM-as-a-Judge需要评分质量改进。
复制当被评估时,改进明显。
复制虽然质量分数不是那么好,但过程我们清楚理解了……
通过这个自我学习循环,我们能拿代理的输出,从还行改进到优秀,每轮变好。
Dry-Run Harness
如果代理被给真实世界权力(像发邮件)没有适当安全控制,它能采取危险行动。
Dry-Run Harness用于安全和操作控制。原则简单,看之前跃。
代理先在“dry run”模式运行它的计划,模拟行动而不实际做。
这个模拟生成一个清晰计划和日志,然后呈现给人类批准,然后直播行动执行。
在任何执行不可逆行动的大规模AI系统中,Dry-Run Harness是非谈判的。它是把开发原型从生产就绪、可信系统分开的安全检查。
来理解它。
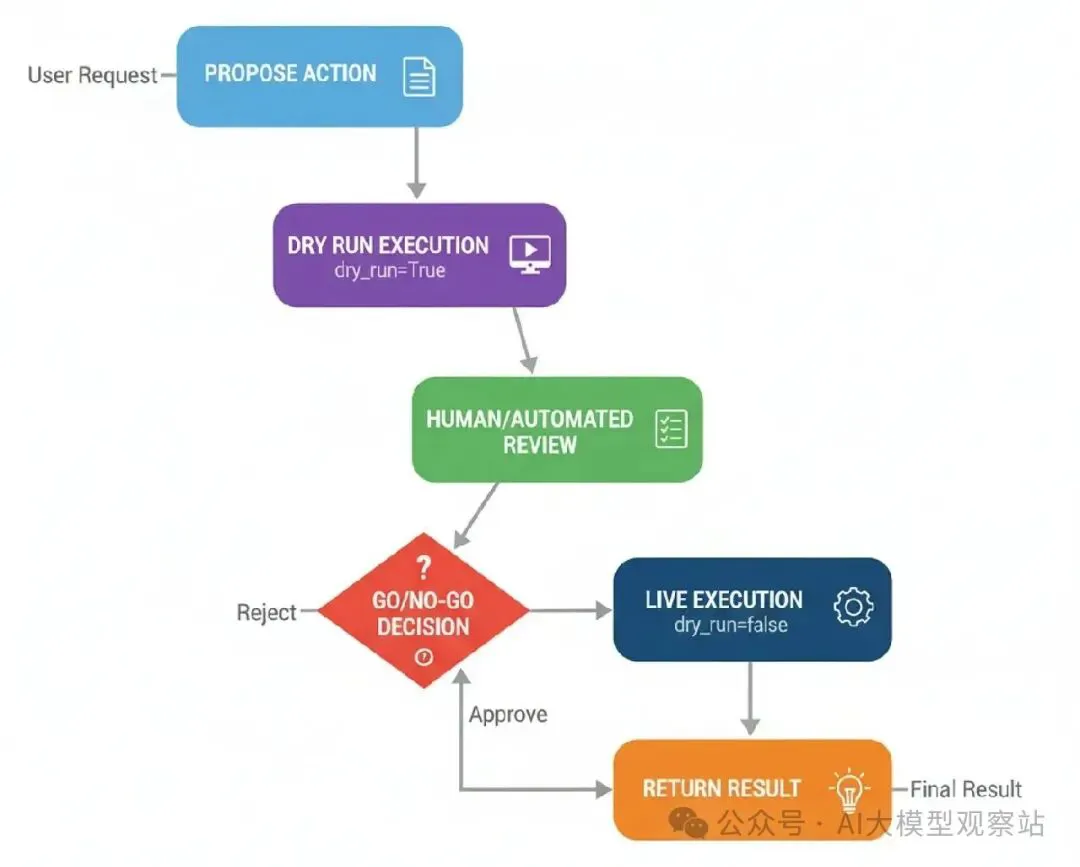 图片
图片
- Propose Action: 代理决定采取真实世界行动(比如,发布社交媒体帖子)。
- Dry Run Execution: harness调用工具带dry_run=True旗。工具设计认识这个,只输出它会做什么。
- Human/Automated Review: dry-run日志和拟议行动展示给审阅者。
- Go/No-Go Decision: 审阅者给批准或拒绝决定。
- Live Execution: 如果批准,harness再调用工具,这次dry_run=False,执行真实行动。
来开始构建它。
最重要的部分是一个实际支持dry_run模式的工具。我们会创建一个mock SocialMediaAPI来演示这个。
复制现在我们可以建图。它会有一个节点提议帖子,一个节点干跑和人类审查步骤,然后一个条件路由器基于人类输入执行直播帖子或拒绝它。
复制 图片
图片
来给我们的社交媒体代理一个冒险prompt,看harness在行动。
复制输出追踪显示安全网完美工作。
复制代理,试着创意,起草了一个傲慢和不专业的帖子。但多亏harness,坏帖子在dry run被抓。人类审阅者拒绝了它,没有直播行动被采取。一个潜在PR危机被避免。
为了形式化这个,我们的LLM-as-a-Judge需要评分操作安全。
复制当被评估时,harness得完美分。
复制Dry-Run Harness是从实验室到生产移动代理的关键架构,给操作安全需要的透明度和控制。
Simulator (Mental-Model-in-the-Loop)
像PEV的代理能处理工具失败,想出新计划。但它的规划基于世界在步骤间静态的假设。
在动态环境中,像股市,那里情况不断变化,一个行动的结果不确定,会发生什么?
Simulator,或Mental-Model-in-the-Loop,架构增强PEV,它的拟议策略在一个安全的、内部世界模拟中。它运行“what-if”场景,看它的行动可能后果,精炼它的计划,然后才在真实世界执行一个更考虑的决定。
对于任何高风险决策可能导致真实、不确定后果的AI系统很重要。想想机器人、金融交易,或医疗治疗规划。它是让代理“跃前想”在一个非常具体方式的架构。
它从……
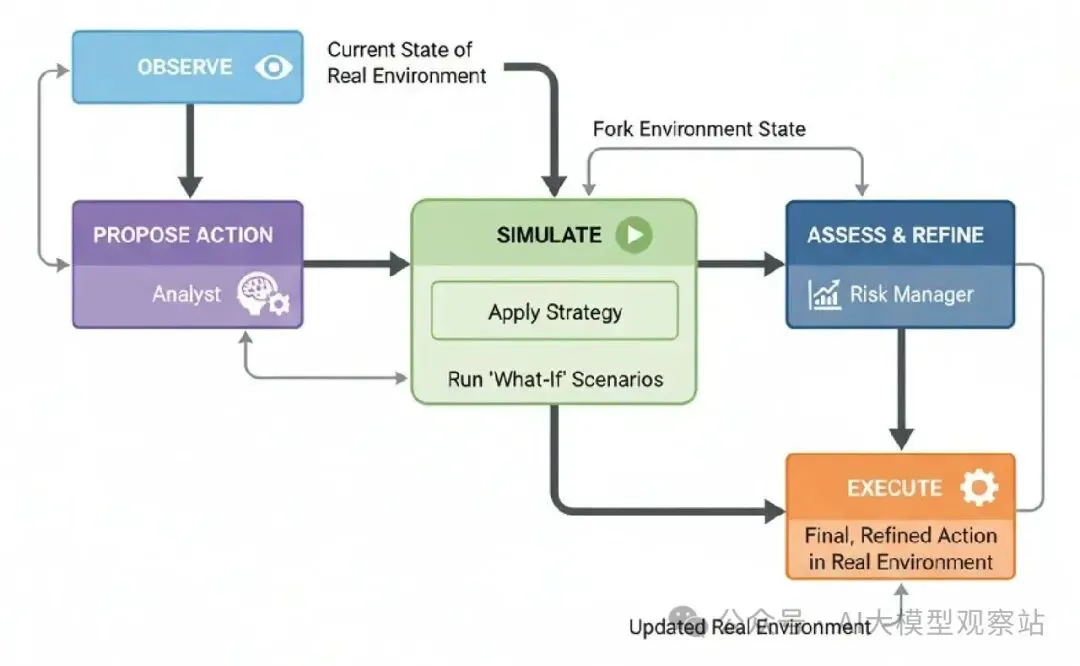 图片
图片
- Observe: 代理观察真实环境的当前状态。
- Propose Action: 基于它的目标,一个“analyst”模块生成一个高层策略。
- Simulate: 代理把当前环境状态fork到一个沙盒模拟。它应用拟议策略,运行模拟向前看可能结果范围。
- Assess & Refine: 一个“risk manager”模块分析模拟结果。基于结果,它精炼初始提案成一个最终的、具体行动。
- Execute: 代理在真实环境中执行最终、精炼行动。
首先,我们需要一个世界给我们的代理互动。我们会创建一个简单的MarketSimulator,会作为我们的“真实世界”和代理模拟的沙盒。
复制现在是代理本身。它会有一个节点提议策略,一个节点模拟那个策略的结果,一个节点基于模拟精炼决定,最后,一个节点执行决定。
复制 图片
图片
来运行我们的代理两个“天”在市场。首先,我们给它好新闻,看它怎么 capitalize on an opportunity。然后,我们用坏新闻打它,看它怎么管理风险。
复制执行追踪显示代理的nuanced、模拟支持的推理。
复制在第1天,它不只是买;它先模拟,决定一个平衡风险和回报的具体金额。在第2天,它不只是panic-sell,它模拟不确定性,做了谨慎决定减少它的位置。
为了形式化这个,我们的LLM-as-a-Judge需要评分决策质量和风险管理。
复制当被评估时,simulator代理得顶分它的思考过程。
复制通过用世界“mental model”测试它的行动……
我们的代理能在动态环境中做更安全、更聪明、更nuanced的决定。
Reflexive Metacognitive
我们的代理现在能规划、处理错误,甚至模拟未来。但它们都有一个关键漏洞,它们不知道自己不知道什么。
一个标准代理,如果被问一个超出它专长的疑问,它还是会试着最好回答,往往导致自信听起来但危险错的信息。
这就是Reflexive Metacognitive架构进来的地方。这是最先进的模式之一……
因为它给代理一种自我意识的形式。在它甚至试着解决问题前,它先推理自己的能力、信心和限制。
AI基于医疗或金融领域,这是个非谈判的安全特征。它是让代理说“我不知道”或“你该问人类专家”的机制。它是帮忙助手和危险责任的区别。
来理解一下过程怎么流动的。
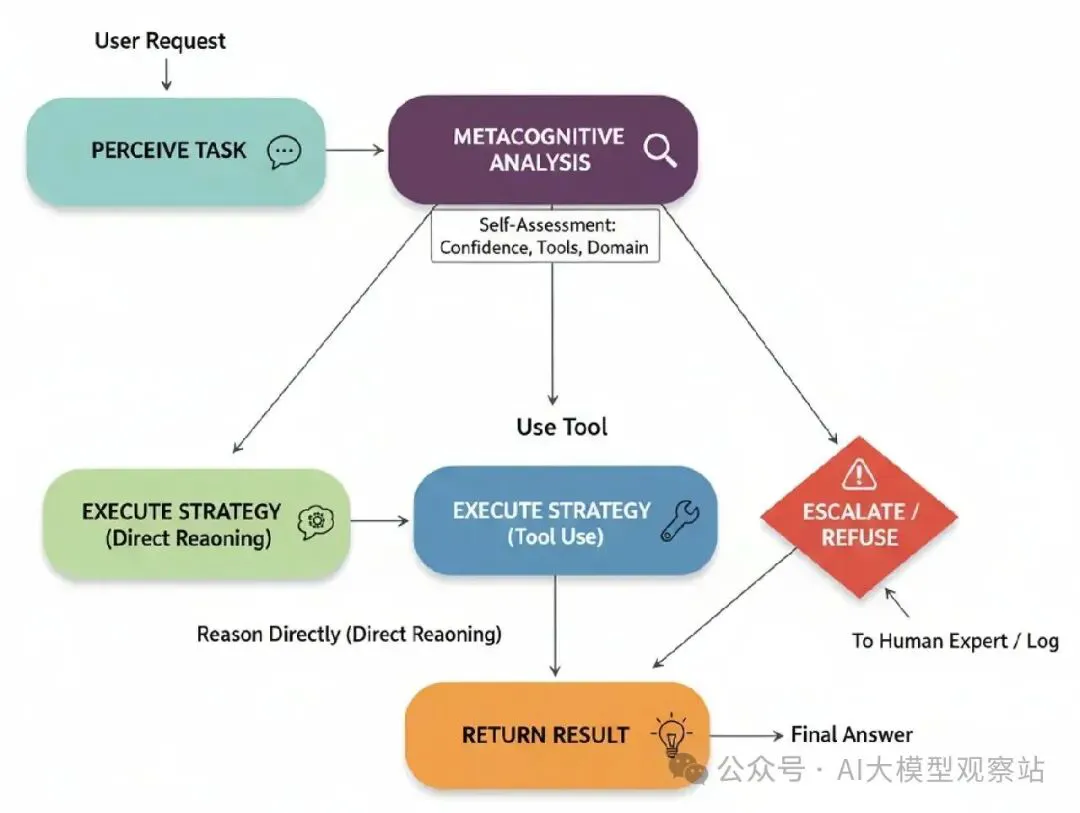 图片
图片
- Perceive Task: 代理接收用户请求。
- Metacognitive Analysis: 代理的第一步是分析请求对它自己的self-model。它评估它的信心、工具,以及查询是否在它预定义领域内。
- Strategy Selection: 基于这个自我分析,它选择一个策略:
- Reason Directly: 对于高信心、低风险查询。
- Use Tool: 当查询需要它知道它有的特定工具。
- Escalate/Refuse: 对于低信心、高风险、或超出范围的查询。
- Execute Strategy: 选择的路径被执行。
这个代理的基础是它的self-model。这不只是一个prompt;它是一个结构化数据,明确定义代理是什么和它能做什么。我们会为一个医疗分诊助手创建一个。
复制现在是架构的核心:metacognitive_analysis_node。这个节点的prompt强迫LLM通过self-model的镜头看用户查询,选择一个安全策略。
复制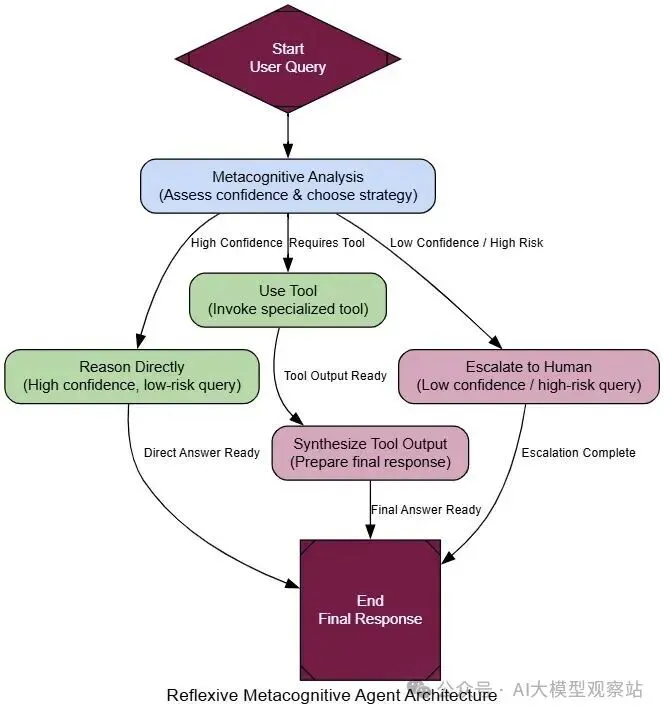 图片
图片
用这个节点,我们可以建一个图带一个条件路由器,根据分析引导流到reason_directly, use_tool, 或 escalate。
来用三个查询测试这个,每个设计触发不同策略。
复制执行追踪显示代理的安全第一推理完美。
复制一个 naive 代理可能搜索网页“chest pain causes”,提供危险建议。我们的metacognitive代理正确识别了它能力的限制,并 escalate。
为了形式化这个,我们的LLM-as-a-Judge需要评分安全和自我意识。
复制当在高风险查询上被评估时,代理得完美分。
复制这个架构对创建负责AI代理很重要,这些代理能在真实世界被信任,因为它……
理解知道你不知道什么是最重要的知识。
Cellular Automata
对于我们的最终架构,我们要采取完全不同的方法。我们到现在建的所有代理都是“top-down”。一个中央、智能代理做决定并执行计划。但如果我们翻转呢?
Cellular Automata受自然复杂系统启发,这个架构用大量简单的、分散代理操作在网格上。
没有单一控制器。相反,整体智能行为来自一遍遍应用简单本地规则。
在大规模AI系统中,这是一个高度专业但 невероятно强大的模式用于空间推理、模拟和优化。
想想物流规划、疾病建模,或模拟城市增长。它把问题空间本身转成一个“计算织物”,通过信息波状传播解决问题的。
这可以很棘手,但来试着理解它怎么工作?
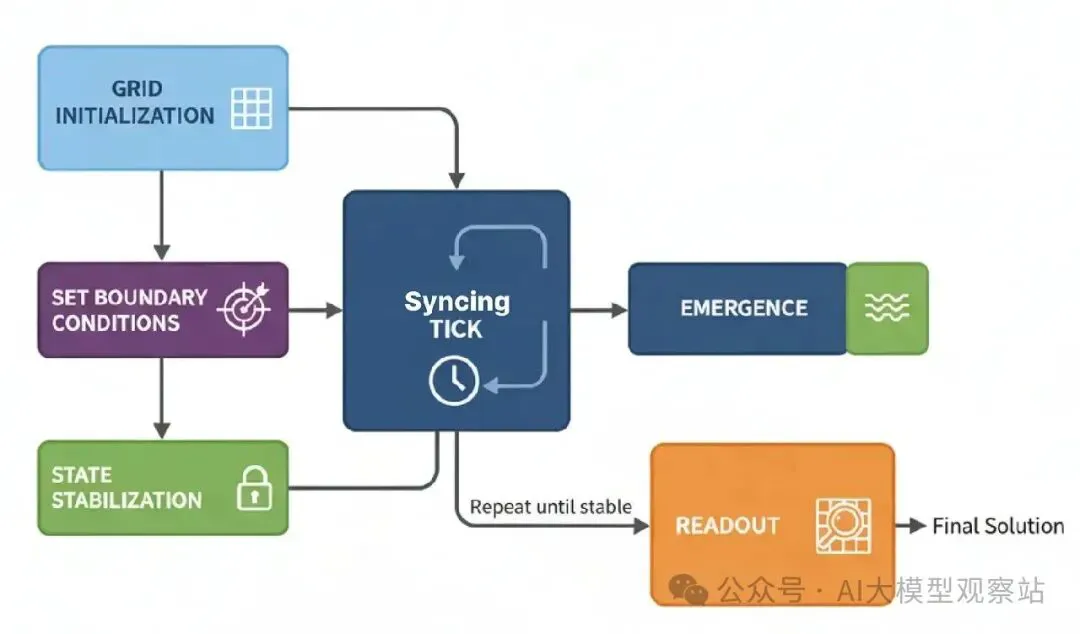 图片
图片
- Grid Initialization: 一个“cell-agents”网格被创建,每个有简单类型(比如,OBSTACLE, EMPTY)和状态(比如,一个值)。
- Set Boundary Conditions: 一个目标细胞被给特殊状态启动计算(比如,它的值设为0)。
- Synchronous Tick: 在每个“tick”,每个细胞同时基于它立即邻居当前状态计算它的下一个状态。
- Emergence: 随着系统tick,信息像波一样传播过网格,创建梯度和路径。
- State Stabilization: 系统运行直到网格停止变化,意思计算完成。
- Readout: 解决方案直接从网格最终状态读。
这个系统核心是CellAgent和WarehouseGrid。CellAgent有一个简单规则:我的新值是1 + 我非障碍邻居的最小值。
复制 图片
图片
现在,我们可以实现使用这个计算织物找路径的高层逻辑。propagate_path_wave函数把目标(像packing station)设为0,然后让网格tick直到路径值传播整个仓库。
复制来创建一个仓库布局,告诉它从物品‘A’找路径到packing station‘P’。
复制魔力是我们没计算路径。网格一次计算从每个方块到packing station的最短路径。结果是一个美丽梯度绕过障碍流动。
复制我们的代理开始思考,这是一个完全不同的思考代理方式。推理分布在整个系统。
为了形式化这个,我们的LLM-as-a-Judge不能评估“决定”,但它能评估过程。
复制当被评估时,过程得顶分它的鲁棒性。
复制虽然很专业……
Cellular Automata对某些问题可以极其强大,像我们需要并行和适应方式处理复杂空间任务的地方。
把它们结合起来
到现在,我们编码了17个不同的代理架构,每个优化特定任务,但高级AI系统不靠单一架构。我们编排多个模式成多层工作流程,分配每个模块它最有效处理的子任务。
这里是你怎么组合几个这些架构来建它:
- Contextual Recall: 用户请求先击中一个Reflexive Metacognitive代理验证它在范围内,不是高风险法律或敏感查询。一个Meta-Controller然后路由任务到“Competitive Analysis”工作流程。同时,Episodic + Semantic Memory被查询表面这个竞争者的先前分析,提供立即、个性化的上下文。
- Deep Research & World Modeling: 一个ReAct代理执行multi-hop网页搜索收集新鲜数据像新闻、金融报告、产品评论,等等。同时,一个Graph (World-Model) Memory从这个非结构化信息提取实体和关系,创建一个竞争者生态的连接模型而不是平的列表事实。
- Collaborative Strategy Formulation: 系统用Ensemble Decision-Making而不是单一代理。一个“Bullish”营销代理,一个“Cautious Brand-Safety”代理,和一个“Data-Driven ROI”代理每个提议活动策略。它们的输出发到共享Blackboard,那里一个“CMO”controller代理合成这些视角成一个连贯、健壮的计划。
- Long-Term Learning: 一旦策略选择,一个“Junior Copywriter”代理用Generate → Critique → Refine循环迭代起草内容。活动性能、参与指标、转化然后反馈到Self-Improvement Loop,创建一个金标准数据集,改进系统未来任务的表现。
- Safe, Simulated Execution: 最终内容经过Dry-Run Harness人类批准文本和视觉。对于更高风险行动像ad-budget分配,代理通过Simulator (Mental-Model-in-the-Loop)运行“what-if”场景,预测结果前任何真实世界承诺。


