
作者 | 论文团队
编辑 | ScienceAI
在临床工作中,医生每天都要面对复杂的推理过程:从病人主诉、化验数据、影像学检查,到诊断、治疗方案和随访决策。
但这些过程不仅繁琐,还充满不确定性。能否让人工智能来帮忙?
近年来,大型语言模型(LLMs)在医疗健康领域展现出前所未有的潜力。它们能读懂病历、生成诊断意见,甚至和患者对话。但要真正成为临床的「智慧助手」,LLMs 需要的不仅是语言能力,更是医学推理能力。
最近,一项由香港理工大学的研究者主导完成的综述 ——《Aligning Clinical Needs and AI Capabilities: A Survey on LLMs for Medical Reasoning》,首次系统梳理了医学推理的全景图:需求、方法、数据、挑战与未来方向。

论文链接:https://www.techrxiv.org/users/966100/articles/1334596-aligning-clinical-needs-and-ai-capabilities-a-survey-on-llms-for-medical-reasoning
Github链接(整理的现有的工作,更新中,欢迎补充):https://github.com/pqpq17/Awesome-LLM-Reasoning-on-Medicine
五级医学推理能力框架
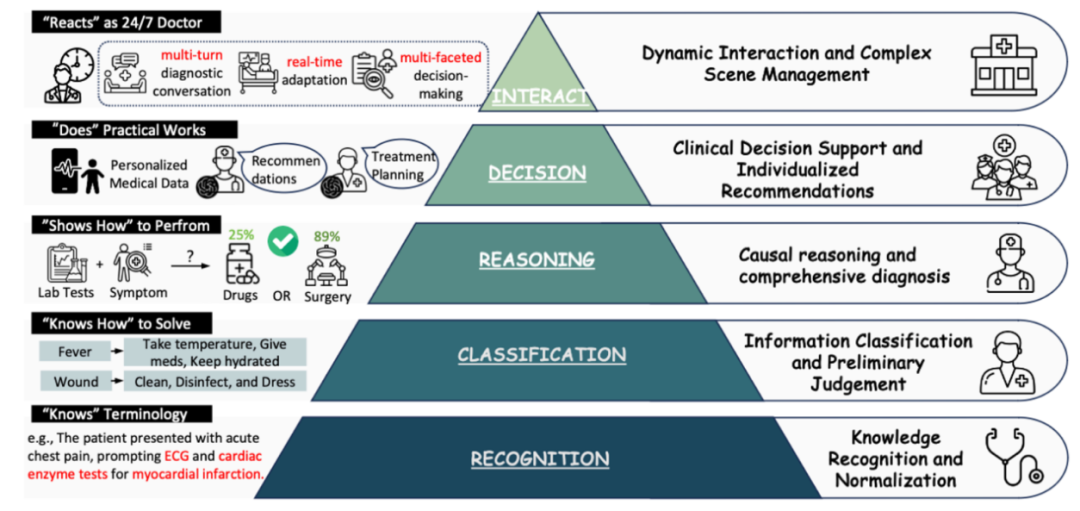
该综述基于 Miller’s Pyramid(米勒金字塔),提出了五级医学推理能力分层体系:
Level 1:医学知识识别与标准化(Knows)
Level 2:信息分类与初步分诊(Knows How)
Level 3:因果推理与综合诊断(Shows How)
Level 4:临床决策支持与个性化推荐(Shows How / Does)
Level 5:动态交互与复杂场景管理(Does)
这个框架清晰描绘了 LLM 从「会认知识」到「能当助手」的进阶路径,对现有benchmark/dataset的做出了清晰的划分。
此外,基于这个五级分类体系以及Reasoning类型的讨论,该综述明确指出一个双视角(即computational & clinical)的对齐框架。
首个标准化五级基准数据集
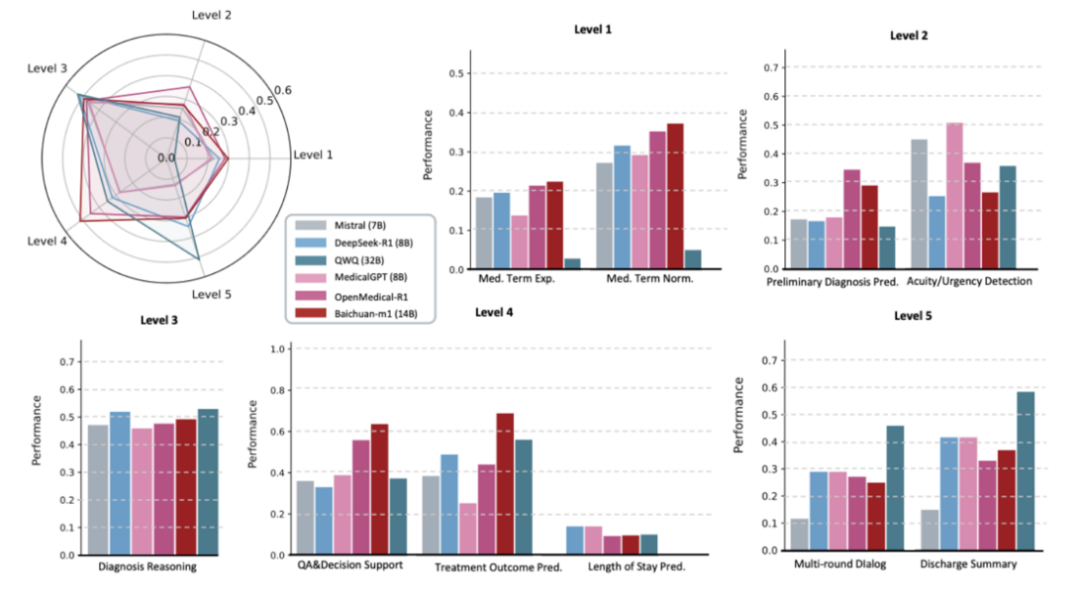
该综述构建了一个包含 5,000 条标注样本的基准数据集,覆盖五个层次的能力要求,并首次系统评测了 18 个代表性模型。
结果显示:
专科模型 → 在诊断类任务上更突出
通用大模型 → 在决策支持、对话和总结上表现更佳
这为未来的模型选择和任务分工提供了实证依据。
前沿方法全景回顾
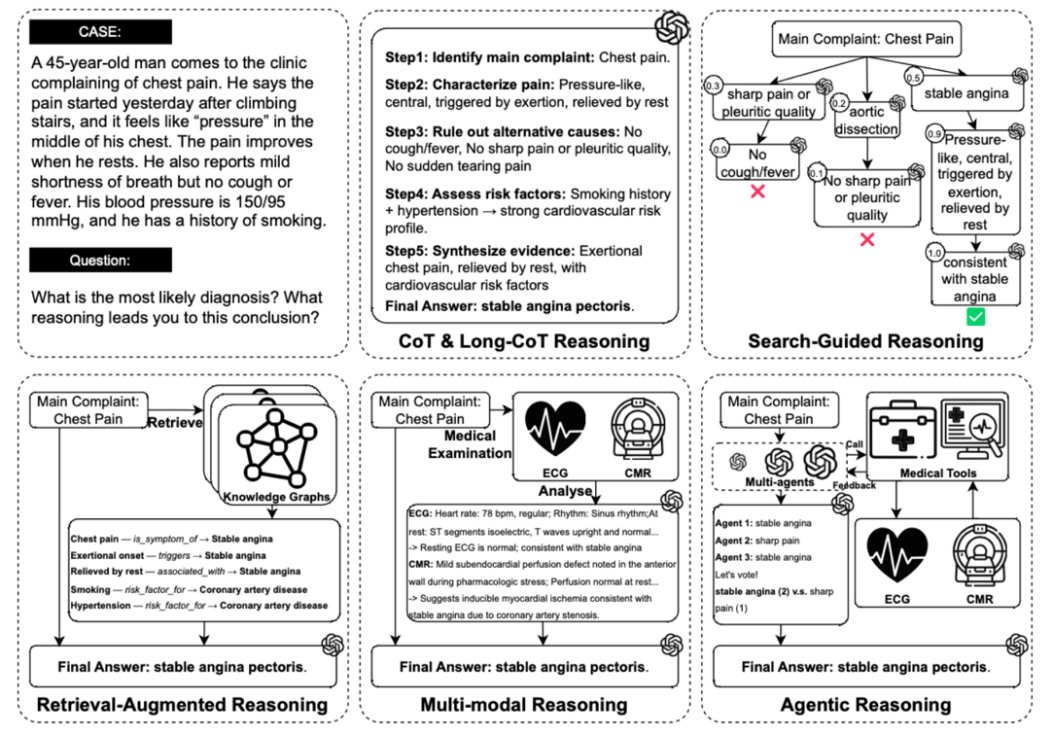
该综述全面回顾了医学 LLM 中的主流推理范式:
链式推理(CoT):逐步解释,思路清晰
长链推理(Long-CoT):更深入的逐步分析,包含自我修正
检索增强推理(RAG):结合医学文献和知识库
多模态推理:同时理解病历、影像和文本
智能体推理(Agentic Reasoning):主动规划、调用外部工具、动态决策
同时,也直面四大挑战:
高质量医学数据不足
「幻觉」问题仍然存在
缺乏证据溯源与临床可解释性
模型结果不确定性难以控制
社会意义
这项工作不仅仅是综述,更是一种「对齐」的尝试:
对齐临床需求:明确医生真正需要的推理能力
对齐 AI 能力:梳理当前模型能做什么、还欠缺什么
对齐未来方向:为科研、产业和医疗实践提供参考
研究团队希望这项工作能推动医学大模型真正落地临床,从「实验室里的聪明模型」变成「病房里的可靠助手」。


