
随着Transformer架构的广泛应用,以GPT为代表的大型语言模型(LLM)在自然语言处理领域取得了突破性进展。这些模型通过"预训练+微调"的范式,在下游任务中展现出强大的性能。
然而,随着模型参数规模从数亿增长到数百亿甚至万亿,全量参数微调(Full Fine-tuning)面临以下挑战:
- 计算资源瓶颈:全量微调需要消耗大量的计算资源和内存
- 存储成本高昂:为每个下游任务单独存储微调模型成本巨大
- 灾难性遗忘:全量微调易导致模型"遗忘"预训练阶段获得的知识
- 过拟合风险:尤其在训练数据有限的情况下,全量微调易出现过拟合
基于上述考量,参数高效微调技术(Parameter-Efficient Fine-Tuning, PEFT)应运而生。这类技术通过仅更新模型的少量参数或引入少量新参数,在大幅降低计算和存储成本的同时,实现与全量微调相当甚至更优的性能。
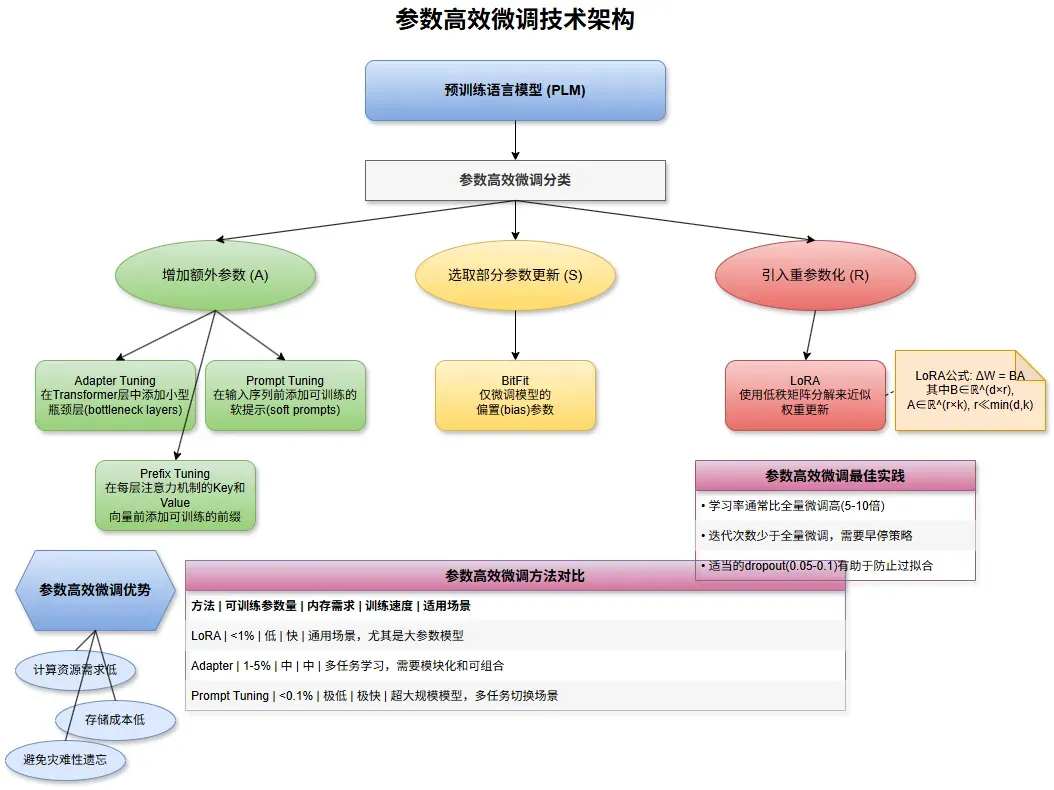
从技术原理角度,参数高效微调技术主要分为三大类:增加额外参数(Additional Parameters),选择性微调(Selective Parameters)重参数化方法(Reparameterization)。
增加额外参数
在预训练模型基础上添加少量新参数,同时冻结原有参数:
Adapter Tuning
Adapter Tuning是最早提出的参数高效微调方法之一。其核心思想是在Transformer的每个层后添加"Adapter模块",该模块通常由两个全连接层组成:
复制输入 → 下投影层(Down-projection) → 激活函数 → 上投影层(Up-projection) → 输出
其中:
- 下投影层将高维特征映射到低维空间(降维)
- 上投影层将低维特征映射回原始维度(升维)
- 整个模块通过残差连接与原始网络连接
设原始模型隐藏层维度为d,Adapter模块中间层维度为r(通常r << d),则单个Adapter模块引入的参数量为2dr,远小于原始层的参数量d²。
优势:
- 模块化设计,可为不同任务训练不同的Adapter
- 可在多个层次添加Adapter,如自注意力层后、前馈网络层后等
- 结构简单,实现容易
Prompt Tuning和P-Tuning
Prompt Tuning和P-Tuning都属于"软提示"(Soft Prompts)方法,通过学习连续的嵌入向量作为模型输入的一部分。
Prompt Tuning在输入序列前添加可训练的"提示标记"(prompt tokens),其仅训练这些提示标记的嵌入,而冻结所有预训练模型参数; 提示标记数量通常为10-100个,引入的参数量很小。
P-Tuning类似Prompt Tuning,但使用小型神经网络(如LSTM)来生成提示标记的嵌入,增强了提示标记之间的关联性,提升了性能。
优势:
- 参数量极少,通常只有几万个参数
- 适用于超大规模模型,如千亿参数级别的模型
- 多任务场景下只需切换不同的提示嵌入
Prefix Tuning
Prefix Tuning是对Prompt Tuning的扩展,不仅在输入层添加可学习的前缀,还在Transformer的每一层都添加:
- 在注意力层的Key和Value向量前添加可训练的前缀向量
- 前缀向量通过小型MLP生成,而非直接优化,以增强稳定性
- 所有其他参数保持冻结状态
这种方法本质上是"软提示"和"Adapter"的结合,既在输入端也在中间层引入可学习参数。
选择性微调
这类方法通过选择模型中的部分参数进行更新,其余参数保持冻结。
BitFit是一种极简的方法,仅微调模型中的偏置(bias)参数:
- 冻结所有权重矩阵,只更新偏置项
- 偏置参数通常仅占模型总参数的<1%
- 实现简单,几乎不增加额外内存开销
尽管简单,在多种NLP任务中表现良好,尤其适合资源受限场景。
重参数化方法
这类方法通过低秩分解等技术重参数化模型权重矩阵。
LoRA是目前最流行的参数高效微调方法之一,其核心思想是使用低秩矩阵来表示预训练权重的更新。
LoRA的核心假设是模型权重的更新矩阵具有低秩特性,即重要的更新可以被低维度的信息捕获。
实现时,LoRA通常应用于注意力机制中的Query、Key、Value矩阵以及MLP中的线性层,而预训练参数保持冻结。
优势:
- 参数量大幅减少(仅需(d+k)r个参数,而非dk个)
- 训练稳定,收敛快
- 可以针对不同任务训练不同的LoRA权重,并快速切换
- 与其他PEFT方法兼容,如Adapter、Prefix Tuning等
LoRA微调技术深入分析
由于LoRA是目前应用最广泛的参数高效微调方法,下面我们深入分析其技术细节和最佳实践。
LoRA的核心是使用低秩分解来近似权重更新:
复制ΔW = BA
其中B和A是小型矩阵,秩r是一个超参数,控制着适应能力和参数效率的权衡。
在前向传播中,输入x经过LoRA处理的计算为:
复制h = Wx + ΔWx = Wx + BAx
以下是使用PyTorch实现简单LoRA的代码示例:
复制class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank=8, alpha=8):
super().__init__()
self.W = nn.Parameter(torch.zeros((out_dim, in_dim)), requires_grad=False) # 冻结的预训练权重
self.A = nn.Parameter(torch.zeros((rank, in_dim))) # 低秩矩阵A
self.B = nn.Parameter(torch.zeros((out_dim, rank))) # 低秩矩阵B
self.alpha = alpha
self.rank = rank
# 初始化
nn.init.normal_(self.A, std=0.02)
nn.init.zeros_(self.B) # B初始化为0,使得ΔW初始为0
def forward(self, x):
# 原始权重前向传播 + LoRA更新
return F.linear(x, self.W) + (self.alpha / self.rank) * F.linear(F.linear(x, self.A.T), self.B.T)参数高效微调的最佳实践
选择LoRA,适合需要接近全量微调的性能,同时有适度的计算资源,需要快速切换不同任务适配器。
选择Adapter,适合需要模块化和可组合的架构,且在多任务场景且不同任务之间差异较大。
选择Prompt Tuning,适合处理超大规模模型(>100B参数),并且资源极度受限,而任务与预训练目标相似。
选择BitFit,适合计算资源极度受限且任务相对简单。
超参数调优建议
对于学习率的选择,通常比全量微调高,如原学习率的5-10倍。对于LoRA,一般1e-3到5e-3通常效果良好。
微调通常需要的迭代次数也少于全量微调,且早停策略非常重要,避免过拟合。
对于LoRA和Adapter,适当的dropout(0.05-0.1)有助于防止过拟合,对于Prompt Tuning,可能需要更强的正则化。
参数高效微调的未来发展
参数高效微调技术仍在快速发展中,仍然存在很多的探索空间。
比如自动化架构搜索,自动确定最佳的适配器配置和位置。多模态扩展,将PEFT技术扩展到视觉、音频等多模态模型。硬件感知优化,针对特定硬件(如GPU、TPU)优化的适配器设计。或者与其他技术结合:与量化、蒸馏等技术结合,进一步提高效率。
写在最后
参数高效微调技术已成为大型语言模型应用的关键技术,它不仅解决了计算资源和存储成本问题,还提供了灵活的模型适应机制。通过选择合适的PEFT方法并遵循最佳实践,可以在资源有限的条件下实现接近甚至超越全量微调的效果,为大模型的广泛应用和个性化定制铺平了道路。
随着模型规模持续增长,参数高效微调的重要性将进一步提升,成为连接通用大模型和特定应用场景的关键桥梁。
2025年的今天,AI创新已经喷井,几乎每天都有新的技术出现。作为亲历三次AI浪潮的技术人,我坚信AI不是替代人类,而是让我们从重复工作中解放出来,专注于更有创造性的事情,关注我们公众号口袋大数据,一起探索大模型落地的无限可能!


