
译者 | 晶颜
审校 | 重楼
大型语言模型(LLM)正在重塑人工智能的格局,然其亦面临一项持续性挑战——检索和利用超出其训练数据的信息。目前,有两种模式相左的方法可以解决这个问题:其一为InfiniRetri,该方法借助LLM自身的注意力机制,从长输入中检索相关上下文;其二是检索增强生成(RAG),它在生成响应前,动态地从结构化数据库获取外部知识。
每种方法都有其独特的优势、局限性和权衡之处。InfiniRetri的目标是通过在模型现有架构内工作来最大限度地提高效率,而RAG通过集成实时外部信息来提高事实准确性。但究竟哪一种方法更优呢?
了解这两种方法的运行机制,优势及局限所在,对于确定它们在未来人工智能驱动的文本生成中的作用至关重要。
InfiniRetri和RAG如何检索信息
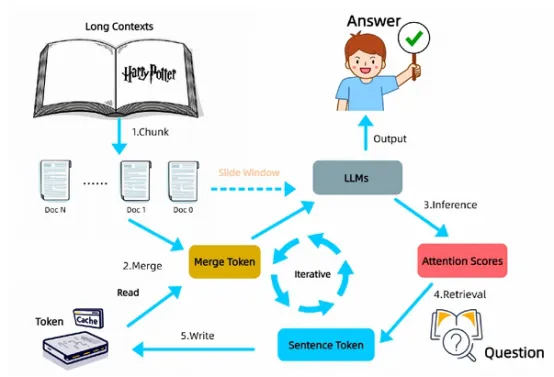
InfiniRetri通过利用基于转换器(Transformer)模型的原生注意力机制来动态地从长上下文中检索相关的令牌。它并非无限制地扩展模型的上下文窗口,而是迭代选择并仅保留最重要的令牌,从而能够在优化内存效率的同时,处理显著更长的输入。
标准LLM处理有限长度的输入,一旦超出上下文窗口就会丢弃先前的信息,而InfiniRetri使用滚动存储系统。它按段处理文本,识别并仅存储最相关的令牌,同时丢弃冗余信息。这使得它可以有效地从大量输入中检索关键细节,而不需要外部存储或数据库查找。
在诸如“大海捞针”(Needle-In-a-Haystack,NIH)测试等受控检索场景中,InfiniRetri已经展示了超过100万个令牌的100%检索准确率,凸显其在极长上下文中追踪关键信息的能力。然而,这并不意味着它在所有任务中均能达到完美的准确性。
另一方面,RAG采用了一种完全不同的方法,它使用外部检索步骤来扩展模型。当出现查询时,RAG首先搜索知识库——通常是矢量数据库、文档存储库或搜索引擎——以查找相关的支持文档。
然后将这些检索到的文本附加到LLM的输入中,使其能够生成基于实时外部信息的响应。该方法确保模型能够访问新的、特定于领域的知识,使其比纯参数模型更不容易产生幻觉。
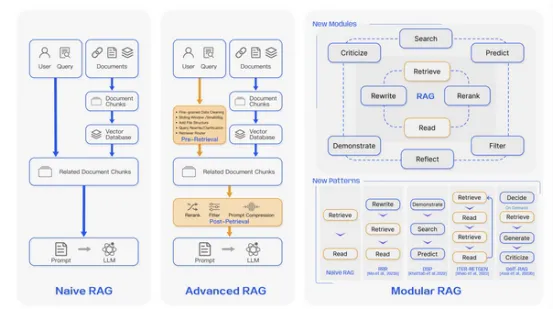
两者的关键区别在于检索发生的位置。InfiniRetri从内部检索先前处理过的文本,而RAG从外部检索结构化知识库。这一差异对性能、效率及可扩展性均会产生重大影响。
哪种方法更有效?
InfiniRetri和RAG之间的性能比较揭示了在效率、准确性和计算需求方面的鲜明对比。InfiniRetri能够在自身架构内动态检索信息,这使其无需额外的基础设施即可运行,即无需外部存储、检索器或微调嵌入。这使得它成为长文档处理的绝佳选择,尤其是当相关信息已经包含在提供的输入之中时。
然而,InfiniRetri也确有局限性。由于它只在模型的注意力机制内运行,因此完全依赖于LLM预先存在的知识。如果一条信息并未包含在模型的训练或输入中,则无法被检索到。这使得infinireti在回答需要最新知识的基于事实或实时查询时效率较低。
相反地,RAG擅长知识密集型任务。因为它从外部数据库中提取信息,所以它可以用真实的、实时的信息来补充模型的预训练知识。这使得它在对准确性要求较高的法律文件处理和研究应用中非常有效。
然而,RAG对外部检索的依赖也带来了更高的计算成本,具体取决于所使用的检索方法。此外,外部查询会引入延迟,且延迟会随数据库大小而变化。在LLM生成响应之前,每个查询都需要进行数据库搜索、文档检索和扩展,这使得LLM在连续长文本处理方面明显慢于InfiniRetri。
在计算效率方面,InfiniRetri具有明显的优势。由于它在内部检索信息而无需对外部系统调用API,因此它的运行延迟较低,基础设施需求较少。同时,RAG虽然功能强大,但受到其检索器效率的限制,必须对其进行微调以确保高召回率和相关性。
哪一个符合你的需求?
虽然这两种方法在各自的领域都非常有效,但都并非“放之四海而皆准”的解决方案。InfiniRetri最适合需要高效长文档检索但不需要外部知识更新的应用程序。这包括法律文件分析、多回合对话保留和长格式摘要。它选择和保留相关标记的迭代方法使长文本处理高效,而不会占用大量内存,使其成为叙事一致性和基于推理的任务的强大选择。
另一方面,RAG是现实世界信息检索的理想选择,在准确性和事实核查至关重要的情况下表现突出。它对于开放领域的问答、基于研究的应用以及必须将幻觉风险降至最低的行业十分有效。因为它从外部来源检索,所以它确保响应保持在可验证的事实基础上,而不是依赖于模型的静态训练数据。
但是,RAG需要不断维护其检索基础结构。更新外部数据库对于保持准确性至关重要,而管理索引、嵌入和存储可能会带来极大的操作复杂性。此外,延迟也是一个主要问题,因为检索时间随着数据库大小的增加而增加,这使得它不太适合速度至关重要的实时应用程序。
这些方法会合并吗?
随着人工智能研究的不断进步,未来的检索很可能不会是InfiniRetri和RAG之间的竞争,而是两者的结合。混合方法可以利用InfiniRetri高效的基于注意力的检索来处理长文档,同时在必要时结合RAG获取实时外部知识的能力。
一个颇具前景的方向是自适应检索模型,LLM首先尝试使用InfiniRetri的方法进行内部检索。如果它确定缺少必要的信息,就会触发一个外部的类似于RAG的检索步骤。这将平衡计算效率和准确性,减少不必要的检索调用,同时在需要时仍能确保基于事实的依据。
另一个开发领域是智能缓存机制,通过RAG从外部检索到的相关信息,可以在内部使用InfiniRetri的注意力技术进行存储和管理。这将允许模型在多个交互中重用检索到的知识,而不需要重复的数据库查询,从而减少延迟并提高性能。
为工作选择合适的工具
在InfiniRetri和RAG之间做出选择,将最终取决于给定应用程序的特定需求。如果任务需要快速、高效和可扩展的长上下文检索,InfiniRetri无疑是赢家。如果任务需要实时事实检查和外部知识扩充,RAG将是最佳选择。
虽然这两种方法各有优势,但实际上它们可以互补,特别是在混合系统中,动态平衡内部基于注意力的检索和基于任务需求的外部知识增强。未来的检索系统可能会整合两者的优势,从而产生更强大、适应性更强的人工智能模型。比起“非InfiniRetri 即RAG”的问题,LLM检索的真正未来可能是InfiniRetri和RAG协同工作。
原文标题:Breaking the Context Barrier of LLMs: InfiniRetri vs RAG,作者:Graziano Casto


