
译者 | 陈峻
审校 | 重楼
目前,数据科学家们已经熟悉了那些以不同的文件格式作为处理输入与输出的各类机器学习模型。在大多数情况下,人工智能智能体(AI agent)都需要通过维护上下文,从人机交互中学习,以及按需访问其他模型无法处理的海量知识存储。这无疑需要庞大的内存架构。
你可以试想这样的数字:GPT-4 的 128k 令牌限制,就相当于大约 96,000 个单词。这样的限制,对于那些需要与整个馆藏资料打交道的学术研究助理、或每天管理数千笔交易的客户服务代表来说,是极具挑战的。他们其实需要的是更加智能化的内存架构,而不是更大的上下文窗口。
这便是向量数据库的用武之处,它可以成为AI基础架构中必不可少的部分,将“语义记忆”的模糊问题转化为数据科学家所理解的高维相似性搜索的精确领域。下面,让我们来详细了解一下。
从特征工程到语义嵌入
嵌入(Embeddings),是从标准的机器学习到智能体内存系统转变的第一步。现代化嵌入模型如同智能特征提取器,可以将普通语言转换为丰富且有意义的表示形式。
而神经嵌入代表的是连续空间中的语义链接,与 TF-IDF 和 n-gram 等稀疏且脆弱的特征并不相同。其中,OpenAI 的 text-embedding-3-large 是将“机器学习模型部署”转换为具有余弦相似性的 3072 个维向量,以满足人类语义相关性的各类评估。
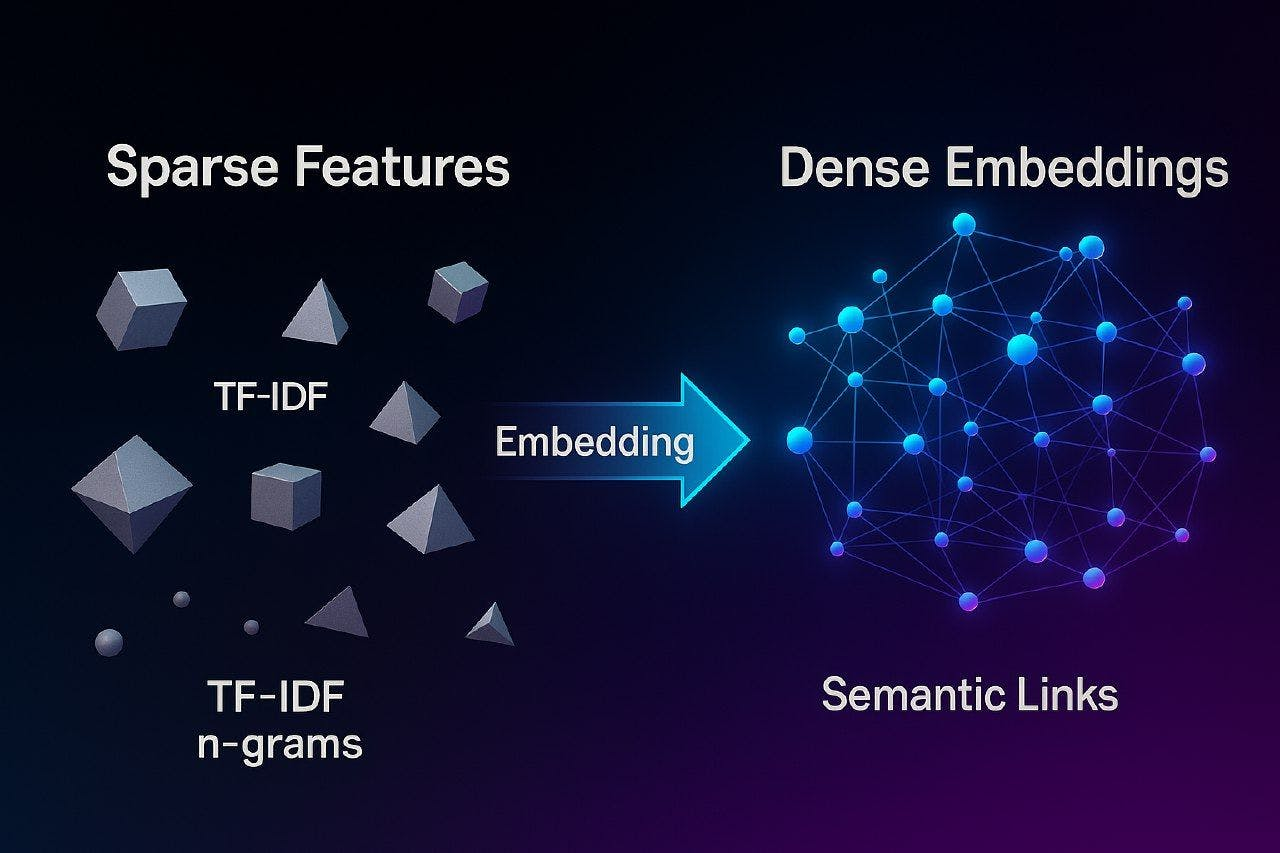
从稀疏特征到密集语义嵌入
实际上,我们已能够将定性相似性(即,某些文档具有相似的主题)转换为可量化的距离测量值,进而测量、优化、以及系统性地改进这些测量值。这也是数据科学的研究基础。
矢量数据库:基础设施层
当前,向量数据库已经解决了当你在需要实时搜索数百万个高维嵌入时出现的可扩展性挑战。作为数据科学家,我们可以将它们视为针对相似性查询(而非聚合进行优化)的专用 OLAP 系统。
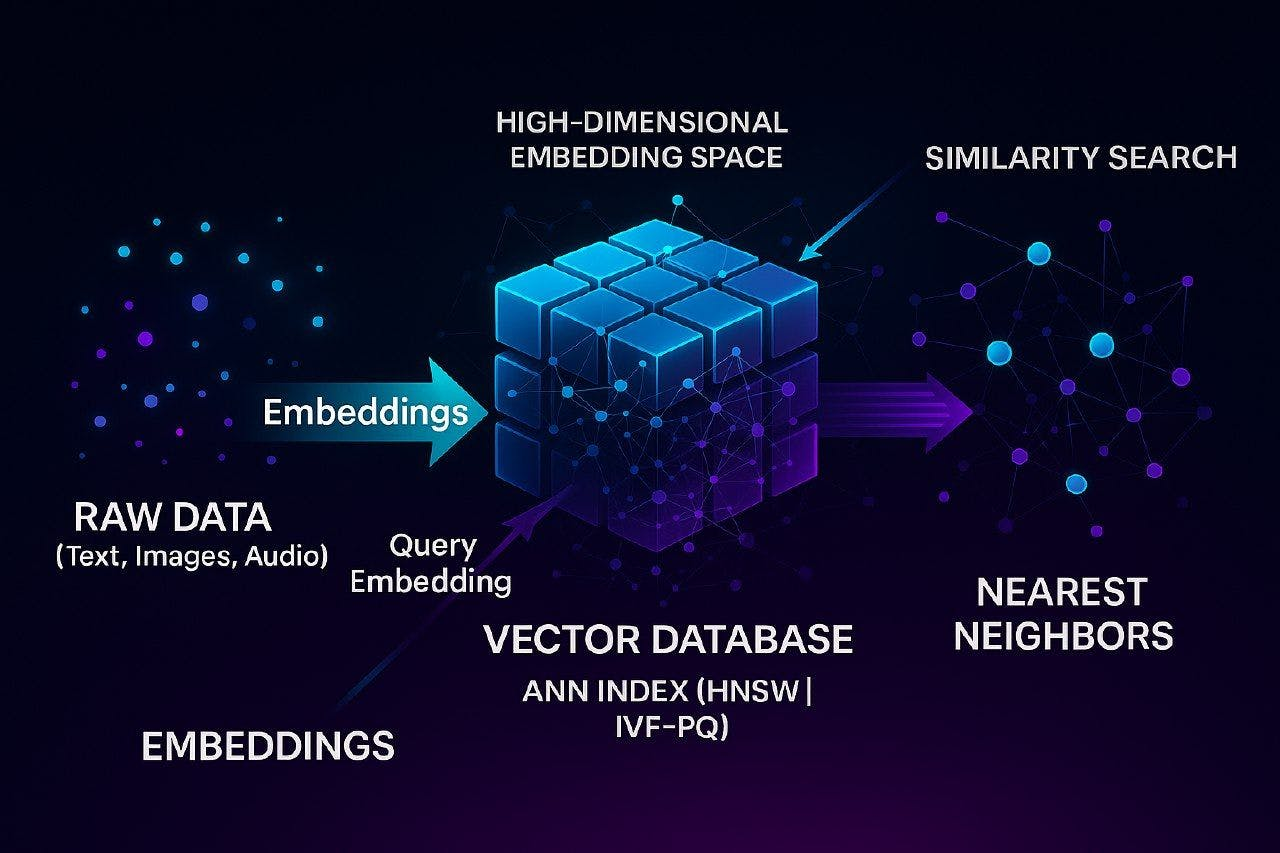
矢量数据库的工作流
不过,此类矢量数据库面临的核心技术挑战,恰好是我们在其他领域已解决的问题:如何在不进行详尽比较的情况下,有效地搜索高维空间?而且当维数的量级超过大约 20 个的时候,维度的诅咒便会使得传统的基于树的索引(如,KD 树、球树)变得毫无用处。
在此基础上,现代化的矢量数据库采用了复杂的索引策略:
- HNSW(分层可导航小世界,Hierarchical Navigable Small World):构建一个多层图形,其中每个节点都连接到其最近的邻居节点上。这主要是因为搜索的复杂性会按照对数的方式,以及数百万个向量的请求来扩展。因此,在大多数情况下,这些请求可能会在不到 100 毫秒的时间内被完成。
- IVF-PQ(具有乘积量化的倒置文件,Inverted File with Product Quantization):通过对向量空间进行聚类并采用学习压缩(learnt compression),它可以将内存占用减少 75%,同时保持较强的召回率。这便是我们从机器学习模型调整中获悉到的经典精度召回率(precision-recall)的优化--使用其中一些准确性换取了巨大的可扩展性。
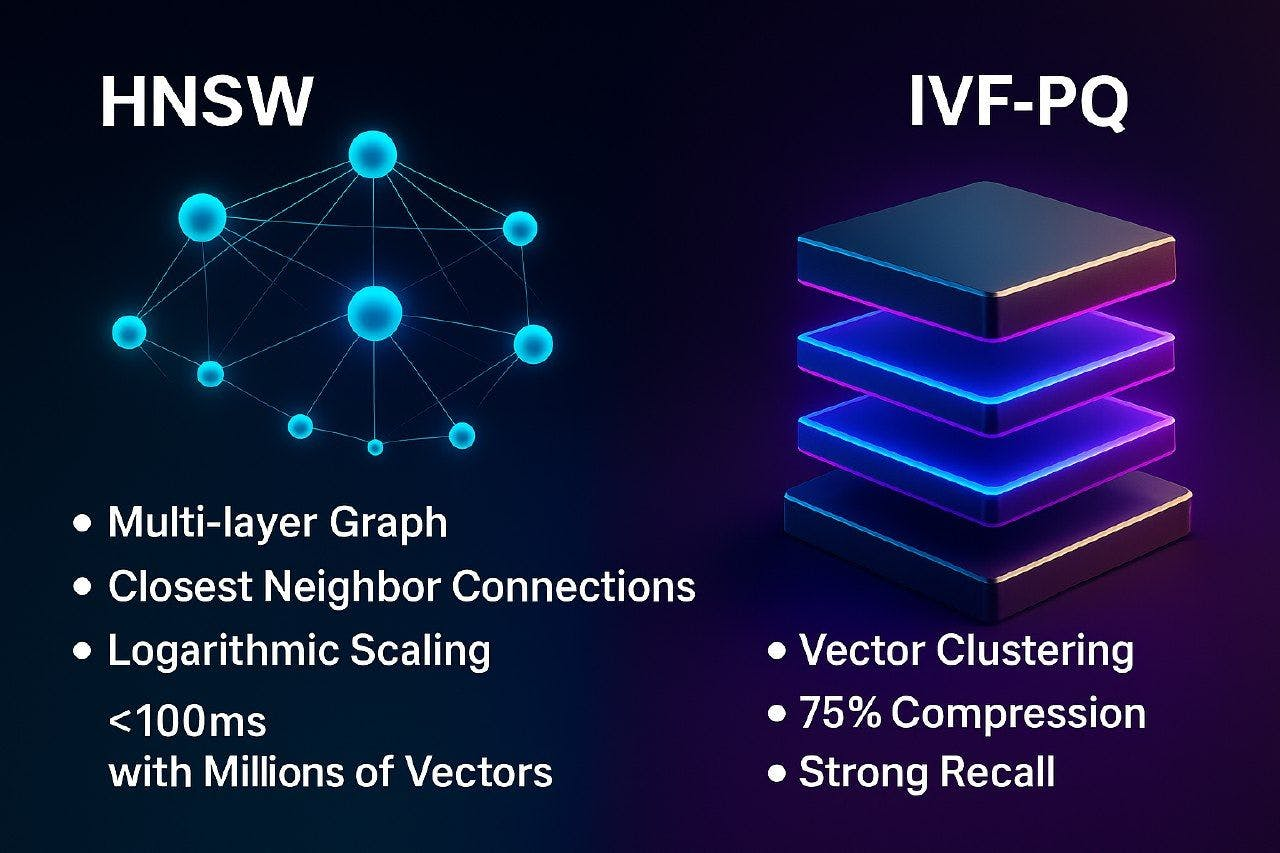
HNSW 与 IVF-PQ
当然,影响选择上述方法的因素往往涉及到对延迟与吞吐量、内存与准确性、以及成本与性能等诸多数据因素的了解与科学权衡。
内存架构:情景存储与语义存储
借鉴认知心理学研究,有效的智能体记忆系统实现了反映人类记忆模式的双重存储机制,即:
- 情景记忆,存储了原始的、带有时间戳的交互。这些交互不限于每一次对话回合、工具的执行、以及环境观察等属性。它为调试、审计跟踪和上下文重建提供了完美的调用。从数据科学的角度来看,我们可以将其视为“原始数据湖”,它不会丢失或转换任何内容。
- 语义记忆,包含了从情景体验中提取的结构化知识。基于此,智能体存储了从有关用户、领域知识、以及行为模式中学习到的事实。与机器学习管道中的特征存储类似,语义记忆提供了对已处理的见解的快速访问。
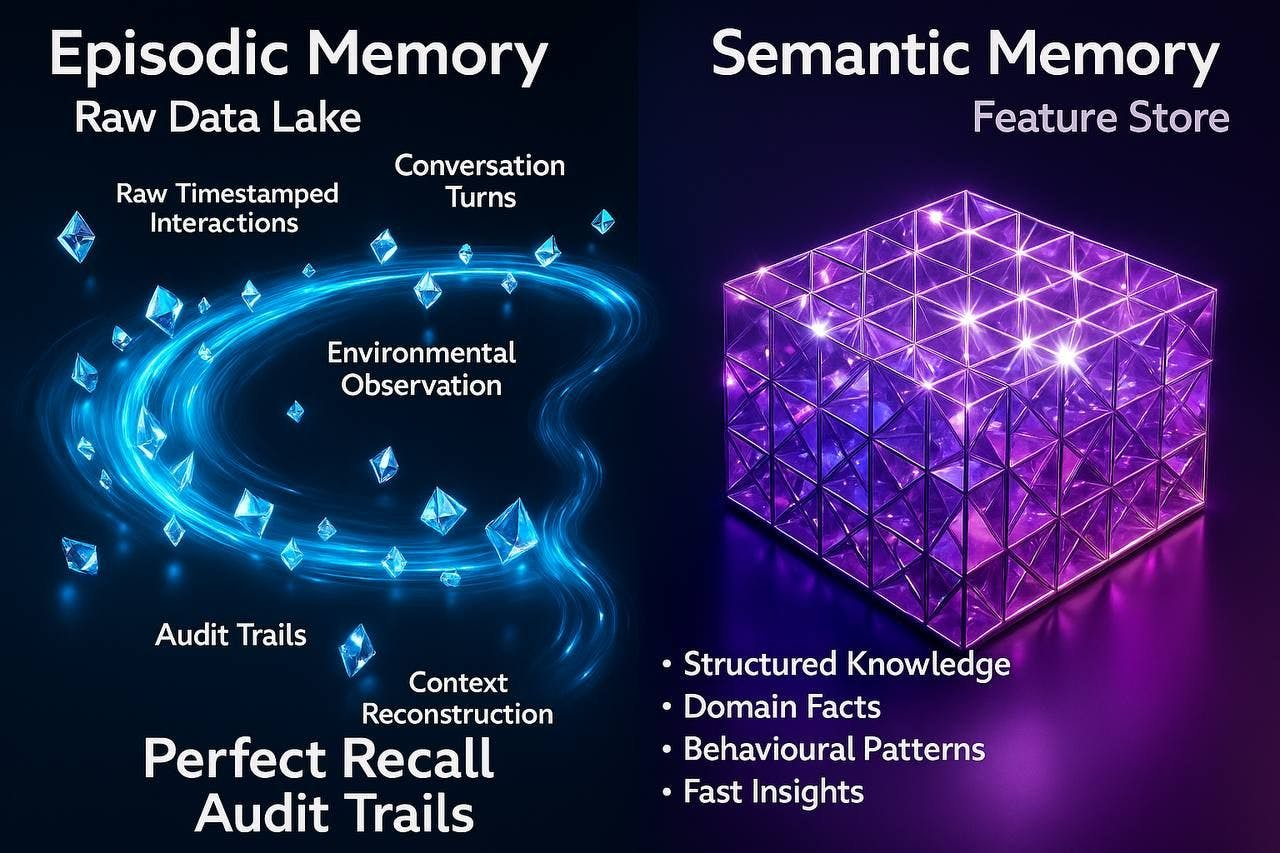
情景记忆与语义记忆
可见,这些不同的记忆模式不仅可以被使用在不同的数据库中,而且能够服务于不同的分析目的,并且具有不同的保留、更新和查询模式。
用于设计和评估的架构
为了让智能体能够提供有效且能产生预期结果的记忆系统,我们从数据科学角度通过如下方面来设计内存架构:
- 检索质量:使用人工标记的相关性评级来衡量recall@k(信息检索和推荐系统中常用的评价指标)和平均倒数排名 (Mean Reciprocal Rank,MRR)。在该架构中,我们不会进行一般性的猜测和测量,而是会描述智能体应该如何实际处理查询的测试集。
- 从开始到结束的性能:在该架构中,我们需要跟踪完成了多少任务,检查用户的满意度,以及响应的效率。同时,为了衡量答案质量的变化,我们还应使用 BLEU、ROUGE 或语义相似性指标之类的工具。
- 系统性能:我们需要密切关注安装成本、存储增长量、查询延迟分布方式、以及基础结构增长情况。这些实用的指标通常会比纯粹准确性的衡量标准更重要。
- 消融研究(Ablation studies):我们可以通过移除部分组件来验证其必要性,进而确保以有计划的方式,更改嵌入模型、块大小、恢复方法、以及上下文压缩技术。显然,这将有助于确定哪些部分可以带来更好的速度,以及哪些部分需要被调整。
提高效率的模式和策略
- 混合检索:使用这种检索方法,我们可以确保密集矢量从搜索开始,使用 BM25(Best Matching 25,一种信息检索领域的经典算法)进行稀疏关键字匹配,以获得各种查询的良好结果。其实,我们正是从模型堆叠中获悉了这种模式:这种组合方法通常比单独使用任何一种方法都更有效。
- 动态分配上下文:我们通过设置学习的规则,根据查询的复杂性、用户的过往交互、以及作业的需求,来更改上下文窗口的使用方式。这将从效率上解决静态资源的分配问题。
- 进行小的更改:对特定于某些智能体的数据,我们使用对比学习,使得通用嵌入模型更适应用户所在的区域。毫不夸张地说,目前市场上已经上市的模型可能没有几个能够达到该模型的准确水平(通常仅达到其15-30%)。
可能面临的挑战
- 管理成本:将 API 放入文本中,会使得成本随着文本量的增加而直接上升。智能的分块计划、压缩方法、以及精心添加的高价值内容都需要成本。为此,我们需要持续监控每位用户所增加的费用,并设置警报,以便在超出限额时能及时发出通知。
- 数据质量:矢量系统可能会使得数据质量问题变得更糟。例如,无法正常工作的分块、不均匀的风格、以及难以阅读的文本都会减慢系统的运行速度。此外,我们还要确保结果质量得到跟踪,并确保数据能够正确地使用类似于机器学习功能的管道。
- 安全保障:采用嵌入的方式会跟踪源文本的含义,这可能会带来安全方面的风险。我们应对此考虑不同的隐私设置、访问控制、以及保存数据的规则,使之既实用又合法。
小结
作为新兴的学习和适应智能系统的基础,数据科学家不仅可以使用矢量数据库作为工具来创建 AI 聊天机器人,也能够利用其逻辑来创建一套智能体内存,以监控系统、协调测试、并加快响应。面对复杂的系统开发与变化,我们不是要改进某一个模型,而是要构建出由多个协同工作能力的 AI 部件组成的分布式内存架构,让更多单打独斗的AI系统转变成协同服务的AI智能体。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:LLMs + Vector Databases: Building Memory Architectures for AI Agents,作者:Lanre Shittu


