在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。
当前,这些内核通常由开发者使用 CUDA、AscendC、Pallas 等硬件专用并行编程语言手工编写 —— 这要求开发者具备精湛的性能调优技巧,并对底层硬件架构有深入理解。
近年来,大语言模型(LLM)在代码生成领域的突破,使 “自动生成高性能深度学习内核” 成为新的研究热点。KernelBench、TritonBench 等评测基准相继出现,主要聚焦于评估 LLM 在 NVIDIA GPU 内核生成上的表现。
已有研究表明,现有 LLM 已具备一定的 GPU 内核生成能力。例如,英伟达工程师基于 DeepSeek-R1 设计了一套工作流程,在简单的 CUDA 内核生成任务中,该流程生成的内核在数值上全部正确,达到了 100% 的通过率。
然而,当前 AI 加速器架构日趋多样(如 NVIDIA GPU、华为昇腾 NPU、Google TPU、Intel GPU 等),其底层内核语言差异显著。现有评测基准普遍存在平台覆盖单一、评估维度粗糙、可扩展性不足等局限。在此背景下,关键问题浮现:大模型在 CUDA 生态下的优势能否有效迁移至异构平台?我们距离自动化生成高性能计算内核究竟还有多远?
针对这些问题,近日,南京大学与浙江大学联合推出全新开源评测框架 MultiKernelBench,打破平台、维度与扩展性的限制,为 LLM 驱动的高性能内核生成提供了新的测评标准。

论文链接:https://arxiv.org/pdf/2507.17773
代码链接:https://github.com/wzzll123/MultiKernelBench
MultiKernelBench 提出了一个开放评测场景:在 GPU、NPU、TPU 等多平台上,LLM 自动生成高性能深度学习内核,并在真实设备中完成编译、运行与性能验证。它首次跨越单一硬件生态,推动 LLM 从 “单平台选手” 迈向 “全能型选手”。
值得注意的是,MultiKernelBench 的设计充分考虑了算子多后端的可扩展性。例如,Intel 工程师基于该框架高效地实现了 Intel GPU 的适配。
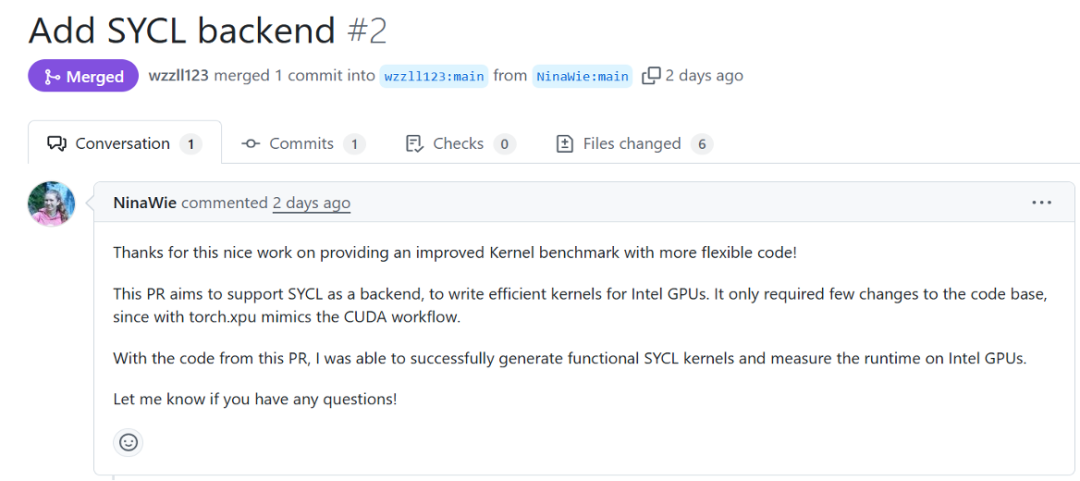
MultiKernelBench 是如何构建的?
为了确保任务覆盖全面且具有可扩展性,研究团队设计了一套模块化评测体系,包含四大核心特性:
1、 跨硬件平台支持
首批覆盖三大主流架构:
NVIDIA GPU(CUDA / Triton)
华为昇腾 NPU(AscendC)
Google TPU(Pallas)
通过统一 Backend 接口与装饰器机制,实现无需修改核心逻辑即可快速接入新平台。
论文作者后续计划逐步扩展对不同 GPU 和 NPU 厂商架构的支持,同时也诚邀各厂商参与开源生态的共建。
2、 细粒度任务体系
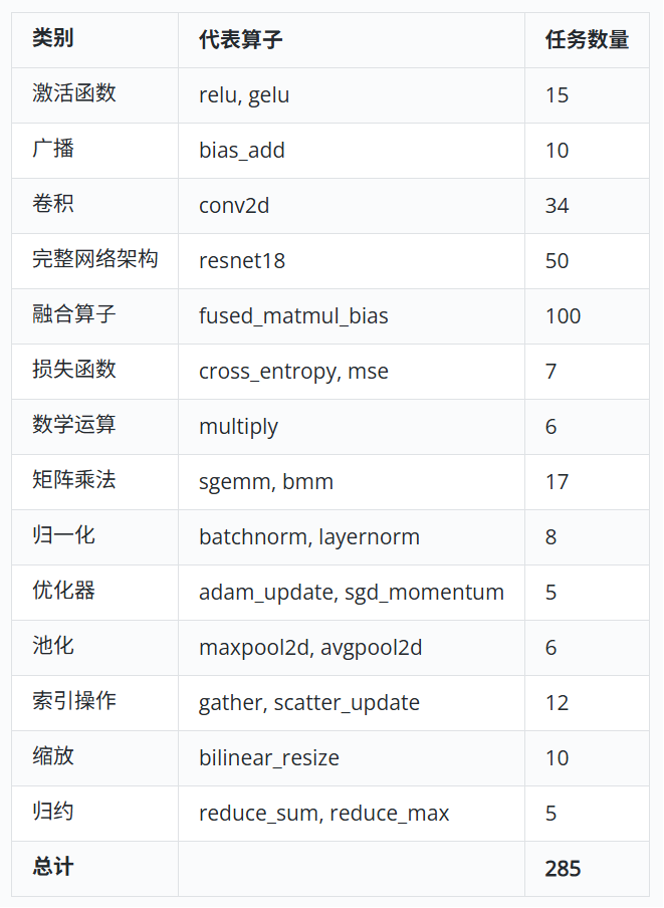
在 Stanford KernelBench 基础上重构分类框架,覆盖 14 类核心深度学习算子(卷积、归一化、优化器、稀疏计算等),不仅继承了 250 个经典任务,还新增 35 个未被现有基准覆盖的关键算子,全面反映 LLM 在不同算子类型上的生成能力。
3、 端到端自动化评测
构建标准化流程:内核生成 → 编译 → 硬件执行 → 性能分析,确保在真实硬件环境中完成全流程验证。
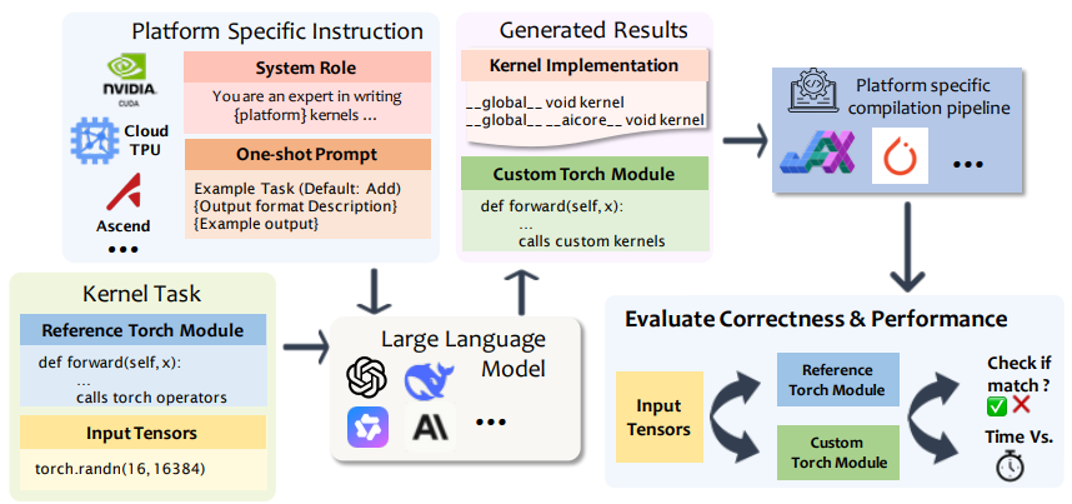
4、 类别感知 One-shot 提示策略
针对不同算子类别动态选取典型样例作为上下文提示,显著提升生成代码的语义相关性与功能正确性,尤其在 AscendC、Pallas 等训练语料稀缺的平台上效果显著。
此外,MultiKernelBench 提供插件式提示模板系统,方便研究者探索多样化的提示工程策略。
对比现有基准,MultiKernelBench 带来三大突破:
平台覆盖更广:打破对单一生态的依赖,真正实现跨 GPU / NPU / TPU 的统一评测。
评估维度更细:任务分类粒度精细化,可定位 LLM 在不同算子类型上的优势与短板。
扩展性更强:模块化架构与统一接口设计,使其能够伴随 AI 硬件生态快速演进。
多模型实测,模型表现如何?
基于 MultiKernelBench,评估了包括 GPT-4o、Claude、DeepSeek-V3、Qwen 等在内的 7 个主流大模型,参数规模涵盖 32B ~ 681B。
评估指标包括:
Compilation@k:生成代码是否能成功编译
Pass@k:是否输出功能正确的结果
SpeedUp@k:运行时是否实现性能优化
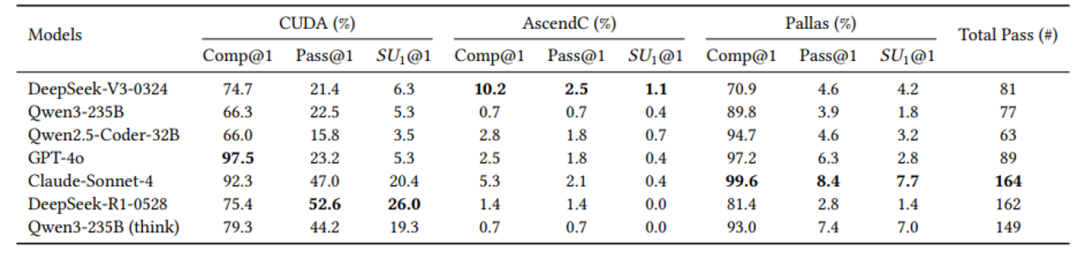
实测结果显示:
Claude-4-Sonnet 在整体评测中表现最佳;推理模型表现优异。
CUDA 平台的 Kernel 执行通过率显著高于 Pallas 与 AscendC,反映出当前 LLM 对 CUDA 更具适应性。
类别感知式 Prompting 明显优于通用模板,尤其在 AscendC 等训练语料较少的平台上,能显著提升生成效果与成功率。
展望与未来计划
MultiKernelBench 的评测结果表明,即便是当前最先进的大语言模型(LLM),在多平台高性能内核生成任务中仍存在明显短板:在非 CUDA 平台上的成功率显著下降,生成代码的性能也普遍落后于手工优化版本。
未来,论文作者希望与社区共同推进 MultiKernelBench 的演进,重点探索以下方向:
更智能的提示策略:利用已有的插件式提示模板系统,开发反馈式、文档增强等新型提示方法,提升低资源平台的生成质量。
跨平台协同生成:实现多平台版本的同步生成与优化思路共享,增强跨架构泛化能力。
支持更多硬件后端:与社区合作接入更多新平台,进一步覆盖异构计算全景。
目前,MultiKernelBench 的全量数据集、框架代码与评测流程已全部开源,欢迎研究者与工程师提出新方法、贡献平台支持,共同推动多平台高性能内核自动生成的发展。