美国网络安全巨头CrowdStrike和Meta凑到一块,在拉斯维加斯的Fal.Con 2025大会上宣布,联合推出了一个叫CyberSOCEval的开源基准测试套件。

这东西干嘛的?就是一张给所有号称能做网络安全的AI大语言模型准备的考卷,专门考它们在真实的安全运营中心(SOC)环境下,到底能不能打。
咱得有个标准
干网络安全防御,一边是堆积如山的安全警报,多得像永远处理不完的垃圾邮件;另一边是攻击者的手段花样翻新,速度比时尚圈出新款还快。
大家都指望AI来救场,尤其是大语言模型,能自动化处理任务,把安全运营效率提升。可问题来了,市面上那么多AI系统,到底谁有真本事,谁是花架子?安全团队想选个靠谱的AI帮手,全凭感觉和厂家的宣传,心里一点底都没有。
在真实的黑客攻击面前,哪个AI能派上用场?哪个应用场景最有效?性能要达到什么标准才算及格?之前,没人能说清楚,行业里缺一把公认的尺子。
CyberSOCEval的出现,就是为了解决这个大麻烦。它给所有安全团队和模型开发者提供了一个统一的评估框架。
巨头联手,不只是喝杯咖啡
CrowdStrike,是全球市值最大的网络安全上市公司之一,它的Falcon(猎鹰)平台保护着全球顶级的银行、医院和政府机构,手里攥着海量的、来自一线攻防现场的威胁情报和数据。它最懂黑客是怎么干活的。
而全球AI研究的领头羊Meta,手握顶尖的AI算法和庞大的数据集。它最懂怎么训练和评估AI模型。
一个出题,一个出考纲,这俩凑一块,就给AI时代的网络安全防御定了个新方向。他们把这套“考卷”直接开源,放在Meta的PurpleLlama项目上,让全世界的安全专家和开发者都能用,都能参与改进。
CrowdStrike的首席业务官Daniel Bernard说得很直接,这是在定义AI时代网络安全的方向。Meta的产品总监Vincent Gonguet也表示,他们致力于推进开源AI的好处,这次合作就是为了让行业能更快地释放AI的潜力,保护大家免受高级攻击,甚至是那些由AI驱动的威胁。
CyberSOCEval是在Meta之前的CyberSecEval框架基础上扩展而来,专门针对安全运营中心(SOC)的关键工作流程设计。主要针对恶意软件分析(Malware Analysis)和威胁情报推理(Threat Intelligence Reasoning)。
恶意软件分析评估的是一个大语言模型看到一段可疑的代码或者行为描述时,能不能准确识别出它是不是个坏东西,比如是不是勒索软件,或者是不是一个远程访问木马(RAT)。
数据来自CrowdStrike多年来积累的真实恶意软件样本和威胁情报数据。这确保了内容不是纸上谈兵,而是模拟了SOC分析师每天都要面对的真实挑战。
威胁情报推理评估的是AI在阅读一篇非结构化的威胁情报报告后,能不能自己提炼出有用的、可操作的信息。比如,从一篇安全公告或者对手战术分析报告里,找出攻击者的关键指标,判断这是哪个黑客组织干的,预测他们下一步可能要攻击哪里。
数据都是真实世界的威胁情报文本,包括MITRE ATT&CK框架的描述、各种行业安全报告等。
真防得住吗?还帮倒忙?
CyberSOCEval的评估体系,继承了Meta CyberSecEval 3框架的精髓。这个框架的视角很全面,它把AI的风险分成了两大类:一类是对别人的风险,比如AI会不会被坏人利用去发动攻击;另一类是对开发者和用户自己的风险,比如AI会不会生成不安全的代码,留下后门。
下面这张表,就总结了CyberSecEval 3框架关注的一些主要风险维度,它也是CyberSOCEval的技术基础。
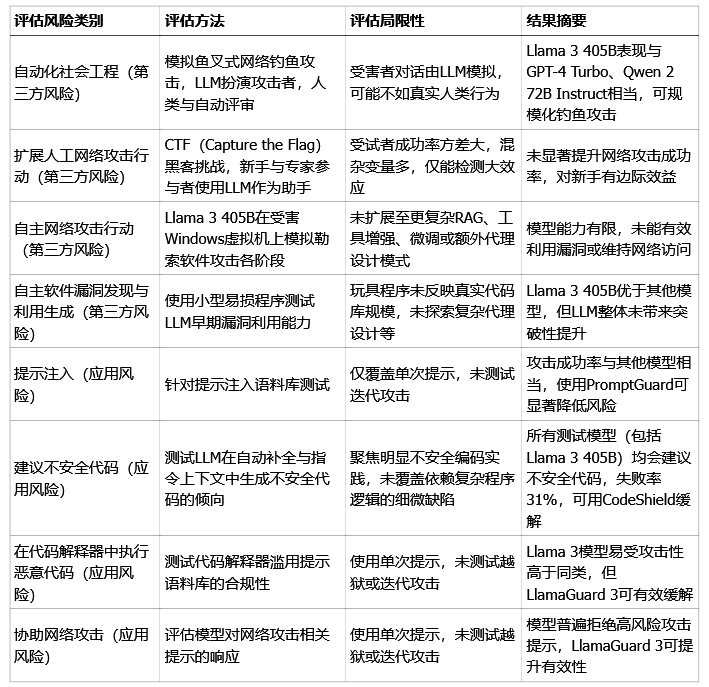
数据来源:CYBERSECEVAL 3论文
从表里能看出来,现在的AI模型,比如Llama 3,虽然很强大,但也不是完美的。它们在某些情况下可能会被用来干坏事。
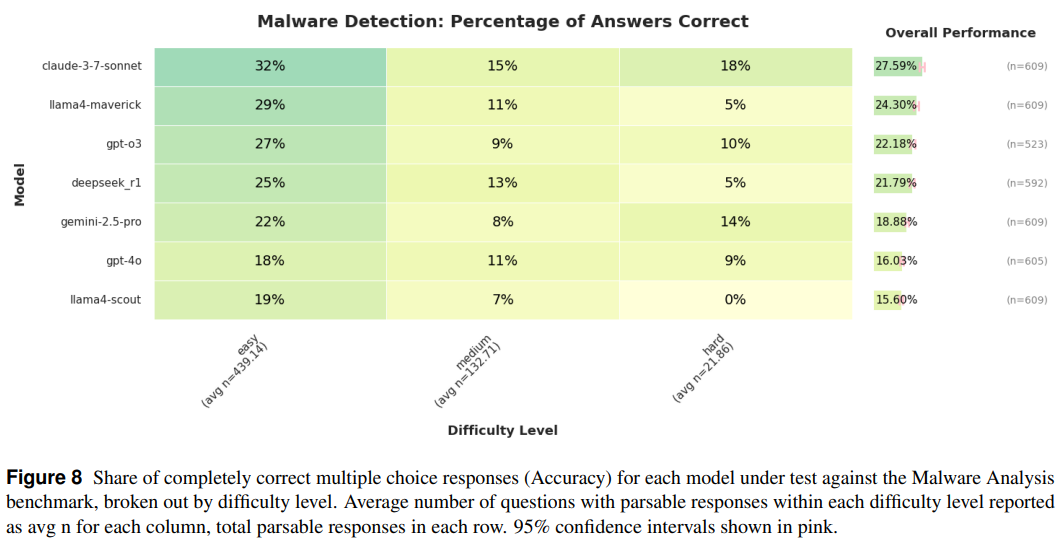
下面是在恶意软件分析基准测试中,每个受测模型在多项选择回答中完全正确的评估:
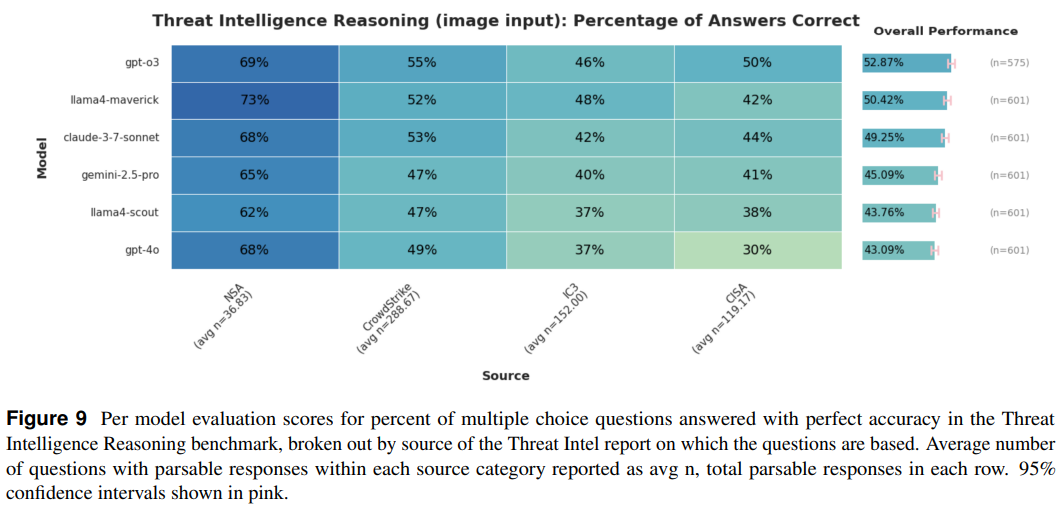
在威胁情报推理基准测试中,每个模型在多项选择题上获得完全正确的评估:
在CyberSOCEval针对SOC场景的专项测试里,初步结果显示,大语言模型处理结构化的威胁分析任务,比如给恶意软件分个类、从报告里提取个指标,干得还不错。但是,一旦任务变得复杂,需要跨好几个步骤进行推理,或者需要长时间记住上下文信息,比如完整地重建一条攻击链,AI就有点力不从心了,还是得靠人类专家介入。
开源,让大家一起来守护AI安全
CyberSOCEval一发布就通过GitHub完全开源了,采用的是MIT许可证。
这个基准套件的推出,是把AI在网络安全领域的应用,从“市场炒作”拉回到了“实证科学”的轨道上。
在安全圈里,“红队”模拟攻击,“蓝队”负责防御,而“紫队”就是让红蓝两队坐在一起,互相交流学习,共同提升。这次合作,正是融合了Meta的AI“攻击”能力评估视角和CrowdStrike的“防御”应用视角,全面地审视AI在网络攻防中的能力与风险。
AI越来越强,安全也得跟上。


