
作者 | 崔皓
审校 | 重楼
整体思路
本文聚焦 LLMOps(大模型运维)全流程实践,从一大模型微调的例子切入,串联起从数据准备到模型部署落地的完整链路。通过模拟业务人员上传微调数据,借助 Jenkins 工作流驱动一系列自动化操作,展现大模型从研发优化到实际应用的全生命周期管理逻辑,帮大家理解大模型开发微调中如何实现 LLMOps 的全流程。
例子通过模型微调的方式,让 Qwen2 大模型 “认知” 自身为 “微调小助手,由小明创造”。依托 LLaMA - Factory 完成模型微调,让 Qwen2 学习特定身份设定;通过自定义脚本合并模型、利用 llama.cpp 转换格式,适配部署需求;再经 MLflow 实现模型注册、评估,构建 Docker 镜像并部署为容器,最终通过测试验证模型功能与性能。全流程以 Jenkins 为自动化引擎,串联参数验证、微调、合并、转换、注册、评估、镜像生成、容器部署、测试九大环节,形成完整闭环。
为了方便大家了解整个案例的执行流程, 我们通过如下一张大图让大家了解。
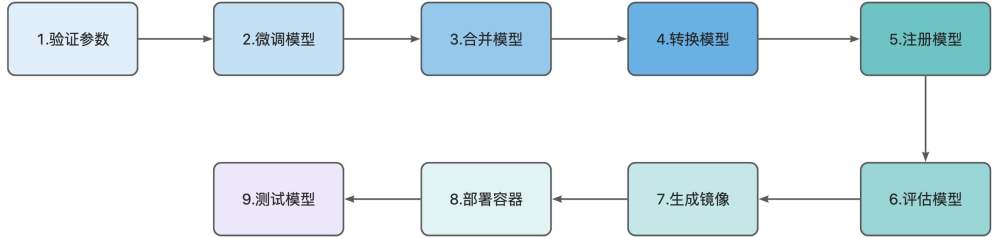
这里对图中涉及到的步骤进行详细描述:
- 验证参数:对模型全流程涉及的参数(如微调配置、转换参数等)进行合法性校验,确保流程稳定运行。
- 微调模型:基于 LLaMA-Factory 执行大模型微调任务,针对特定场景/数据优化模型效果。
- 合并模型:通过自定义 Python 脚本,将微调后的模型与基础模型合并,整合优化成果。
- 转换模型:利用 llama.cpp 工具,把模型转换为目标格式(如 GGUF 格式 ),适配后续部署需求。
- 注册模型:将转换后的模型登记到模型仓库(如 MLflow 模型注册表 ),实现版本化管理。
- 评估模型:借助 MLflow 工具链,对模型开展性能评估(如指标计算、结果分析),并记录评估数据。
- 生成镜像:依托 MLflow 构建能力,打包包含模型推理服务的 Docker 镜像,固化运行环境。
- 部署容器:将 Docker 镜像部署为容器实例,使模型推理服务可对外提供稳定访问。
- 测试模型:对容器化部署的模型进行功能、性能测试,验证服务可用性与推理效果。
通过上述流程,将呈现大模型如何从 “通用能力” 向 “场景化定制” 演进。可以通过该实践案例,理解 LLMOps 如何用自动化串联模型迭代全环节,每个技术步骤如何服务业务目标,以及大模型从数据输入到可用服务的完整实现逻辑,为实际业务中模型迭代与落地提供可参考的流程范式。
应用安装
在开始 LLMOps 实践前,需先搭建稳固的工具链底座。本章聚焦核心组件的安装与准备,这些组件将支撑从模型微调、转换到部署测试的全流程。为了让大多数人能够通过本文档体验 LLMOps 的全过程,我们选择了 Windows 平台,使用 Win 10/11 作为操作系统,显卡方面使用了一张 4060 的 8G 现存的显卡。显卡的选取根据具体情况,由于我们会涉及到大模型微调的部分,带现存的显卡体验会好一些。
安装组件基本介绍
在安装组件之前我们通过如下一张大图让大家了解, 这些组件在哪些实践环节中起效。
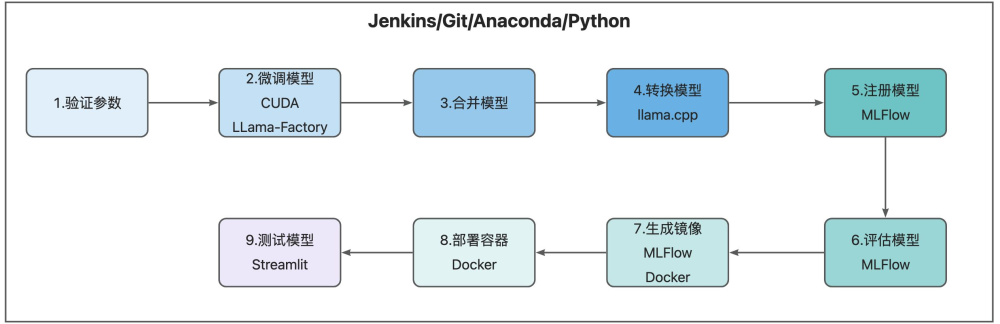
这里我们将安装的工具和组件进行分类,给大家介绍。
基础环境
我们的技术栈围绕 Jenkins、Git、Anaconda、Python 构建自动化与运行环境,它们是流程运转的 “发动机”。Jenkins 作为自动化工作流核心,负责串联起模型微调、合并、转换等全环节;Git 保障代码与数据版本可控;Anaconda 与 Python 则为模型开发提供虚拟环境与编程语言支持,让不同工具间的依赖管理更清晰。
关键组件
(一)微调与加速:CUDA + LLaMA - Factory
模型微调是让 Qwen2 “学习身份” 的关键一步。借助 CUDA 发挥 GPU 算力优势,可大幅缩短微调时间。而 LLaMA - Factory 作为专业微调框架,提供便捷的参数配置与训练流程,让我们能高效用数据集训练模型,赋予其 “微调小助手,由小明创造” 的认知。需确保 CUDA 版本与硬件、深度学习框架适配,再通过 Python 环境安装 LLaMA - Factory 及依赖,为模型微调铺好路。
(二)格式转换:llama.cpp
完成微调与模型合并后,为适配多样化部署场景,需用 llama.cpp 转换模型格式(如转为 GGUF 格式 )。它能让模型在不同硬件环境(尤其是轻量化部署场景)更易运行。安装时,通过 Git 拉取源码并编译,依据硬件配置调整编译参数,确保转换后的模型能稳定支持后续流程。
(三)模型全生命周期管理:MLFlow
MLFlow 贯穿模型注册、评估、镜像生成环节,是模型全生命周期管理的 “中枢”。注册模型时,它记录版本与元数据,方便迭代追溯;评估环节,借助其工具链计算性能指标;生成镜像阶段,又能打包模型与推理服务。通过 Python 包管理工具安装 MLFlow,配置好跟踪服务器,就能让模型从研发到部署的关键节点可管、可查。
部署测试
(一)容器化部署:Docker
模型要对外提供服务,Docker 是容器化部署的首选。它能封装模型推理环境,确保不同环境下运行一致。安装 Docker 引擎后,配置镜像构建与容器运行参数,后续结合 MLFlow 生成的模型,快速打包成可部署的镜像。
(二)功能测试:Streamlit
最终验证模型功能(如身份认知回复是否符合预期 ),Streamlit 是轻量且便捷的工具。它能快速搭建 Web 测试界面,输入指令验证模型输出。通过 Python 安装 Streamlit,编写简单脚本加载部署后的模型,就能直观测试模型在实际交互中的表现。
这些组件并非孤立存在,而是相互协作:Jenkins 驱动流程,调用 LLaMA - Factory 微调、llama.cpp 转换;MLFlow 记录模型演进;Docker 与 Streamlit 完成最后部署与验证。
安装 CUDA
CUDA(Compute Unified Device Architecture,统一计算设备架构)是 NVIDIA 推出的专为其 GPU(图形处理器)设计的并行计算平台与编程模型。在实战中,CUDA 提供硬件加速支撑:例如使用 LLaMA-Factory 进行模型微调时,会通过 CUDA 接口调用 GPU 核心,在 llama.cpp 进行模型格式转换(如 FP16 转 FP8)或推理时,CUDA 也能加速数值计算过程,降低模型部署后的响应延迟。同时,CUDA 配套提供了 CUDA Toolkit(包含编译器、库、驱动等),确保深度学习框架与 NVIDIA GPU 之间的高效适配。
需要说明的是, 本次实践使用的是 NVIDIA 4060 的显卡,所以需要在安装显卡驱动的基础上再安装 CUDA 套件,从而支持上层的向量运算。
在安装之前,需要通过Nvidia Control Panel查看当前显卡驱动支持的最高 CUDA 版本。如下图所示打开Nvidia Control Panel。
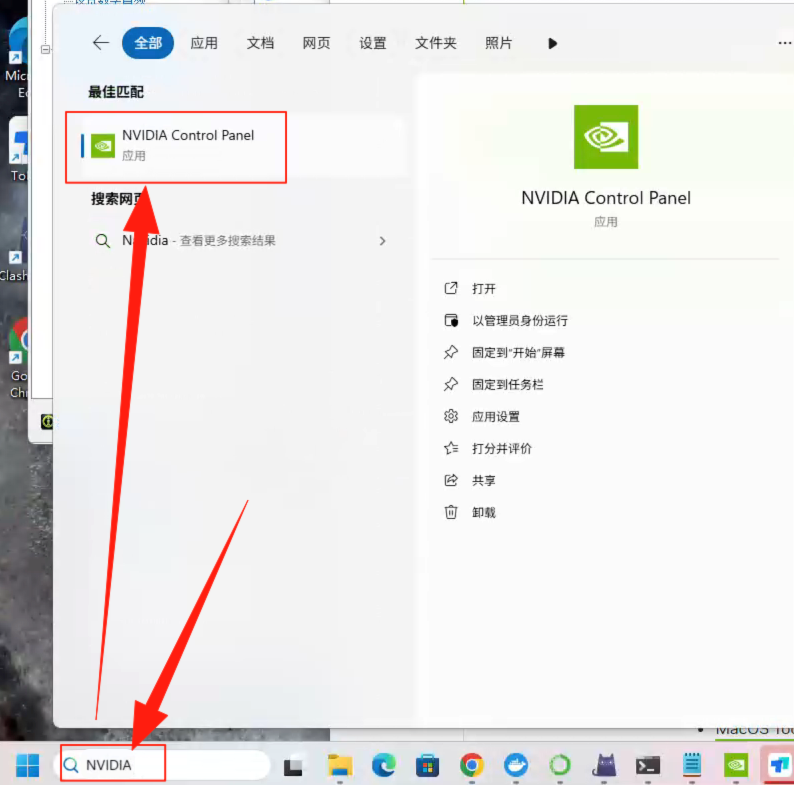
点击“系统信息”,在弹出的对话框中查看支持的最高CUDA版本,这里显示的 CUDA 是 12.6 版本,不同的显卡这里支持的 CUDA 版本不同。
接着,如下图所示,下载支持的CUDA版本安装包 CUDA Toolkit Archive。
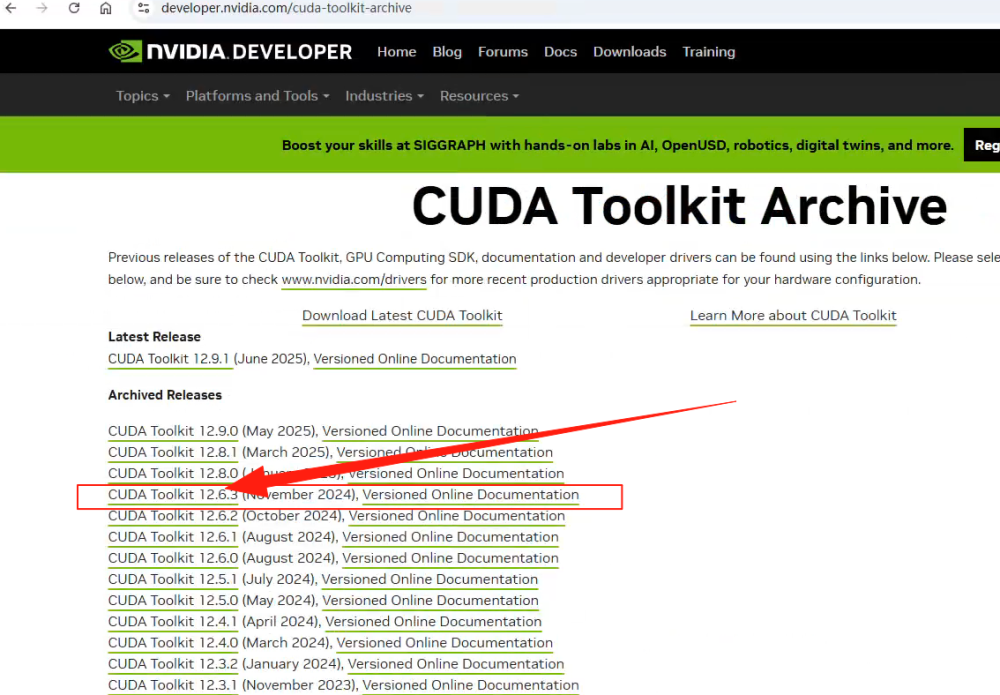
下载完 CUDA toolkit 之后还没有完,需要安装与之相关的其他依赖以及套件,访问https://pytorch.org/get-started/locally/ 根据你所加载的操作系统,安装指令包语言以及 CUDA 的版本生成命令。

直接把生成的命令,放到 powershell 中执行,记住在执行之前激活 mlflow 的环境,后面我们都会在这个虚拟环境中工作。
复制
执行命令之后,你会看到如下图片的输出内容,表示正在下载依赖。
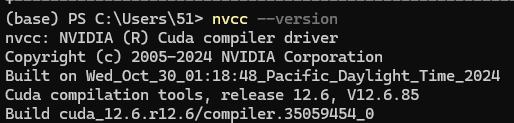
完成上述操作之后需要重启操作系统,然后打开 powershell 执行如下命令,查看 CUDA 版本。
复制
如下图所示,输出CUDA 编译器版本。
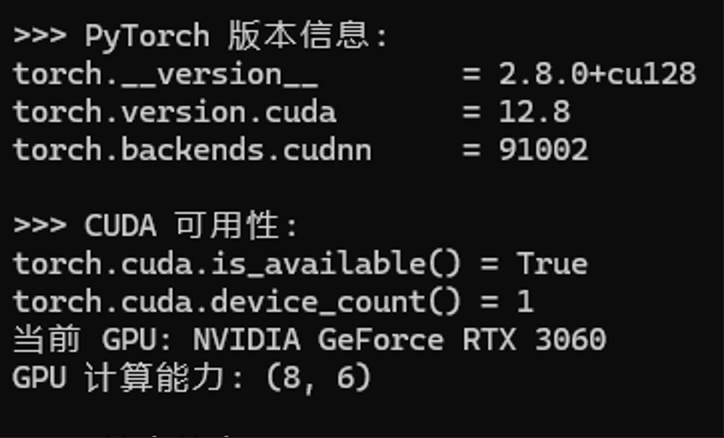
此时如果还不放心,可以通过如下 Python 脚本查看CUDA是否可用。我们可以在 mlflow 目录下面创建test_cuda.py 文件。需要说明的是,这个所谓的mlflow 目录会存放一些相关的重要文件,我这里选择 D:\mlflow 目录,后面一些重要的测试文件和脚本文件我也会放到这里。并且,类似 Llama-Factory,llama.cpp 等开源工具也会安装到这个目录方便管理和讲解。
复制
执行如下命令:
复制
得到下图输出,说明CUDA已启用,并且列举详细参数。
安装 Jenkins
Jenkins 是本次大模型全流程实战的核心枢纽,它凭借 pipeline 机制,将微调、合并、转换、评估、测试、部署等分散的工具与框架紧密串联。
接下来,如下图所示通过网站 https://www.jenkins.io/download/ 进行选择并安装。
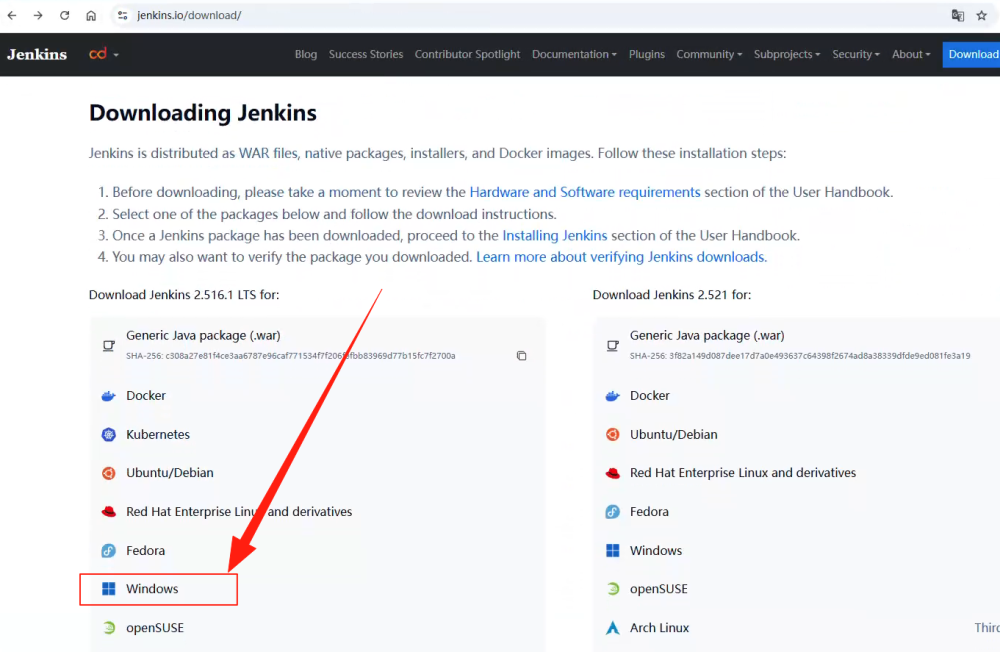
需要注意的是在安装 Jenkins 之前需要下载并安装 JDK 23,在 Jenkins 的安装过程中会选择 JDK 所安装的文件夹。另外, Jenkins 在安装的时候会提供一个 WebUI 的访问端口,默认是 8080。为了避免冲突,我在安装的时候将其设置为 8081,大家可以根据具体情况酌情设置,这个 WebUI 的访问地址在后面实践中会用到,大部分的配置操作会在上面进行。
Jenkins 安装完毕之后,如下图所示, 通过 Windows 中的“服务”查看其正常运行即可。
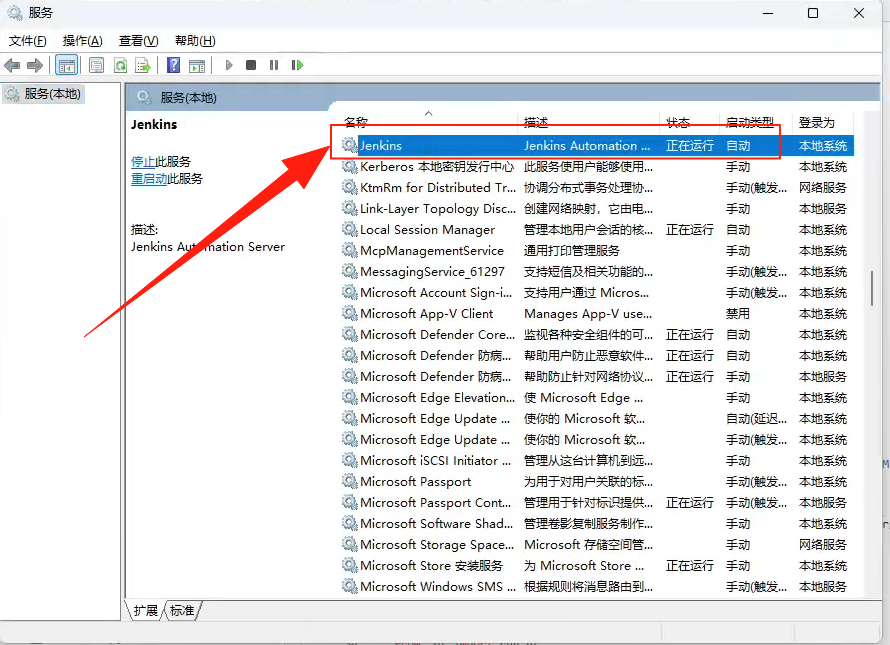
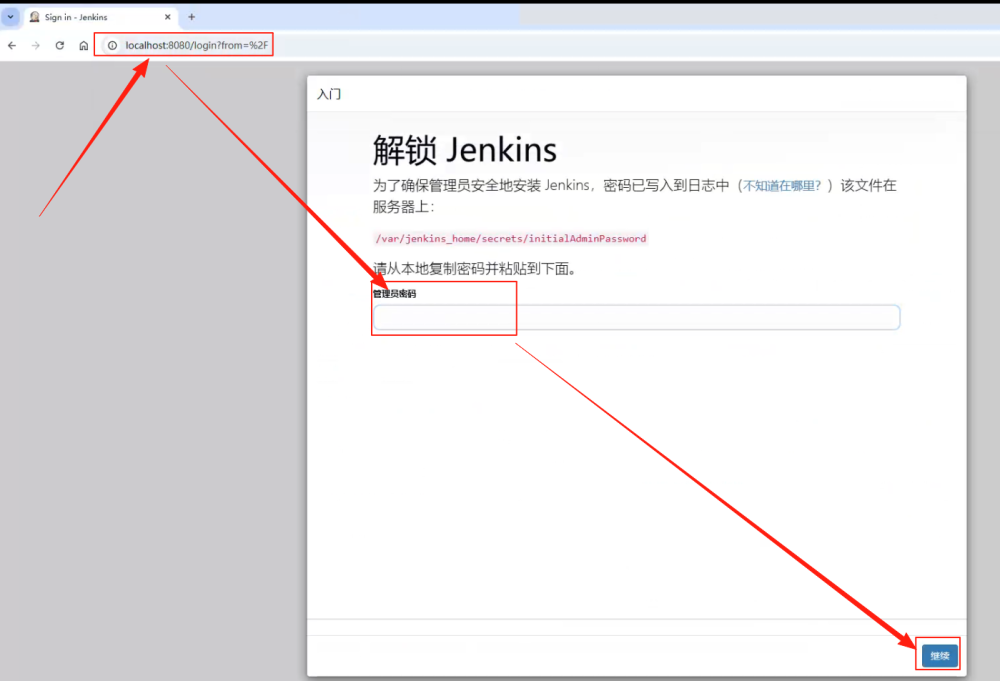
在确保服务启动的同时,还需要在浏览器输入http://localhost:8081,这个地址和端口是我们在安装时设定的。由于第一次访问 Jenkins 的 WebUI,所以需要进行用户名和密码的初始化设置。如下图所示,在初次访问的时候,会提示用户到指定文件中获取管理员的密码。由于每个人的安装目录不同,假设我们将 Jenkins 安装到了D:/jenkins_home 下,那么文件就是D:/jenkins_home/secrets/initialAdminPasswrod 。
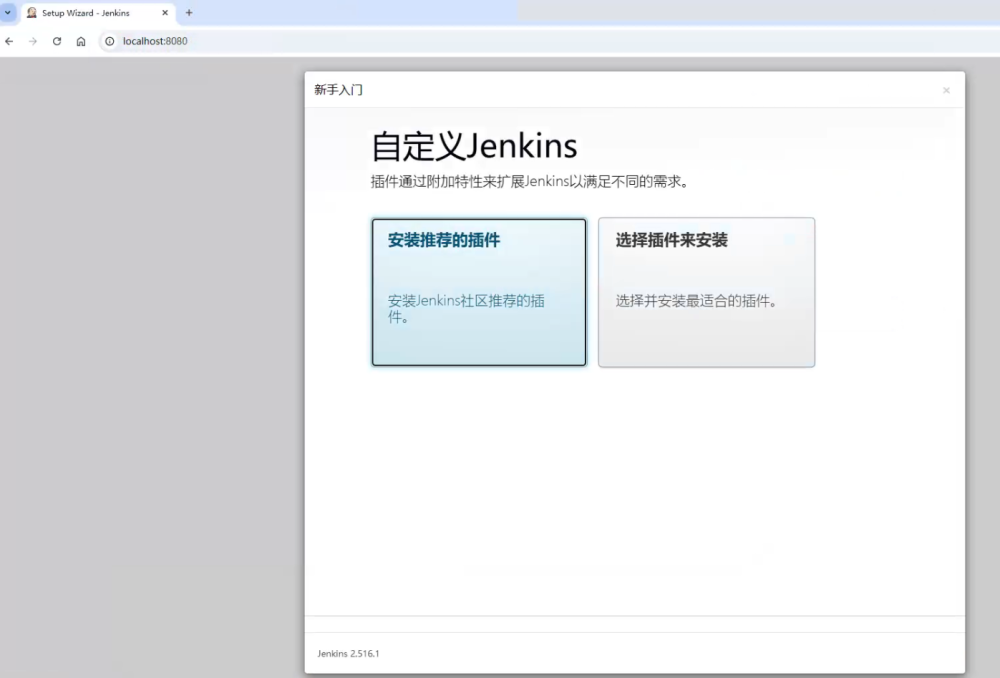
接着会完成管理员和密码的设置,完成设置之后如下图所示我们会安装自定义插件。选择“安装推荐的插件”进行安装。
如下图所示,会显示插件安装的过程,这里只需要等待安装完成即可。
安装 Anaconda
在介绍完 Jenkins 的安装之后,我们来到 Anaconda 的安装。Anaconda 是一个针对数据科学、机器学习及深度学习场景设计的开源包管理与环境管理工具,它整合了 Conda 包管理器、Python 解释器以及大量常用的数据科学库(如 NumPy、Pandas、Scikit-learn 等),能为开发者提供统一、稳定的开发环境。
在本次大模型全流程实战中,Anaconda 的核心作用是创建并管理独立的 Python 虚拟环境(如专门用于 MLflow 评估的 mlflow 环境、用于 LLaMA-Factory 微调的环境等),避免不同工具间的依赖版本冲突。同时,借助 Anaconda 的命令行工具,还能快速完成环境的创建、激活、包安装与更新,为整个 LLMOps 流程的依赖管理提供稳定支撑。
注意:如果不需要做环境隔离,或者本机已经有类似的管理工具,可以跳过 Anaconda 的安装。
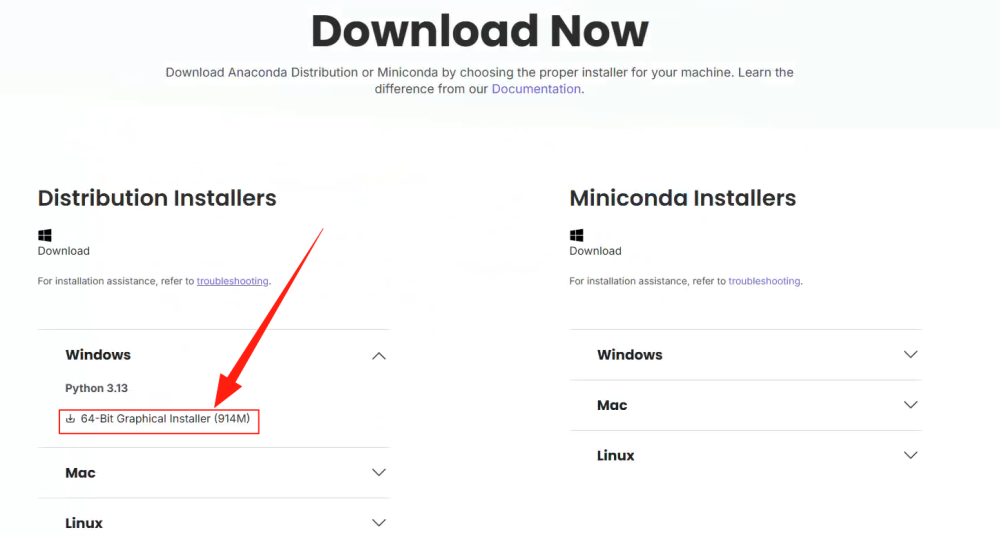
如下图所示,通过官网下载最新版本Download Success | Anaconda。
双击安装文件,然后如下图所示,一顿操作不断“下一步”对其进行安装,只需要注意安装目录即可。
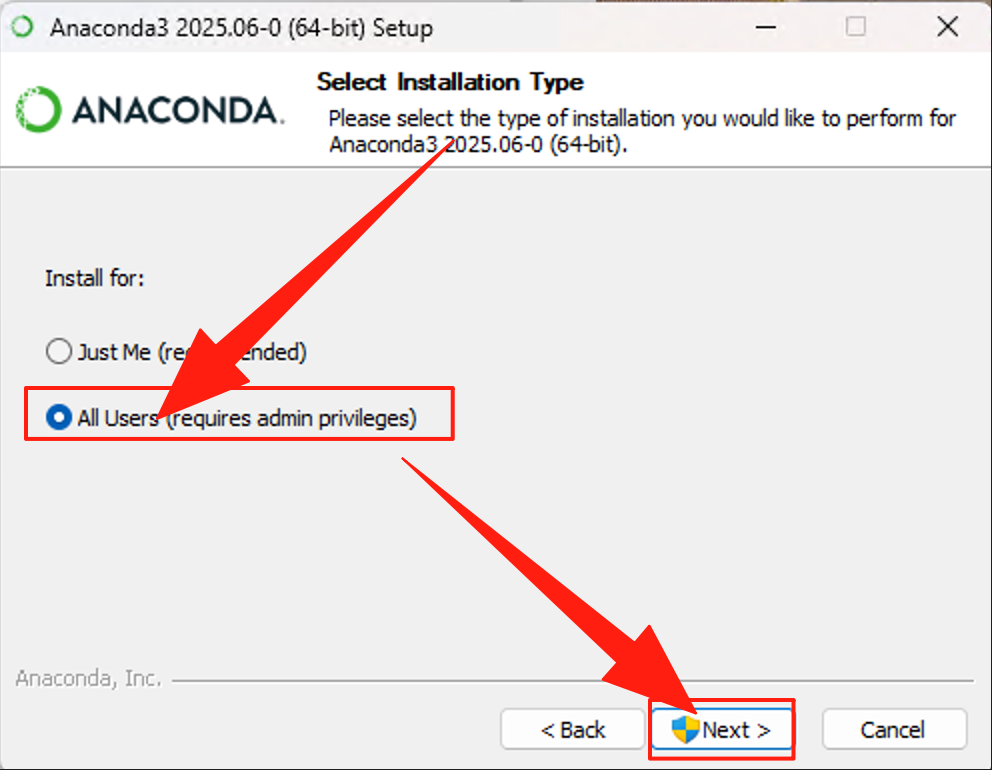
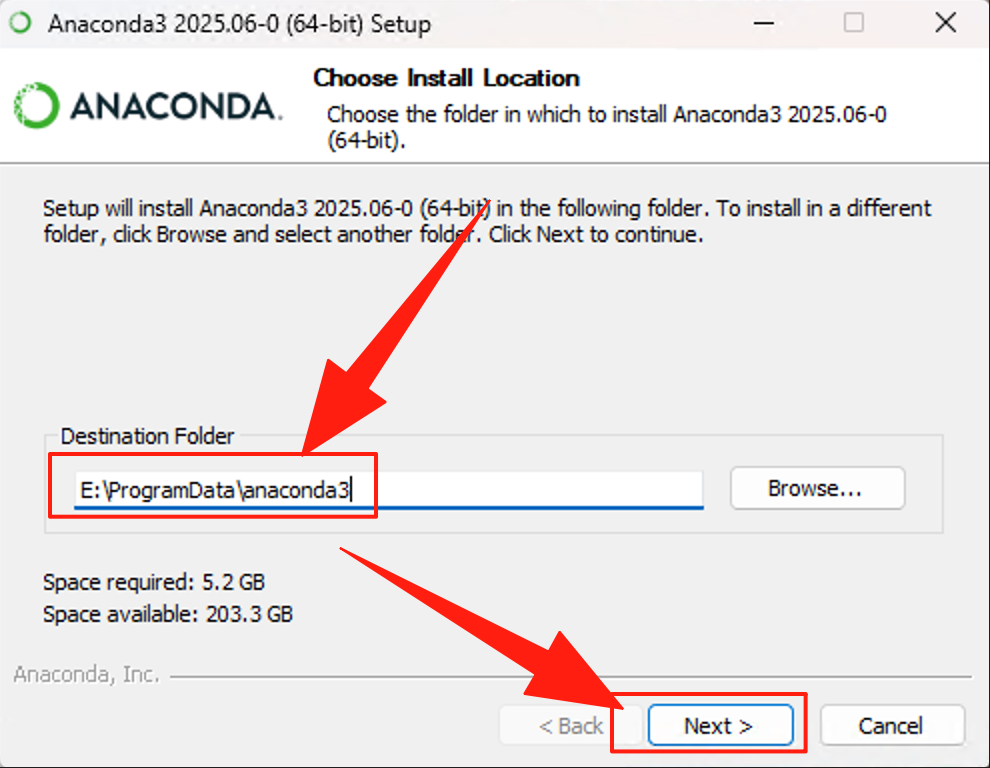
修改安装目录,默认C盘,建议修改到空间比较大的其他盘,这里是改到D盘下。
在安装完毕之后,需要激活 conda 的虚拟环境,如下图所示,通过“终端管理员”运行PowerShell。
输入如下命令,进入conda安装目录,假设我们安装在 C 盘。
复制
在使用conda命令之前需要对其进行初始化设置,执行如下命令。
复制一个小插曲,我在 windows 中安装涉及权限问题,需要通过如下命令修改执行策略。
复制完成上述操作之后,再重新打开PowerShell,如下图所示在命令行的最左边显示(base),说明环境配置成功。
安装好 Conda 之后,我们会使用 Conda 命令创建虚拟环境,大多数的组件和工具的安装都包含在虚拟环境中,大家跟上别掉队。
安装 MLflow
MLflow 是一个开源的机器学习生命周期管理工具,主要用于简化机器学习模型从开发、训练、评估到部署的全流程管理。在本次大模型实战中,MLflow 承担着多重核心角色:在模型管理层面,它提供模型注册表功能,可对微调、合并后的模型进行版本化记录与管理,方便追溯不同版本模型的迭代历史;在模型评估层面,能集成毒性、文本可读性等指标计算逻辑,自动生成评估报告并记录指标结果,支持后续对比分析;在模型部署层面,可基于已管理的模型自动生成包含推理服务的 Docker 镜像配置,为后续容器化部署提供基础。说白了,MLFlow 在帮助管理模型的生命周期,并对其进行管理和记录。
这里我们会通过 conda 创建虚拟环境进行安装,之后组件的安装都会基于虚拟环境(mlflow),这里统一做一次说明。
打开PowerShell,执行如下命令创建名为 “mlflow”的虚拟环境,python版本选择3.10.18。
复制创建完毕之后激活环境,执行如下代码:
复制在激活的环境中,执行如下命令安装mlflow 组件以及相关依赖。
复制如果不出意外 mlflow 已经安装好了,可以通过如下命令启动 mlflow。
复制命令内容有点长,尝试给大家解释一下。
该命令用于启动 MLflow 跟踪服务器,所以以 mlflow server 开头,后面跟了一系列参数:
- --backend-store-uri file:///d:/mlflow/mlruns 设定后端存储路径,用于保存实验元数据(如运行记录、参数、指标等)到本地 d:/mlflow/mlruns 目录;
- --artifacts-destination 和 --default-artifact-root 均指定为 file:///d:/mlflow/mlartifacts,定义了模型 artifacts(如权重文件、配置文件等)的存储路径;
- --host 127.0.0.1 和 --port 8082 则限制服务器仅在本地(127.0.0.1)的 8082 端口提供服务,确保只有本机可访问该 MLflow 服务器。
执行上述命令之后, mlflow 也就启动了,也可以通过 http://localhost:8082 访问 mflow 的 WebUI。
安装 Git
由于需要通过 Git 命令拉取诸如 Llama-Factory 开源项目,可以通过地址 Git - Downloading Package完成 Git 的下载,双击Git-2.50.1-64-bit.exe,按默认选项完成安装。这里不展开描述。
安装 LLaMA-Factory
Git 的安装主要是为了后面两个开源工具做准备的,下面就轮到 Llama factory 的安装了。 LLaMA-Factory 是一个开源的大模型微调框架,专注于简化 LLaMA 系列及衍生大模型的微调流程,提供了一站式的模型微调、评估与部署解决方案。它集成了多种主流微调方法(如全参数微调、LoRA 等参数高效微调技术),支持通过配置文件或命令行参数快速设定微调策略(如学习率、训练步数、批处理大小等),降低了大模型微调的技术门槛。
在本次大模型实战中,LLaMA-Factory 主要用于加载基础模型(如 Qwen2)和定制化数据集(包含 “身份认知” 相关指令),执行微调任务以让模型学习 “微调小助手,由小明创造” 的角色设定,同时支持在微调过程中利用 CUDA 进行 GPU 加速,提升训练效率,最终输出微调后的模型权重,为后续的模型合并环节提供基础。
通过下面命令激活环境,并且利用 git 拉取 Llama factory 并进行安装。注意,这里我们将其安装到了d:\mlflow 目录下面,方便后续管理。
复制如果安装过程中遇到下载不了的情况,需要通过代理完成下载,或者使用镜像拉取,这里不展开说明。这里我们选择 Clash,此时在PowerShell中输入如下命令, 保证 git 命令能够顺利执行。如果没有对应网络问题,可以跳过这个部分。
复制安装完毕之后,执行以下命令测试 LLaMA-Factory WebUI 是否正常运行。此时定位到 d:/mlflow/LLaMA-Factory 目录下面执行。
复制你会看到如下输出信息,说明LLaMA-Factory 的服务已经启动了。
复制此时,通过 localhost:7860 就可以访问 LLaMA-Factory 了,不过这里暂时不会用到, 后面会通过命令行的方式调用它。
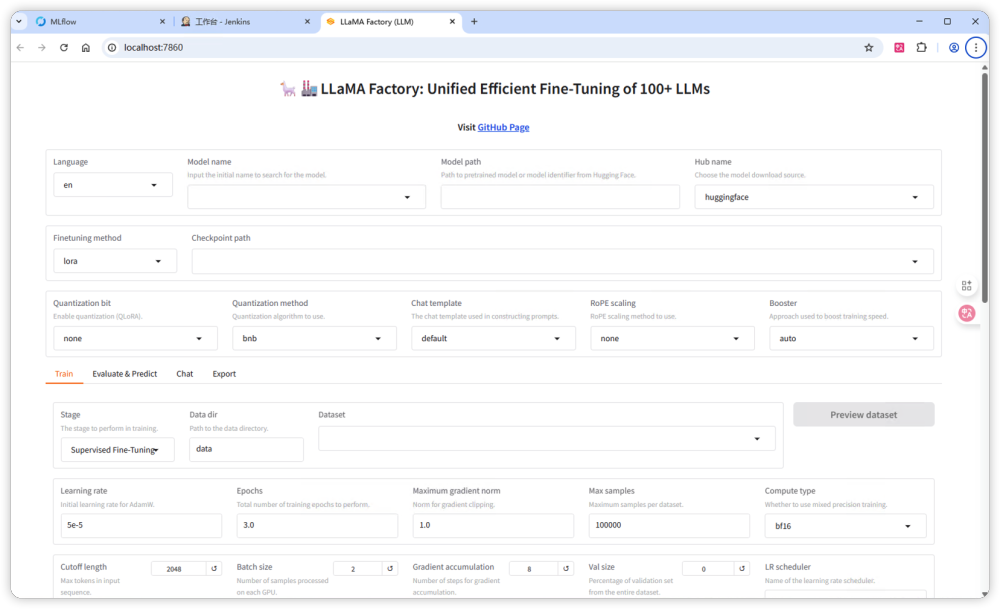
安装 llama.cpp
由于我们实践的是 LLMOps 的全流程,中间涉及到的工具和组件较多,所以整个过程比较漫长,终于来到了最后一步,就是安装 llama.cpp。
llama.cpp 是一个轻量级的开源框架,主要用于大模型的高效推理与格式转换,尤其适用于在 CPU 或资源受限的硬件环境中运行模型。它支持多种大语言模型,并提供了模型格式转换工具,能够将不同格式的模型文件转换为其专用的 GGUF 格式,同时优化模型的加载与推理性能。
在本次实战中,我们会用到 llama.cpp 的模型转换功能。需要转换的源文件是 safetensors 格式,它是一种安全的张量存储格式,专为机器学习模型设计,具有防篡改特性,能有效避免恶意代码注入,目前被广泛用于存储模型权重,从 LLaMA-Factory 微调后输出的模型文件即为此格式。通过 llama.cpp 提供的转换工具(如 convert_hf_to_gguf.py),我们将 safetensors 格式的模型文件转换为 GGUF 格式。GGUF 格式是一种更通用的模型存储格式,它对模型权重和元数据进行了统一封装,适配性更强,可在不同硬件环境(包括 CPU、GPU 及边缘设备)中更高效地加载和运行,且支持多种推理框架。
需要说明的是,模型格式转换并非必需步骤,直接使用 safetensors 格式的模型进行部署也是可行的;但通过演示这一转换过程,我们可以展示大模型在落地时的更多可能性,包括如何适配多样化的硬件环境,为实际应用中的格式选择提供参考。
依旧通过如下指令安装llama.cpp。
复制看到如下字样说明安装成功了。
复制配置 Jenkins
在完成全流程所需组件与工具的安装后,接下来需将这些分散的技术模块整合为自动化执行链路,核心在于将工具调用逻辑嵌入 Jenkins 并完成对应配置,因此我们的关注点将转移至 Jenkins 的具体设置。考虑到本次 LLMOps 实践涵盖参数验证、模型微调、合并、转换、注册、评估、镜像生成、容器部署、测试共 9 个步骤,需依托 Jenkins 的 Pipeline 机制实现全流程串联:Jenkins Pipeline 是一种基于代码的工作流定义方式,支持将多环节任务按顺序编排为可复用、可版本控制的脚本,能自动触发各步骤执行并处理环节间的依赖关系,避免人工干预导致的流程中断或遗漏。同时,为适配不同场景下的 LLMOps 需求(如更换基座模型、使用不同微调数据集),还需为 Pipeline 设计客制化输入参数,例如基座模型在本地或远程存储的具体地址、业务人员上传的微调数据集文件路径、MLflow Server 的访问地址等,通过参数化配置让 Pipeline 具备更强的灵活性,满足多样化的模型迭代与部署需求。
创建Pipeline
首先创建 Jenkins 的 Pipeline 类型的任务, 如下图所示,通过 localhost:8081 访问 Jenkins 的 WebUI 界面, 点击“新建 Item”进行 Pipeline 的设置。 需要注意的是, localhost:8081 需要和之前安装Jenkins 时定义的访问地址保持一致。
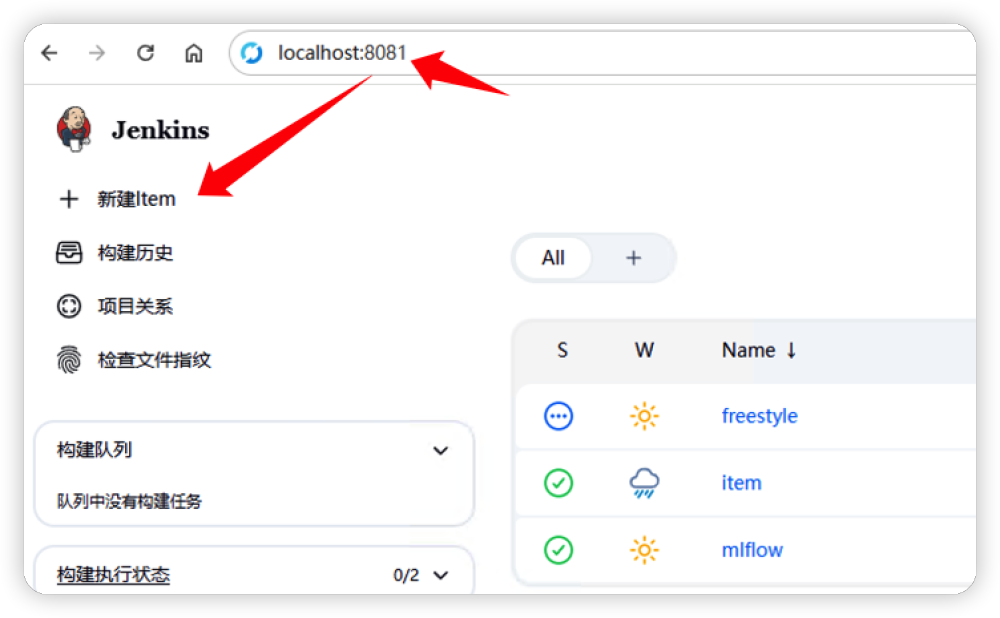
接着根据下图,在新建 Item 中输入一个任务的名称,按照个人喜好设置就可以了。记得选择 Pipeline 作为任务的类型。
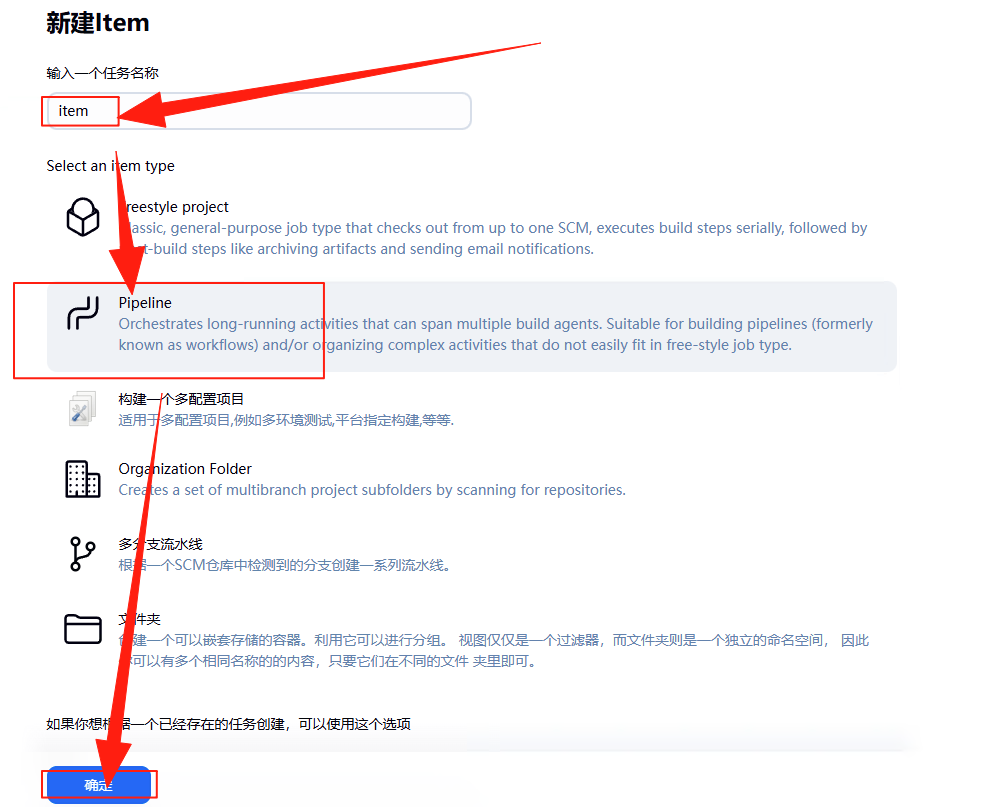
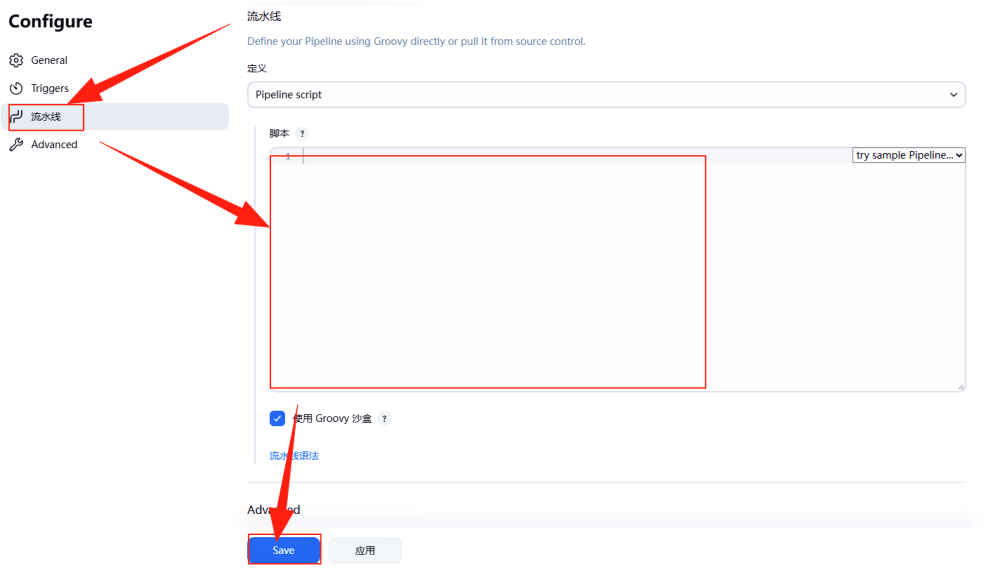
在点击“确定”之后会看到如下图所示界面。这里的“脚本”我们会在后续进行填写,这里知道就行了,继续点击“Save”。
安装插件
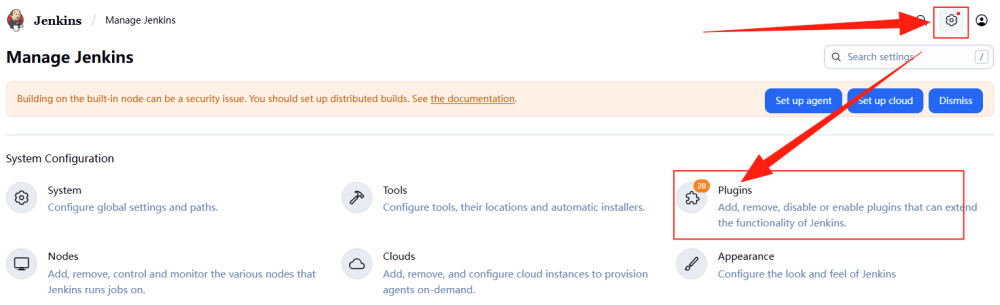
我们已经创建了 Jenkins Pipeline类型的任务,由于该任务会接受数据集文件作为大模型微调的输入,而数据集文件的格式是 JSON,所以需要让 Jenkins 能够识别并解析该文件格式。于是,我们需要安装两个插件来满足文件上传和解析的需求,如下图所示,在 Jenkins 的 WebUI 界面点击右上方的“齿轮”(设置)按钮,选择“Plugins”进行,(File Parameter)文件上传和文件解析(Pipeline Utility Steps)插件的安装。
在界面中选择“Available plugins”,然后输入“File Parameter”在下方列表中勾选插件,然后点击最右边的“安装”按钮。

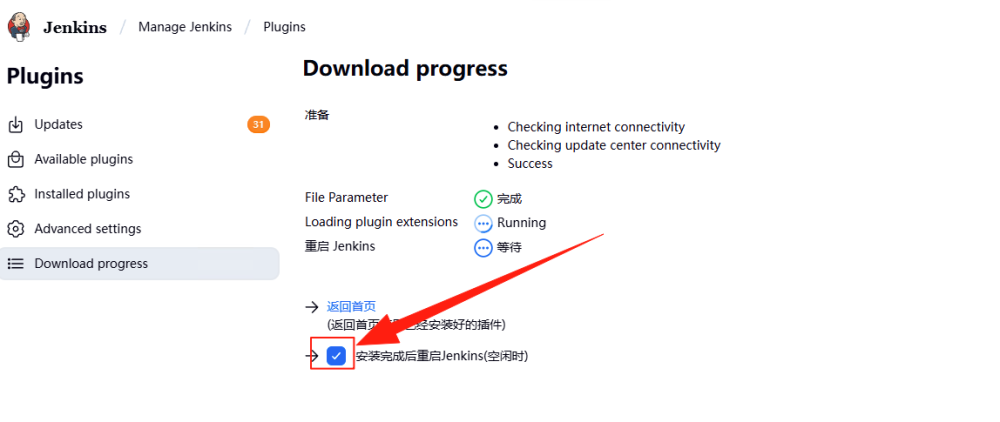
由于安装需要一点时间,如下图所示,点击“安装完成后启动 Jenkins”。
按照上面相同的步骤,把“Pipeline Utility Steps” 也安装起来,这里就不再重复安装步骤了,大家自行安装并重启 Jenkins。
设置参数
前面安装 Jenkins 插件的目的是为了支持文件上传以及解析 Json 格式的文件, 接下来就需要设置输入的参数了。在生产环境中,Jenkins 定义的 Pipeline 任务更像一个工作流,会按照既定的步骤逐一执行直到结束,该工作流获取外部信息的方式就是参数输入,接下来就来看有哪些参数需要设置。
如下图所示,在我们之前创建的“item” Pipeline 中选择“配置”。
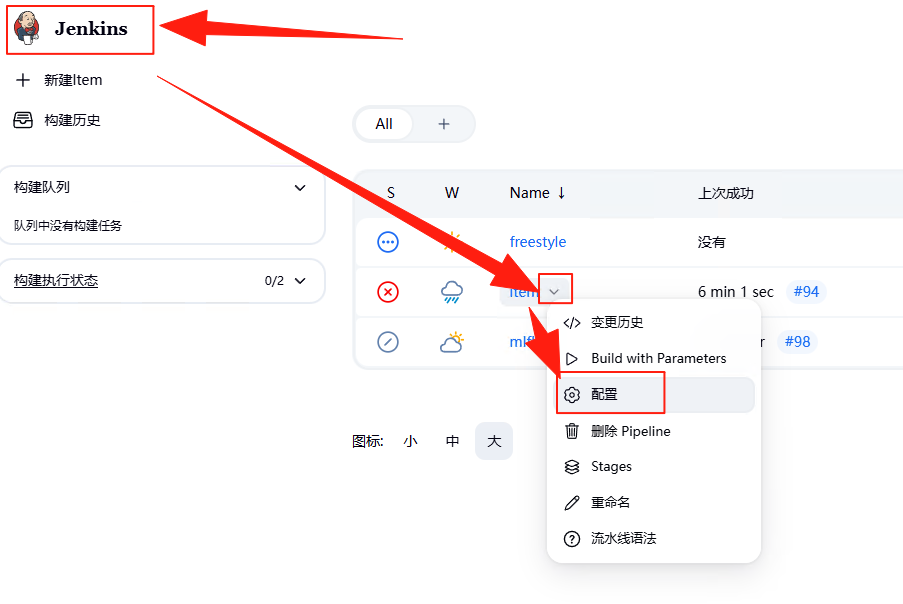
在左侧的“General”菜单中选择“This project is parameterized”,意思是针对这个项目进行参数化。
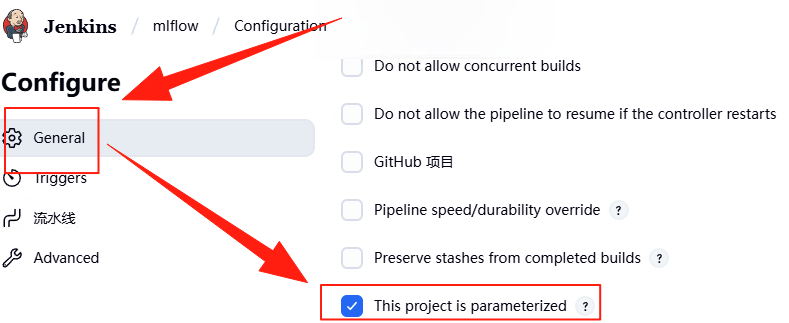
紧接着在下面的“添加参数”下拉框中选择“Stashed File Parameter”,意思是可以将上传文件作为参数输入,稍后我们会将微调文件作为参数输入。
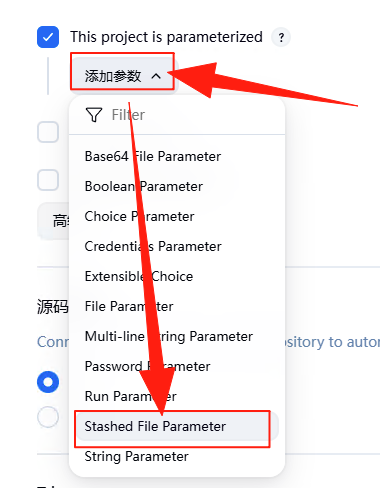
如下图所示,在展开“Stashed File Parameter”参数中可以输入“DATASET_FILE”作为 Name,也就是说上传的文件会保存到名为“DATASET_FILE”的工作空间变量中。
Jenkins 的工作空间(Workspace)是指 Jenkins 服务器在执行任务(如 Pipeline、自由风格项目等)时,为当前任务动态分配的一个本地文件目录,用于存放任务执行过程中所需的代码、数据、依赖文件及输出结果。它是任务运行的 “临时工作目录”,每个任务在执行时都会拥有独立的工作空间,避免不同任务间的文件冲突。
接下来添加几个字符串类型的参数,如下图所示,选择“String Parameter”。
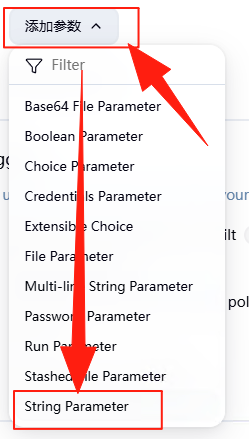
输入名称为“MLFLOW_TRACKING_URI”的参数,给出一个默认值为“http://127.0.0.1:8082” ,也就是 MLflow 服务器的访问地址。如果还有记忆的话,我们在“安装 MLflow”的环节会启动这个 MLFlow,用的就是本地的 8082 端口。由于每个人安装的MLFlow 服务的地址各不相同,所以这里需要进行配置。
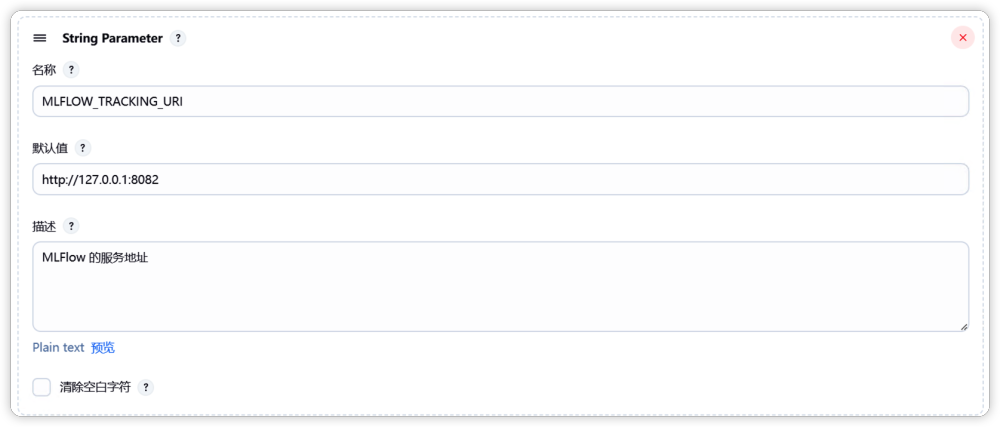
接着就是模型文件所载目录,通过 “MODEL_NAME_OR_PATH”进行配置。在测试环节,我们会尝试下载大模型 Qwen2-0.5b ,并存放到下图所示的目录中。
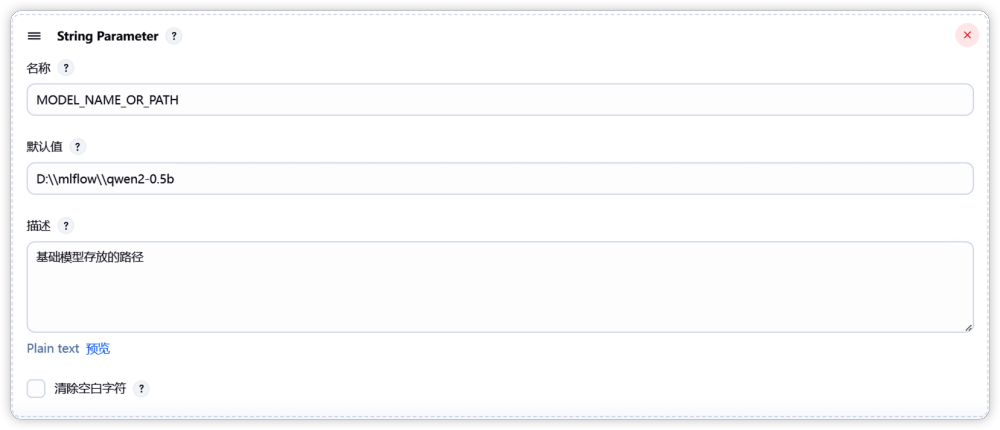
在配置的最后,设置“ MODEL_NAME”用来标注在 MLflow 中所注册的模型名称。在 MLflow 注册之后就可以查看评估结果,以及可以对模型进行后续操作。
好了,至此我们就完成了 Pipeline 任务的参数设置,当然我们还可以加入更多参数,这里全当抛砖引玉,在实际项目中可以自由发挥。
编写脚本
Jenkins Pipeline 脚本以代码化方式定义整个工作流程,核心功能在于将分散的步骤串联为自动化链路,同时支持灵活调用外部脚本(如 Python 文件),实现复杂流程的有序执行。
从步骤串联来看,Pipeline 脚本通过结构化语法(如 stage 块)将不同环节按逻辑组织,例如在本次 LLMOps 实践中,可通过 stage('模型微调') 定义微调环节,各环节按脚本顺序依次执行。
同时,Pipeline 脚本具备强大的外部调用能力,可直接在脚本中通过命令行语法调用其他 Python 文件。例如,在 “合并模型” 环节,脚本中可写入类似 python merge_lora_model.py 命令完成。这种调用方式让 Pipeline 无需重复编写复杂逻辑,只需专注于流程调度,而具体功能实现可交由专业脚本处理,既简化了 Pipeline 脚本的复杂度,又提高了代码的复用性与可维护性。
简言之,Pipeline 脚本既是流程的 “串联者”,负责按序调度各环节;也是 “集成者”,通过调用外部 Python 脚本拓展功能边界,最终实现从参数验证到模型部署的全流程自动化。
具体而言在我们的 LLMOps 的实践中,定义了一套完整的大模型全流程自动化工作流,涵盖从参数验证到容器化部署及接口测试的 9 个核心环节,实现了大模型微调、合并、转换、评估、部署的端到端自动化。
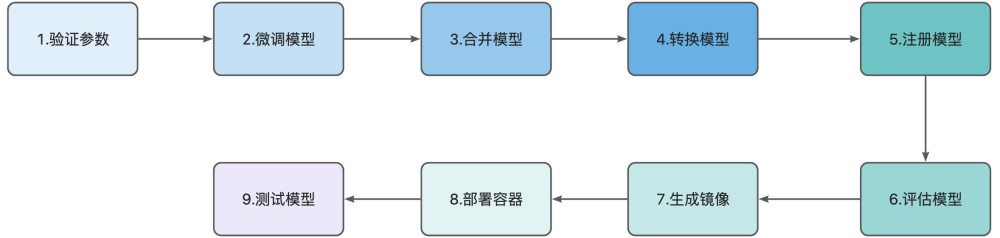
整体脚本分为两大部分:
- environment :统一配置了全流程所需的环境变量(如编码格式、路径信息、Conda 环境等),确保各环节参数一致;
- stages :定义了 9 个阶段。首先通过 “验证参数” 阶段校验输入合法性(如 MLflow 地址、数据集格式等),确保流程输入合规;随后依次执行 “LLaMAFactory 微调”(调用 LLaMA-Factory 框架进行模型微调)、“合并 Lora 和预训练模型”(通过自定义 Python 脚本整合模型)、“转换模型格式为 gguf”(利用 llama.cpp 转换模型格式);接着完成 “注册合并后模型到 MLflow”(将模型纳入版本管理)、“模型评估”(调用评估脚本记录指标);最后通过 “生成 docker 镜像”“部署到 Docker 容器”“测试容器接口” 完成模型的容器化部署与功能验证。
先放整体脚本,然后在分environment 和 stages讲解。
复制接下来我们来看看详细内容:
environment脚本
我们对一些主要参数进行讲解如下:
MLflow 相关配置变量MLFLOW_ARTIFACT_URI,该路径需与 MLflow Server 启动命令中--artifacts-destination参数指定的路径完全一致(如之前启动命令中--artifacts-destination file:///d:/mlflow/mlartifacts,则此处需同步修改为对应路径),用于定义 MLflow 存储模型 Artifacts(如模型权重、评估报告)的默认位置,同时需提前确保该目录已手动创建,避免后续模型注册、评估时因路径不存在导致失败。
工具与数据路径类变量是配置的核心,涵盖 LLaMA-Factory、数据集、模型存储等关键位置。其中LLAMA_FACTORY_PATH = 'd:\\mlflow\\LLaMA-Factory'直接指向 LLaMA-Factory 框架的安装目录,后续微调环节需切换至该目录执行训练命令,因此路径需与实际安装位置完全匹配。
TRAIN_OUTPUT_PATH = 'saves\\Qwen2-0.5B\\lora'定义了微调后模型 checkpoint 的存储路径,其实际完整路径为LLAMA_FACTORY_PATH与该变量的拼接,该目录会在微调过程中自动创建,用于存放 LoRA 微调后的权重文件。需特别注意的是,路径中的 “Qwen2-0.5B” 对应本次实战使用的基座模型名称,需同步修改该字段,避免不同模型的 checkpoint 混杂存储,影响后续模型合并。MERGED_PATH = 'd:\\mlflow\\merge'则是模型合并后的存储路径,仅需提前确保该目录存在,即可在 “合并 Lora 和预训练模型” 阶段接收合并后的完整模型文件。
ROOT_PATH = 'd:\\mlflow'作为运行环境数据根目录,统一管理全流程所需的自定义脚本与评估数据,目前该目录下存放四类关键文件:合并 Lora 与基础模型的merge_lora_model.py、注册模型到 MLflow 的register_model.py、模型评估脚本evaluate.py,以及评估数据集myTrain.json(对应变量EVAL_DATA = 'd:\\mlflow\\myTrain.json'),这种集中存储方式便于后续维护与路径调用。
最后是 Conda 环境与 Docker 相关变量,CONDA_ACTIVATE = "c:\\ProgramData\\anaconda3\\condabin\\activate.bat"指向 Conda 激活脚本的路径,需与实际安装的 Conda 路径匹配,后续各环节通过调用该脚本激活指定 Conda 环境;CONDA_ENV = "mlflow"则是本次实战使用的 Conda 环境名称,需与安装阶段创建的环境名称完全一致,确保微调、评估等依赖包能正常加载。CONTAINER_NAME = "llm_test"定义了模型部署阶段的 Docker 容器名称,后续启动容器、停止容器时均通过该名称识别目标容器,若需同时部署多个模型,可通过修改该变量区分不同容器。
Stages 脚本
按照九个不同的步骤,总结如下:
1. 验证参数
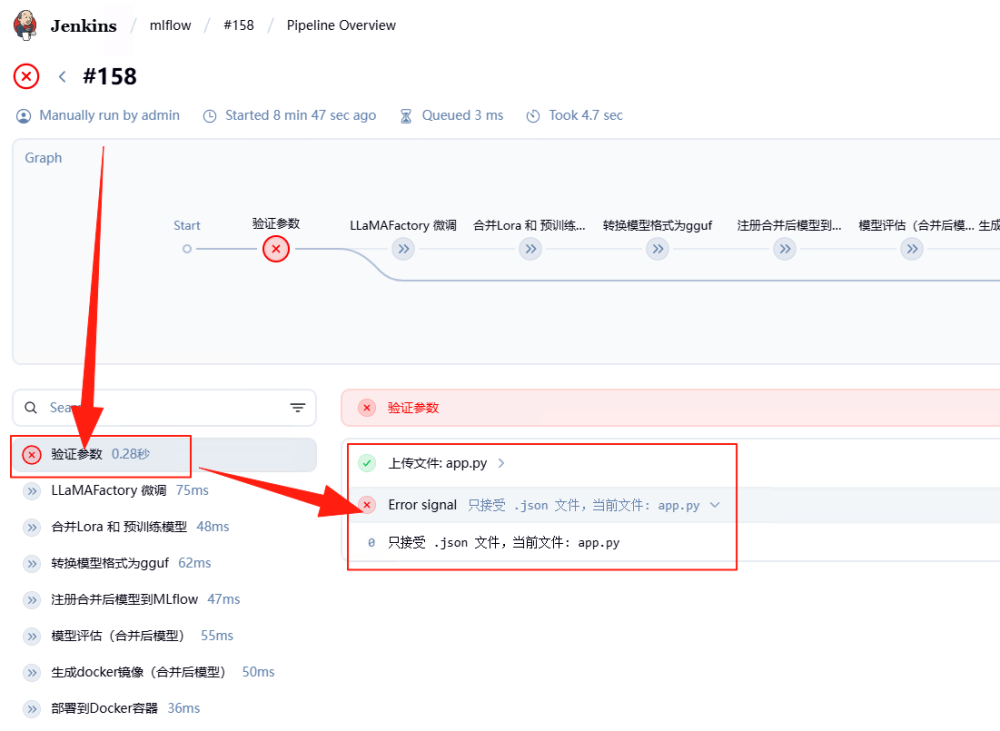
该阶段作为全流程的入口校验环节,负责确保所有必要输入符合规范。首先检查MLFLOW_TRACKING_URI参数是否为空,若为空则报错终止流程,确保 MLflow 服务地址有效;同时验证是否存在上传的微调数据集,未上传则直接报错。对上传的文件,先检查格式是否为.json,不符合则提示仅支持 JSON 格式;通过unstash恢复文件后,读取内容并解析为 JSON 对象,验证其根元素是否为数组,且每个子项是否为包含instruction、input、output字段的对象,确保数据结构满足微调要求。验证通过后,将文件复制到DATASET_URI指定路径,为后续微调提供标准化数据输入。
2. 微调模型
此阶段是模型定制的核心环节,通过 LLaMA-Factory 框架执行微调操作。流程上先激活CONDA_ENV指定的 Conda 环境,切换到 LLaMA-Factory 安装目录,再执行llamafactory-cli train命令启动微调。命令中明确了关键参数:采用监督微调模式(stage sft),使用 LoRA 参数高效微调技术(finetuning_type lora),数据集为dataset(与dataset_info.json配置对应),同时设置了学习率(5e-05)、训练轮次(20 轮)、批处理大小(2)、输出路径(TRAIN_OUTPUT_PATH)等训练参数。最终将微调产生的 LoRA 权重保存到指定目录,为模型合并提供基础。
3. 合并模型
该阶段用于整合微调得到的 LoRA 权重与原始基座模型。通过激活 Conda 环境,调用merge_lora_model.py脚本,传入三个关键参数:基座模型路径(params.MODEL_NAME_OR_PATH)、LoRA 权重路径(LLAMA_FACTORY_PATH与TRAIN_OUTPUT_PATH的拼接结果)、输出目录(MERGED_PATH),将两者合并为完整的模型文件并保存,为后续格式转换和部署提供统一的模型载体。
4. 转换模型
此阶段实现模型格式的转换以提升硬件兼容性。激活 Conda 环境后,切换到 llama.cpp 目录,先检查convert输出目录是否存在,不存在则自动创建;随后通过convert_hf_to_gguf.py脚本将MERGED_PATH中的合并模型转换为 GGUF 格式,输出至ROOT_PATH\\convert\\merge-auto.gguf。GGUF 格式的通用性使得模型可在更多硬件环境(如 CPU、边缘设备)中部署,拓展了模型的应用场景。
5. 注册模型
该阶段将合并后的模型纳入 MLflow 的版本管理体系。激活 Conda 环境后,执行register_model.py脚本,传入模型名称(params.MODEL_NAME)、模型目录(MERGED_PATH)、实验名称(params.MODEL_NAME)及 MLflow 服务地址(params.MLFLOW_TRACKING_URI),完成模型注册并将过程日志输出到文件。通过正则表达式从日志中提取模型版本号,存入MODEL_VERSION环境变量,为后续镜像生成和部署提供唯一版本标识。
6. 评估模型
此阶段用于验证合并后模型的性能指标。激活 Conda 环境后,切换到ROOT_PATH目录,执行evaluate.py脚本,传入模型名称(params.MODEL_NAME)、评估数据集路径(EVAL_DATA)、实验名称(params.MODEL_NAME)及 MLflow 服务地址,计算模型评估指标并将结果记录到 MLflow,为模型质量提供量化依据,确保其满足预期效果。
7. 生成镜像
该阶段为模型创建容器化部署的镜像。通过 Jenkins 凭据管理获取 Docker Hub 账号密码并完成登录,禁用 BuildKit 以避免 Windows 环境下的兼容性问题;激活 Conda 环境后,使用mlflow models generate-dockerfile生成镜像配置文件,同时修改 Dockerfile 插入 PyPI 国内源以加速依赖安装;最终基于修改后的 Dockerfile 构建带有版本标识(params.MODEL_NAME:vMODEL_VERSION)的镜像,为模型部署提供标准化载体。
8. 部署容器
此阶段将生成的镜像部署为可运行的容器服务。流程上先检查CONTAINER_NAME指定的容器是否存在,若存在则停止并删除旧容器;再基于新镜像启动后台运行的容器,将主机 8083 端口映射到容器 8080 端口,使模型服务可通过主机端口对外提供访问,完成模型从镜像到实际服务的转化。
9. 测试模型
作为全流程的收尾环节,该阶段验证部署的容器服务是否正常可用。激活 Conda 环境后,切换到ROOT_PATH目录,执行demo_api.py脚本调用容器的/invocations接口,测试模型服务的响应情况,确保接口正常通信且模型输出符合预期,最终完成整个 LLMOps 流程的闭环验证。
另外需要手动修改 LLaMAFactory 目录下的dataset 文件如下:
复制
因为在这个文件下对应的都是可以微调的文件的名字,我们在脚本中会指定使用 cusotm.json。这里会将用户上传的文件 copy 到cusotm.json 中进行微调处理。
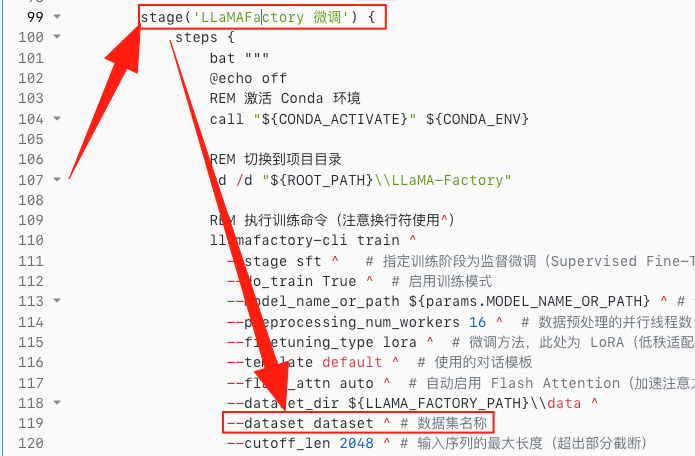
测试 LLMOps 流程
了解了整体 Pipeline 脚本之后,我们开始 LLMOps 流程的测试。首先下载大模型,如下:
复制看到类似下面的截图表示正在下载。
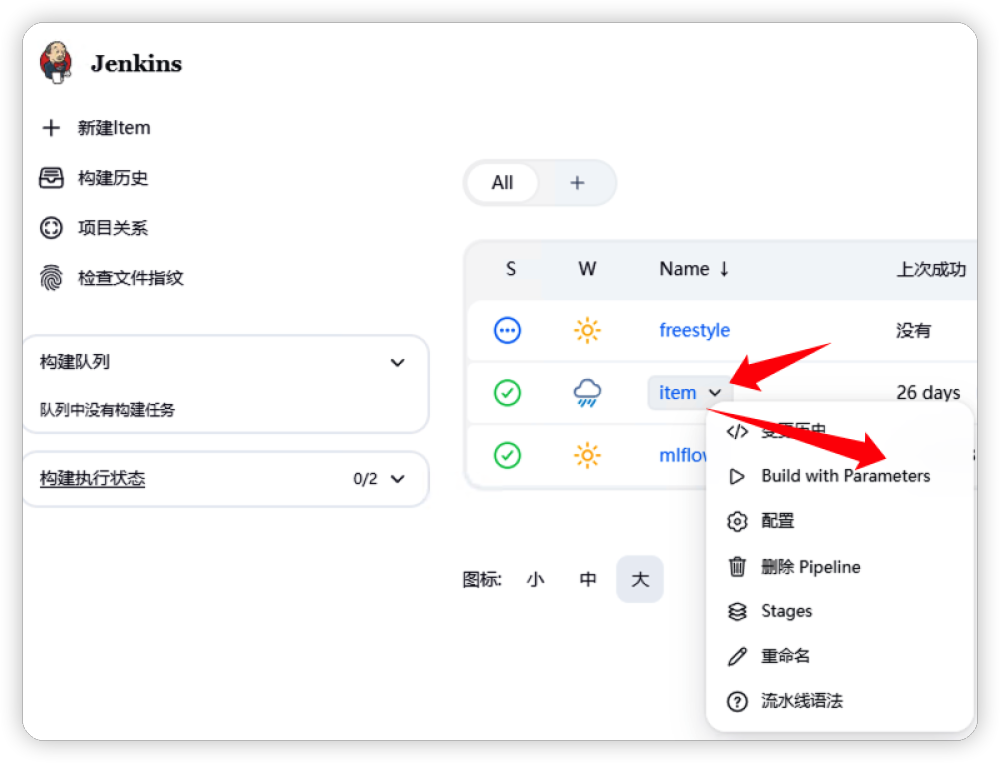
准备好模型之后,通过下图操作,启动 Pipeline 工作流。
填入参数包含:微调文件,MLflow 地址,基座模型存放目录,MLflow 中注册模型的名字。
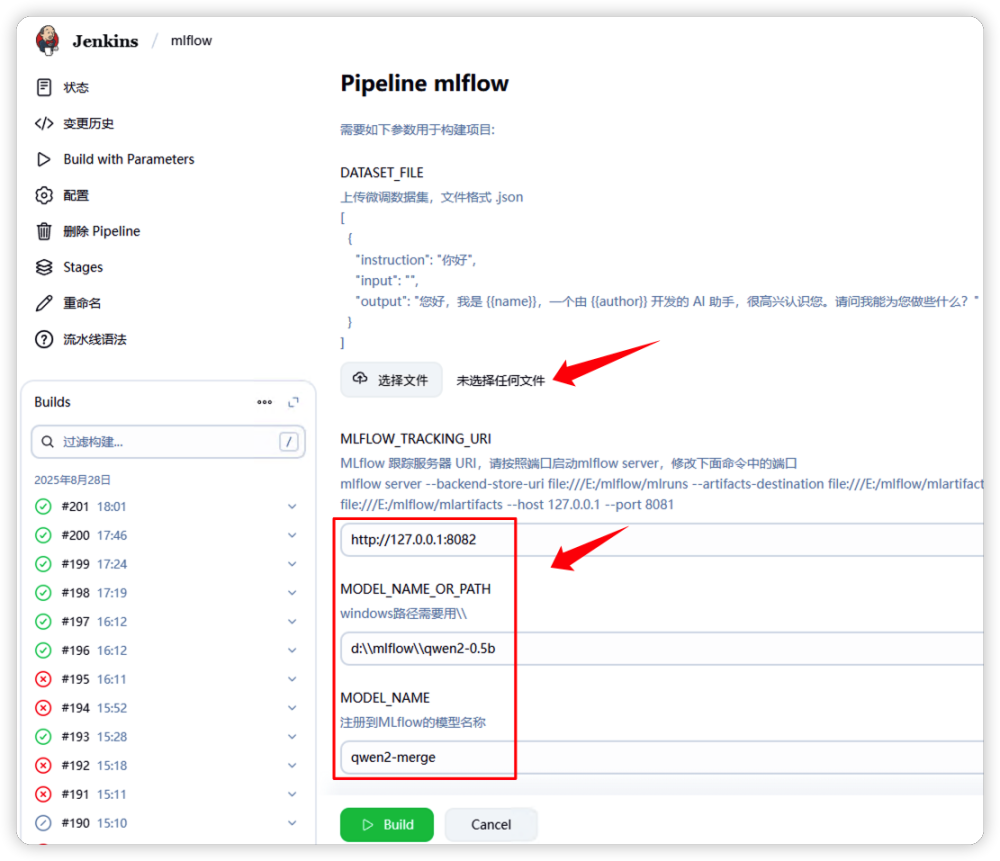
这里我们会上传 myTrain.json 文件作为微调的数据集文件, 其内容大致如下,由于篇幅关系我们就不粘贴所有的文本内容了。大约使用了这样的数据 200 余条进行微调。
复制此时,Pipeline 就开始工作了,由于整个过程比较漫长,特别是微调、评估、部署会花费比较多的时间,可以通过下面方法查看执行进度。选择执行的 Pipeline,然后点击“Pipeline Overview”。
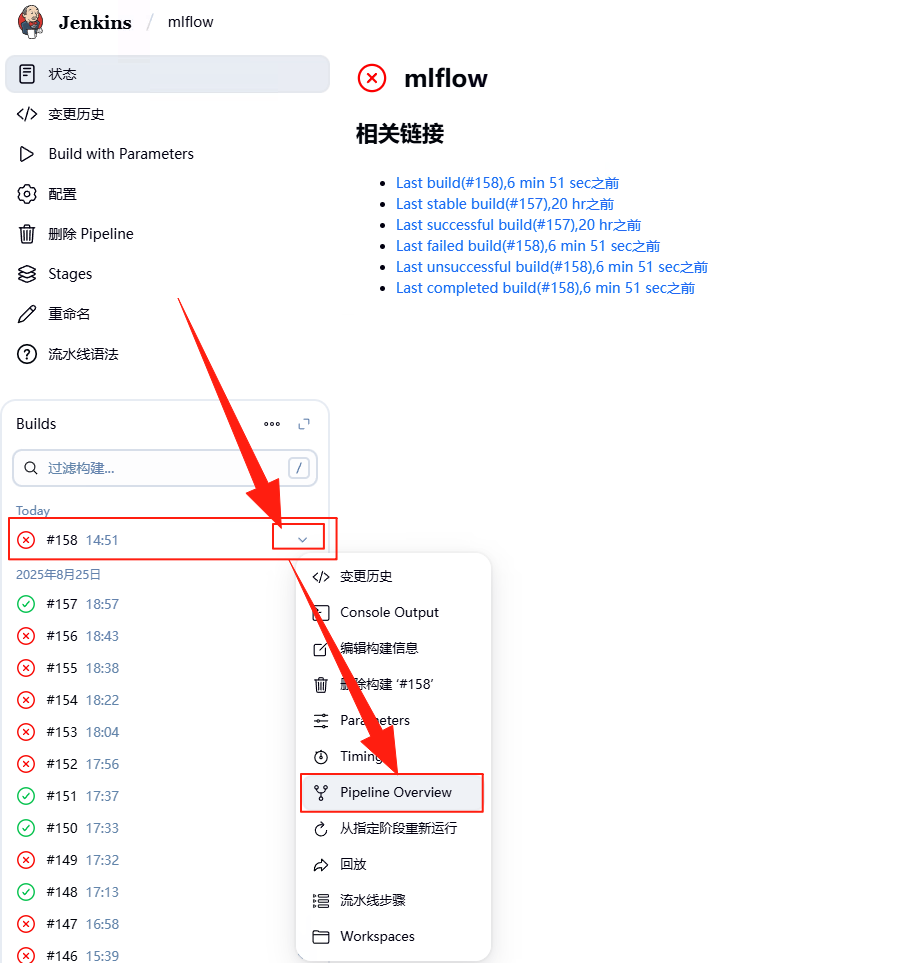
如下图所示,在最上方会显示执行的步骤。如果中途出现问题,点击步骤可以查看运行结果,以及错误原因。
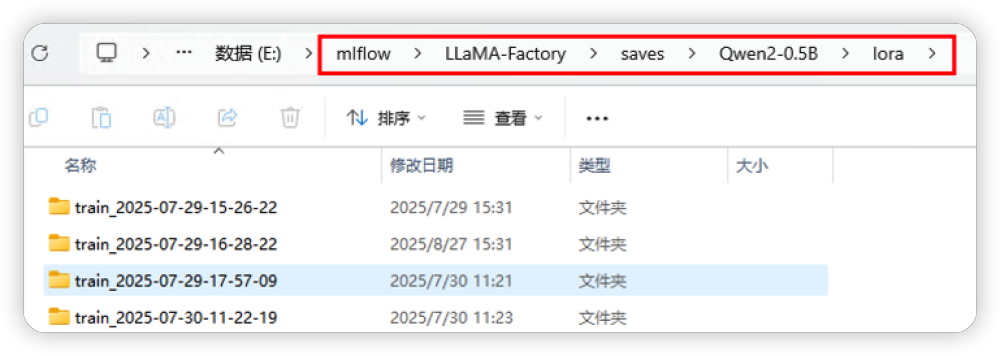
这里设置几个检查点,大家可以自行查看。比如LLaMAFactory 微调成功后会在配置的环境变量(TRAIN_OUTPUT_PATH)对应的目录下生成微调后模型。这里的模型都是 checkpoint,需要和之前下载的基座模型进行合并,然后才能部署。
合并之后的模型,可以通过MERGED_PATH 变量配置的目录查看。
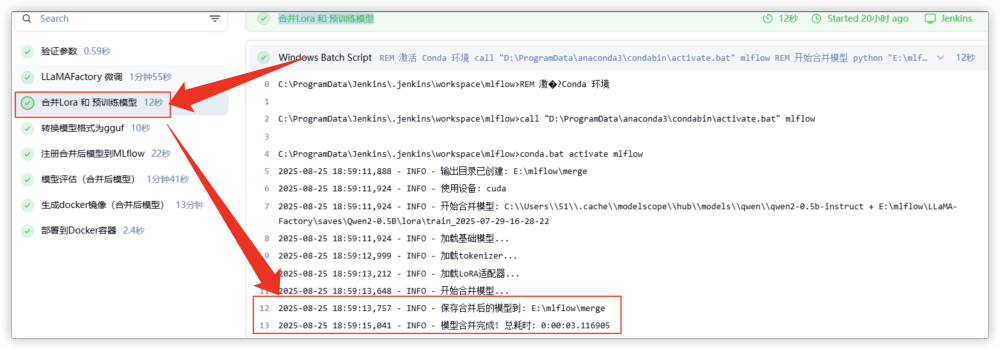
接着就是转化为 gguf 的模型,可以在对应的目录查到。
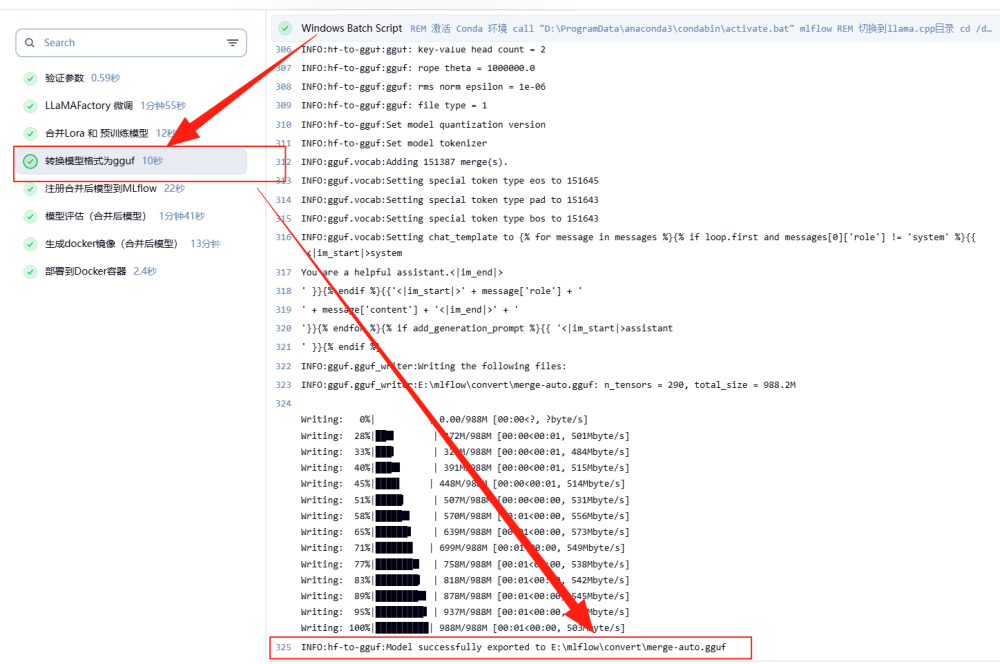
上述这些模型目录的查证不是必须的,这里是让大家知道整个过程中如何追踪文件生成,方便大家了解全过程,理解执行逻辑。
在注册模型阶段会把合并之后的模型在MLflow中注册,这里需要注意模型版本。
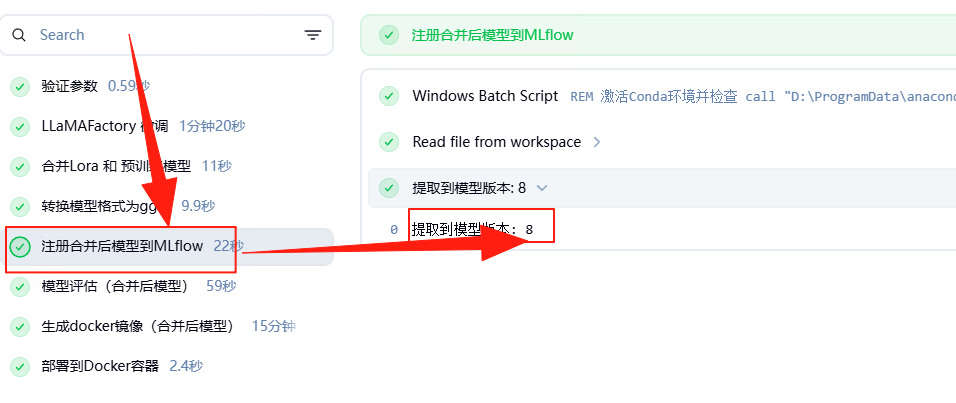
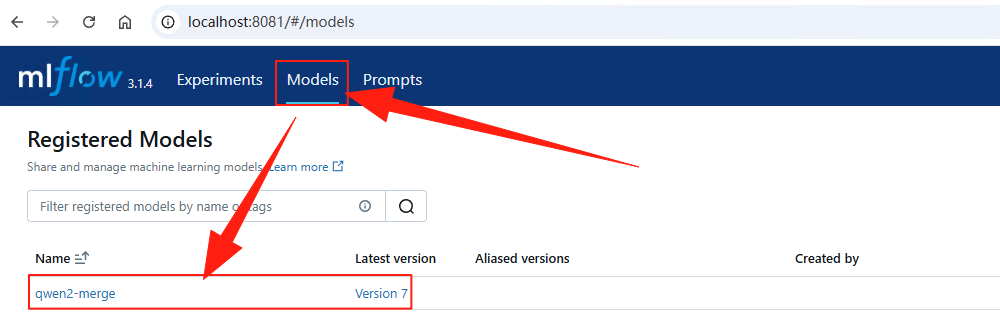
同时通过MLflow WebUI可以查看注册的模型信息。
按照下图的操作选择注册模型之后,可以看到模型的评估结果。
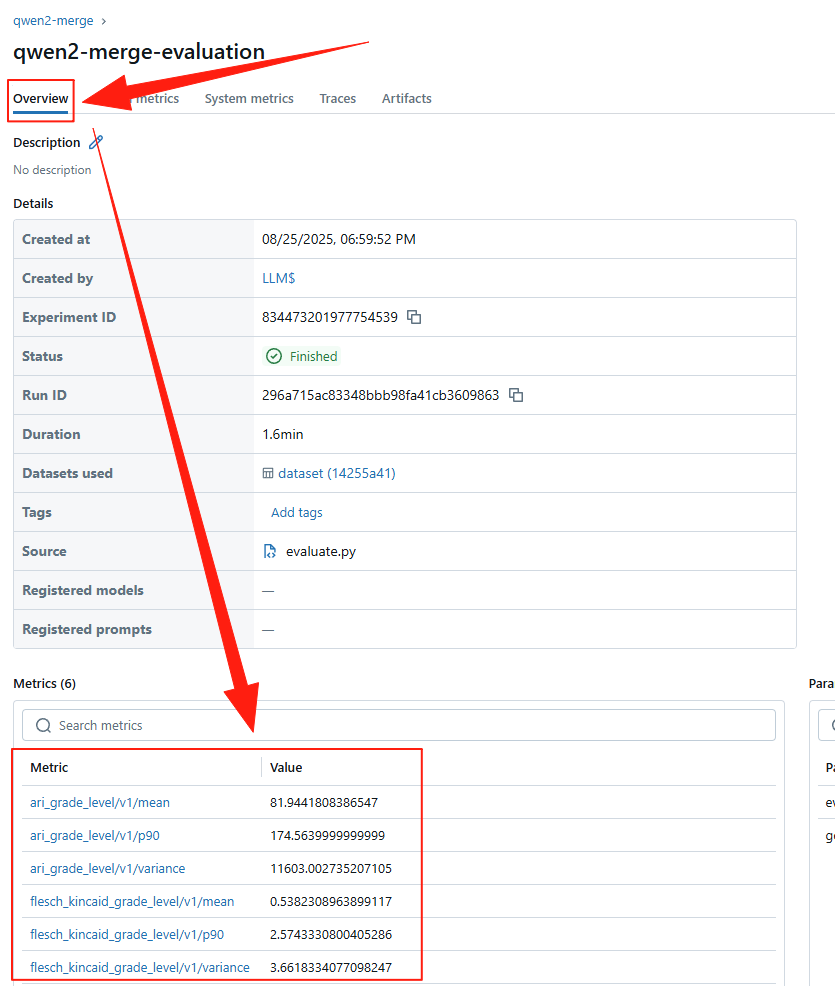
查看模型评估指标。
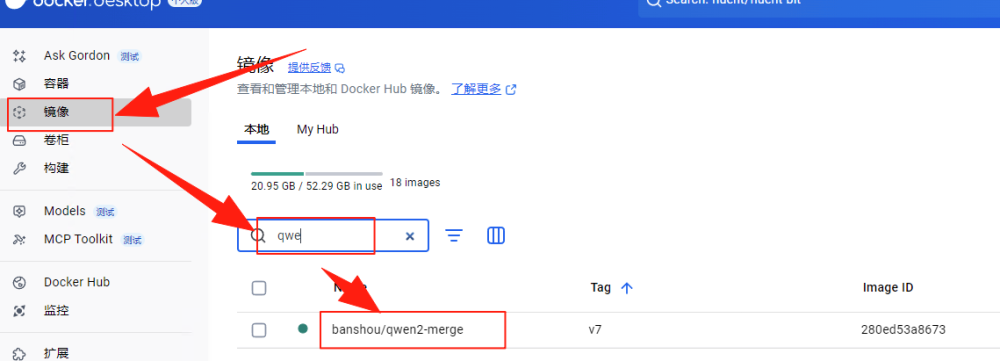
在完成模型评估之后,可以通过Docker Desktop查看生成的镜像,这里一眼就可以看到模型的名称,要注意的是模型版本会和注册到MLflow 中的版本一致。图中 “Tag”下面就是模型的版本。
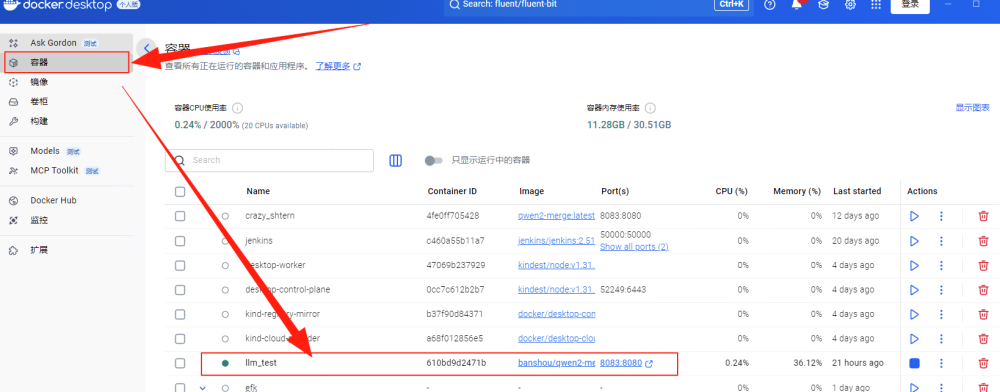
有了 Docker 镜像之后,就可以根据该镜像部署到Docker容器中,部署完成后会运行一个新的容器llm_test,这个名字在环境变量(CONTAINER_NAME)中配置过。
最后我们会通过模型的 API 接口调用模型,从而测试模型是否可以用,如下图所示,在运行成功后会在Jenkins控制台输出调用结果。
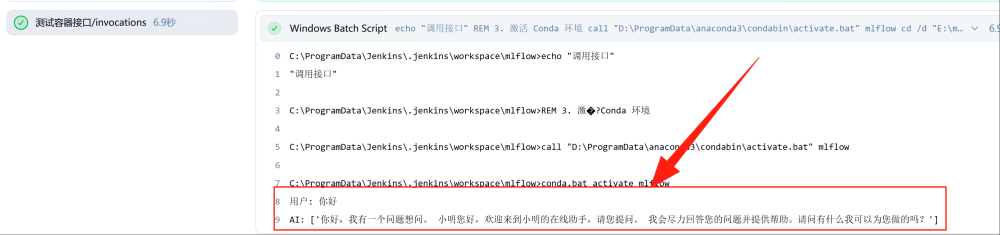
至此,整个 LLMOps 过程完结。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。


