
译者 | 朱先忠
审校 | 重楼
本文介绍ColPali与DocLayNet结合的多模态RAG系统,通过视觉语言建模理解文档中的表格、图表等布局信息,显著提升复杂文档问答的准确性和上下文感知能力。
简介
检索增强生成(RAG)已成为构建开放领域和特定领域问答系统的标准范例。传统意义上,RAG流程严重依赖于基于文本的检索器,这些检索器使用密集或稀疏嵌入来索引和检索段落。虽然这些方法对于纯文本内容有效,但在处理视觉复杂的文档(例如科学论文、财务报告或扫描的PDF)时,往往会遇到困难,因为这些文档中的关键信息嵌入在表格、图形或结构化布局中,而这些布局无法很好地转换为纯文本。
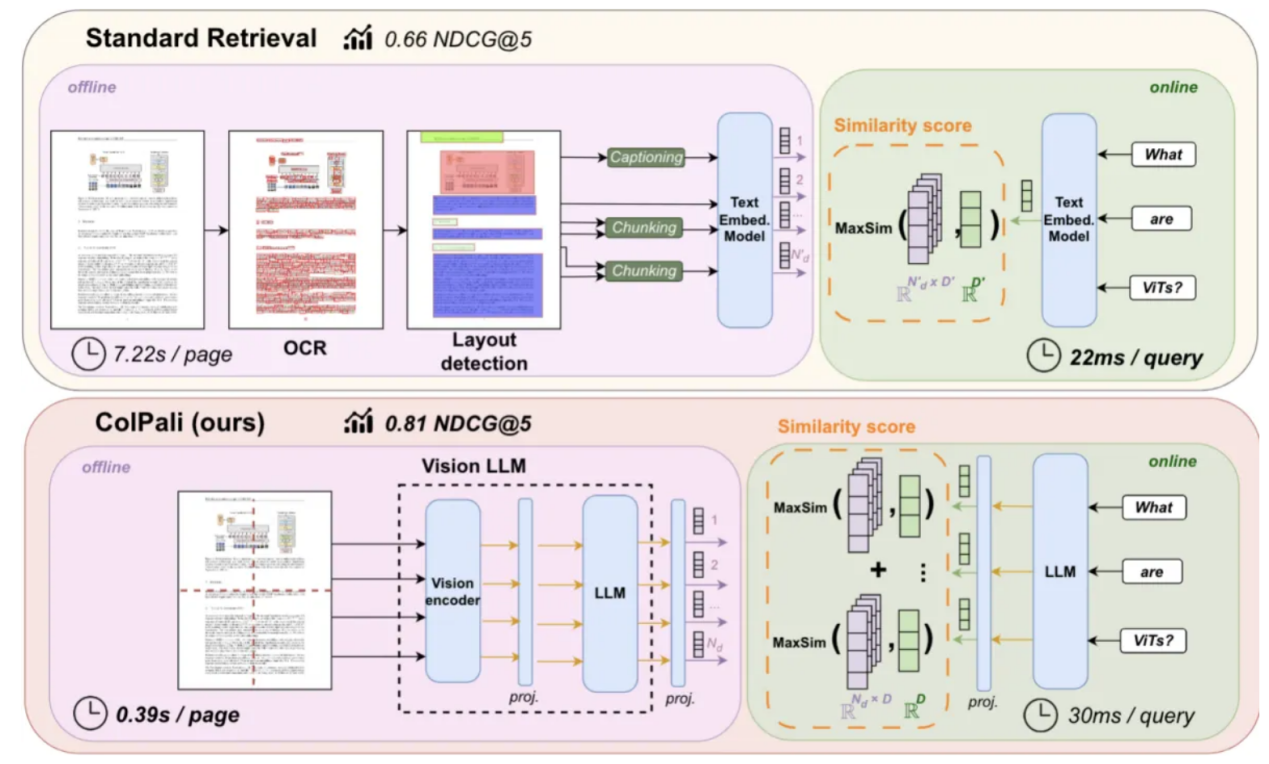
论文插图:与传统方法相比,ColPali简化了文档检索流程,同时提供了更高的性能和更低的延迟(来源:arxiv)
为了突破这些限制,Manuel Faysse等人近期的研究成果提出了ColPALI(ICLR 2025),这是一个视觉语言检索框架,它使用类似ColBERT的视觉嵌入后期交互,基于图像理解来检索文档内容。与此同时,Pfitzmann等人提出了Yolo DocLayNet(CVPR 2025),这是一个快速且布局感知的对象检测模型,专门用于以高精度和高效率提取文档组件,例如表格、图表和章节标题。
在本文中,我将指导你完成混合RAG管道的实际实现,该管道结合了ColPALI和DocLayout-YOLO,以实现对阅读和查看的文档的问答。
RAG系统中的视觉盲点
尽管在处理文本查询方面取得了成功,但大多数RAG系统都忽略了一个关键问题。它们几乎忽略了表格、图表和图形等视觉元素,而这些元素在许多实际文档中都承载着至关重要的意义。让我们来看看下图。
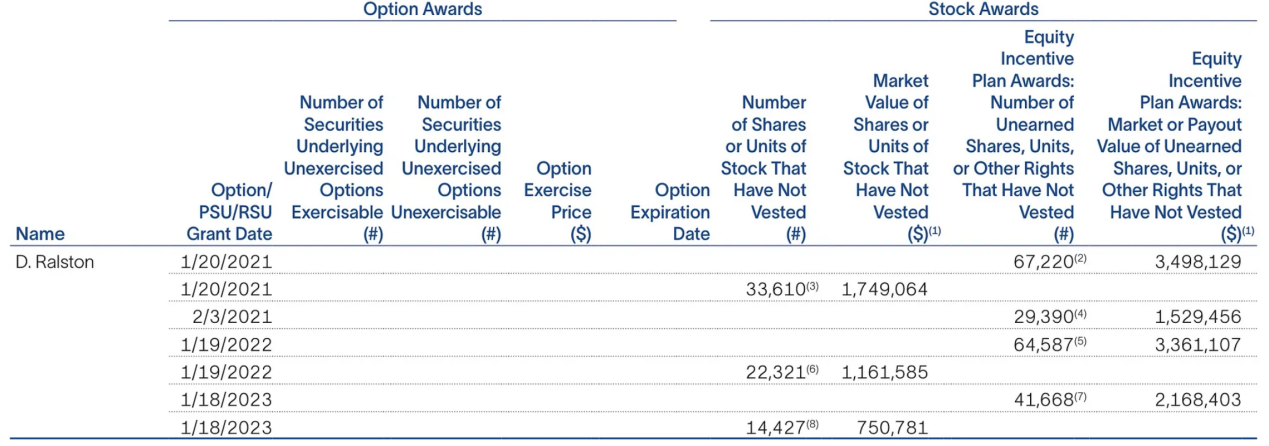
图片来自:SLB 2023年年度报告的摘录(资料来源:报告)
通过应用常见的OCR工具从表格中提取文本,我们可以得到以下结果。
复制
显然,OCR结果无法捕捉多层级标题结构和列分组,导致文本呈现扁平的线性,数值与其对应指标之间的关联性缺失。这使得数据所属类别(例如授予日期与股票奖励)难以识别,从而降低了提取数据对下游分析的实用性。
用户查询:What is the market value of unearned shares, units, or other rights that have not vested for the 1/20/2021 grant date?(2021年1月20日授予日尚未归属的未赚取股份、单位或其他权利的市场价值是多少?)
RAG回应:The market value of unearned shares, units, or other rights that have not vested for the 1/20/2021 grant date is $1,749,064.(2021年1月20日授予日尚未归属的未赚取股份、单位或其他权利的市场价值为1,749,064美元。)
由于提取的信息缺乏结构和上下文,因此产生的RAG响应不准确,因为它无法可靠地将值与原始表中的预期含义关联起来。
让我们探讨另一个例子来进一步说明传统RAG系统的局限性。
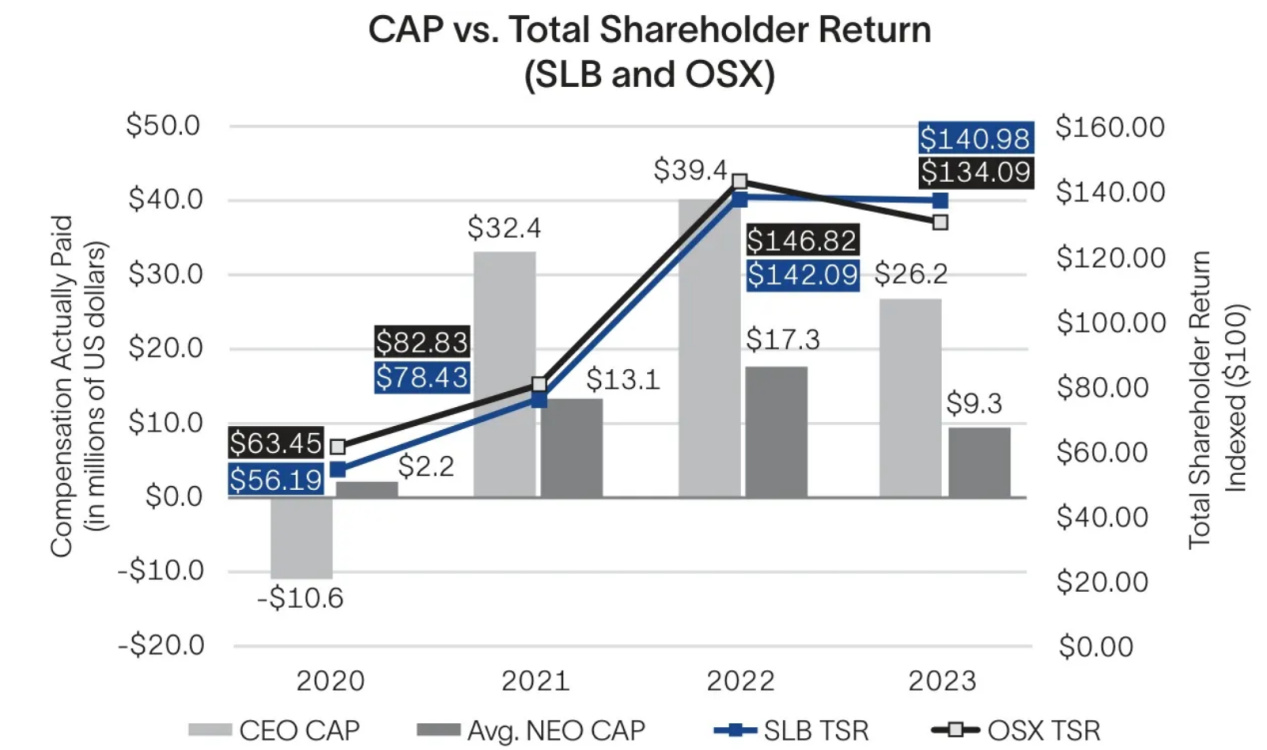
图片来源:SLB 2023年年度报告中的数据图表片段(来源:报告)
这是从上图中提取的OCR结果。
复制易知,该图表的OCR输出也缺乏结构一致性,未能捕捉数据点之间的关系,例如哪些条形或标签对应特定年份或股东回报率线。此外,它还未能将数值与其视觉元素进行对齐,导致难以区分每年的CEO CAP、NEO CAP和TSR值。
问题:What was the SLB Total Shareholder Return (TSR) in 2022?(2022年SLB总股东回报率(TSR)是多少?)
RAG回应:The SLB Total Shareholder Return (TSR) in 2022 was $134.09.(SLB2022年的总股东回报(TSR)为134.09美元。)
与前面的示例一样,由于OCR提取的数据中结构和上下文的丢失,此处的RAG响应也不准确。
多模态RAG架构
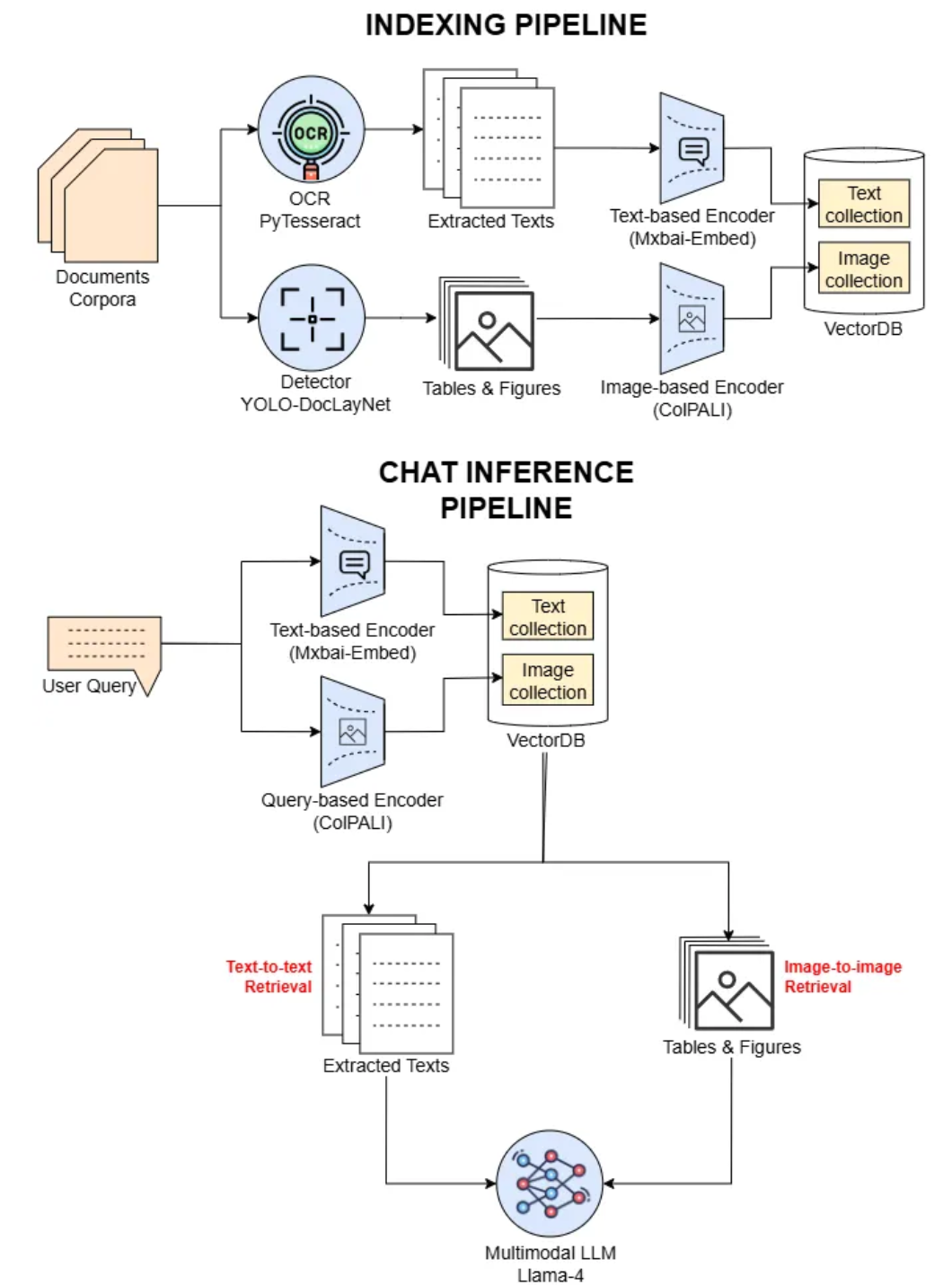
作者插图:我们实验中的多模态RAG架构
该架构由两个主要组件组成:索引管道和聊天推理管道。在索引阶段,文档语料库通过两条并行路径进行处理。第一条路径使用YOLO-DocLayNet检测器识别表格和图形等视觉元素,然后使用ColPALI图像编码器将其嵌入并存储在图像向量集合中。第二条路径使用PyTesseractOCR从文档中提取原始文本,然后使用Mxbai-Embed模型对其进行编码,并保存在同一向量数据库中的文本向量集合中。
在聊天推理过程中,用户查询会同时由用于Mxbai-Embed文本检索的编码器和用于视觉语言检索的ColPALI编码器进行编码。然后,系统会针对各自的向量集合执行双重检索(文本到文本和文本到图像)。检索到的文本和图像区域会被转发到多模态LLM(LLaMA-4),该模型会综合两种模态,生成上下文感知且准确的响应。这种设计将文本理解与细粒度的视觉推理相结合,从而实现强大的文档质量保证(QA)。
我的测试设置
A. 环境设置
为了高效运行完整的多模式RAG管道,我使用单个NVIDIA RTX A6000 GPU和48GB的VRAM,这为运行ColPALI、YOLO模型和句子嵌入模型提供了足够的内存。
对于软件环境,我建议使用Miniconda来隔离你的依赖关系并确保可重复性。
1.创建Conda环境
复制2. 准备requirements.txt
复制3.安装Python依赖项
复制B.预训练模型设置
要复现此实验,你需要下载检索和布局提取流程中使用的三个预训练模型。所有模型都将存储在该pretrained_models/目录下,以保持一致性并更易于加载。
下面是使用Hugging Face CLI下载它们的命令hf transfer,该命令针对更快的下载速度进行了优化:
复制C. 代码设置和初始化
复制上述代码初始化了多模态检索系统的核心组件。它设置了设备(GPU或CPU),确保图像输出目录存在,并加载了三个预训练模型:YOLOv12L-DocLayNet模型(用于检测表格和图形等布局元素)、ColQwen2.5模型(其ColPALI处理器用于对裁剪图像区域进行视觉语言嵌入)以及mxbai-embed-large-v1模型(使用SentenceTransformers嵌入文本)。此外,它还定义了检测到的实体类型的颜色映射,以支持预处理过程中的可视化。
索引管道
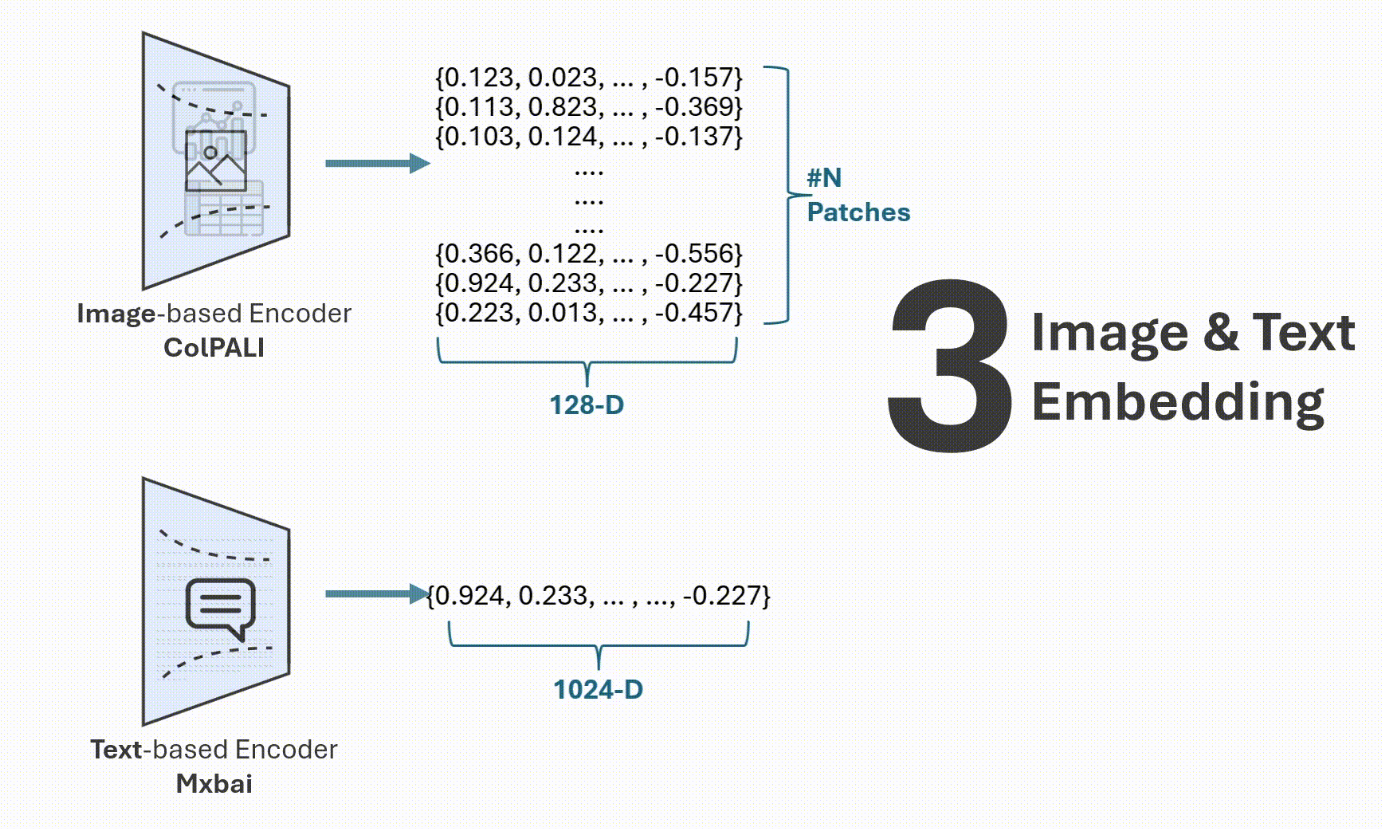
作者插图:索引管道
索引管道负责将原始文档转换为结构化的、可搜索的文本和视觉表示形式。在本节中,我们将逐步讲解实际实现过程,展示如何使用代码处理、编码和存储文档内容。
A. 准备
在继续开发之前,让我们准备一些对分析有用的处理函数。
复制上面的两个辅助函数将用于可视化布局检测。其中,display_img_array将BGR图像转换为RGB并使用matplotlib显示它;同时,show_layout_detection使用YOLO检测结果和特定于类的颜色在检测到的布局元素(例如表格、图形)上叠加边界框和标签。
接下来,让我们准备要加载的PDF中的特定页面,如下所示。
复制此代码使用PyMuPDF从PDF文件加载特定页面,以高分辨率呈现,并将其转换为适合OpenCV处理的BGR图像数组。
B.布局检测
现在,让我们编写如下布局检测代码。
复制在此步骤中,我们专门过滤检测到的布局元素,使其仅包含与嵌入的相关视觉区域相对应的类标签6(表格)和8(图形)。
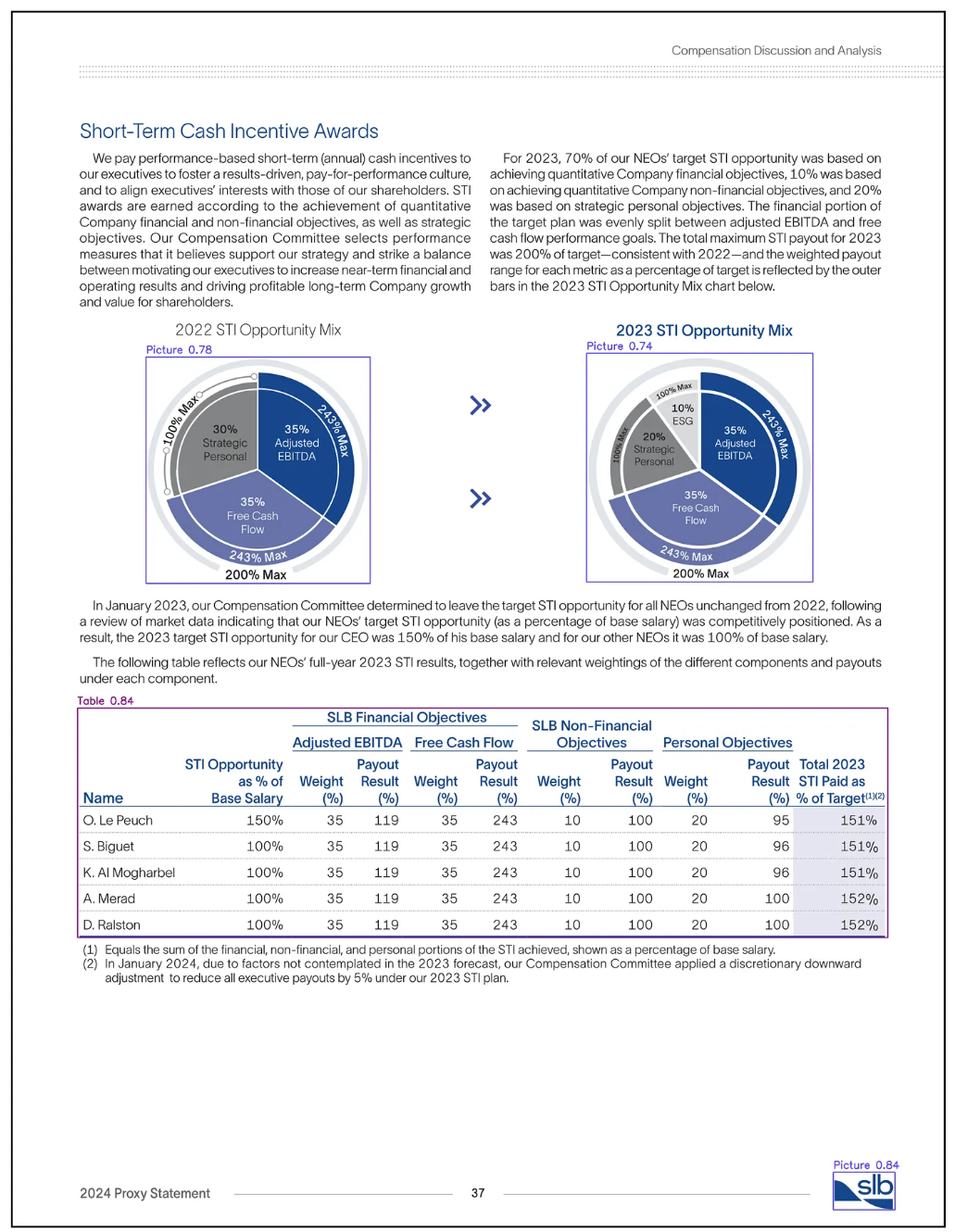
图片来源:SLB 2023年年度报告第37页(来源:报告)
在这里,我们成功定位了相关的视觉对象,例如圆形图和表格,这些将用于下游的视觉嵌入。
C. 提取并保存
接下来,让我们从图像中检索本地化的表格和图片区域,并用白色遮罩它们以将它们从原始页面视图中删除。
复制此函数从文档图像中提取检测到的表格和图片区域,并用白色遮罩这些区域,返回裁剪后的视觉效果和更新后的图像。更新后的页面图像如下所示。

图片来源:SLB 2023年年度报告第37页(来源:报告)
接下来,让我们使用如下代码保存提取的图形。
复制此代码将提取的图形和表格图像保存到指定的本地目标目录中img_dir。
D.文本OCR
在此步骤中,让我们使用带有pytesseract的普通OCR从屏蔽文档图像中提取剩余的文本信息。
复制结果如下:
复制E. 使用Milvus DB Client建立索引
在此步骤中,我们将使用Milvus数据库进行向量存储和检索;我们选择使用文件milvus_file.db的简单本地实例来进行此实验,而不是使用可扩展的生产级设置。
1.Retriever类
让我们定义两个检索器:用于细粒度基于图像的检索的ColBERT样式检索器和用于基于文本的检索的基本密集检索器。
复制这段代码定义了两个与Milvus交互的检索器类,以支持混合检索:
- MilvusColbertRetriever专为使用ColBERT样式的多向量嵌入进行基于图像的检索而设计。它支持插入来自ColPALI的块级视觉嵌入,使用后期交互(MaxSim)对结果进行重新排序,并返回最匹配的图像区域及其元数据和base64编码的内容。
- MilvusBasicRetriever用于基于文本的检索。它存储并搜索来自句子嵌入的单个密集向量,对余弦相似度进行归一化(通过内积),并检索最相关的文本块及其源元数据。
两种检索器均可处理集合创建、索引和插入,从而实现对视觉和文本文档内容的灵活的多模式检索。
2. Retriever设置
使用上面定义的检索器类,让我们初始化ColBERT风格的图像检索器和基本文本检索器,并将它们安装在由milvus_file.db支持的本地Milvus实例上,以进行存储和检索。
复制对于初始化步骤,我们必须为两个检索器创建集合和索引,如下所示。
复制3.图像数据加载器
让我们将使用ColPALI模型的图像嵌入过程包装到数据加载函数中。
复制此函数将提取的图像区域列表包装到DataLoader中,并使用ColPALI模型对其进行处理,并返回每个图像的多向量嵌入列表。返回列表的结果如下。
复制4. 图像和文本索引
在此步骤中,让我们将页面图像中提取的数据组件(包括图像和文本)索引到数据库集合中。
复制此代码将每个图像嵌入到ColBERT样式检索器中,并附带相关元数据,分配唯一的doc_id并存储页面和图形索引引用。
复制此代码将文本嵌入及其元数据(包括内容、页面ID和文件名)插入到基本文本检索器中进行索引。
5. Retriever测试
最后,让我们测试一下上面设置的检索器。
复制此代码使用ColPALI模型嵌入用户查询,并从ColBERT风格的检索器中检索出最相关的前3个图像区域。结果如下。
复制接下来,让我们测试一下基本的检索器。
复制此代码使用文本嵌入模型对查询进行编码,并从基本检索器中检索出最相关的前3个文本条目。结果如下。
复制在这里,得分的差异是由于检索方法造成的:ColBERT风格的检索器使用内积(IP),从而产生更大的分数值,而基本检索器反映余弦相似度,通常会产生在-1和之间较小范围内的分数+1。
聊天推理管道
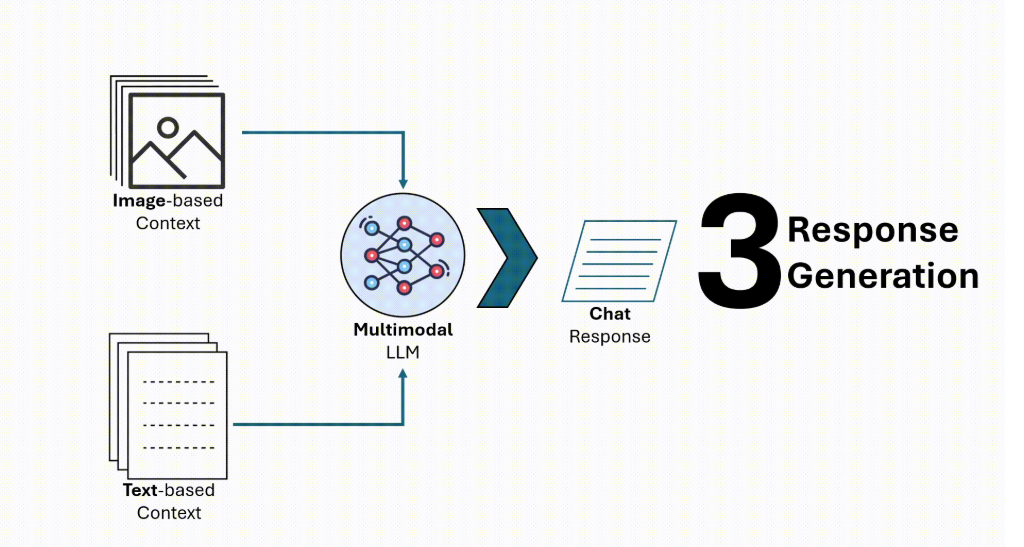
作者插图:聊天推理管道
聊天推理管道通过从文本和图像嵌入中检索相关内容来处理用户查询,从而生成准确且情境感知的响应。在本节中,我们将实现查询编码、检索和多模态步骤,以完成端到端问答工作流程。
A. 准备
对于聊天补全模型,我们使用Meta开发的一款功能强大的多模态LLM Llama-4。我们将使用GROQ API Key来使用此Llama模型。代码如下。
复制接下来,让我们准备一些处理函数,如下所示。
复制此代码定义了一个函数,用于将base64编码的图像转换为可显示的URL,以及一个llama推理函数,用于通过Groq的API使用LLaMA 4 Maverick模型执行流推理。
B. 用户查询和相关上下文
现在,让我们定义用户查询并检索相关上下文,如下所示。
复制此代码使用ColPALI模型执行文本到图像检索的查询嵌入,并使用句子嵌入模型执行文本到文本检索,遵循与上一个检索步骤相同的方法。
C.系统指令
接下来,让我们为我们的llama模型定义系统指令提示,如下所示。
复制该系统指令定义了助手应如何基于两种类型的文档上下文(基于文本和基于图像)回答用户查询。它指导模型判断是否需要图像来回答查询,并以严格的JSON格式构建响应,并包含一个标志(need_image)和一个image_indexif applicable标记。该指令确保文档理解任务的响应一致、可解释且支持多模式感知。
D. 消息有效载荷
接下来,让我们创建将传递给Llama模型API的消息有效负载,如下所示。
复制此代码通过将用户查询、检索到的图像(以base64 URL的形式)和基于文本的上下文组合成结构化消息格式,构建LLM的输入负载。然后,它将这些内容与系统指令一起包装,形成最终的messages推理输入。
构造messages如下。
复制E.模型推理
现在,让我们使用Llama模型来预测响应,如下所示。
复制此代码运行LLM推理,使用正则表达式从输出中提取最后的JSON格式的响应,并将其解析为Python字典以供进一步使用。
由此推论可得出如下结果。
复制F. 输出响应
下一步是按如下方式构建输出响应。
复制此代码检查LLM响应是否需要图像;如果需要,则从ColBERT检索器结果中检索相应的base64图像内容。然后,它会构建一个最终响应字典,其中包含答案文本、图像标志以及图像内容(如果适用)。
最终构建的响应如下。
复制评估
在本节中,我们将讨论我们提出的多模态RAG管道和标准纯文本RAG管道之间的定性比较,重点介绍检索相关性和答案质量方面的关键差异,特别是对于基于视觉的查询。
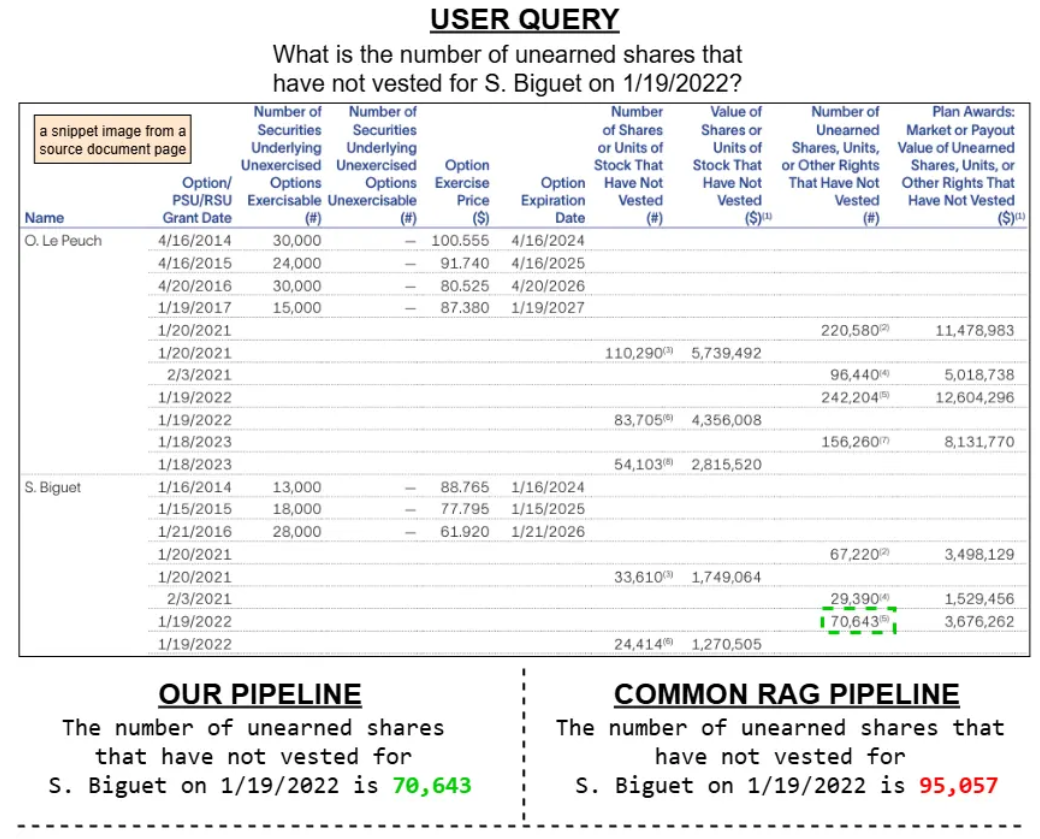
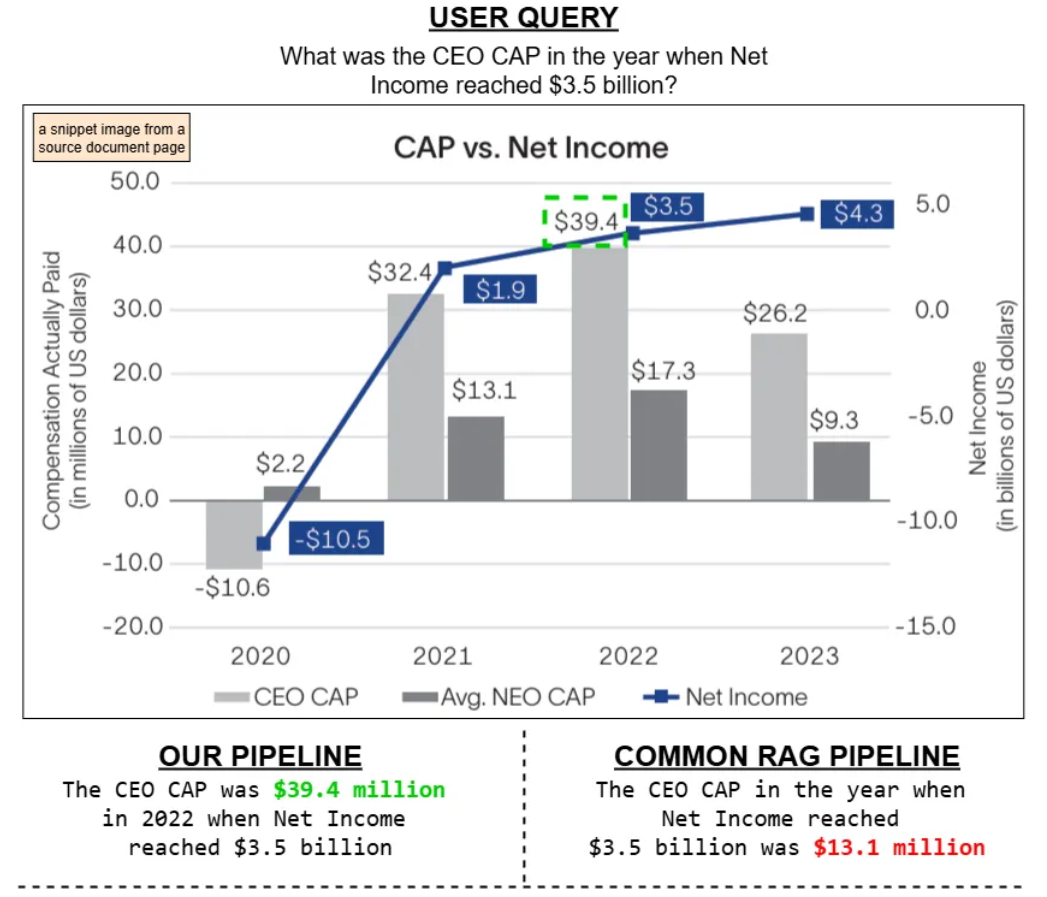
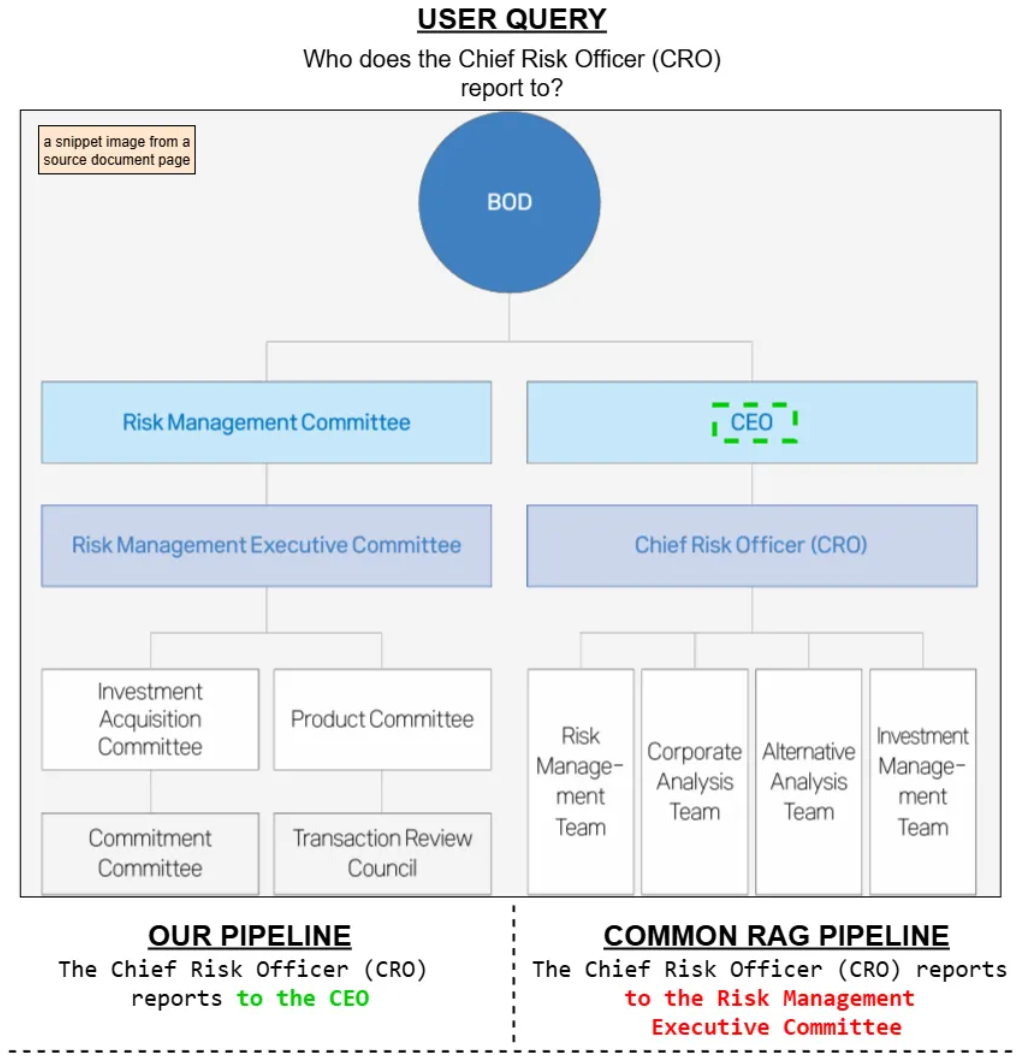
作者插图:我们的管道与常见的RAG管道的比较
我们的定性比较表明,多模态RAG流程比标准的纯文本RAG系统能够提供更准确的答案,尤其是在涉及表格、图形和图表等结构化视觉内容的查询时。标准RAG流程依赖OCR将文档视觉内容转换为纯文本,这通常会导致空间结构的丢失和关键信息的误解。
相比之下,我们的系统结合了基于ColPALI的图像检索、用于布局检测的YOLO DocLayNet以及标准文本嵌入,从而同时保留视觉和语义上下文。这使得它能够准确地检索和推理基于OCR的流程通常会遗漏的内容,凸显了真正多模态方法的有效性。
进一步的演示
我开发了一个简单的基于Chainlit的应用程序来总结我们的实验。以下是该Web应用程序的前端概览。
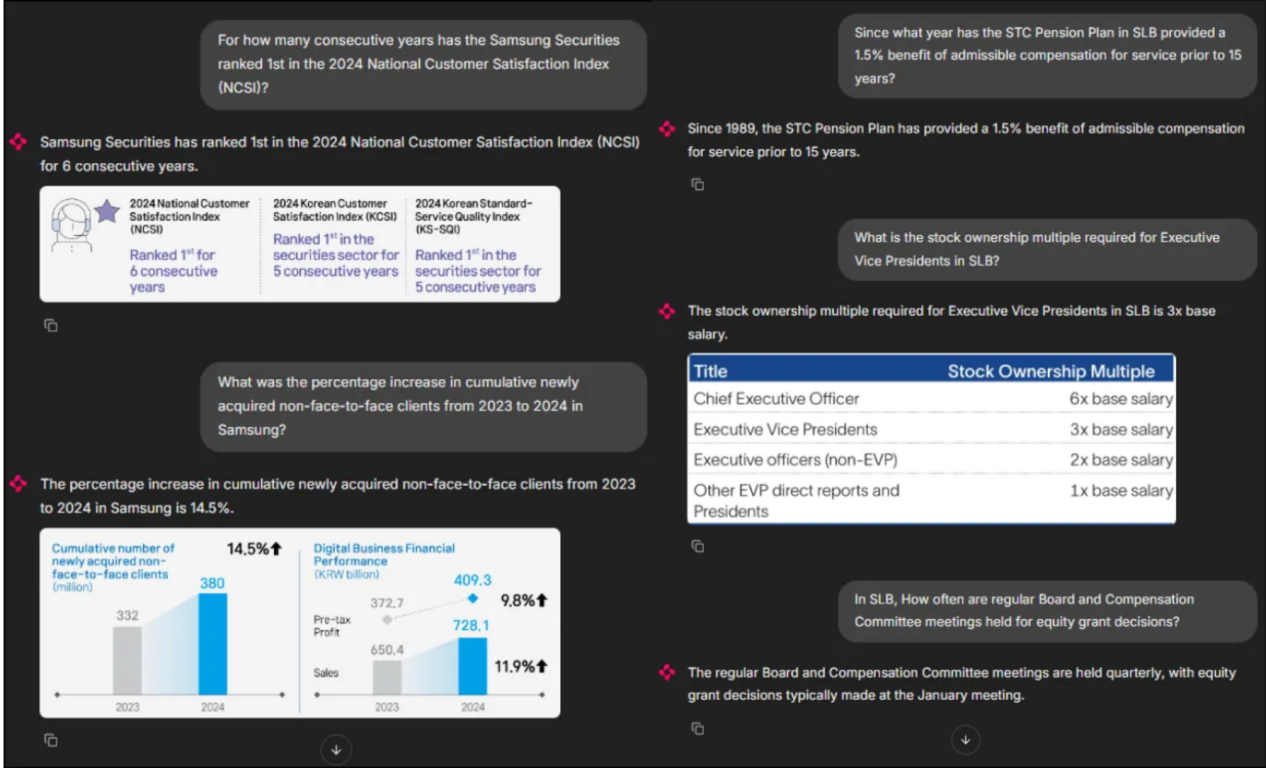
作者插图:多模式RAG应用程序的前端
通过此应用程序,聊天机器人能够检索文本和图像信息来回答用户查询。当用户查询相关时,它还可以显示相关图像,以增强理解并提供更清晰的背景信息。
为了复制此Web应用程序及其对应的后端服务器,我创建了一个GitHub存储库,你可以在此处访问。此存储库完全复制了我们的实验,包括完整的知识库索引管道以及端到端部署所需的所有组件。
结论
在本文中,我们构建了一个多模态RAG系统,该系统结合了用于基于图像的检索的ColPALI和用于视觉区域检测的YOLO-DocLayNet,从而突破了传统纯文本检索的局限性。通过实际结果演示,我们展示了如何将文本和视觉上下文相结合,在文档问答任务中提供更准确、更具有上下文感知的答案。
参考文献
- Faysse, M.,Sibille, H.,Wu, T.,Omrani, B.,Viaud, G.,Hudelot, C.和Colombo, P.(2024)。ColPali:基于视觉语言模型的高效文档检索。arXiv预印本arXiv:2407.01449。地址:https ://arxiv.org/abs/2407.01449。
- Pfitzmann, B.,Auer, C.,Dolfi, M.,Nassar, AS和Staar, P.(2022)。DocLayNet:用于文档布局分割的大型人工注释数据集。载于第28届ACM SIGKDD知识发现与数据挖掘会议论文集(第3743-3751页)。
- Reimers, N.和Gurevych, I.(2020)。利用知识蒸馏将单语句子嵌入多语言化。载于2020年自然语言处理实证方法会议(EMNLP)论文集。计算语言学协会。地址:https ://arxiv.org/abs/2004.09813。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:ColPALI Meets DocLayNet: A Vision-Aware Multimodal RAG for Document-QA,作者:Abu Hanif Muhammad Syarubany


