Meta发布了 Code World Model (CWM,论文:CWM: An Open-Weights LLM for Research on Code Generation with World Models),一个拥有32B参数的开源大语言模型(LLM),旨在推动基于世界模型的代码生成研究。与传统仅从静态代码训练的模型不同,CWM在大规模 Python解释器执行轨迹 和 agent性Docker环境交互轨迹 上进行中期训练,并在可验证编码、数学和多轮软件工程环境中进行多任务强化学习(RL)。CWM为研究者提供了探索世界建模在代码生成中通过推理和规划提升能力的强大平台。
 图片
图片
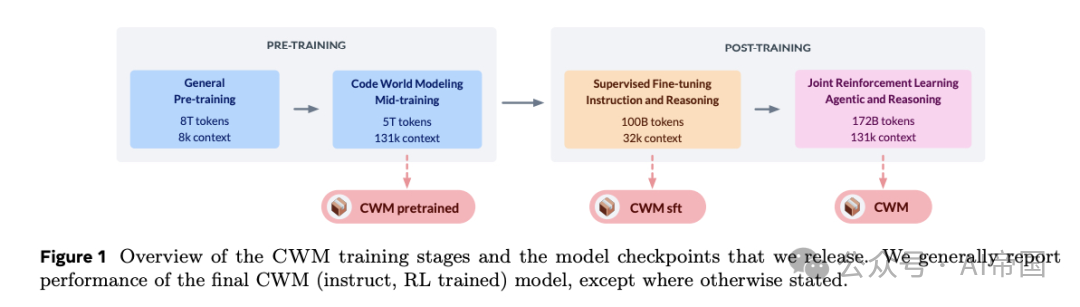
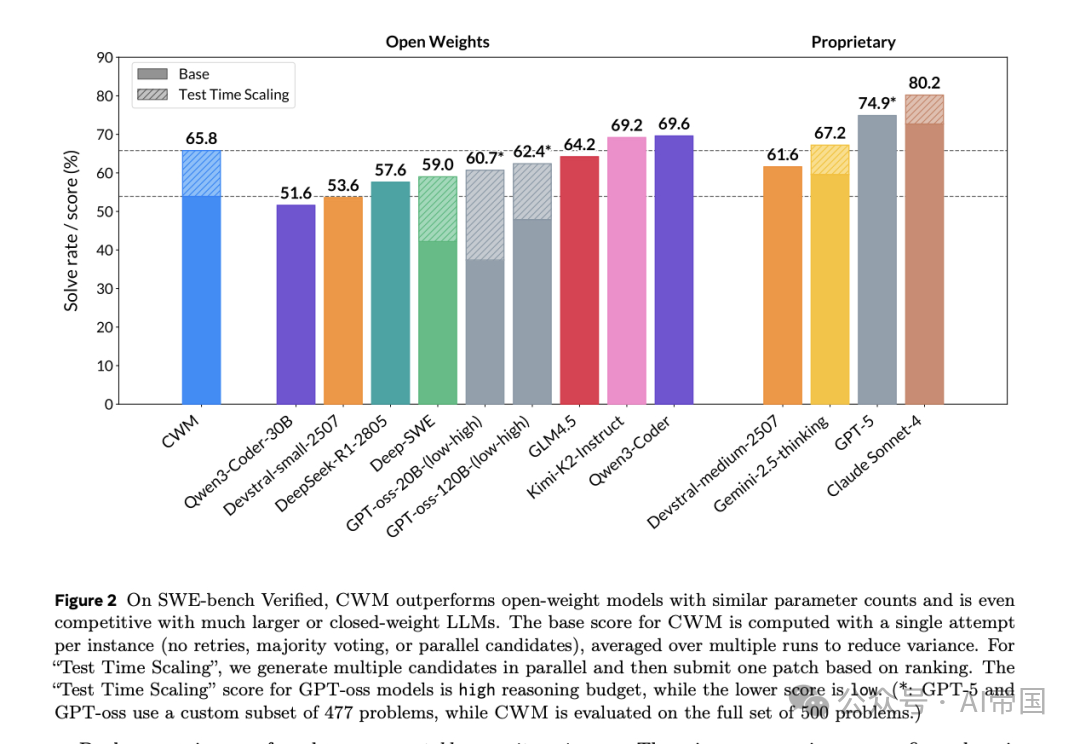
CWM是一个仅解码器的密集型LLM,支持最大131k上下文长度训练。在通用代码和数学任务中表现优异:在 SWE-bench Verified 达到65.8% pass@1,在 LiveCodeBench 达到68.6%,在 Math-500 上达到96.6%,在 AIME 2024 上达到76%。论文同时发布了中期训练、SFT和RL阶段的模型检查点,支持研究者进一步探索代码世界模型。
 图片
图片
软件开发是LLM应用最活跃的领域之一。从生成小片段代码到自主编写完整代码库,LLM能力正在迅速提升。然而,高质量代码的可靠生成仍然具有挑战性。推动代码生成的进步,需要新的训练和建模范式。
传统预训练中,代码被视为文本,模型通过逐行预测学习语法特征。但掌握编程还需要理解代码执行时的行为:局部变量变化、程序输出影响等。CWM旨在教授模型这种 代码世界建模能力。
论文通过两类观察-动作轨迹进行中期训练:Python代码执行轨迹:动作是Python语句,观察是局部变量的状态。模型学习代码的语义,而不仅是语法;Docker环境中agent性交互轨迹:使用ForagerAgent生成,涵盖软件工程场景,如修复错误或实现功能。动作包括shell命令或代码编辑,观察是环境响应。
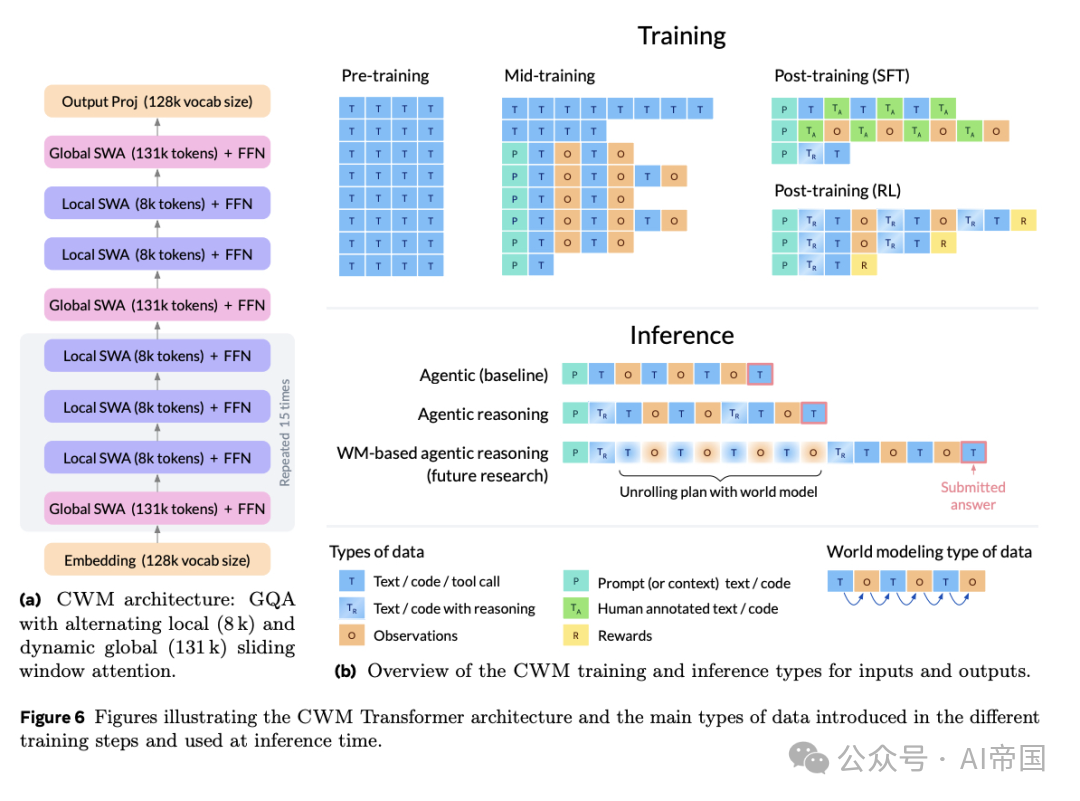
CWM采用32B参数密集型解码器Transformer架构,支持滑动窗口注意力和131k最大上下文长度。其在各种代码和推理任务中表现优异,也为探索基于世界模型的推理和规划提供了基础。
编码世界模型数据集
CWM在预训练、中期训练和后期训练阶段使用了多样数据集,重点是 Python执行轨迹 和 ForagerAgent交互数据。
可执行存储库映像:论文构建了 Docker容器存储库映像,支持隔离和可重复执行存储库代码和测试。通过RepoAgent和Actiw流程,论文创建了超过 35k个可执行存储库映像,保证了大规模的Python执行数据收集。
 图片
图片
Python跟踪:论文收集函数级和仓库级Python执行跟踪,捕获每行代码执行后的局部变量状态。数据来源包括:
•函数级跟踪:从在线函数数据集收集,结合模糊测试和LLM生成输入输出对,最终超过 120M条跟踪。
•CodeContests解决方案跟踪:生成编程竞赛问题的Python解决方案,经过筛选和单元测试验证,最终保留约 33k代码片段和70k跟踪。
•仓库级跟踪:对超过21k可跟踪仓库映像进行跟踪,最终生成约 70k提交记录。
论文还生成 自然语言跟踪数据,将代码执行逐步解释为自然语言描述,便于知识迁移和推理任务训练。
 图片
图片
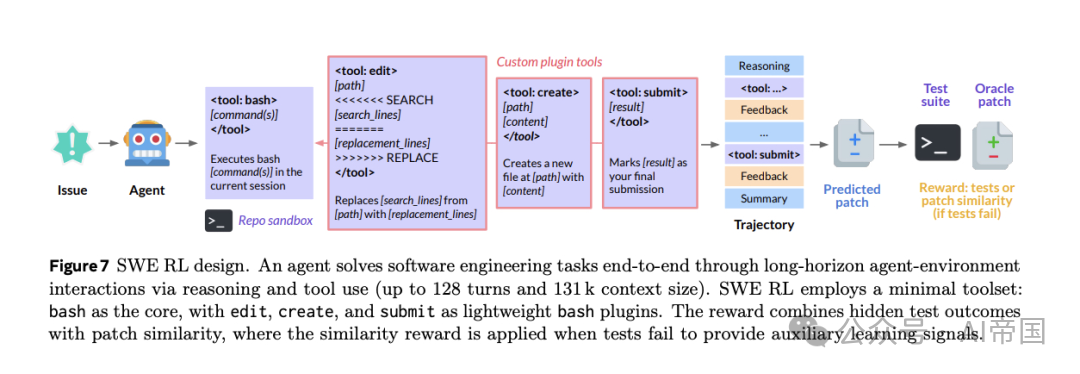
ForagerAgent是一个LLM驱动的软件工程agent,与计算环境交互,生成大规模agent数据。任务分为:
1.Mutate-Fix任务:在已有代码库中引入合成错误,让agent修复。
2.问题修复任务:使用实际GitHub问题和PR数据,让agent修复真实软件问题。
通过近似去重处理,最终收集 3M条轨迹,用于中期训练,增强模型对agent交互和代码环境的理解。
代码世界建模示例
CWM能够逐行模拟Python代码执行,并结合环境反馈进行推理。例如,在编程竞赛问题中,CWM先生成初步解决方案,再通过输入-输出对验证正确性,并修正预测结果。这种能力展示了 世界模型在agent性编码和推理中的潜力。
 图片
图片
论文还探索了将执行跟踪预测集成到自然语言推理中,使模型无需访问实时环境即可进行稳固推理,未来可用于创建“神经调试器”,支持程序验证、调试和生成的状态抽象表示。
架构与训练
模型架构:CWM是 32B参数的稠密解码器模型,采用交错局部和全局注意力块,滑动窗口注意力支持131k上下文长度。使用SwiGLU激活、RMSNorm和旋转位置编码(RoPE),支持长上下文建模。
 图片
图片
两阶段预训练:通用预训练:多来源数据,包括编码、STEM和一般知识;中期训练代码世界模型:加入Python执行轨迹和ForagerAgent数据,中期训练是教授代码世界建模能力的关键阶段。
中期训练数据混合中,CWM特定数据占30%,通用代码占40%,预训练复习占30%,并通过多epoch训练优化下游性能。
后训练:SFT与RL
SFT:CWM在 监督微调(SFT) 阶段训练,以提高推理能力和指令跟随能力,使用多样化内部数据和开放访问数据,包括agent交互轨迹和推理数据集。引入推理token,使模型可切换推理模式。
RL算法:论文采用 Group Relative Policy Optimization (GRPO)变体,支持 多轮RL 和 异步RL,结合多任务、多回合强化学习,进一步提升CWM在复杂代码任务中的能力。
 图片
图片


