 在 SIGGRAPH Asia 2025 期间,盛大集团(Shanda Group)旗下,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究,正式登上国际顶级学术与产业舞台。
在 SIGGRAPH Asia 2025 期间,盛大集团(Shanda Group)旗下,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究,正式登上国际顶级学术与产业舞台。
这一全新范式是盛大集团创始人陈天桥长期愿景的直接体现。他多年来对脑科学与 AI 融合研究的战略投入,以及在 TCCI 首届 AI 驱动科学研讨会(AIAS 2025)上系统阐述的 “发现式智能”(discovery intelligence)理念,共同强调了智能体认知基底的重要性。而「交互智能」的实现,也得益于盛大集团旗下 EverMind 团队产品 EverMemOS 的能力互补,彰显了集团内部强大的技术协同生态。然而,在将这一宏大构想付诸现实的道路上,整个行业正面临着深刻的共同挑战。

图 1 盛大集团创始人陈天桥阐述 “脑科学与 AI 融合” 的战略愿景,强调智能体认知基底的重要性。
问题的核心:为何当下的数字人交互缺乏 “灵魂”?
尽管当前的数字人技术已经能够创造出与真人无异的视觉形象,但用户在与之互动时,普遍会感到一种难以言喻的 “空洞感” 或 “断裂感”。这种交互上的 “灵魂缺失” 并非微不足道的瑕疵,而是导致数十亿美元投资于视觉特效的数字资产,至今仍未能带来真正有意义用户粘性的根本原因。这种 “灵魂感” 的缺失,并非单一技术问题,而是源于三个层面的系统性挑战:
长期记忆与人格一致性: 标准的通用大语言模型(LLM)在长时间对话中,往往难以维持稳定的人格设定,出现所谓的 “人格漂移”(persona drift)现象,导致叙事逻辑前后矛盾。真正的 “记忆” 不仅是对过往事件的回溯,更是维持个性、习惯和世界观连贯性的基石。缺乏这一能力,数字人便无法形成可信赖的、持续的身份认同。

图 2 盛大 AI 首席科学家郑波博士深入剖析数字人 “灵魂缺失” 的核心难题,并确立了以 “交互智能” 和 “时空智能” 为核心的研究目标。
多模态情感表达的缺失: “灵魂感” 很大程度上源于人类丰富的非语言交流。然而,目前的数字人普遍存在 “僵尸脸(zombie-face)” 现象 —— 在倾听或思考时面部僵硬,缺乏自然的微表情和反应。真正的沉浸感来自于语音语调、面部表情、眼神乃至肢体动作的协同作用,它们共同构成了情感表达的完整层次,而这正是当前技术的薄弱环节。
缺乏自主进化的能力: 大多数数字人本质上仍是一个被动的 “播放系统”,根据预设脚本或实时指令做出反应,而不能从交互中学习和成长。它们无法自主适应用户偏好、修正错误认知或发展出新的行为模式。这种自我进化的能力,是智能体从 “模仿” 走向真正 “智能” 的关键分水岭。
这三大挑战共同作用,导致了当前数字人交互体验的浅层化和碎片化,使用户难以建立真正的情感连接。如何系统性地攻克这些难题,不仅是技术上的挑战,更需要顶层的战略远见。

图 3 香港大学教授、SIGGRAPH Asia 大会主席 Taku Komura (左) 与早稻田大学教授 Shigeo Morishima (右) 在盛大 AI 闭门研讨会上发表致辞。
业界共鸣:SIGGRAPH Asia 闭门研讨会的深刻洞见
陈天桥的远见得到了行业的验证。解决上述挑战的紧迫性,并非盛大 AI 的内部洞见,而是一个由行业顶尖头脑共同铸就的明确共识。2025 年 12 月 17 日,在香港 SIGGRAPH Asia 大会期间,恰逢其 Mio 技术报告于前一日(12 月 16 日)公开发布之际,盛大 AI 东京研究院(Shanda AI Research Tokyo)主办了一场高端闭门晚宴及专题研讨会。这场活动汇聚了来自学术界和产业界的顶尖专家,旨在通过思想的深度碰撞,共同擘画数字人技术的未来蓝图,并即时探讨 Mio 报告所带来的突破性启示。
与会的专家学者阵容强大,包括:
Prof. Taku Komura (香港大学,Siggraph Asia 大会 General Chair)
Prof. Shigeo Morishima (早稻田大学,日本数字人协会主席,真人自动化复刻到电影的第一人)
Prof. Erwin Wu (东京科学大学)
Prof. Xiangyu Yue (香港中文大学)
Prof. Anyi Rao (香港科技大学)
Prof. Yuan Liu (香港科技大学)
Prof. Xiaoguang Han (香港中文大学)

图 4 来自港大、港中大、港科大及东京科学大学的顶尖学者在 Panel 环节深度探讨 “交互智能” 的未来。
在这场高水平的对话中,专家们达成了一个清晰的共识:当前数字人发展的瓶颈已从视觉表现力转向了认知和交互逻辑。他们一致认为,未来数字人的核心竞争力将体现在其「交互智能」上,即必须具备长期记忆、多模态情感表达和自主演进这三大关键能力。这三大支柱,由业界最敏锐的头脑共同确立,正是 Mio 的核心模块 —— 认知核心、多模态动画师及自主演进框架 —— 被系统性地设计出来旨在解决的精确挑战。
正是基于这样的行业共识与自身长期的技术探索,盛大 AI 东京研究院系统性地推出了自己的解决方案。
Mio 的诞生:盛大 AI 对「交互智能」的系统性解答
为了迎接这一行业共同的挑战,盛大 AI 东京研究院正式推出了 Mio(Multimodal Interactive Omni-Avatar)—— 一个旨在实现「交互智能」(Interactive Intelligence)的端到端系统性框架。Mio 的诞生标志着一个分水岭时刻,其设计理念是将数字人从一个被动执行指令的 “木偶”,转变为一个能够自主思考、感知并与世界互动的智能伙伴。
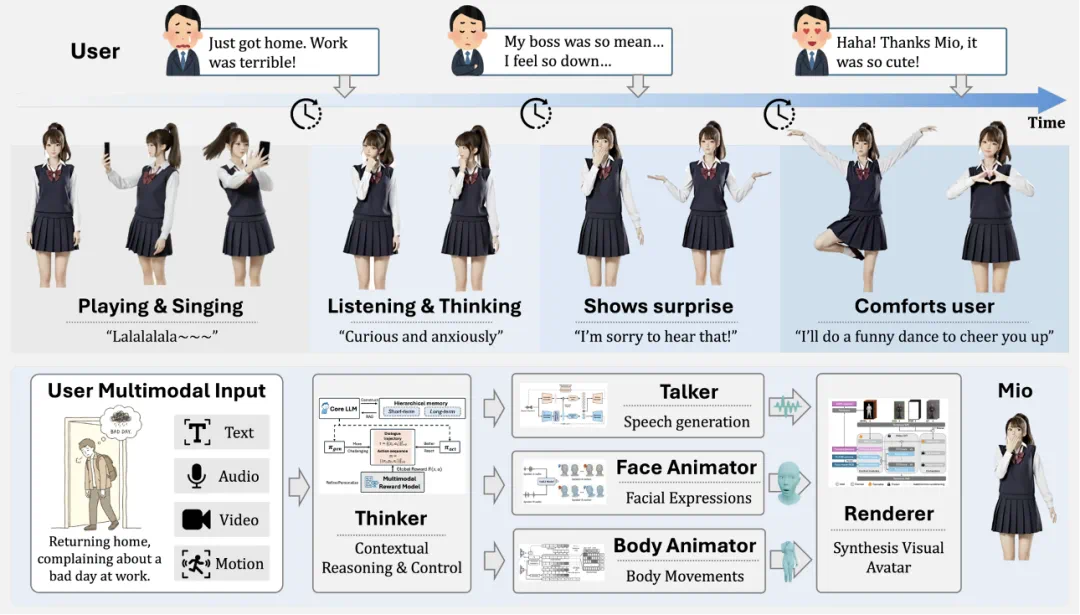
图 5 Mio 系统的端到端交互闭环演示 —— 从感知用户情绪(User Input)到 Thinker 进行认知推理,再通过多模态模块(Face/Body/Speech)生成抚慰性的反馈动作。
该框架由五个高度协同的核心模块构成:
认知核心 (Thinker): 为克服标准 LLM 固有的 “失忆症” 和人格漂移问题,Mio 的 “大脑”——Thinker 模块 —— 采用了一种革命性的 “介于叙事时间的知识图谱”(Diegetic Knowledge Graph)。该架构为每条信息标记了 “故事时间”,确保数字人绝不会 “剧透”。在 CharacterBox 基准测试中,其人格保真度超越了 GPT-4o,并在防止剧透测试中取得了近乎完美(超过 90%)的成绩。同时,其 “无数据自训练” 机制赋予了数字人通过自我博弈不断进化的能力。
语音引擎 (Talker): 该模块利用高效的离散化语音表征技术,能够生成与当前情境、情绪和人格设定高度匹配的自然语音。它不仅保证了对话的流畅性,更是数字人情感表达的关键一环。
面部动画师 (Facial Animator): 为彻底消除破坏沉浸感的 “僵尸脸” 现象,该模块采用了一个统一的 “听 - 说” 框架。无论是在说话还是倾听,它都能生成生动、自然的微表情、眼神和头部姿态。在用户研究中,超过 90% 的参与者认为其倾听反应优于业界领先的竞品。
身体动画师 (Body Animator): 为摆脱笨拙的预设动作,身体动画师采用新颖的流式扩散模型(Streaming Diffusion),实时地将认知意图转化为流畅、连贯的全身动作。这项技术实现了前所未有的突破:在保持实时性的同时,其运动质量(FID 为 0.057)达到了与顶尖离线模型相媲美的水平。
渲染引擎 (Renderer): 作为最终的视觉呈现层,渲染引擎确保在任何动态和视角变化下,都能生成高保真且身份高度一致的视觉形象,将 “灵魂” 的内在活动忠实地外化为可信的视觉表现。
Mio 框架通过将这五个模块无缝融合,实现了从认知推理到实时多模态体现(embodiment)的完整闭环,这不只是一次技术的迭代,而是一种全新的架构哲学,标志着数字人技术从 “形似” 向 “神似” 的决定性跨越。
未来展望与行动号召
Mio 的诞生,标志着数字人发展的一次范式转移 —— 行业的关注焦点正从静态的、孤立的外观逼真度,转向动态的、有意义的交互智能。这并非一个概念上的飞跃,而是可以被量化的巨大进步。在严谨的测试中,Mio 的整体交互智能分数(IIS)达到了 76.0,较之前的最优技术水平提升了整整 8.4 分,为行业树立了新的性能标杆。
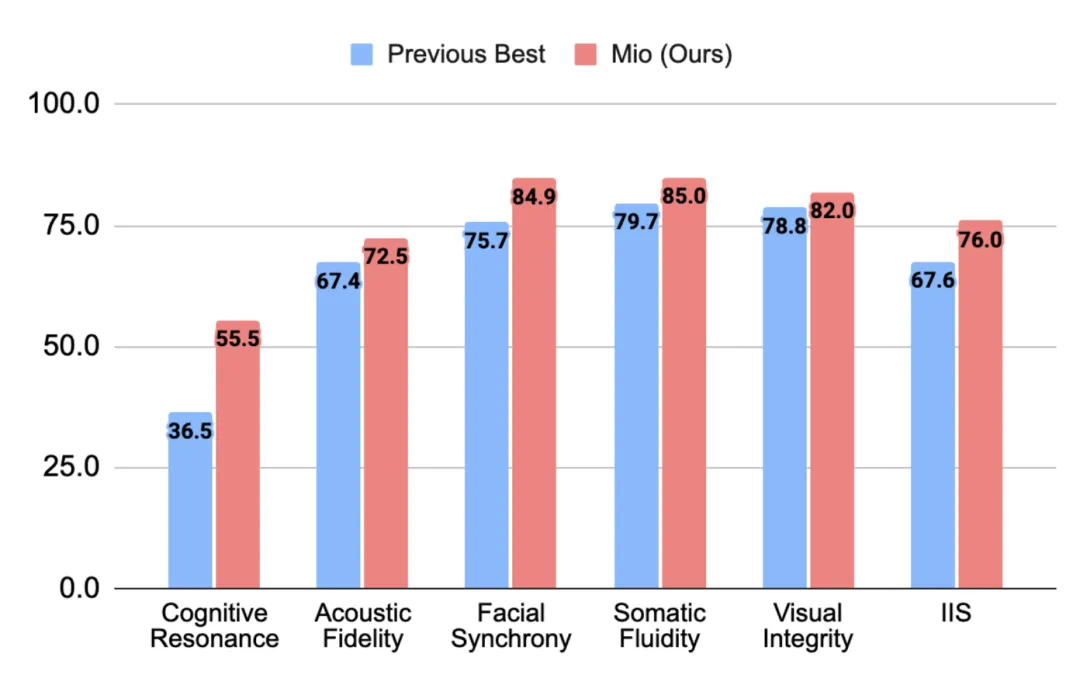
图 6 Mio (红色) 在认知共鸣、面部同步、肢体流畅度等各项指标上全面超越现有最优技术 (蓝色),IIS 总分达到 76.0。
可以预见,「交互智能」将为虚拟陪伴、互动叙事、沉浸式游戏等领域带来革命性的变革。未来的数字人将不再是冰冷的程序,而是能够与我们建立深层情感连接、共同成长的智能伙伴。被动、无声的虚拟形象时代已经结束。我们诚邀全球的研究者、开发者与创造者社区,与我们一道构建下一代拥有智能与灵魂的数字生命。现在,工具已在你们手中。

图 7 盛大 AI 东京研究院团队与全球顶尖学者在香港齐聚一堂,共同致力于构建下一代有灵魂的数字生命。
为了推动这一领域的共同进步,盛大 AI 东京研究院已将 Mio 项目的完整技术报告、预训练模型和评估基准公开发布。
项目地址: https://shandaai.github.io/project_mio_page/



